Amazon SageMaker Puntos finales multimodelo (MME) son una capacidad totalmente administrada de inferencia de SageMaker que le permite implementar miles de modelos en un único punto final. Anteriormente, las MME asignaban de forma predeterminada la potencia de cálculo de la CPU a los modelos de forma estática, independientemente de la carga de tráfico del modelo, utilizando Servidor multimodelo (MMS) como su servidor modelo. En esta publicación, analizamos una solución en la que una MME puede ajustar dinámicamente la potencia de cálculo asignada a cada modelo en función del patrón de tráfico del modelo. Esta solución le permite utilizar la computación subyacente de MME de manera más eficiente y ahorrar costos.
Las MME cargan y descargan modelos dinámicamente en función del tráfico entrante al punto final. Cuando se utiliza MMS como servidor modelo, las MME asignan una cantidad fija de trabajadores modelo para cada modelo. Para obtener más información, consulte Patrones de hospedaje de modelos en Amazon SageMaker, Parte 3: Ejecute y optimice la inferencia de varios modelos con puntos de enlace de varios modelos de Amazon SageMaker.
Sin embargo, esto puede generar algunos problemas cuando su patrón de tráfico es variable. Digamos que tiene uno o pocos modelos que reciben una gran cantidad de tráfico. Puede configurar MMS para asignar una gran cantidad de trabajadores para estos modelos, pero esto se asigna a todos los modelos detrás de MME porque es una configuración estática. Esto lleva a que una gran cantidad de trabajadores utilicen computación de hardware, incluso los modelos inactivos. Puede ocurrir el problema opuesto si establece un valor pequeño para el número de trabajadores. Los modelos populares no tendrán suficientes trabajadores en el nivel del servidor modelo para asignar adecuadamente suficiente hardware detrás del punto final para estos modelos. El problema principal es que es difícil permanecer independiente del patrón de tráfico si no puede escalar dinámicamente a sus trabajadores en el nivel del servidor modelo para asignar la cantidad necesaria de computación.
La solución que discutimos en esta publicación utiliza DJLSirviendo como servidor modelo, que puede ayudar a mitigar algunos de los problemas que analizamos y permitir el escalado por modelo y permitir que las MME sean independientes del patrón de tráfico.
arquitectura MME
SageMaker MME le permite implementar múltiples modelos detrás de un único punto final de inferencia que puede contener una o más instancias. Cada instancia está diseñada para cargar y servir múltiples modelos hasta su capacidad de memoria y CPU/GPU. Con esta arquitectura, una empresa de software como servicio (SaaS) puede romper el costo linealmente creciente de alojar múltiples modelos y lograr la reutilización de la infraestructura consistente con el modelo multiusuario aplicado en otras partes de la pila de aplicaciones. El siguiente diagrama ilustra esta arquitectura.
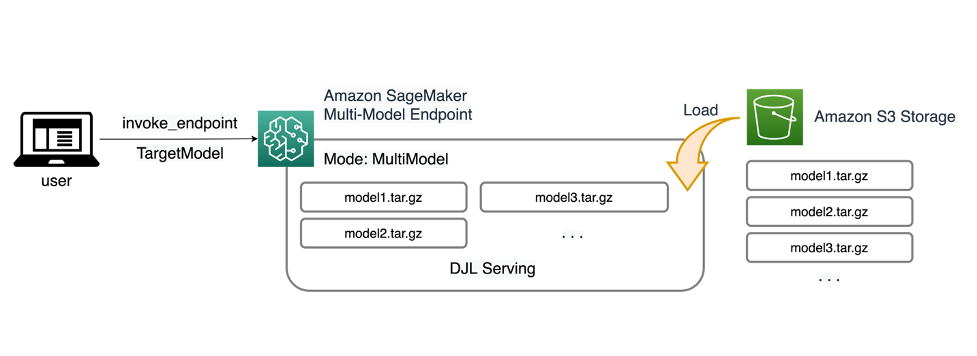
Un SageMaker MME carga dinámicamente modelos desde Servicio de almacenamiento simple de Amazon (Amazon S3) cuando se invoca, en lugar de descargar todos los modelos cuando se crea el punto final por primera vez. Como resultado, una invocación inicial a un modelo puede tener una latencia de inferencia más alta que las inferencias posteriores, que se completan con una latencia baja. Si el modelo ya está cargado en el contenedor cuando se invoca, entonces se omite el paso de descarga y el modelo devuelve las inferencias con baja latencia. Por ejemplo, supongamos que tiene un modelo que sólo se usa unas pocas veces al día. Se carga automáticamente según demanda, mientras que los modelos a los que se accede con frecuencia se retienen en la memoria y se invocan con una latencia constantemente baja.
