Los modelos básicos (FM) son grandes modelos de aprendizaje automático (ML) entrenados en un amplio espectro de conjuntos de datos generalizados y sin etiquetar. Los FM, como sugiere el nombre, proporcionan la base para crear aplicaciones posteriores más especializadas y son únicos en su adaptabilidad. Pueden realizar una amplia gama de tareas diferentes, como el procesamiento del lenguaje natural, clasificar imágenes, pronosticar tendencias, analizar sentimientos y responder preguntas. Esta escala y adaptabilidad de propósito general son lo que diferencia a los FM de los modelos de ML tradicionales. Los FM son multimodales; Trabajan con diferentes tipos de datos como texto, video, audio e imágenes. Los modelos de lenguaje grande (LLM) son un tipo de FM y están previamente entrenados con grandes cantidades de datos de texto y, por lo general, tienen usos de aplicaciones como generación de texto, chatbots inteligentes o resúmenes.
La transmisión de datos facilita el flujo constante de información diversa y actualizada, mejorando la capacidad de los modelos para adaptarse y generar resultados más precisos y contextualmente relevantes. Esta integración dinámica de transmisión de datos permite IA generativa aplicaciones para responder rápidamente a las condiciones cambiantes, mejorando su adaptabilidad y rendimiento general en diversas tareas.
Para comprender mejor esto, imagine un chatbot que ayude a los viajeros a reservar sus viajes. En este escenario, el chatbot necesita acceso en tiempo real al inventario de las aerolíneas, el estado de los vuelos, el inventario de hoteles, los últimos cambios de precios y más. Estos datos generalmente provienen de terceros y los desarrolladores deben encontrar una manera de ingerir estos datos y procesar los cambios en los datos a medida que ocurren.
El procesamiento por lotes no es la mejor opción en este escenario. Cuando los datos cambian rápidamente, procesarlos en un lote puede provocar que el chatbot utilice datos obsoletos, lo que proporciona información inexacta al cliente, lo que afecta la experiencia general del cliente. Sin embargo, el procesamiento de flujo puede permitir que el chatbot acceda a datos en tiempo real y se adapte a los cambios en la disponibilidad y el precio, brindando la mejor orientación al cliente y mejorando la experiencia del cliente.
Otro ejemplo es una solución de monitorización y observabilidad impulsada por IA en la que los FM monitorean las métricas internas de un sistema en tiempo real y producen alertas. Cuando el modelo encuentra una anomalía o un valor métrico anormal, debe generar inmediatamente una alerta y notificar al operador. Sin embargo, el valor de datos tan importantes disminuye significativamente con el tiempo. Lo ideal es que estas notificaciones se reciban en segundos o incluso mientras sucede. Si los operadores reciben estas notificaciones minutos u horas después de que ocurrieron, dicha información no es procesable y potencialmente ha perdido su valor. Puede encontrar casos de uso similares en otras industrias, como la venta minorista, la fabricación de automóviles, la energía y la industria financiera.
En esta publicación, analizamos por qué la transmisión de datos es un componente crucial de las aplicaciones de IA generativa debido a su naturaleza en tiempo real. Discutimos el valor de los servicios de transmisión de datos de AWS, como Streaming administrado por Amazon para Apache Kafka (Amazon MSK), Secuencias de datos de Amazon Kinesis, Servicio administrado de Amazon para Apache Flinky Manguera de bomberos de datos de Amazon Kinesis en la creación de aplicaciones de IA generativa.
Aprendizaje en contexto
Los LLM están capacitados con datos de un momento determinado y no tienen la capacidad inherente de acceder a datos nuevos en el momento de la inferencia. A medida que aparecen nuevos datos, tendrás que ajustar o entrenar aún más el modelo continuamente. Esta no sólo es una operación costosa, sino también muy limitante en la práctica porque la velocidad de generación de nuevos datos supera con creces la velocidad del ajuste fino. Además, los LLM carecen de comprensión contextual y dependen únicamente de sus datos de entrenamiento y, por lo tanto, son propensos a sufrir alucinaciones. Esto significa que pueden generar una respuesta fluida, coherente y sintácticamente sólida, pero objetivamente incorrecta. También carecen de relevancia, personalización y contexto.
