En AWS re:Invent 2022, Amazon Athena lanzó soporte para Apache Spark. Con este lanzamiento, Atenea amazónica admite dos motores de consulta de código abierto: Apache Spark y Trino. Athena Spark le permite crear aplicaciones Apache Spark utilizando una experiencia de notebook simplificada en la consola de Athena o mediante las API de Athena. Los cuadernos Athena Spark son compatibles con PySpark y Notebook Magics para permitirle trabajar con Spark SQL. Para aplicaciones interactivas, Athena Spark le permite pasar menos tiempo esperando y ser más productivo, con un tiempo de inicio de la aplicación en menos de un segundo. Y como Athena no tiene servidor y está totalmente administrado, puede ejecutar sus cargas de trabajo sin preocuparse por la infraestructura subyacente.
Las aplicaciones modernas almacenan enormes cantidades de datos en Servicio de almacenamiento simple de Amazon (Amazon S3), que proporcionan almacenamiento rentable y altamente duradero, y le permiten ejecutar análisis y aprendizaje automático (ML) desde su lago de datos para generar información sobre sus datos. Antes de ejecutar estas cargas de trabajo, la mayoría de los clientes ejecutan consultas SQL para extraer, filtrar, unir y agregar datos de forma interactiva en una forma que pueda usarse para la toma de decisiones, el entrenamiento de modelos o la inferencia. Ejecutar SQL en lagos de datos es rápido y Athena proporciona una API optimizada, compatible con Trino y Presto que incluye un potente optimizador. Además, organizaciones de múltiples industrias, como servicios financieros, atención médica y comercio minorista, están adoptando Apache Spark, un popular sistema de procesamiento distribuido de código abierto que está optimizado para análisis rápidos y transformaciones avanzadas de datos de cualquier tamaño. Con soporte en Athena para Apache Spark, puede usar Spark SQL y PySpark en un solo cuaderno para generar información sobre aplicaciones o crear modelos. Comience con Spark SQL para extraer, filtrar y proyectar los atributos con los que desea trabajar. Luego, para realizar análisis de datos más complejos, como pruebas de regresión y pronósticos de series temporales, puede usar Apache Spark con Python, que le permite aprovechar un rico ecosistema de bibliotecas, incluida la visualización de datos en Matplot, Seaborn y Plotly.
En esta primera publicación de una serie de tres partes, le mostramos cómo comenzar a usar Spark SQL en los cuadernos Athena. Demostramos la consulta de bases de datos y tablas en Amazon S3 y el Pegamento AWS Catálogo de datos usando Spark SQL en Athena. Cubrimos algunos comandos SQL comunes y avanzados utilizados en Spark SQL y le mostramos cómo usar Python para ampliar su funcionalidad con funciones definidas por el usuario (UDF), así como para visualizar datos consultados. En la próxima publicación, le mostraremos cómo usar Athena Spark con formatos de tablas transaccionales de código abierto. En la tercera publicación, cubriremos el análisis de fuentes de datos distintas de Amazon S3 utilizando Athena Spark.
Requisitos previos
Para comenzar, necesitará lo siguiente:
Proporcione a Athena Spark acceso a sus datos a través de una función de IAM
A medida que avanza en este tutorial, creamos nuevas bases de datos y tablas. De forma predeterminada, Athena Spark no tiene permiso para hacer esto. Para proporcionar este acceso, puede agregar la siguiente política en línea al Gestión de identidades y accesos de AWS (IAM) rol asociado al grupo de trabajo, proporcionando la región y su número de cuenta. Para obtener más información, consulte la sección Para incorporar una política en línea para un usuario o rol (consola) in Adición de permisos de identidad de IAM (consola).
Ejecute consultas SQL directamente en el cuaderno sin usar Python
Cuando usamos los cuadernos Athena Spark, podemos ejecutar consultas SQL directamente sin tener que usar PySpark. Hacemos esto usando magia de celdas, que son encabezados especiales en un cuaderno que cambian el comportamiento de las celdas. Para SQL, podemos agregar la magia %%sql, que interpretará todo el contenido de la celda como una declaración SQL que se ejecutará en Athena Spark.