Detrás de cada MME hay instancias de hospedaje modelo, como se muestra en el siguiente diagrama. Estas instancias cargan y desalojan múltiples modelos hacia y desde la memoria según los patrones de tráfico hacia los modelos.
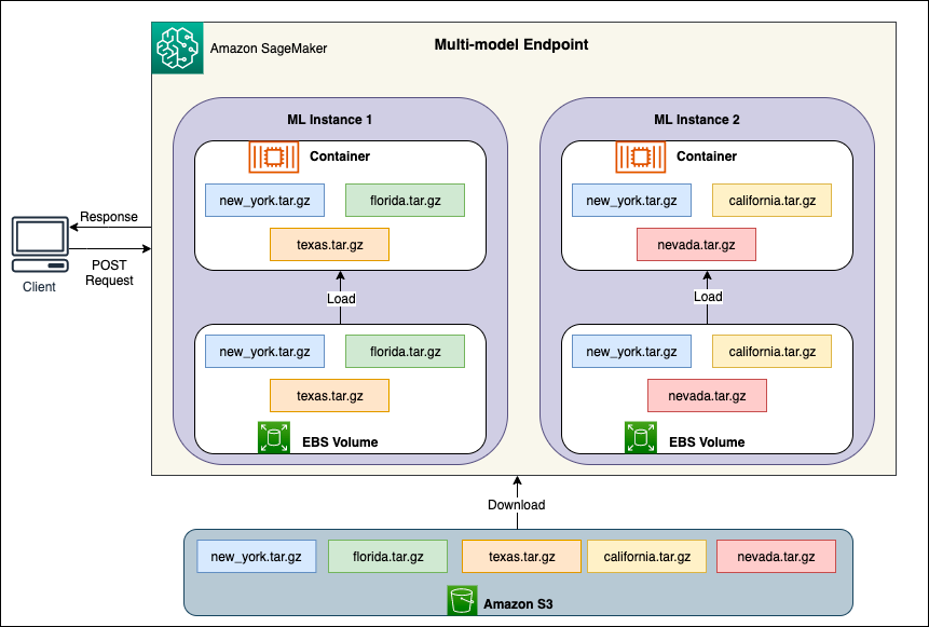
SageMaker continúa enrutando solicitudes de inferencia para un modelo a la instancia donde el modelo ya está cargado, de modo que las solicitudes se atiendan desde una copia del modelo en caché (consulte el siguiente diagrama, que muestra la ruta de solicitud para la primera solicitud de predicción versus la predicción en caché). ruta de solicitud). Sin embargo, si el modelo recibe muchas solicitudes de invocación y hay instancias adicionales para MME, SageMaker enruta algunas solicitudes a otra instancia para adaptarse al aumento. Para aprovechar el escalado de modelo automatizado en SageMaker, asegúrese de tener configuración de escalado automático de instancias para aprovisionar capacidad de instancia adicional. Configure su política de escalado a nivel de punto final con parámetros personalizados o invocaciones por minuto (recomendado) para agregar más instancias a la flota de puntos finales.

Descripción general del servidor de modelos
Un servidor de modelos es un componente de software que proporciona un entorno de ejecución para implementar y servir modelos de aprendizaje automático (ML). Actúa como una interfaz entre los modelos entrenados y las aplicaciones cliente que desean hacer predicciones utilizando esos modelos.
El objetivo principal de un servidor de modelos es permitir una integración sencilla y una implementación eficiente de modelos de aprendizaje automático en sistemas de producción. En lugar de integrar el modelo directamente en una aplicación o un marco específico, el servidor de modelos proporciona una plataforma centralizada donde se pueden implementar, administrar y servir múltiples modelos.
