Vivimos en una era en la que el modelo de aprendizaje automático está en su apogeo. En comparación con hace décadas, la mayoría de la gente nunca habría oído hablar de ChatGPT o la Inteligencia Artificial. Sin embargo, esos son los temas de los que la gente sigue hablando. ¿Por qué? Porque los valores dados son muy significativos en comparación con el esfuerzo.
El avance de la IA en los últimos años podría atribuirse a muchas cosas, pero una de ellas es el modelo de lenguaje grande (LLM). Muchas personas que utilizan IA de generación de texto funcionan con el modelo LLM; Por ejemplo, ChatGPT utiliza su modelo GPT. Como LLM es un tema importante, deberíamos aprender sobre él.
Este artículo analizará los modelos de lenguajes grandes en 3 niveles de dificultad, pero solo tocaremos algunos aspectos de los LLM. Solo nos diferenciaremos de una manera que permita a cada lector comprender qué es LLM. Con eso en mente, entremos en ello.
En el primer nivel, asumimos que el lector no sabe sobre LLM y puede que sepa un poco sobre el campo de la ciencia de datos/aprendizaje automático. Por lo tanto, presentaría brevemente la IA y el aprendizaje automático antes de pasar a los LLM.
Inteligencia artificial es la ciencia del desarrollo de programas informáticos inteligentes. Está destinado a que el programa realice tareas inteligentes que los humanos podrían realizar pero no tiene limitaciones en las necesidades biológicas humanas. Aprendizaje automático es un campo de la inteligencia artificial que se centra en estudios de generalización de datos con algoritmos estadísticos. En cierto modo, el aprendizaje automático intenta lograr la inteligencia artificial a través del estudio de datos para que el programa pueda realizar tareas de inteligencia sin instrucción.
Históricamente, el campo que se cruza entre la informática y la lingüística se llama Natural. Procesamiento del lenguaje campo. Este campo se refiere principalmente a cualquier actividad de procesamiento mecánico del texto humano, como por ejemplo documentos de texto. Anteriormente, este campo solo se limitaba al sistema basado en reglas, pero se hizo más amplio con la introducción de algoritmos avanzados semisupervisados y no supervisados que permiten que el modelo aprenda sin ninguna dirección. Uno de los modelos avanzados para hacer esto es el Modelo de Lenguaje.
El idioma modelo es un modelo probabilístico de PNL para realizar muchas tareas humanas como traducción, corrección gramatical y generación de texto. La forma antigua del modelo de lenguaje utiliza enfoques puramente estadísticos como el método de n-gramas, donde se supone que la probabilidad de la siguiente palabra depende sólo de los datos de tamaño fijo de la palabra anterior.
Sin embargo, la introducción de Red neuronal ha destronado el enfoque anterior. Una red neuronal artificial, o NN, es un programa informático que imita la estructura neuronal del cerebro humano. Es bueno utilizar el enfoque de red neuronal porque puede manejar el reconocimiento de patrones complejos a partir de datos de texto y manejar datos secuenciales como texto. Es por eso que el modelo de lenguaje actual generalmente se basa en NN.
Modelos de lenguaje grande, o LLM, son modelos de aprendizaje automático que aprenden de una gran cantidad de documentos de datos para realizar la generación de lenguaje de propósito general. Siguen siendo un modelo de lenguaje, pero la gran cantidad de parámetros aprendidos por NN hace que se consideren grandes. En términos sencillos, el modelo podría representar muy bien cómo escriben los humanos prediciendo muy bien las siguientes palabras a partir de las palabras de entrada dadas.
Ejemplos de tareas de LLM incluyen traducción de idiomas, chatbot automático, respuesta a preguntas y muchas más. A partir de cualquier secuencia de entrada de datos, el modelo podría identificar relaciones entre las palabras y generar resultados adecuados a partir de la instrucción.
Casi todos los productos de IA generativa que cuentan con algo que utiliza la generación de texto funcionan con LLM. Grandes productos como ChatGPT, Bard de Google y muchos más utilizan LLM como base de su producto.
El lector tiene conocimientos de ciencia de datos pero necesita aprender más sobre el LLM en este nivel. Como mínimo, el lector puede comprender los términos utilizados en el campo de los datos. En este nivel, profundizaríamos en la arquitectura base.