Los LLM, sin embargo, tienen la capacidad de aprender de los datos que reciben del contexto para responder con mayor precisión sin modificar las ponderaciones del modelo. Se llama aprendizaje en contextoy se puede utilizar para producir respuestas personalizadas o proporcionar una respuesta precisa en el contexto de las políticas de la organización.
Por ejemplo, en un chatbot, los eventos de datos podrían pertenecer a un inventario de vuelos y hoteles o cambios de precios que se incorporan constantemente a un motor de almacenamiento de transmisión. Además, los eventos de datos se filtran, enriquecen y transforman a un formato consumible mediante un procesador de flujo. El resultado se pone a disposición de la aplicación consultando la última instantánea. La instantánea se actualiza constantemente mediante el procesamiento de secuencias; por lo tanto, los datos actualizados se proporcionan en el contexto de una solicitud del usuario al modelo. Esto permite que el modelo se adapte a los últimos cambios de precio y disponibilidad. El siguiente diagrama ilustra un flujo de trabajo básico de aprendizaje en contexto.
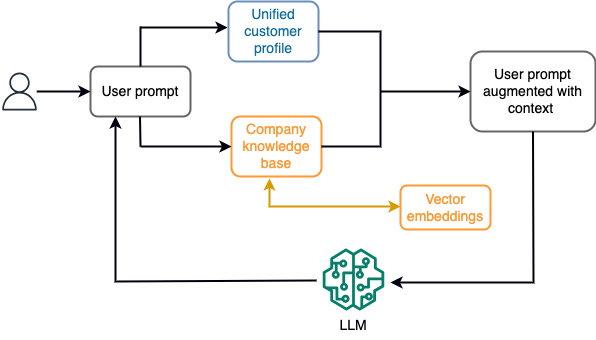
Un enfoque de aprendizaje en contexto comúnmente utilizado es utilizar una técnica llamada Generación Aumentada de Recuperación (RAG). En RAG, usted proporciona la información relevante, como la política más relevante y los registros de clientes, junto con la pregunta del usuario en el mensaje. De esta manera, el LLM genera una respuesta a la pregunta del usuario utilizando información adicional proporcionada como contexto. Para obtener más información sobre RAG, consulte Respuesta a preguntas mediante recuperación de generación aumentada con modelos básicos en Amazon SageMaker JumpStart.
Una aplicación de IA generativa basada en RAG solo puede producir respuestas genéricas basadas en sus datos de entrenamiento y los documentos relevantes en la base de conocimientos. Esta solución se queda corta cuando se espera una respuesta personalizada casi en tiempo real de la aplicación. Por ejemplo, se espera que un chatbot de viajes considere las reservas actuales del usuario, el inventario de hoteles y vuelos disponibles, y más. Además, los datos personales relevantes del cliente (comúnmente conocidos como perfil de cliente unificado) suele estar sujeto a cambios. Si se emplea un proceso por lotes para actualizar la base de datos del perfil de usuario de la IA generativa, el cliente puede recibir respuestas insatisfactorias basadas en datos antiguos.
En esta publicación, analizamos la aplicación del procesamiento de flujo para mejorar una solución RAG utilizada para crear agentes de respuesta a preguntas con contexto, desde acceso en tiempo real hasta perfiles de clientes unificados y una base de conocimiento organizacional.