Los servidores de modelos suelen ofrecer las siguientes funcionalidades:
- Carga del modelo – El servidor carga los modelos de ML entrenados en la memoria, preparándolos para realizar predicciones.
- API de inferencia – El servidor expone una API que permite que las aplicaciones cliente envíen datos de entrada y reciban predicciones de los modelos implementados.
- Piel escamosa – Los servidores modelo están diseñados para manejar solicitudes simultáneas de múltiples clientes. Proporcionan mecanismos para el procesamiento paralelo y la gestión eficiente de recursos para garantizar un alto rendimiento y una baja latencia.
- Integración con motores backend – Los servidores de modelos tienen integraciones con marcos de backend como DeepSpeed y FasterTransformer para particionar modelos grandes y ejecutar inferencias altamente optimizadas.
arquitectura DJL
Servicio DJL es un servidor modelo universal, de código abierto y alto rendimiento. DJL Serving se basa en DJL, una biblioteca de aprendizaje profundo escrita en el lenguaje de programación Java. Puede tomar un modelo de aprendizaje profundo, varios modelos o flujos de trabajo y ponerlos a disposición a través de un punto final HTTP. DJL Serving admite la implementación de modelos de múltiples marcos como PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer y más.
DJL Serving ofrece muchas características que te permiten implementar tus modelos con alto rendimiento:
- Facilidad de uso – DJL Serving puede servir a la mayoría de los modelos listos para usar. Simplemente traiga los artefactos del modelo y DJL Serving podrá alojarlos.
- Soporte para múltiples dispositivos y aceleradores – DJL Serving admite la implementación de modelos en CPU, GPU y Inferencia de AWS.
- Rendimiento – DJL Serving ejecuta inferencia multiproceso en una única JVM para aumentar el rendimiento.
- Procesamiento por lotes dinámico – DJL Serving admite procesamiento por lotes dinámico para aumentar el rendimiento.
- Escalado automático – DJL Serving aumentará y reducirá automáticamente la escala de los trabajadores según la carga de tráfico.
- Soporte multimotor – DJL Serving puede alojar simultáneamente modelos utilizando diferentes marcos (como PyTorch y TensorFlow).
- Modelos de conjunto y flujo de trabajo. – DJL Serving admite la implementación de flujos de trabajo complejos compuestos por múltiples modelos y ejecuta partes del flujo de trabajo en la CPU y partes en la GPU. Los modelos dentro de un flujo de trabajo pueden utilizar diferentes marcos.
En particular, la función de escala automática de DJL Serving hace que sea sencillo garantizar que los modelos se escale adecuadamente para el tráfico entrante. De forma predeterminada, DJL Serving determina la cantidad máxima de trabajadores para un modelo que puede ser compatible según el hardware disponible (núcleos de CPU, dispositivos GPU). Puede establecer límites inferiores y superiores para cada modelo para asegurarse de que siempre se pueda atender un nivel de tráfico mínimo y que un solo modelo no consuma todos los recursos disponibles.
DJL Serving utiliza un Netty frontend encima de los grupos de subprocesos de los trabajadores backend. La interfaz utiliza una única configuración de Netty con múltiples Controladores de solicitudes Http. Diferentes manejadores de solicitudes brindarán soporte para la API de inferencia, API de administraciónu otras API disponibles en varios complementos.
El backend se basa en el Administrador de carga de trabajo (WLM) módulo. WLM se encarga de múltiples subprocesos de trabajo para cada modelo junto con el procesamiento por lotes y el enrutamiento de solicitudes hacia ellos. Cuando se sirven varios modelos, WLM comprueba primero el tamaño de la cola de solicitudes de inferencia de cada modelo. Si el tamaño de la cola es mayor que dos veces el tamaño del lote de un modelo, WLM aumenta la cantidad de trabajadores asignados a ese modelo.