Como se explicó anteriormente, LLM es un modelo de red neuronal entrenado con cantidades masivas de datos de texto. Para comprender mejor este concepto, sería beneficioso comprender cómo funcionan las redes neuronales y el aprendizaje profundo.
En el nivel anterior explicamos que una neurona neuronal es un modelo que imita la estructura neuronal del cerebro humano. El elemento principal de la red neuronal son las neuronas, a menudo llamadas nodos. Para explicar mejor el concepto, consulte la arquitectura típica de la red neuronal en la imagen a continuación.
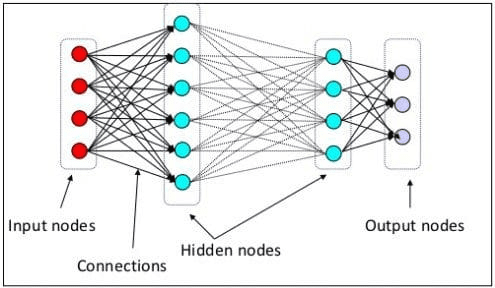
Arquitectura de red neuronal (fuente de la imagen: nuggets)
Como podemos ver en la imagen superior, la Red Neural consta de tres capas:
- Capa de entrada donde recibe la información y la transfiere a los demás nodos de la siguiente capa.
- Capas de nodos ocultos donde se realizan todos los cálculos.
- Capa de nodo de salida donde están las salidas computacionales.
Se llama aprendizaje profundo cuando entrenamos nuestro modelo de red neuronal con dos o más capas ocultas. Se llama profundo porque utiliza muchas capas intermedias. La ventaja de los modelos de aprendizaje profundo es que aprenden y extraen automáticamente características de los datos que los modelos tradicionales de aprendizaje automático son incapaces de hacer.
En el modelo de lenguaje grande, el aprendizaje profundo es importante ya que el modelo se basa en arquitecturas de redes neuronales profundas. Entonces, ¿por qué se llama LLM? Esto se debe a que miles de millones de capas se entrenan sobre cantidades masivas de datos de texto. Las capas producirían parámetros del modelo que ayudarían al modelo a aprender patrones complejos en el lenguaje, incluida la gramática, el estilo de escritura y muchos más.
El proceso simplificado de entrenamiento del modelo se muestra en la siguiente imagen.
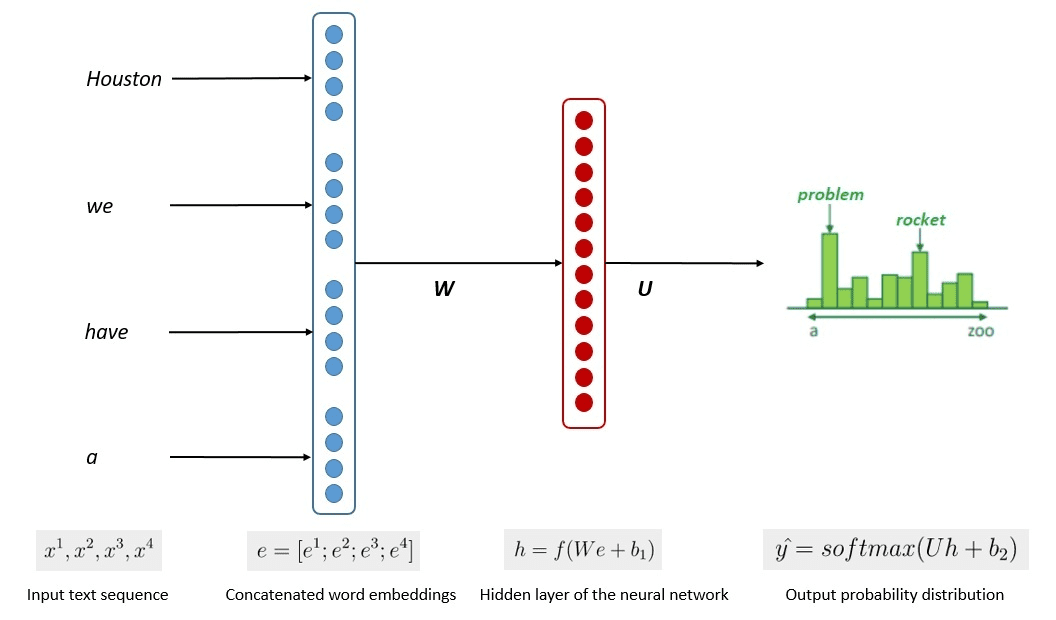
Imagen de Kumar Chandrakant (Fuente: Baeldung.com)
El proceso demostró que los modelos podían generar texto relevante en función de la probabilidad de cada palabra u oración de los datos de entrada. En los LLM, el enfoque avanzado utiliza aprendizaje auto supervisado y aprendizaje semi-supervisado para lograr la capacidad de propósito general.