Ahora que hemos creado nuestro grupo de trabajo y nuestro cuaderno, comencemos a explorar el Resumen del día de la superficie global de la NOAA conjunto de datos, que proporciona medidas ambientales de varios lugares de todo el mundo. Los conjuntos de datos utilizados en esta publicación son conjuntos de datos públicos alojados en las siguientes ubicaciones de Amazon S3:
- Datos de parquet para el año 2020 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - Datos de parquet para el año 2021 –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2021/ - Datos de parquet del año 2022 –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2022/
Para utilizar estos datos, necesitamos una base de datos de AWS Glue Data Catalog que actúe como metastore para Athena, lo que nos permitirá crear tablas externas que apunten a la ubicación de los conjuntos de datos en Amazon S3. Primero, creamos una base de datos en el catálogo de datos usando Athena y Spark.
Crea una base de datos
Ejecute el siguiente SQL en su cuaderno usando %%sql magia:
Obtiene el siguiente resultado: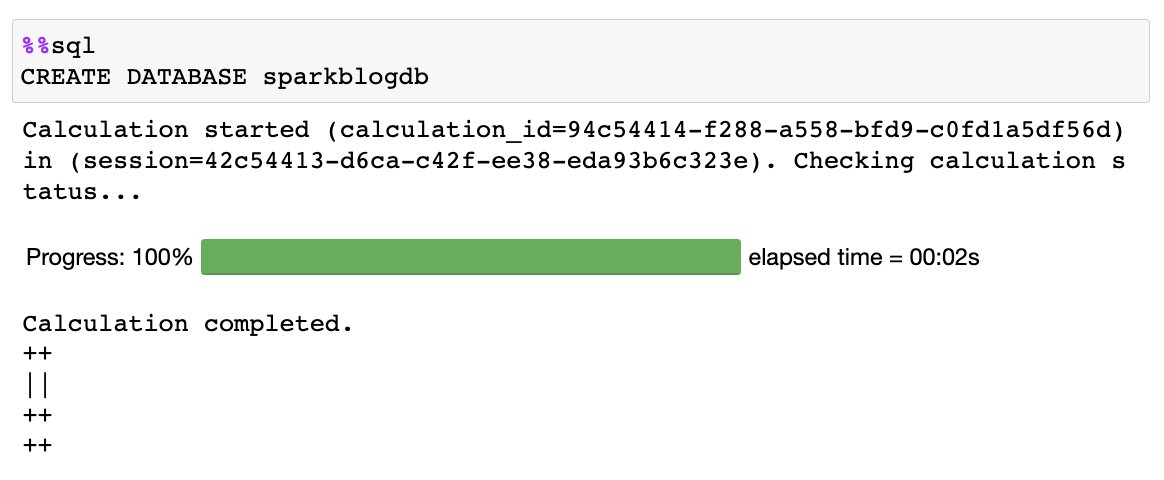
Crear una tabla
Ahora que hemos creado una base de datos en el catálogo de datos, podemos crear una tabla particionada que apunte a nuestro conjunto de datos almacenado en Amazon S3:
Este conjunto de datos está dividido por año, lo que significa que almacenamos archivos de datos para cada año por separado, lo que simplifica la administración y mejora el rendimiento porque podemos apuntar a ubicaciones S3 específicas en una consulta. El catálogo de datos conoce la tabla y ahora le dejaremos calcular cuántas particiones tenemos automáticamente usando el comando MSCK utilidad:
Cuando se complete la declaración anterior, puede ejecutar el siguiente comando para enumerar las particiones anuales que se encontraron en la tabla:

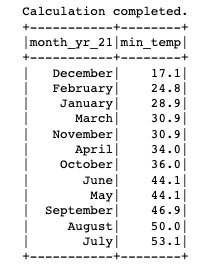
Ahora que tenemos la tabla creada y las particiones agregadas, ejecutemos una consulta para encontrar la temperatura mínima registrada para el 'SEATTLE TACOMA AIRPORT, WA US' ubicación:

Consultar un catálogo de datos entre cuentas desde Athena Spark
Athena admite el acceso a catálogos de datos de AWS Glue entre cuentas, lo que le permite utilizar Spark SQL en Athena Spark para consultar un catálogo de datos en una cuenta de AWS autorizada.