Resumen de la solución
La implementación de DJL con un MME difiere de la configuración predeterminada de MMS. Para DJL Serving con un MME, comprimimos los siguientes archivos en el formato model.tar.gz que espera SageMaker Inference:
- modelo.joblib – Para esta implementación, insertamos directamente los metadatos del modelo en el tarball. En este caso estamos trabajando con un
.joblibarchivo, por lo que proporcionamos ese archivo en nuestro archivo tar para que lo lea nuestro script de inferencia. Si el artefacto es demasiado grande, también puede enviarlo a Amazon S3 y señalarlo en la configuración de servicio que defina para DJL. - sirviendo.propiedades – Aquí puedes configurar cualquier modelo relacionado con el servidor. Variables de entorno. El poder de DJL aquí es que puedes configurar
minWorkersymaxWorkerspara cada modelo tarball. Esto permite que cada modelo se amplíe y reduzca en el nivel del servidor de modelos. Por ejemplo, si un modelo singular recibe la mayor parte del tráfico de un MME, el servidor del modelo ampliará los trabajadores dinámicamente. En este ejemplo, no configuramos estas variables y dejamos que DJL determine la cantidad necesaria de trabajadores según nuestro patrón de tráfico. - modelo.py – Este es el script de inferencia para cualquier preprocesamiento o posprocesamiento personalizado que desee implementar. Model.py espera que su lógica esté encapsulada en un método de manejo de forma predeterminada.
- requisitos.txt (opcional) – De forma predeterminada, DJL viene instalado con PyTorch, pero cualquier dependencia adicional que necesites se puede enviar aquí.
Para este ejemplo, mostramos el poder de DJL con un MME tomando un modelo SKLearn de muestra. Realizamos un trabajo de entrenamiento con este modelo y luego creamos 1,000 copias de este artefacto de modelo para respaldar nuestro MME. Luego mostramos cómo DJL puede escalar dinámicamente para manejar cualquier tipo de patrón de tráfico que pueda recibir su MME. Esto puede incluir una distribución uniforme del tráfico en todos los modelos o incluso que unos pocos modelos populares reciban la mayor parte del tráfico. Puedes encontrar todo el código en el siguiente Repositorio GitHub.
Requisitos previos
Para este ejemplo, utilizamos una instancia de cuaderno de SageMaker con un kernel conda_python3 y una instancia ml.c5.xlarge. Para realizar las pruebas de carga, puede utilizar un Nube informática elástica de Amazon (Amazon EC2) o una instancia de cuaderno SageMaker más grande. En este ejemplo, escalamos a más de mil transacciones por segundo (TPS), por lo que sugerimos probar en una instancia EC2 más pesada, como ml.c5.18xlarge, para que tenga más computación con la que trabajar.
Crear un artefacto modelo
Primero necesitamos crear el artefacto y los datos de nuestro modelo que usaremos en este ejemplo. Para este caso, generamos algunos datos artificiales con NumPy y entrenamos usando un modelo de regresión lineal SKLearn con el siguiente fragmento de código:
Después de ejecutar el código anterior, debería tener un model.joblib archivo creado en su entorno local.
Extraiga la imagen de DJL Docker
La imagen de Docker djl-inference:0.23.0-cpu-full-v1.0 es nuestro contenedor de servicio DJL utilizado en este ejemplo. Puede ajustar la siguiente URL según su región:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Opcionalmente, también puede utilizar esta imagen como imagen base y ampliarla para crear su propia imagen de Docker en Registro de contenedores elásticos de Amazon (Amazon ECR) con cualquier otra dependencia que necesite.
Crear el archivo del modelo
Primero, creamos un archivo llamado serving.properties. Esto indica a DJLServing que utilice el motor Python. También definimos el max_idle_time de un trabajador es de 600 segundos. Esto garantiza que nos lleve más tiempo reducir la cantidad de trabajadores que tenemos por modelo. No nos ajustamos minWorkers y maxWorkers que podemos definir y dejamos que DJL calcule dinámicamente la cantidad de trabajadores necesarios dependiendo del tráfico que recibe cada modelo. Las propiedades de servicio se muestran a continuación. Para ver la lista completa de opciones de configuración, consulte Configuración del motor.
A continuación, creamos nuestro archivo model.py, que define la lógica de inferencia y carga del modelo. Para MME, cada archivo model.py es específico de un modelo. Los modelos se almacenan en sus propias rutas en la tienda de modelos (normalmente /opt/ml/model/). Al cargar modelos, se cargarán en la ruta de la tienda de modelos en su propio directorio. El ejemplo completo de model.py en esta demostración se puede ver en la Repositorio GitHub.
