Introducción
Con la llegada de los modelos de lenguaje grandes (LLM), han permeado numerosas aplicaciones, reemplazando modelos de transformadores más pequeños como BERTI o modelos basados en reglas en muchos Procesamiento del lenguaje natural (PNL) tareas. Los LLM son versátiles y capaces de manejar tareas como clasificación de texto, resumen, análisis de sentimientos y modelado de temas, debido a su amplia capacitación previa. Sin embargo, a pesar de sus amplias capacidades, los LLM a menudo tienen desventajas en precisión en comparación con sus contrapartes más pequeñas.
Para abordar esta limitación, una estrategia eficaz es perfeccionar los LLM previamente capacitados para que sobresalgan en tareas específicas. El ajuste fino de modelos grandes con frecuencia produce resultados óptimos. En particular, Gemini de Google, entre otros modelos grandes, ahora ofrece a los usuarios la posibilidad de ajustar estos modelos con sus propios datos de entrenamiento. En esta guía, recorreremos el proceso de ajuste de los modelos Gemini para problemas específicos, así como también cómo seleccionar un conjunto de datos utilizando recursos de HuggingFace.
OBJETIVOS DE APRENDIZAJE
- Comprenda el rendimiento de los modelos Gemini de Google.
- Aprenda a preparar conjuntos de datos para el ajuste del modelo Gemini.
- Configure los parámetros para el ajuste fino del modelo Gemini.
- Supervise el progreso y las métricas de ajuste.
- Pruebe el rendimiento del modelo Gemini con nuevos datos.
- Explore las aplicaciones del modelo Gemini para enmascarar PII.

Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Google anuncia el ajuste de Gemini
Gemini viene en dos versiones: Pro y Ultra. En la versión Pro, están Gemini 1.0 Pro y el nuevo Gemini 1.5 Pro. Estos modelos de Google compiten con otros modelos avanzados como ChatGPT y Claude. Los modelos Gemini son de fácil acceso para todos a través de la interfaz de usuario de AI Studio y una API gratuita.
Recientemente, Google anunció una nueva función para los modelos Gemini: el ajuste. Esto significa que cualquiera puede ajustar el modelo Gemini a sus necesidades. Puede ajustar Gemini utilizando la interfaz de usuario de AI Studio o su API. El ajuste fino es cuando le damos nuestros propios datos a Gemini para que pueda comportarse como queremos. Google utiliza el ajuste eficiente de parámetros (PET) para ajustar rápidamente algunas partes importantes del modelo Gemini, haciéndolo útil para diferentes tareas.
Preparando el conjunto de datos
Antes de comenzar a ajustar el modelo, comenzaremos instalando las bibliotecas necesarias. Por cierto, trabajaremos con Colab para esta guía.
Instalación de bibliotecas necesarias
Los siguientes son los módulos de Python necesarios para comenzar:
!pip install -q google-generativeai datasets- google-generativeai: Se trata de una biblioteca del equipo de Google que nos permite acceder al Modelo Google Gemini. Se puede trabajar con la misma biblioteca para ajustar el modelo Gemini.
- conjuntos de datos: Esta es una biblioteca de HuggingFace con la que podemos trabajar para descargar una variedad de conjuntos de datos desde el centro de HuggingFace. Trabajaremos con esta biblioteca de conjuntos de datos para descargar el conjunto de datos PII (información de identificación personal) y entregárselo al modelo Gemini para su ajuste.
Al ejecutar el siguiente código, se descargará e instalará la IA generativa de Google y la biblioteca de conjuntos de datos en nuestro entorno Python.
Configuración de OAuth
En el siguiente paso, necesitamos configurar OAuth para este tutorial. El OAuth es necesario para que los datos que enviamos a Google para Fine-Tuning Gemini estén seguros. Para obtener OAuth sigue esto liga. Luego descargue client_secret.json después de crear OAuth. Guarde el contenido de client_secrent.json en Colab Secrets con el nombre CLIENT_SECRET y ejecute el siguiente código:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'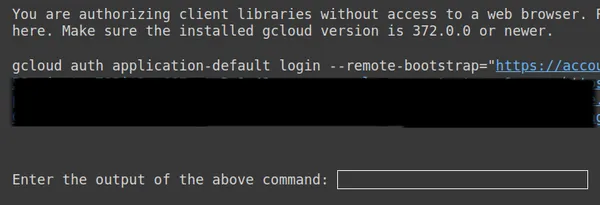
Arriba, copie el segundo enlace, péguelo en su sistema local CMD y ejecútelo.