Actualizaciones del perfil del cliente casi en tiempo real
Los registros de clientes normalmente se distribuyen entre almacenes de datos dentro de una organización. Para que su aplicación de IA generativa proporcione un perfil de cliente relevante, preciso y actualizado, es vital crear canales de transmisión de datos que puedan realizar la resolución de identidades y la agregación de perfiles en los almacenes de datos distribuidos. Los trabajos de transmisión ingieren constantemente nuevos datos para sincronizarlos entre sistemas y pueden realizar enriquecimiento, transformaciones, uniones y agregaciones en distintos períodos de tiempo de manera más eficiente. Los eventos de captura de datos de cambios (CDC) contienen información sobre el registro de origen, las actualizaciones y los metadatos, como la hora, el origen, la clasificación (insertar, actualizar o eliminar) y el iniciador del cambio.
El siguiente diagrama ilustra un flujo de trabajo de ejemplo para la ingesta y el procesamiento de streaming de CDC para perfiles de clientes unificados.

En esta sección, analizamos los componentes principales de un patrón de transmisión CDC necesarios para admitir aplicaciones de IA generativa basadas en RAG.
Ingestión de transmisión de CDC
Un replicador de CDC es un proceso que recopila cambios de datos de un sistema fuente (generalmente leyendo registros de transacciones o binlogs) y escribe eventos de CDC exactamente en el mismo orden en que ocurrieron en un flujo de datos o tema de transmisión. Esto implica una captura basada en registros con herramientas como Servicio de migración de bases de datos de AWS (AWS DMS) o conectores de código abierto como Debezium para Apache Kafka Connect. Apache Kafka Connect es parte del entorno Apache Kafka, lo que permite incorporar datos de diversas fuentes y entregarlos a una variedad de destinos. Puede ejecutar su conector Apache Kafka en Conexión de Amazon MSK en cuestión de minutos sin preocuparse por la configuración y el funcionamiento de un clúster Apache Kafka. Sólo necesita cargar el código compilado de su conector a Servicio de almacenamiento simple de Amazon (Amazon S3) y configure su conector con la configuración específica de su carga de trabajo.
También existen otros métodos para capturar cambios de datos. Por ejemplo, Amazon DynamoDB proporciona una función para transmitir datos CDC a Secuencias de Amazon DynamoDB o Kinesis Data Streams. Amazon S3 proporciona un activador para invocar un AWS Lambda funciona cuando se almacena un nuevo documento.
Almacenamiento de transmisión
El almacenamiento en streaming funciona como un búfer intermedio para almacenar eventos CDC antes de que se procesen. El almacenamiento de transmisión proporciona almacenamiento confiable para datos de transmisión. Por diseño, es altamente disponible y resistente a fallas de hardware o nodos y mantiene el orden de los eventos tal como se escriben. El almacenamiento en streaming puede almacenar eventos de datos de forma permanente o durante un período de tiempo determinado. Esto permite a los procesadores de flujo leer parte del flujo si hay una falla o es necesario volver a procesarlo. Kinesis Data Streams es un servicio de transmisión de datos sin servidor que facilita la captura, el procesamiento y el almacenamiento de flujos de datos a escala. Amazon MSK es un servicio totalmente administrado, de alta disponibilidad y seguro proporcionado por AWS para ejecutar Apache Kafka.
Procesamiento de flujo
Los sistemas de procesamiento de flujo deben diseñarse para que el paralelismo maneje un alto rendimiento de datos. Deben dividir el flujo de entrada entre múltiples tareas que se ejecutan en múltiples nodos informáticos. Las tareas deberían poder enviar el resultado de una operación a la siguiente a través de la red, haciendo posible procesar datos en paralelo mientras se realizan operaciones como uniones, filtrado, enriquecimiento y agregaciones. Las aplicaciones de procesamiento de flujo deberían poder procesar eventos con respecto a la hora del evento para casos de uso en los que los eventos podrían llegar tarde o el cálculo correcto depende de la hora en que ocurren los eventos en lugar de la hora del sistema. Para obtener más información, consulte Nociones de tiempo: tiempo de evento y tiempo de procesamiento.