Creamos un model.tar.gz archivo que incluye nuestro modelo (model.joblib), model.pyy serving.properties:
Para fines de demostración, hacemos 1,000 copias del mismo. model.tar.gz archivo para representar la gran cantidad de modelos que se alojarán. En producción, es necesario crear un model.tar.gz archivo para cada uno de sus modelos.
Por último, cargamos estos modelos en Amazon S3.
Crear un modelo de SageMaker
Ahora creamos un modelo de SageMaker. Usamos la imagen ECR definida anteriormente y el artefacto del modelo del paso anterior para crear el modelo de SageMaker. En la configuración del modelo, configuramos el Modo como MultiModel. Esto le dice a DJLServing que estamos creando un MME.
Crear un punto final de SageMaker
En esta demostración, utilizamos 20 instancias ml.c5d.18xlarge para escalar a un TPS en el rango de miles. Asegúrese de obtener un aumento del límite en su tipo de instancia, si es necesario, para lograr el TPS al que se dirige.
Prueba de carga
Al momento de escribir este artículo, la herramienta de prueba de carga interna SageMaker Recomendador de inferencia de Amazon SageMaker no admite de forma nativa pruebas para MME. Por lo tanto, utilizamos la herramienta Python de código abierto. Langosta. Locust es sencillo de configurar y puede realizar un seguimiento de métricas como TPS y latencia de un extremo a otro. Para comprender completamente cómo configurarlo con SageMaker, consulte Prácticas recomendadas para pruebas de carga de puntos de enlace de inferencia en tiempo real de Amazon SageMaker.
En este caso de uso, tenemos tres patrones de tráfico diferentes que queremos simular con MME, por lo que tenemos los siguientes tres scripts de Python que se alinean con cada patrón. Nuestro objetivo aquí es demostrar que, independientemente de cuál sea nuestro patrón de tráfico, podemos lograr el mismo TPS objetivo y escalar adecuadamente.
Podemos especificar un peso en nuestro script Locust para asignar tráfico en diferentes partes de nuestros modelos. Por ejemplo, con nuestro modelo único, implementamos dos métodos de la siguiente manera:
Luego podemos asignar un peso determinado a cada método, que es cuando un determinado método recibe un porcentaje específico del tráfico:
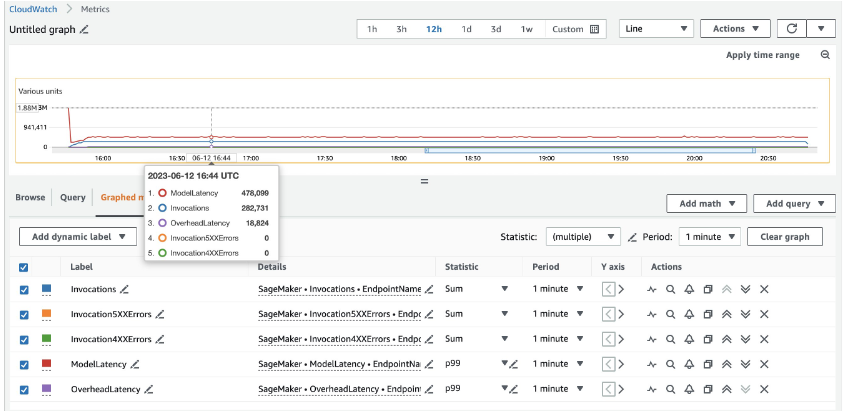
Para 20 instancias ml.c5d.18xlarge, vemos las siguientes métricas de invocación en el Reloj en la nube de Amazon consola. Estos valores siguen siendo bastante consistentes en los tres patrones de tráfico. Para comprender mejor las métricas de CloudWatch para la inferencia en tiempo real de SageMaker y MME, consulte Métricas de invocación de puntos finales de SageMaker.
Puedes encontrar el resto de los guiones de Locust en el directorio langosta-utils en el repositorio de GitHub.
