Introducción
En el mundo de los inteligencia artificial, imagine una técnica de aprendizaje que permita a las máquinas aprovechar su conocimiento existente y abordar nuevos desafíos con experiencia. Esta técnica única se llama aprendizaje por transferencia. En los últimos años, hemos sido testigos de una expansión de las capacidades y aplicaciones de los modelos generativos. Podemos utilizar el aprendizaje por transferencia para simplificar el entrenamiento de los modelos generativos. Imagine a un artista experto que, habiendo dominado diversas formas de arte, puede crear sin esfuerzo una obra maestra aprovechando sus diversas habilidades. De manera similar, el aprendizaje por transferencia permite a las máquinas utilizar el conocimiento adquirido en un área para sobresalir en otra. Esta fantástica e increíble capacidad de transferir conocimiento ha abierto un mundo de posibilidades en inteligencia artificial.
OBJETIVOS DE APRENDIZAJE
En este artículo, haremos
- Obtenga información sobre el concepto de aprendizaje por transferencia y descubra las ventajas que ofrece en el mundo del aprendizaje automático.
- Además, exploraremos varias aplicaciones del mundo real donde se emplea eficazmente el aprendizaje por transferencia.
- Luego, comprenda el proceso paso a paso de construcción de un modelo para clasificar los gestos de las manos de piedra, papel y tijera.
- Descubra cómo aplicar técnicas de aprendizaje por transferencia para entrenar y probar su modelo de manera efectiva.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Transferir aprendizaje
Imagínese ser un niño y desear con muchas ganas aprender a andar en bicicleta por primera vez. Te resultará difícil mantener el equilibrio y aprender. En ese momento, hay que aprender todo desde cero. Recuerde mantener el equilibrio, un mango de dirección, usar frenos y todo será mejor. Se necesita mucho tiempo y, después de muchas pruebas fallidas, finalmente aprenderá todo.
De igual forma, imagina ahora si quieres aprender sobre motos. En este caso, no es necesario que aprendas todo desde cero como lo hacías en la infancia. Ahora ya sabes muchas cosas. Ya tienes algunas habilidades como cómo mantener el equilibrio, cómo manejar el volante y cómo utilizar los frenos. Ahora tienes que transferir todas estas habilidades y aprender habilidades adicionales como usar engranajes. Haciéndolo mucho más fácil para ti y tomando menos tiempo para aprender. Ahora, comprendamos el aprendizaje por transferencia desde una perspectiva técnica.
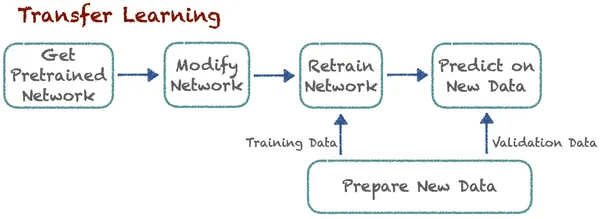
Transfer Learning mejora el aprendizaje en una nueva tarea al transferir conocimientos de una lección relacionada que los expertos ya han descubierto. Esta técnica permite a los algoritmos recordar nuevos trabajos utilizando modelos previamente entrenados. Digamos que existe un algoritmo que clasifica perros y gatos. Ahora, los expertos utilizan el mismo modelo previamente entrenado con algunas modificaciones para clasificar automóviles y camiones. La idea básica aquí es la clasificación. Aquí, el aprendizaje de nuevas tareas se basa en lecciones previamente conocidas. El algoritmo puede almacenar y acceder a este conocimiento previamente aprendido.
Beneficios del Aprendizaje por Transferencia
- Aprendizaje más rápido: Como el modelo no aprende desde cero, aprender nuevas tareas lleva muy poco tiempo. Utiliza conocimientos previamente entrenados, lo que reduce significativamente el tiempo de capacitación y los recursos computacionales. El modelo necesita una ventaja. De esta forma, tiene el beneficio de un aprendizaje más rápido.