Los procesos de flujo producen continuamente resultados en forma de eventos de datos que deben enviarse a un sistema de destino. Un sistema de destino podría ser cualquier sistema que pueda integrarse directamente con el proceso o mediante almacenamiento en streaming como intermediario. Dependiendo del marco que elija para el procesamiento de flujo, tendrá diferentes opciones para los sistemas de destino según los conectores receptores disponibles. Si decide escribir los resultados en un almacenamiento de transmisión intermediario, puede crear un proceso independiente que lea eventos y aplique cambios al sistema de destino, como ejecutar un conector receptor Apache Kafka. Independientemente de la opción que elija, los datos de los CDC necesitan un manejo adicional debido a su naturaleza. Dado que los eventos CDC transportan información sobre actualizaciones o eliminaciones, es importante que se combinen en el sistema de destino en el orden correcto. Si los cambios se aplican en el orden incorrecto, el sistema de destino no estará sincronizado con su origen.
Apache Flink es un potente marco de procesamiento de flujo conocido por su baja latencia y capacidades de alto rendimiento. Admite procesamiento de tiempo de eventos, semántica de procesamiento exactamente una vez y alta tolerancia a fallas. Además, proporciona soporte nativo para datos CDC a través de una estructura especial llamada tablas dinámicas. Las tablas dinámicas imitan las tablas de la base de datos de origen y proporcionan una representación en columnas de los datos de transmisión. Los datos de las tablas dinámicas cambian con cada evento que se procesa. Se pueden agregar, actualizar o eliminar nuevos registros en cualquier momento. Las tablas dinámicas abstraen la lógica adicional que necesita implementar para cada operación de registro (insertar, actualizar, eliminar) por separado. Para obtener más información, consulte Tablas dinámicas.
Con Servicio administrado de Amazon para Apache Flink, puede ejecutar trabajos de Apache Flink e integrarlos con otros servicios de AWS. No hay servidores ni clústeres que administrar, y no hay infraestructura informática ni de almacenamiento que configurar.
Pegamento AWS es un servicio de extracción, transformación y carga (ETL) totalmente administrado, lo que significa que AWS maneja el aprovisionamiento, el escalado y el mantenimiento de la infraestructura por usted. Aunque es conocido principalmente por sus capacidades ETL, AWS Glue también se puede utilizar para aplicaciones de transmisión Spark. AWS Glue puede interactuar con servicios de transmisión de datos como Kinesis Data Streams y Amazon MSK para procesar y transformar datos CDC. AWS Glue también puede integrarse perfectamente con otros servicios de AWS como Lambda, Funciones de paso de AWSy DynamoDB, que le brindan un ecosistema integral para crear y administrar canales de procesamiento de datos.
Perfil de cliente unificado
Superar la unificación del perfil del cliente en una variedad de sistemas fuente requiere el desarrollo de canales de datos sólidos. Necesita canalizaciones de datos que puedan reunir y sincronizar todos los registros en un solo almacén de datos. Este almacén de datos proporciona a su organización la vista holística de los registros de clientes que se necesita para la eficiencia operativa de las aplicaciones de IA generativa basadas en RAG. Para construir un almacén de datos de este tipo, lo mejor sería un almacén de datos no estructurados.
Un gráfico de identidad es una estructura útil para crear un perfil de cliente unificado porque consolida e integra datos de clientes de diversas fuentes, garantiza la precisión y la deduplicación de los datos, ofrece actualizaciones en tiempo real, conecta conocimientos entre sistemas, permite la personalización, mejora la experiencia del cliente y apoya el cumplimiento normativo. Este perfil de cliente unificado permite que la aplicación de IA generativa comprenda e interactúe con los clientes de manera efectiva y cumpla con las regulaciones de privacidad de datos, lo que en última instancia mejora las experiencias de los clientes e impulsa el crecimiento empresarial. Puede crear su solución de gráfico de identidad utilizando Amazonas Neptuno, un servicio de base de datos de gráficos rápido, confiable y totalmente administrado.