Resumen
En esta publicación, analizamos cómo una MME puede ajustar dinámicamente la potencia informática asignada a cada modelo en función del patrón de tráfico del modelo. Esta característica recientemente lanzada está disponible en todas las regiones de AWS donde SageMaker está disponible. Tenga en cuenta que en el momento del anuncio, solo se admiten instancias de CPU. Para obtener más información, consulte Algoritmos, marcos e instancias compatibles.
Acerca de los autores
 Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
 qingweili es un especialista en aprendizaje automático en Amazon Web Services. Recibió su Ph.D. en Investigación de Operaciones después de que rompió la cuenta de subvenciones de investigación de su asesor y no pudo entregar el Premio Nobel que prometió. Actualmente, ayuda a los clientes de la industria de seguros y servicios financieros a crear soluciones de aprendizaje automático en AWS. En su tiempo libre le gusta leer y enseñar.
qingweili es un especialista en aprendizaje automático en Amazon Web Services. Recibió su Ph.D. en Investigación de Operaciones después de que rompió la cuenta de subvenciones de investigación de su asesor y no pudo entregar el Premio Nobel que prometió. Actualmente, ayuda a los clientes de la industria de seguros y servicios financieros a crear soluciones de aprendizaje automático en AWS. En su tiempo libre le gusta leer y enseñar.
 James Wu es un arquitecto de soluciones especialista en inteligencia artificial/aprendizaje automático sénior en AWS. ayudar a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de James cubre una amplia gama de casos de uso de ML, con un interés principal en la visión artificial, el aprendizaje profundo y la ampliación de ML en toda la empresa. Antes de unirse a AWS, James fue arquitecto, desarrollador y líder tecnológico durante más de 10 años, incluidos 6 años en ingeniería y 4 años en las industrias de marketing y publicidad.
James Wu es un arquitecto de soluciones especialista en inteligencia artificial/aprendizaje automático sénior en AWS. ayudar a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de James cubre una amplia gama de casos de uso de ML, con un interés principal en la visión artificial, el aprendizaje profundo y la ampliación de ML en toda la empresa. Antes de unirse a AWS, James fue arquitecto, desarrollador y líder tecnológico durante más de 10 años, incluidos 6 años en ingeniería y 4 años en las industrias de marketing y publicidad.
 Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
 Xu Deng es gerente de ingeniería de software en el equipo de SageMaker. Se centra en ayudar a los clientes a crear y optimizar su experiencia de inferencia de IA/ML en Amazon SageMaker. En su tiempo libre le encanta viajar y hacer snowboard.
Xu Deng es gerente de ingeniería de software en el equipo de SageMaker. Se centra en ayudar a los clientes a crear y optimizar su experiencia de inferencia de IA/ML en Amazon SageMaker. En su tiempo libre le encanta viajar y hacer snowboard.
 Siddharth Venkatesan es ingeniero de software en AWS Deep Learning. Actualmente se centra en la construcción de soluciones para la inferencia de modelos grandes. Antes de AWS, trabajó en la organización de Amazon Grocery creando nuevas funciones de pago para clientes de todo el mundo. Fuera del trabajo, le gusta esquiar, estar al aire libre y ver deportes.
Siddharth Venkatesan es ingeniero de software en AWS Deep Learning. Actualmente se centra en la construcción de soluciones para la inferencia de modelos grandes. Antes de AWS, trabajó en la organización de Amazon Grocery creando nuevas funciones de pago para clientes de todo el mundo. Fuera del trabajo, le gusta esquiar, estar al aire libre y ver deportes.
 Rohith Nallamaddi es ingeniero de desarrollo de software en AWS. Trabaja en la optimización de cargas de trabajo de aprendizaje profundo en GPU, creando inferencia de ML de alto rendimiento y soluciones de servicio. Antes de esto, trabajó en la creación de microservicios basados en AWS para el negocio de Amazon F3. Fuera del trabajo le gusta jugar y ver deportes.
Rohith Nallamaddi es ingeniero de desarrollo de software en AWS. Trabaja en la optimización de cargas de trabajo de aprendizaje profundo en GPU, creando inferencia de ML de alto rendimiento y soluciones de servicio. Antes de esto, trabajó en la creación de microservicios basados en AWS para el negocio de Amazon F3. Fuera del trabajo le gusta jugar y ver deportes.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