- Desempeño mejorado: Los modelos que utilizan el aprendizaje por transferencia logran un mejor rendimiento, especialmente cuando ajustan un modelo previamente entrenado para una tarea relacionada, en comparación con los modelos que aprenden todo desde cero. Esto condujo a una mayor precisión y eficiencia.
- Eficiencia de datos: Sabemos que entrenar modelos de aprendizaje profundo requiere una gran cantidad de datos. Sin embargo, necesitamos conjuntos de datos más pequeños para los modelos de aprendizaje por transferencia, ya que heredan el conocimiento del dominio de origen. Por tanto, reduce la necesidad de grandes cantidades de datos etiquetados.
- Ahorra recursos: Construir y mantener modelos a gran escala desde cero puede requerir muchos recursos. La transferencia de aprendizaje permite a las organizaciones utilizar los recursos existentes de forma eficaz. Y no necesitamos muchos recursos para obtener suficientes datos para entrenar.
- Aprendizaje Continuo: El aprendizaje continuo se puede lograr mediante el aprendizaje por transferencia. Los modelos pueden aprender y adaptarse continuamente a nuevos datos, tareas o entornos. Se consigue así un aprendizaje continuo, fundamental en el aprendizaje automático.
- Resultados de última generación: El aprendizaje por transferencia ha desempeñado un papel crucial a la hora de lograr resultados de última generación. Logró resultados de vanguardia en muchas competiciones y pruebas de aprendizaje automático. Actualmente se ha convertido en una técnica estándar en este campo.
Aplicaciones del aprendizaje por transferencia
Transferir el aprendizaje es similar a utilizar el conocimiento existente para que aprender cosas nuevas sea más sencillo. Es una técnica poderosa ampliamente utilizada en diferentes dominios para mejorar las capacidades de los programas informáticos. Ahora, exploremos algunas áreas comunes donde el aprendizaje por transferencia juega un papel vital.
Visión por computador:
Muchos visión de computadora Las tareas utilizan ampliamente el aprendizaje por transferencia, particularmente en la detección de objetos, donde los expertos ajustan modelos previamente entrenados como ResNet, VGG o MobileNet para tareas específicas de reconocimiento de objetos. Algunos modelos como FaceNet y OpenFace emplean aprendizaje por transferencia para reconocer rostros en diferentes condiciones de iluminación, poses y ángulos. Los modelos previamente entrenados también están adaptados para tareas de clasificación de imágenes. Estos incluyen análisis de imágenes médicas, monitoreo de vida silvestre y control de calidad en la fabricación.
Procesamiento del lenguaje natural (PNL):
Hay algunos modelos de aprendizaje por transferencia como BERTI y GPT donde estos modelos se ajustan para el análisis de sentimiento. Para que puedan comprender el sentimiento del texto en diversas situaciones, el modelo Transformer de Google utiliza el aprendizaje por transferencia para traducir texto entre idiomas.
Vehículos autónomos:
La aplicación del aprendizaje por transferencia en vehículos autónomos es un área de desarrollo crítica y en rápida evolución en la industria automotriz. Hay muchos segmentos en esta área donde se utiliza el aprendizaje por transferencia. Algunos son detección de objetos, reconocimiento de objetos, planificación de rutas, predicción de comportamiento, fusión de sensores, controles de tráfico y muchos más.
Generación de contenido:
Generación de contenido es una interesante aplicación de aprendizaje por transferencia. GPT-3 (Generative Pre-trained Transformer 3) ha sido entrenado con grandes cantidades de datos de texto. Puede generar contenido creativo en muchos dominios. GPT-3 y otros modelos generan contenido creativo, incluido arte, música, narración y generación de código.
Sistemas de recomendación:
Todos conocemos las ventajas de sistemas de recomendación. Simplemente nos hace la vida un poco más sencilla y sí, aquí también utilizamos el aprendizaje por transferencia. Muchas plataformas en línea, incluidas Netflix y YouTube, utilizan el aprendizaje por transferencia para recomendar películas y vídeos según las preferencias del usuario.