AWS ofrece algunas otras ofertas de servicios de almacenamiento NoSQL administrados y sin servidor para objetos clave-valor no estructurados. Amazon DocumentDB (con compatibilidad con MongoDB) es una empresa rápida, escalable, de alta disponibilidad y totalmente administrada base de datos de documentos servicio que admite cargas de trabajo JSON nativas. DynamoDB es un servicio de base de datos NoSQL totalmente administrado que proporciona un rendimiento rápido y predecible con una escalabilidad perfecta.
Actualizaciones de la base de conocimientos organizacionales casi en tiempo real
Al igual que los registros de clientes, los repositorios de conocimientos internos, como las políticas de la empresa y los documentos organizacionales, están aislados en todos los sistemas de almacenamiento. Por lo general, se trata de datos no estructurados y se actualizan de forma no incremental. El uso de datos no estructurados para aplicaciones de IA es eficaz mediante incrustaciones de vectores, que es una técnica para representar datos de alta dimensión, como archivos de texto, imágenes y archivos de audio, como números multidimensionales.
AWS proporciona varios servicios de motor vectorial, Tales como Amazon OpenSearch sin servidor, amazona kendray Edición compatible con Amazon Aurora PostgreSQL con la extensión pgvector para almacenar incrustaciones de vectores. Las aplicaciones de IA generativa pueden mejorar la experiencia del usuario transformando el mensaje del usuario en un vector y utilizándolo para consultar el motor de vectores para recuperar información contextualmente relevante. Tanto el mensaje como los datos vectoriales recuperados se pasan al LLM para recibir una respuesta más precisa y personalizada.
El siguiente diagrama ilustra un ejemplo de flujo de trabajo de procesamiento de flujo para incrustaciones de vectores.
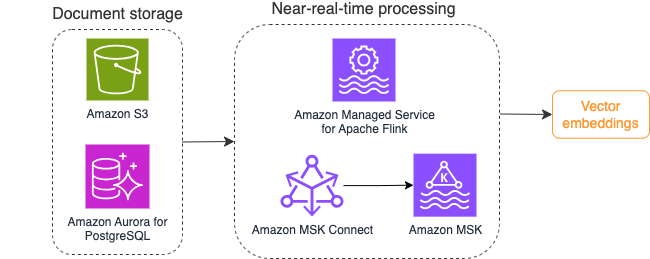
Los contenidos de la base de conocimientos deben convertirse en incrustaciones de vectores antes de escribirse en el almacén de datos vectoriales. lecho rocoso del amazonas or Amazon SageMaker puede ayudarle a acceder al modelo de su elección y exponer un punto final privado para esta conversión. Además, puede utilizar bibliotecas como LangChain para integrarse con estos puntos finales. Crear un proceso por lotes puede ayudarle a convertir el contenido de su base de conocimientos en datos vectoriales y almacenarlos inicialmente en una base de datos vectorial. Sin embargo, debe confiar en un intervalo para reprocesar los documentos y sincronizar su base de datos vectorial con los cambios en el contenido de su base de conocimientos. Con una gran cantidad de documentos, este proceso puede resultar ineficiente. Entre estos intervalos, los usuarios de su aplicación de IA generativa recibirán respuestas de acuerdo con el contenido anterior o recibirán una respuesta inexacta porque el contenido nuevo aún no está vectorizado.
El procesamiento de flujo es una solución ideal para estos desafíos. Inicialmente produce eventos según los documentos existentes y monitorea aún más el sistema fuente y crea un evento de cambio de documento tan pronto como ocurren. Estos eventos se pueden almacenar en el almacenamiento de transmisión y esperar a ser procesados por un trabajo de transmisión. Un trabajo de transmisión lee estos eventos, carga el contenido del documento y transforma el contenido en una serie de tokens de palabras relacionados. Cada token se transforma aún más en datos vectoriales a través de una llamada API a un FM integrado. Los resultados se envían para su almacenamiento en el almacenamiento de vectores a través de un operador de sumidero.