El aprendizaje autosupervisado es una técnica en la que no tenemos etiquetas y, en cambio, los datos de entrenamiento proporcionan la retroalimentación del entrenamiento. Se utiliza en el proceso de formación de LLM ya que los datos normalmente carecen de etiquetas. En LLM, se podría utilizar el contexto circundante como pista para predecir las siguientes palabras. Por el contrario, el aprendizaje semisupervisado combina los conceptos de aprendizaje supervisado y no supervisado con una pequeña cantidad de datos etiquetados para generar nuevas etiquetas para una gran cantidad de datos no etiquetados. El aprendizaje semisupervisado se utiliza generalmente para LLM con necesidades de contexto o dominio específicos.
En el tercer nivel, discutiríamos el LLM más profundamente, abordando especialmente la estructura del LLM y cómo podría lograr una capacidad de generación similar a la humana.
Hemos comentado que LLM se basa en el modelo de Red Neural con técnicas de Deep Learning. El LLM generalmente se ha construido en base a basado en transformador arquitectura en los últimos años. El transformador se basa en el mecanismo de atención de múltiples cabezales introducido por Vaswani et al. (2017) y se ha utilizado en muchos LLM.
Transformers es una arquitectura modelo que intenta resolver las tareas secuenciales encontradas previamente en los RNN y LSTM. La antigua forma del modelo de lenguaje era usar RNN y LSTM para procesar datos secuencialmente, donde el modelo usaría cada palabra de salida y las repetiría para que el modelo no las olvidara. Sin embargo, tienen problemas con los datos de secuencia larga una vez que se introducen los transformadores.
Antes de profundizar en Transformers, quiero presentar el concepto de codificador-decodificador que se usaba anteriormente en RNN. La estructura codificador-decodificador permite que el texto de entrada y salida no tenga la misma longitud. El caso de uso de ejemplo es la traducción de un idioma, que a menudo tiene un tamaño de secuencia diferente.
La estructura se puede dividir en dos. La primera parte se llama Codificador, que es una parte que recibe una secuencia de datos y crea una nueva representación basada en ella. La representación se utilizaría en la segunda parte del modelo, que es el decodificador.
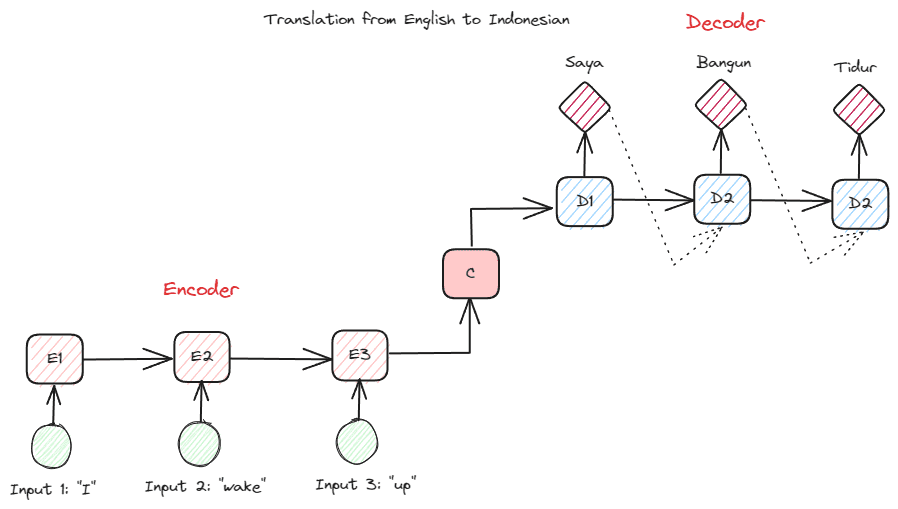
Imagen del autor
El problema con RNN es que el modelo podría necesitar ayuda para recordar secuencias más largas, incluso con la estructura codificador-decodificador anterior. Aquí es donde el mecanismo de atención podría ayudar a resolver el problema, una capa que podría resolver problemas de entrada largos. El mecanismo de atención es introducido en el artículo por Bahdanau et al. (2014) para resolver los RNN de tipo codificador-decodificador centrándose en una parte importante de la entrada del modelo mientras se tiene la predicción de salida.