El patrón de acceso al catálogo de datos entre cuentas se utiliza a menudo en un malla de datos arquitectura, cuando un productor de datos quiere compartir un catálogo y datos con cuentas de consumidores. Luego, las cuentas de los consumidores pueden realizar análisis y exploraciones de datos en los datos compartidos. Este es un modelo simplificado donde no necesitamos usar Formación del lago AWS compartir datos. El siguiente diagrama ofrece una descripción general de cómo funciona la configuración entre una cuenta de productor y una cuenta de consumidor, que se puede extender a varias cuentas de productor y consumidor.
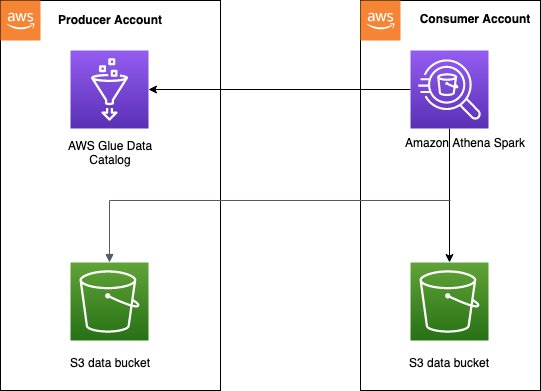
Debe configurar las políticas de acceso correctas en el catálogo de datos de la cuenta del productor para permitir el acceso entre cuentas. Específicamente, debe asegurarse de que la función IAM de la cuenta del consumidor utilizada para ejecutar cálculos de Spark en Athena tenga acceso al catálogo de datos entre cuentas y a los datos en Amazon S3. Para obtener instrucciones de configuración, consulte Configuración del acceso entre cuentas de AWS Glue en Athena para Spark.
Hay dos formas en que la cuenta del consumidor puede acceder al catálogo de datos entre cuentas desde Athena Spark, dependiendo de si realiza la consulta desde una cuenta de productor o desde varias.
Consultar una única tabla de productores.
Si solo está consultando datos de la cuenta de AWS de un único productor, puede decirle a Athena Spark que solo use el catálogo de esa cuenta para resolver objetos de la base de datos. Al utilizar esta opción, no es necesario modificar el SQL porque está configurando el ID de la cuenta de AWS a nivel de sesión. Para habilitar este método, edite la sesión y establezca la propiedad "spark.hadoop.hive.metastore.glue.catalogid": "999999999999" siguiendo los siguientes pasos:
- En el editor del cuaderno, en el Sesión menú, seleccione Editar sesión.
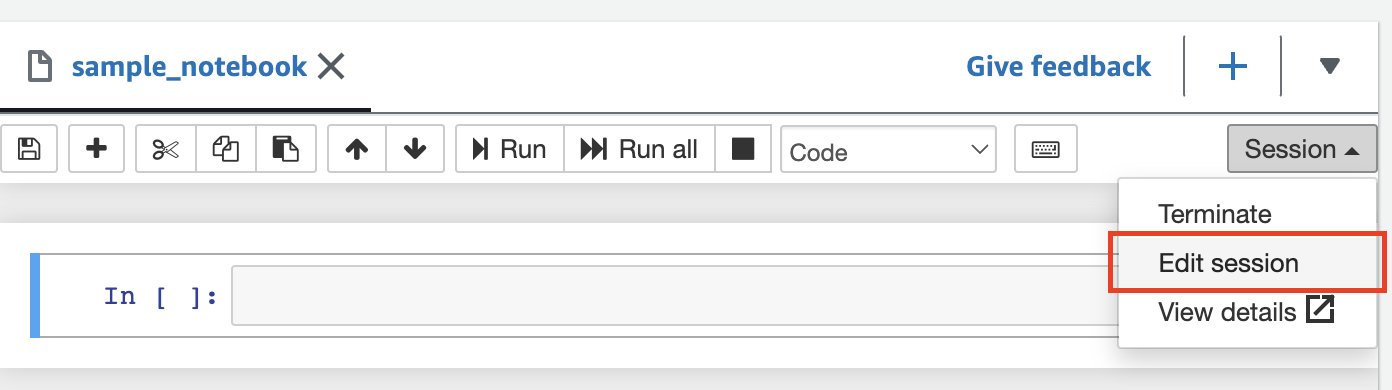
- Elige Editar en JSON.