Si utiliza Amazon S3 para almacenar sus documentos, puede crear una arquitectura de origen de eventos basada en activadores de cambio de objetos de S3 para Lambda. Una función Lambda puede crear un evento en el formato deseado y escribirlo en su almacenamiento de transmisión.
También puede utilizar Apache Flink para ejecutarlo como un trabajo de transmisión. Apache Flink proporciona el conector de origen nativo de FileSystem, que puede descubrir archivos existentes y leer su contenido inicialmente. Después de eso, puede monitorear continuamente su sistema de archivos en busca de archivos nuevos y capturar su contenido. El conector admite la lectura de un conjunto de archivos de sistemas de archivos distribuidos como Amazon S3 o HDFS con formato de texto sin formato, Avro, CSV, Parquet y más, y produce un registro de transmisión. Como servicio totalmente administrado, Managed Service para Apache Flink elimina la sobrecarga operativa de implementar y mantener trabajos de Flink, lo que le permite concentrarse en crear y escalar sus aplicaciones de transmisión. Con una integración perfecta en los servicios de transmisión de AWS, como Amazon MSK o Kinesis Data Streams, proporciona características como escalado automático, seguridad y resiliencia, proporcionando aplicaciones Flink confiables y eficientes para manejar datos de transmisión en tiempo real.
Según su preferencia de DevOps, puede elegir entre Kinesis Data Streams o Amazon MSK para almacenar los registros de transmisión. Kinesis Data Streams simplifica las complejidades de crear y administrar aplicaciones de transmisión de datos personalizadas, lo que le permite concentrarse en obtener información valiosa de sus datos en lugar del mantenimiento de la infraestructura. Los clientes que utilizan Apache Kafka a menudo optan por Amazon MSK debido a su sencillez, escalabilidad y confiabilidad a la hora de supervisar los clústeres de Apache Kafka dentro del entorno de AWS. Como servicio totalmente administrado, Amazon MSK asume las complejidades operativas asociadas con la implementación y el mantenimiento de clústeres de Apache Kafka, lo que le permite concentrarse en la construcción y expansión de sus aplicaciones de streaming.
Debido a que una integración de API RESTful se adapta a la naturaleza de este proceso, necesita un marco que admita un patrón de enriquecimiento con estado a través de llamadas de API RESTful para rastrear fallas y reintentar la solicitud fallida. Apache Flink nuevamente es un marco que puede realizar operaciones con estado a velocidad de memoria. Para comprender las mejores formas de realizar llamadas API a través de Apache Flink, consulte Patrones comunes de enriquecimiento de datos de transmisión en Amazon Kinesis Data Analytics para Apache Flink.
Apache Flink proporciona conectores receptores nativos para escribir datos en almacenes de datos vectoriales como Amazon Aurora para PostgreSQL con pgvector o Servicio Amazon OpenSearch con VectorDB. Como alternativa, puede organizar la salida del trabajo de Flink (datos vectorizados) en un tema de MSK o un flujo de datos de Kinesis. OpenSearch Service brinda soporte para la ingesta nativa de flujos de datos de Kinesis o temas de MSK. Para obtener más información, consulte Presentación de Amazon MSK como fuente para la ingestión de Amazon OpenSearch y Cargando datos de streaming desde Amazon Kinesis Data Streams.
Análisis de comentarios y ajuste
Es importante que los administradores de operaciones de datos y los desarrolladores de IA/ML obtengan información sobre el rendimiento de la aplicación de IA generativa y los FM en uso. Para lograrlo, necesita crear canales de datos que calculen datos importantes de indicadores clave de rendimiento (KPI) en función de los comentarios de los usuarios y una variedad de registros y métricas de aplicaciones. Esta información es útil para que las partes interesadas obtengan información en tiempo real sobre el rendimiento del FM, la aplicación y la satisfacción general del usuario sobre la calidad del soporte que reciben de su aplicación. También debe recopilar y almacenar el historial de conversaciones para ajustar aún más sus FM y mejorar su capacidad para realizar tareas específicas del dominio.