La estructura del transformador está inspirada en el tipo codificador-decodificador y construida con técnicas de mecanismo de atención, por lo que no necesita procesar datos en orden secuencial. El modelo general de transformadores está estructurado como la imagen a continuación.

Arquitectura de transformadores (Vaswani et al. (2017))
En la estructura anterior, los transformadores codifican la secuencia del vector de datos en la incrustación de palabras mientras usan la decodificación para transformar los datos al formato original. La codificación puede asignar cierta importancia a la entrada con el mecanismo de atención.
Hemos hablado un poco de transformadores que codifican el vector de datos, pero ¿qué es un vector de datos? Discutamoslo. En el modelo de aprendizaje automático, no podemos ingresar los datos sin procesar del lenguaje natural en el modelo, por lo que debemos transformarlos en formas numéricas. El proceso de transformación se llama incrustación de palabras, donde cada palabra de entrada se procesa a través del modelo de incrustación de palabras para obtener el vector de datos. Podemos utilizar muchas incrustaciones de palabras iniciales, como palabra2vec or Guante, pero muchos usuarios avanzados intentan perfeccionarlos utilizando su vocabulario. De forma básica, el proceso de incrustación de palabras se puede mostrar en la siguiente imagen.
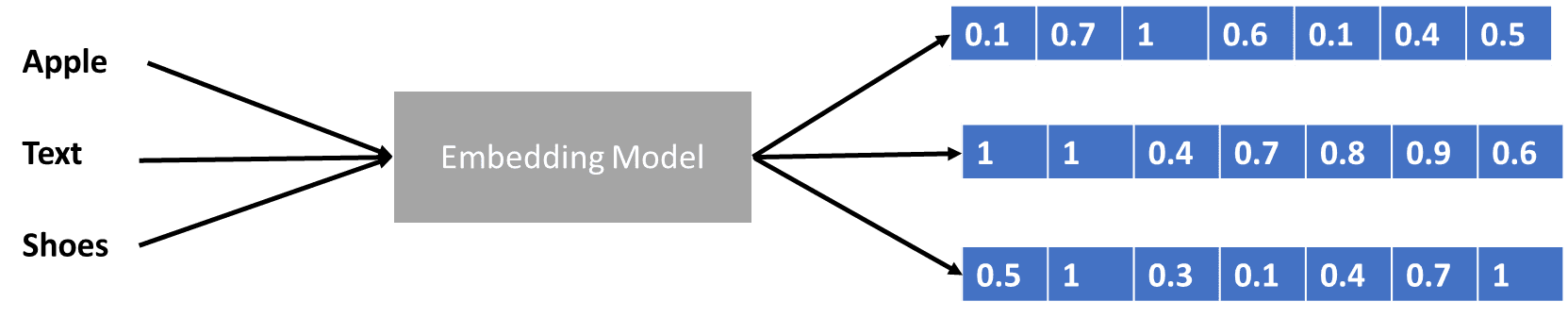
Imagen del autor
Los transformadores podrían aceptar la entrada y proporcionar un contexto más relevante presentando las palabras en formas numéricas como el vector de datos anterior. En los LLM, las incrustaciones de palabras suelen depender del contexto y generalmente se refinan según los casos de uso y el resultado previsto.
Discutimos el modelo de lenguaje grande en tres niveles de dificultad, desde principiante hasta avanzado. Desde el uso general de LLM hasta cómo está estructurado, puedes encontrar una explicación que explica el concepto con más detalle.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios de escritura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