- Agregue la siguiente propiedad y elija Guardar:
{"spark.hadoop.hive.metastore.glue.catalogid": "999999999999"}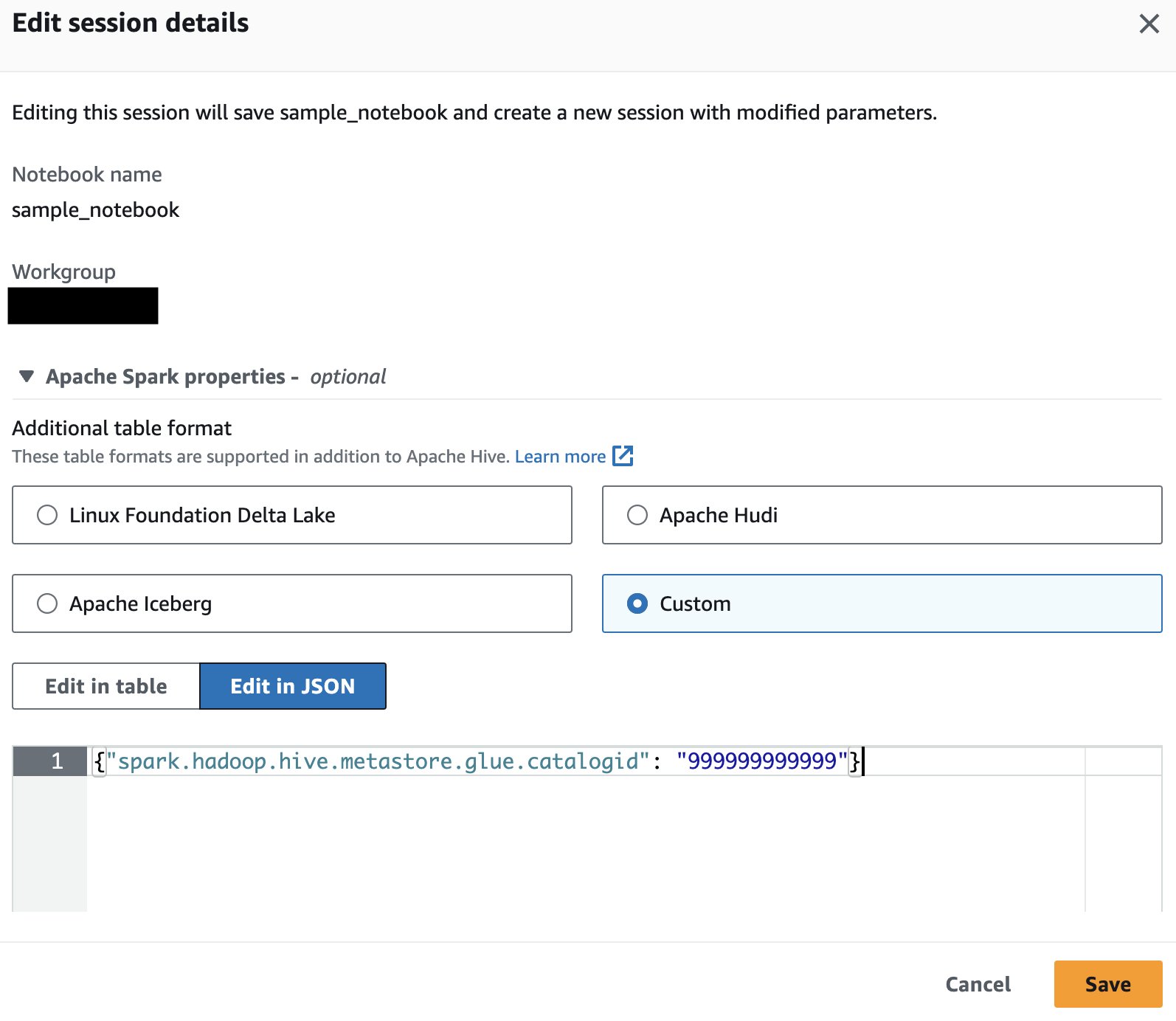 Esto iniciará una nueva sesión con los parámetros actualizados.
Esto iniciará una nueva sesión con los parámetros actualizados. - Ejecute la siguiente instrucción SQL en Spark para consultar tablas del catálogo de la cuenta del productor:
Consultar múltiples tablas de productores.