Más información: Comprender el aprendizaje por transferencia para el aprendizaje profundo
Mejora de los modelos generativos
Los modelos generativos son uno de los conceptos más apasionantes y revolucionarios en el campo de la inteligencia artificial, en rápida evolución. En muchos sentidos, el aprendizaje por transferencia puede mejorar la funcionalidad y el rendimiento de los modelos de IA generativa como GAN (redes generativas adversarias) or VAE (codificadores automáticos variacionales). Uno de los principales beneficios del aprendizaje por transferencia es que permite que los modelos utilicen el conocimiento adquirido en diferentes tareas relacionadas. Sabemos que los modelos generativos requieren una amplia formación. Para lograr mejores resultados, es esencial entrenarlo en grandes conjuntos de datos, una práctica fuertemente respaldada por el aprendizaje por transferencia. En lugar de empezar desde cero, los modelos pueden iniciar actividades con conocimientos preexistentes.
En el caso de GAN o VAE, los expertos pueden entrenar previamente las partes discriminadoras o codificadoras-decodificadoras del modelo en un conjunto de datos o dominio más amplio. Esto puede acelerar el proceso de formación. Los modelos generativos suelen necesitar grandes cantidades de datos de dominios específicos para generar contenido de alta calidad. El aprendizaje por transferencia puede resolver este problema, ya que solo requiere conjuntos de datos más pequeños. También facilita el aprendizaje continuo y la adaptación de modelos generativos.
El aprendizaje por transferencia ya ha encontrado aplicaciones prácticas para mejorar los modelos de IA generativa. Se ha utilizado para adaptar modelos basados en texto como GPT-3 para generar imágenes y escribir código. En el caso de las GAN, el aprendizaje por transferencia puede ayudar a crear imágenes hiperrealistas. A medida que la IA generativa siga mejorando, el aprendizaje por transferencia será muy importante para ayudarla a hacer cosas aún más excelentes.
MóvilNet V2
Google creó MobileNetV2, una robusta arquitectura de red neuronal previamente entrenada ampliamente utilizada en aplicaciones de visión por computadora y aprendizaje profundo. Inicialmente pretendían que este modelo manejara y analizara imágenes rápidamente, con el objetivo de lograr un rendimiento de vanguardia en una variedad de tareas. Ahora es una opción muy apreciada para muchas tareas de visión por computadora. MobileNetV2 está diseñado específicamente para ser liviano y eficiente. Requiere una cantidad relativamente pequeña de parámetros y logra resultados impresionantes y de alta precisión.
A pesar de su eficiencia, MobileNetV2 mantiene una alta precisión en diversas tareas de visión por computadora. MobileNetV2 introduce el concepto de residuos invertidos. A diferencia de los residuales tradicionales, donde la salida de una capa se agrega a su entrada, los residuales invertidos utilizan una conexión de acceso directo para agregar la información a la producción. Hace que el modelo sea más profundo y más eficiente.
Los residuos invertidos utilizan una conexión de acceso directo para agregar información a la producción, a diferencia de los residuos tradicionales donde la salida de una capa se agrega a su entrada. Puede tomar este modelo MobileNetV2 previamente entrenado y ajustarlo para aplicaciones específicas. Por lo tanto, ahorra mucho tiempo y recursos computacionales, lo que lleva a la reducción del costo computacional. Debido a su eficacia y eficiencia, MobileNetV2 se utiliza ampliamente en la industria y la investigación. TensorFlow Hub ofrece fácil acceso a modelos MobileNetV2 previamente entrenados. Facilita la integración del modelo en proyectos basados en Tensorflow.
Clasificación piedra, papel o tijera
Empecemos a construir un aprendizaje automático Modelo para la tarea de clasificación piedra, papel y tijera. Usaremos la técnica de aprendizaje por transferencia para implementar. Para ello, utilizamos el modelo preentrenado MobileNet V2.