Este caso de uso encaja muy bien en el dominio del análisis de streaming. Su aplicación debe almacenar cada conversación en un almacenamiento de transmisión. Su aplicación puede solicitar a los usuarios su calificación de la precisión de cada respuesta y su satisfacción general. Estos datos pueden estar en un formato de elección binaria o en un texto de formato libre. Estos datos se pueden almacenar en un flujo de datos de Kinesis o en un tema MSK y procesarse para generar KPI en tiempo real. Puede poner a trabajar los FM para el análisis de sentimientos de los usuarios. Los FM pueden analizar cada respuesta y asignar una categoría de satisfacción del usuario.
La arquitectura de Apache Flink permite la agregación de datos complejos en períodos de tiempo. También proporciona soporte para consultas SQL sobre flujo de eventos de datos. Por lo tanto, al utilizar Apache Flink, puede analizar rápidamente las entradas sin procesar del usuario y generar KPI en tiempo real escribiendo consultas SQL familiares. Para obtener más información, consulte API de tabla y SQL.
Con Servicio administrado de Amazon para Apache Flink Studio, puede crear y ejecutar aplicaciones de procesamiento de flujo Apache Flink utilizando SQL, Python y Scala estándar en un cuaderno interactivo. Los portátiles Studio funcionan con Apache Zeppelin y utilizan Apache Flink como motor de procesamiento de secuencias. Los portátiles Studio combinan a la perfección estas tecnologías para hacer que los análisis avanzados de flujos de datos sean accesibles para desarrolladores de todos los conjuntos de habilidades. Con soporte para funciones definidas por el usuario (UDF), Apache Flink permite crear operadores personalizados para integrarlos con recursos externos como FM para realizar tareas complejas como el análisis de sentimientos. Puede utilizar las UDF para calcular varias métricas o enriquecer los datos sin procesar de los comentarios de los usuarios con información adicional, como la opinión de los usuarios. Para obtener más información sobre este patrón, consulte Abordar proactivamente las inquietudes de los clientes en tiempo real con GenAI, Flink, Apache Kafka y Kinesis.
Con Managed Service para Apache Flink Studio, puede implementar su computadora portátil Studio como un trabajo de transmisión con un solo clic. Puede utilizar conectores receptores nativos proporcionados por Apache Flink para enviar la salida al almacenamiento de su elección o organizarla en un flujo de datos de Kinesis o un tema de MSK. Desplazamiento al rojo de Amazon y OpenSearch Service son ideales para almacenar datos analíticos. Ambos motores brindan soporte de ingesta nativa desde Kinesis Data Streams y Amazon MSK a través de una canalización de transmisión separada a un lago de datos o almacén de datos para su análisis.
Amazon Redshift utiliza SQL para analizar datos estructurados y semiestructurados en almacenes y lagos de datos, utilizando hardware y aprendizaje automático diseñados por AWS para ofrecer la mejor relación precio-rendimiento a escala. OpenSearch Service ofrece capacidades de visualización impulsadas por OpenSearch Dashboards y Kibana (versiones 1.5 a 7.10).
Puede utilizar el resultado de dicho análisis combinado con los datos de las indicaciones del usuario para ajustar el FM cuando sea necesario. SageMaker es la forma más sencilla de ajustar sus FM. El uso de Amazon S3 con SageMaker proporciona una integración potente y perfecta para ajustar sus modelos. Amazon S3 sirve como una solución de almacenamiento de objetos escalable y duradera, que permite el almacenamiento y la recuperación sencillos de grandes conjuntos de datos, datos de entrenamiento y artefactos de modelos. SageMaker es un servicio de ML totalmente administrado que simplifica todo el ciclo de vida de ML. Al utilizar Amazon S3 como backend de almacenamiento para SageMaker, puede beneficiarse de la escalabilidad, confiabilidad y rentabilidad de Amazon S3, mientras lo integra perfectamente con las capacidades de capacitación e implementación de SageMaker. Esta combinación permite una gestión eficiente de los datos, facilita el desarrollo de modelos colaborativos y garantiza que los flujos de trabajo de ML sean optimizados y escalables, lo que en última instancia mejora la agilidad y el rendimiento generales del proceso de ML. Para obtener más información, consulte Ajuste Falcon 7B y otros LLM en Amazon SageMaker con @remote decorador.