Como alternativa, puede agregar el ID de la cuenta de AWS del productor en cada nombre de base de datos, lo cual resulta útil si va a consultar catálogos de datos de diferentes propietarios. Para habilitar este método, establezca la propiedad {"spark.hadoop.aws.glue.catalog.separator": "/"} al invocar o editar la sesión (siguiendo los mismos pasos que en la sección anterior). Luego, agrega el ID de la cuenta de AWS para el catálogo de datos de origen como parte del nombre de la base de datos:
Si el depósito S3 que pertenece a la cuenta de AWS del productor está configurado con los pagos del solicitante habilitados, se le cobra al consumidor en lugar del propietario del depósito por las solicitudes y descargas. En este caso, puede agregar la siguiente propiedad al invocar o editar una sesión de Athena Spark para leer datos de estos depósitos:
{"spark.hadoop.fs.s3.useRequesterPaysHeader": "true"}
Infiera el esquema de sus datos en Amazon S3 y únalos con tablas rastreadas en el catálogo de datos
En lugar de solo poder revisar el catálogo de datos para comprender la estructura de la tabla, Spark puede inferir esquemas y leer datos directamente desde el almacenamiento. Esta característica permite a los analistas y científicos de datos realizar una exploración rápida de los datos sin necesidad de crear una base de datos o tabla, pero también se puede usar con otras tablas existentes almacenadas en el Catálogo de datos en la misma cuenta o en diferentes cuentas. Para hacer esto, utilizamos una vista temporal de Spark, que es una estructura de datos en memoria que almacena el esquema de los datos almacenados en un marco de datos.
Usando la partición del conjunto de datos NOAA para 2020, creamos una vista temporal leyendo datos de S3 en un marco de datos:
Ahora puedes consultar el y20view usando Spark SQL como si fuera una base de datos de Data Catalog:

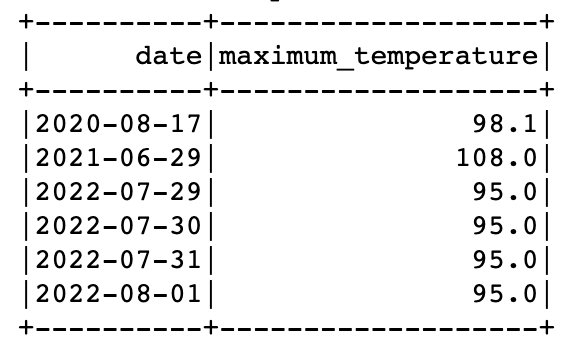
Puede consultar datos de vistas temporales y tablas del catálogo de datos en la misma consulta en Spark. Por ejemplo, ahora que tenemos una tabla que contiene datos de los años 2021 y 2022, y una vista temporal con los datos de 2020, podemos encontrar las fechas de cada año en las que se registró la temperatura máxima para 'SEATTLE TACOMA AIRPORT, WA US'.
Para ello podemos utilizar la función de ventana y UNION:
Amplíe su SQL con una UDF en Spark SQL
Puede ampliar su funcionalidad SQL registrándose y utilizando una función personalizada definida por el usuario en Athena Spark. Estas UDF se utilizan además de las funciones predefinidas comunes disponibles en Spark SQL y, una vez creadas, se pueden reutilizar muchas veces dentro de una sesión determinada.
En esta sección, analizamos una UDF sencilla que convierte un valor de mes numérico en el nombre completo del mes. Tiene la opción de escribir la UDF en Java o Python.
UDF basado en Java
El código Java para la UDF se puede encontrar en el Repositorio GitHub. Para esta publicación, hemos subido un JAR prediseñado de la UDF a s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.jar.
Para registrar la UDF, usamos Spark SQL para crear una función temporal:
UDF basado en Python
Ahora veamos cómo agregar una UDF de Python a la sesión de Spark existente. El código Python para la UDF se puede encontrar en el Repositorio GitHub. Para esta publicación, el código se ha subido a s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.py.