Conjunto de datos de piedra, papel y tijera
El conjunto de datos 'Piedra, papel y tijera' es una colección de 2,892 imágenes. Consta de diversas manos en las tres posturas diferentes. Estos son,
- Rock: El puño cerrado.
- Papel: La palma abierta.
- Tijeras: Los dos dedos extendidos formando una V.
Las imágenes incluyen manos de personas de diferentes razas, edades y géneros. Todas las imágenes tienen el mismo fondo blanco liso. Esta diversidad lo convierte en un recurso valioso para aplicaciones de aprendizaje automático y visión por computadora. Esto ayuda a prevenir tanto el sobreajuste como el desajuste.
Cargando y explorando el conjunto de datos
Comencemos importando las bibliotecas básicas requeridas. Este proyecto requiere tensorflow, tensorflow hub, conjuntos de datos de tensorflow para conjunto de datos, matplotlib para visualización, numpy y os.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pylab as plt
import numpy as np
import os
Utilizando conjuntos de datos de tensorflow, cargue el conjunto de datos "Piedra, papel o tijera". Aquí le proporcionamos cuatro parámetros. Tenemos que mencionar el nombre del conjunto de datos que necesitamos cargar. Aquí está piedra_papel_tijera. Para solicitar información sobre el conjunto de datos, establezca with_info en True. A continuación, para cargar el conjunto de datos en el formato supervisado, establezca as_supervised en True.
Y por último definir los splits que queremos cargar. Aquí necesitamos entrenar y probar particiones. Cargue conjuntos de datos e información en las variables correspondientes.
datasets, info = tfds.load( name='rock_paper_scissors', # Specify the name of the dataset you want to load. with_info=True, # To request information about the dataset as_supervised=True, # Load the dataset in a supervised format. split=['train', 'test'] # Define the splits you want to load.
)
Imprimir información
Ahora imprima la información. Publicará todos los detalles del conjunto de datos. Su nombre, versión, descripción, recurso del conjunto de datos original, características, número total de imágenes, números divididos, autor y muchos más detalles.
info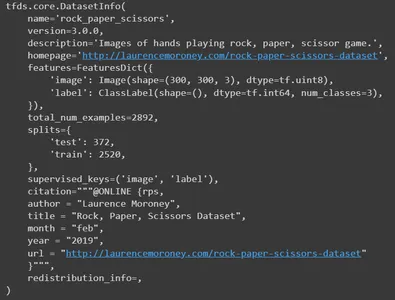
Ahora, imprima algunas imágenes de muestra del conjunto de datos de entrenamiento.
train, info_train = tfds.load(name='rock_paper_scissors', with_info=True, split='train')
tfds.show_examples(info_train,train)
Primero cargamos el conjunto de datos “Piedra, papel o tijera” con los niños. Función Load (), que especifica las divisiones de entrenamiento y prueba por separado. Luego, concatenamos los conjuntos de datos de entrenamiento y prueba usando el método .concatenate(). Finalmente, mezclamos el conjunto de datos combinado usando el método .shuffle() con un tamaño de búfer 3000. Ahora, tiene una única variable de conjunto de datos que combina datos de entrenamiento y prueba.
dataset=datasets[0].concatenate(datasets[1])
dataset=dataset.shuffle(3000)Debemos dividir todo el conjunto de datos en conjuntos de datos de entrenamiento, prueba y validación utilizando los métodos skip() y take(). Utilizamos las primeras 600 muestras del conjunto de datos para la validación. Luego, creamos un conjunto de datos temporal excluyendo las 600 imágenes iniciales. En este conjunto de datos temporal, seleccionamos las primeras 400 fotos para realizar pruebas. Nuevamente, en el conjunto de datos de entrenamiento, toma todas las fotografías del conjunto de datos temporal después de omitir las primeras 400 imágenes.
A continuación se muestra un resumen de cómo se dividen los datos:
- rsp_val: 600 ejemplos para validación.
- rsp_test: 400 muestras para prueba.