Con un conector receptor del sistema de archivos, los trabajos de Apache Flink pueden entregar datos a Amazon S3 en archivos de formato abierto (como JSON, Avro, Parquet y más) como objetos de datos. Si prefiere administrar su lago de datos utilizando un marco de lago de datos transaccional (como Apache Hudi, Apache Iceberg o Delta Lake), todos estos marcos proporcionan un conector personalizado para Apache Flink. Para obtener más detalles, consulte Cree una canalización de fuente a lago de datos de baja latencia con Amazon MSK Connect, Apache Flink y Apache Hudi.
Resumen
Para una aplicación de IA generativa basada en un modelo RAG, es necesario considerar la posibilidad de crear dos sistemas de almacenamiento de datos y crear operaciones de datos que los mantengan actualizados con todos los sistemas de origen. Los trabajos por lotes tradicionales no son suficientes para procesar el tamaño y la diversidad de los datos que necesita para integrarse con su aplicación de IA generativa. Los retrasos en el procesamiento de los cambios en los sistemas fuente dan como resultado una respuesta inexacta y reducen la eficiencia de su aplicación de IA generativa. La transmisión de datos le permite ingerir datos de una variedad de bases de datos en varios sistemas. También le permite transformar, enriquecer, unir y agregar datos de muchas fuentes de manera eficiente y casi en tiempo real. La transmisión de datos proporciona una arquitectura de datos simplificada para recopilar y transformar las reacciones o comentarios de los usuarios en tiempo real sobre las respuestas de la aplicación, lo que le ayuda a entregar y almacenar los resultados en un lago de datos para ajustar el modelo. La transmisión de datos también le ayuda a optimizar los canales de datos al procesar solo los eventos de cambio, lo que le permite responder a los cambios de datos de manera más rápida y eficiente.
Aprenda más sobre Servicios de transmisión de datos de AWS y comience a crear su propia solución de transmisión de datos.
Acerca de los autores
 Alí Alemi es Arquitecto de Soluciones Especialista en Streaming en AWS. Ali asesora a los clientes de AWS con las mejores prácticas arquitectónicas y los ayuda a diseñar sistemas de datos analíticos en tiempo real que sean confiables, seguros, eficientes y rentables. Trabaja hacia atrás a partir de los casos de uso del cliente y diseña soluciones de datos para resolver sus problemas comerciales. Antes de unirse a AWS, Ali apoyó a varios clientes del sector público y socios consultores de AWS en su proceso de modernización de aplicaciones y migración a la nube.
Alí Alemi es Arquitecto de Soluciones Especialista en Streaming en AWS. Ali asesora a los clientes de AWS con las mejores prácticas arquitectónicas y los ayuda a diseñar sistemas de datos analíticos en tiempo real que sean confiables, seguros, eficientes y rentables. Trabaja hacia atrás a partir de los casos de uso del cliente y diseña soluciones de datos para resolver sus problemas comerciales. Antes de unirse a AWS, Ali apoyó a varios clientes del sector público y socios consultores de AWS en su proceso de modernización de aplicaciones y migración a la nube.
 Imtiaz (Taz) Sayed es el líder tecnológico mundial en análisis de AWS. Le gusta interactuar con la comunidad en todo lo relacionado con datos y análisis. Se le puede contactar a través de Etiqueta LinkedIn.
Imtiaz (Taz) Sayed es el líder tecnológico mundial en análisis de AWS. Le gusta interactuar con la comunidad en todo lo relacionado con datos y análisis. Se le puede contactar a través de Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