Las UDF de Python no se pueden registrar en Spark SQL, por lo que usamos un pequeño fragmento de código PySpark para agregar el archivo Python, importar la función y luego registrarlo como una UDF:
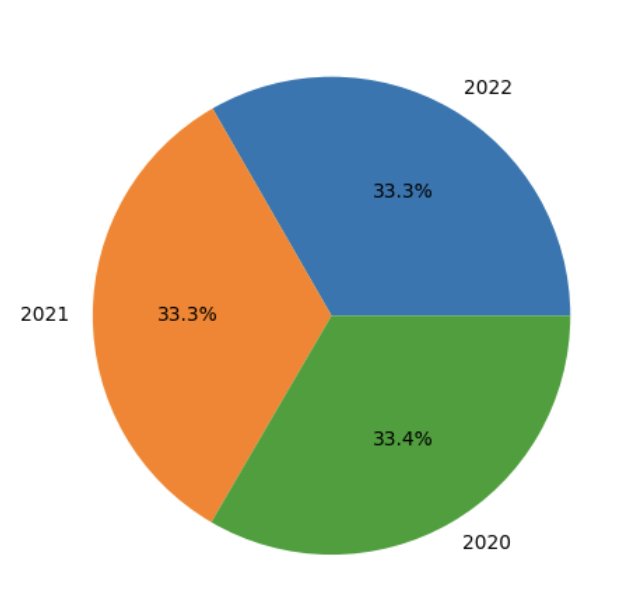
Trazar imágenes a partir de las consultas SQL.
Es sencillo utilizar Spark SQL, incluso en cuentas de AWS para la exploración de datos, y no es complicado ampliar Athena Spark con UDF. Ahora veamos cómo podemos ir más allá de SQL usando Python para visualizar datos dentro de la misma sesión de Spark y buscar patrones en los datos. Usamos la tabla y las vistas temporales creadas anteriormente para generar un gráfico circular que muestra el porcentaje de lecturas tomadas cada año para la estación. 'SEATTLE TACOMA AIRPORT, WA US'.
Comencemos creando un marco de datos Spark a partir de una consulta SQL y convirtiéndolo en un marco de datos pandas:
Limpiar
Para limpiar los recursos creados para esta publicación, complete los siguientes pasos:
- Ejecute las siguientes instrucciones SQL en la celda del cuaderno para eliminar la base de datos y las tablas del catálogo de datos:
- Eliminar el grupo de trabajo creado para esta publicación. Esto también eliminará las libretas guardadas que forman parte del grupo de trabajo.
- Eliminar el cubo S3 que creó como parte del grupo de trabajo.
Conclusión
Athena Spark hace que sea más fácil que nunca consultar bases de datos y tablas en el catálogo de datos de AWS Glue directamente a través de Spark SQL en Athena, y consultar datos directamente desde Amazon S3 sin necesidad de un metastore para una exploración rápida de datos. También simplifica el uso de comandos SQL comunes y avanzados utilizados en Spark SQL, incluido el registro de UDF para funcionalidad personalizada. Además, Athena Spark facilita el uso de Python en un entorno de cuaderno de inicio rápido para visualizar y analizar datos consultados a través de Spark SQL.
En general, Spark SQL desbloquea la capacidad de ir más allá del SQL estándar en Athena, proporcionando a los usuarios avanzados más flexibilidad y potencia a través de SQL y Python en un único portátil integrado, y proporcionando un análisis de datos rápido y complejo en Amazon S3 sin configuración de infraestructura. Para obtener más información sobre Athena Spark, consulte Amazon Athena para Apache Spark.
Acerca de los autores
 Patik Shah es arquitecto sénior de análisis en Amazon Athena. Se unió a AWS en 2015 y desde entonces se ha centrado en el espacio de análisis de big data, ayudando a los clientes a crear soluciones escalables y sólidas utilizando los servicios de análisis de AWS.
Patik Shah es arquitecto sénior de análisis en Amazon Athena. Se unió a AWS en 2015 y desde entonces se ha centrado en el espacio de análisis de big data, ayudando a los clientes a crear soluciones escalables y sólidas utilizando los servicios de análisis de AWS.
 Raj Devnath es gerente de producto en AWS en Amazon Athena. Le apasiona crear productos que los clientes adoren y ayudarlos a extraer valor de sus datos. Su experiencia se centra en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, domótica y sistemas de comunicación de datos.
Raj Devnath es gerente de producto en AWS en Amazon Athena. Le apasiona crear productos que los clientes adoren y ayudarlos a extraer valor de sus datos. Su experiencia se centra en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, domótica y sistemas de comunicación de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/run-spark-sql-on-amazon-athena-spark/