- rsp_train: Los ejemplos restantes para el entrenamiento.
rsp_val=dataset.take(600)
rsp_test_temp=dataset.skip(600)
rsp_test=rsp_test_temp.take(400)
rsp_train=rsp_test_temp.skip(400)Entonces, veamos cuántas imágenes hay en el conjunto de datos de entrenamiento.
len(list(rsp_train)) #1892
#It has 1892 images in totalPreprocesamiento de datos
Ahora, realicemos un preprocesamiento para nuestro conjunto de datos. Para eso, definiremos una escala de función. Le pasaremos la imagen y su correspondiente etiqueta como argumentos. Usando el método de conversión, convertiremos el tipo de datos de la imagen a float32. Luego, en el siguiente paso, tenemos que normalizar los valores de píxeles de la imagen. Escala los valores de píxeles de la imagen al rango [0, 1]. El cambio de tamaño de la imagen es un paso de preprocesamiento común para garantizar que todas las imágenes de entrada tengan las dimensiones exactas, lo que a menudo se requiere cuando se entrenan modelos de aprendizaje profundo. Entonces, devolveremos las imágenes de tamaño [224,224]. Para las etiquetas, realizaremos una codificación onehot. La etiqueta se convertirá en un vector codificado one-hot si tiene tres clases (piedra, papel, tijera). Este vector está siendo devuelto.
Por ejemplo, si la etiqueta es 1 (Papel), se transformará en [0, 1, 0]. Aquí, cada elemento corresponde a una clase. El “1” se coloca en la posición correspondiente a esa clase en particular (Papel). De manera similar, para etiquetas de roca, el vector será [1, 0, 0], y para tijeras, será [0, 0, 1].
Código
def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return tf.image.resize(image,[224,224]), tf.one_hot(label, 3)Ahora, defina una función para crear conjuntos de datos preprocesados y por lotes para entrenamiento, prueba y validación. Aplique la función de escala predefinida a los tres conjuntos de datos. Defina el tamaño del lote como 64 y páselo como argumento. Esto es común en el aprendizaje profundo, donde los modelos a menudo se entrenan con lotes de datos en lugar de ejemplos individuales. Necesitamos mezclar el conjunto de datos del tren para evitar un sobreajuste. Finalmente, devuelva los tres conjuntos de datos escalados.
def get_dataset(batch_size=64): train_dataset_scaled = rsp_train.map(scale).shuffle(1900).batch(batch_size) test_dataset_scaled = rsp_test.map(scale).batch(batch_size) val_dataset_scaled = rsp_val.map(scale).batch(batch_size) return train_dataset_scaled, test_dataset_scaled, val_dataset_scaledCargue los tres conjuntos de datos individualmente usando la función get_dataset. Luego, entrene en caché y valide los conjuntos de datos. El almacenamiento en caché es una técnica valiosa para mejorar el rendimiento de la carga de datos, especialmente cuando se tiene suficiente memoria para almacenar los conjuntos de datos. El almacenamiento en caché significa que los datos se cargan en la memoria y se mantienen allí para un acceso más rápido durante los pasos de capacitación y validación. Esto puede acelerar el entrenamiento, especialmente si su proceso de entrenamiento involucra múltiples épocas, porque evita cargar repetidamente los mismos datos desde el almacenamiento.
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()Cargando modelo previamente entrenado
Con Tensorflow Hub, cargue un extractor de funciones MobileNet V2 previamente entrenado. Y configúrelo como una capa en un modelo Keras. Este modelo de MobileNet está entrenado en un gran conjunto de datos y se puede utilizar para extraer características de imágenes. Ahora, cree una capa keras usando el extractor de funciones MobileNet V2. Aquí, especifique input_shape como (224, 224, 3). Esto indica que el modelo espera imágenes de entrada con dimensiones de 224×224 píxeles y tres canales de color (RGB). Establezca el atributo entrenable de esta capa en Falso. Hacer esto indica que no desea ajustar el modelo MobileNet V2 previamente entrenado durante el proceso de capacitación. Pero puedes agregar tus capas personalizadas encima.
feature_extractor = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor_layer = hub.KerasLayer(feature_extractor, input_shape=(224,224,3))
feature_extractor_layer.trainable = FalseModelo de construcción
Es hora de construir el modelo secuencial de TensorFlow Keras agregando capas a la capa de extracción de funciones de MobileNet V2. A feature_extractor_layer, agregaremos una capa de eliminación. Aquí estableceremos una tasa de abandono del 0.5. Este método de regularización es lo que hacemos para evitar el sobreajuste. Durante el entrenamiento, si la tasa de abandono se establece en 0.5, el modelo eliminará un promedio del 50% de las unidades. Luego, agregamos una capa densa con tres unidades de salida y, en este paso, usamos la función de activación 'softmax'. 'Softmax' es una función de activación ampliamente utilizada para resolver problemas de clasificación de clases múltiples. Calcula la distribución de probabilidad sobre las clases de cada imagen de entrada (piedra, papel, tijera). Luego, imprima el resumen del modelo.
model = tf.keras.Sequential([ feature_extractor_layer, tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(3,activation='softmax')
]) model.summary()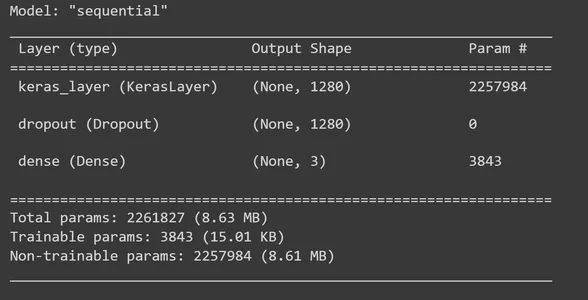
Es hora de compilar nuestro modelo. Para ello, utilizamos el optimizador Adam y la función de pérdida C.ategoricalCrossentropy. El argumento from_logits=True indica que la salida de su modelo produce logits sin procesar (puntuaciones no normalizadas) en lugar de distribuciones de probabilidad. Para monitorear durante la capacitación, utilizamos métricas de precisión.
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['acc'])Las funciones llamadas devoluciones de llamada se pueden ejecutar en diferentes etapas del entrenamiento, incluido el final de cada lote o época. En este contexto, definimos una devolución de llamada personalizada en TensorFlow Keras con el propósito de recopilar y registrar valores de pérdida y precisión a nivel de lote durante el entrenamiento.
class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()Ahora, crea un objeto de la clase creada. Luego, entrene el modelo usando el método fit_generator. Para hacer esto, necesitamos proporcionar los parámetros necesarios. Necesitamos un conjunto de datos de entrenamiento que mencione la cantidad de épocas que necesita entrenar, el conjunto de datos de validación y establecer devoluciones de llamadas.
batch_stats_callback = CollectBatchStats() history = model.fit_generator(train_dataset, epochs=5, validation_data=val_dataset, callbacks = [batch_stats_callback])Visualizaciones
Usando matplotlib, trace la pérdida de entrenamiento a lo largo de los pasos de entrenamiento usando los datos recopilados por la devolución de llamada CollectBatchStats. Podemos observar cómo se optimiza la pérdida en campo a medida que avanza el entrenamiento.
plt.figure()
plt.ylabel("Loss")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)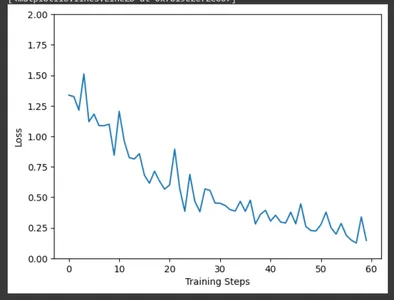
De manera similar, trace la precisión de los pasos de entrenamiento. Aquí también podemos observar el aumento de la precisión a medida que avanza el entrenamiento.
plt.figure()
plt.ylabel("Accuracy")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)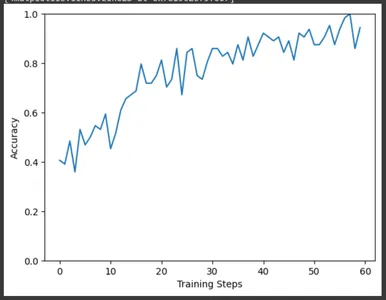
Evaluación y resultados
Es hora de evaluar nuestro modelo utilizando un conjunto de datos de prueba. La variable de resultado contendrá los resultados de la evaluación, incluida la pérdida de prueba y cualquier otra métrica que haya definido durante la compilación del modelo. Extraiga la pérdida de la prueba y la precisión de la prueba de la matriz de resultados e imprímalas. Obtendremos una pérdida de 0.14 y una precisión de alrededor del 96% para nuestro modelo.
result=model.evaluate(test_dataset)
test_loss = result[0] # Test loss
test_accuracy = result[1] # Test accuracy
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}") #Test Loss: 0.14874716103076935
#Test Accuracy: 0.9674999713897705
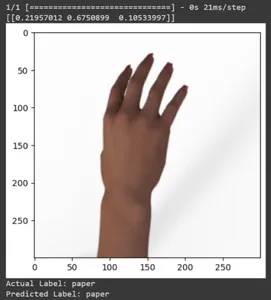
Veamos la predicción para algunas imágenes de prueba. Este bucle recorre en iteración las primeras diez muestras del conjunto de datos rsp_test. Aplique la función de escala para preprocesar la imagen y la etiqueta. Realizamos escalado de la imagen y codificación one-hot de la marca. Imprimirá la etiqueta real (convertida a partir de un formato codificado one-hot) y la etiqueta predicha (basada en la clase con la mayor probabilidad en las predicciones).
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])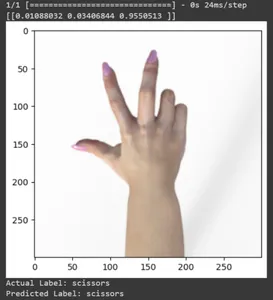
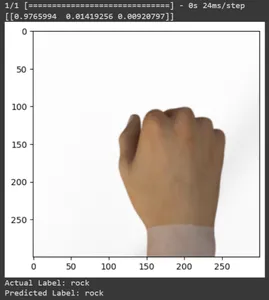
Imprimamos predicciones de todas las imágenes de prueba. Generará pronósticos para todo el conjunto de datos de prueba utilizando su modelo TensorFlow Keras entrenado y luego extraerá las etiquetas de clase (índices de clase) con la mayor probabilidad para cada predicción.
np.argmax(model.predict(test_dataset),axis=1)Imprima la matriz de confusión para las predicciones del modelo. La matriz de confusión proporciona un desglose detallado de cómo se alinean las predicciones del modelo con las etiquetas. Es una herramienta valiosa para evaluar el rendimiento de un modelo de clasificación. Le da a cada clase verdaderos positivos, verdaderos negativos y falsos positivos.
for f0,f1 in rsp_test.map(scale).batch(400): y=np.argmax(f1, axis=1) y_pred=np.argmax(model.predict(f0),axis=1) print(tf.math.confusion_matrix(labels=y, predictions=y_pred, num_classes=3)) #Output tf.Tensor(
[[142 3 0] [ 1 131 1] [ 0 1 121]], shape=(3, 3), dtype=int32) Guardar y cargar el modelo entrenado
Guarde el modelo entrenado. De modo que cuando necesites utilizar el modelo, no tengas que enseñar todo desde cero. Tienes que cargar el modelo y usarlo para la predicción.
model.save('./path/', save_format='tf')Comprobemos el modelo cargándolo.
loaded_model = tf.keras.models.load_model('path')De manera similar, como hicimos antes, probemos el modelo con algunas imágenes de muestra en el conjunto de datos de prueba.
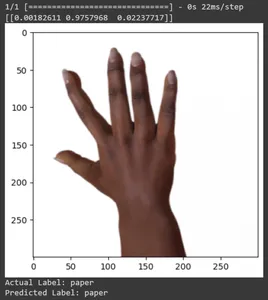
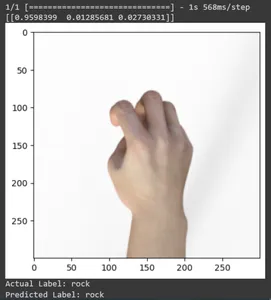
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=loaded_model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])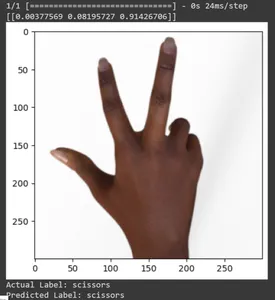
Conclusión
En este artículo, hemos aplicado el aprendizaje por transferencia para la tarea de clasificación Piedra, Papel y Tijera. Hemos utilizado un modelo Mobilenet V2 previamente entrenado para esta tarea. Nuestro modelo funciona con éxito con una precisión de alrededor del 96%. En las imágenes de predicciones, podemos ver qué tan bien predice nuestro modelo. Las últimas tres tomas muestran lo perfecta que es, incluso si la pose de la mano es imperfecta. Para representar “tijeras”, abra tres dedos en lugar de utilizar una configuración de dos dedos. Para “Rock”, no cierres el puño por completo. Pero aún así, nuestro modelo puede comprender la clase correspondiente y predecir perfectamente.
Puntos clave
- Transferir aprendizaje se trata de transferir conocimientos. Los conocimientos adquiridos en la tarea anterior se utilizan para aprender un nuevo trabajo.
- El aprendizaje por transferencia tiene el potencial de revolucionar el campo del aprendizaje automático. Proporciona varios beneficios, incluido el aprendizaje acelerado y un mejor rendimiento.
- El aprendizaje por transferencia promueve el aprendizaje continuo, donde los modelos pueden cambiar con el tiempo para abordar nueva información, tareas o el entorno.
- Es un método flexible y eficaz que eleva la efectividad y eficiencia de los modelos de aprendizaje automático.
- En este artículo, hemos aprendido todo sobre el aprendizaje por transferencia, sus beneficios y aplicaciones. También implementamos el uso de un modelo previamente entrenado en un nuevo conjunto de datos para realizar la tarea de clasificación de piedra, papel y tijera.
Preguntas Frecuentes
R. Transferir aprendizaje es la mejora del aprendizaje en una nueva tarea mediante la transferencia de conocimientos de una lección relacionada que ya se ha descubierto. Esta técnica permite a los algoritmos recordar nuevos trabajos utilizando modelos previamente entrenados.
R. Puede adaptar este proyecto a otras tareas de clasificación de imágenes reemplazando el conjunto de datos Piedra-Papel-Tijera con su conjunto de datos. Además, hay que ajustar el modelo según los requisitos del nuevo trabajo.
R. MobileNet V2 es un modelo de extracción de funciones previamente entrenado disponible en TensorFlow Hub. En escenarios de aprendizaje por transferencia, los profesionales suelen utilizar MobileNetV2 como extractor de funciones. Ajustan el modelo MobileNetV2 previamente entrenado para una tarea particular incorporando capas específicas de la tarea encima. Su enfoque permite una capacitación rápida y eficiente en diversas tareas de visión por computadora.
R. TensorFlow es un marco de aprendizaje automático de código abierto desarrollado por Google. Se utiliza ampliamente para crear y entrenar modelos de aprendizaje automático y modelos de aprendizaje intenso.
R. El ajuste fino es una técnica de aprendizaje por transferencia compartida en la que se toma un modelo previamente entrenado y se lo entrena más en su tarea específica con una tasa de aprendizaje más baja. Esto permite que el modelo adapte su conocimiento a los matices de la tarea objetivo.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/10/transfer-learning-a-rock-paper-scissors-case-study/