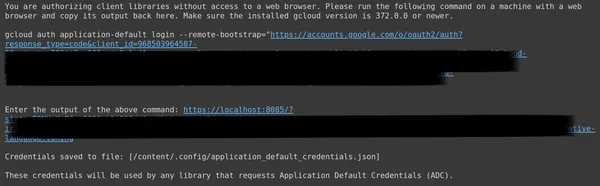
Luego, será redirigido al navegador web para iniciar sesión con el correo electrónico con el que configuró OAuth. Después de iniciar sesión, en CMD, obtenemos una URL, ahora pegue esa URL en la tercera línea y presione Intro. Ahora hemos terminado de realizar OAuth con Google.
Descarga y preparación del conjunto de datos
En primer lugar, comenzaremos descargando el conjunto de datos con el que trabajaremos para ajustarlo al modelo Gemini. Para ello, trabajamos con la biblioteca de conjuntos de datos. El código para esto será:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- Aquí comenzamos importando la función load_dataset de la biblioteca de conjuntos de datos.
- A esta función load_dataset(), le pasamos el conjunto de datos que deseamos descargar. Aquí, en nuestro ejemplo, es "ai4privacy/pii-masking-200k", que contiene 200 filas de datos PII enmascarados y desenmascarados.
- Luego imprimimos el conjunto de datos.

Vemos que el conjunto de datos contiene 209261 filas de datos de entrenamiento y ningún dato de prueba. Y cada fila contiene diferentes columnas como texto_enmascarado, texto_unmasked, máscara_privacidad, etiquetas_span, etiquetas_biográficas y texto_tokenizado. Los datos de muestra se mencionan a continuación:
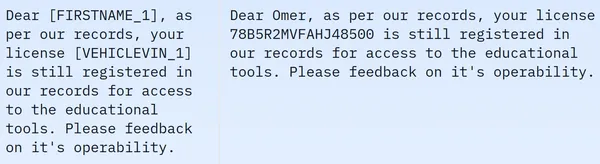
En la imagen mostrada observamos frases tanto enmascaradas como desenmascaradas. Específicamente, en la oración enmascarada, ciertos elementos como el nombre de la persona y el número del vehículo están ocultos por etiquetas específicas. Para preparar los datos para su posterior procesamiento, ahora necesitamos realizar algún preprocesamiento de datos. A continuación se muestra el código para este paso de preprocesamiento:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- En primer lugar, tomamos la parte de entrenamiento de los datos del conjunto de datos (el conjunto de datos que hemos descargado contiene solo la parte de entrenamiento). Luego convertimos esto a Pandas Dataframe.
- Aquí, para ajustar Gemini, solo necesitamos las columnas unmasked_text y masked_text, por lo que solo tomamos estas dos.
- Luego obtenemos las primeras 2000 filas de datos. Trabajaremos con las primeras 2000 filas para afinar Gemini.
- Luego editamos los nombres de las columnas de texto_enmascarado y texto_enmascarado a columnas de entrada y salida, porque, cuando damos los datos de texto de entrada que contienen la PII (información de identificación personal) al modelo Gemini, esperamos que genere los datos de texto de salida donde la PII está enmascarado.
Formateo de datos para ajustar Gemini
El siguiente paso es formatear nuestros datos. Para hacer esto, crearemos una función de formateo:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- Aquí definimos un formateador de funciones, que toma x, una fila de nuestros datos.
- Luego define un texto variable con cadenas f, donde proporcionamos el contexto, seguido de los datos de entrada del marco de datos.
- Finalmente, devolvemos el texto formateado.
- La última línea aplica la función de formateador a cada fila del marco de datos que hemos creado mediante la función apply().
- El eje = 1 indica que la función se aplicará a cada fila del marco de datos.
La ejecución del código dará como resultado la creación de una nueva columna llamada "entrenamiento" que contiene el texto formateado para cada fila, incluido el campo de entrada. Intentemos observar uno de los elementos del marco de datos:
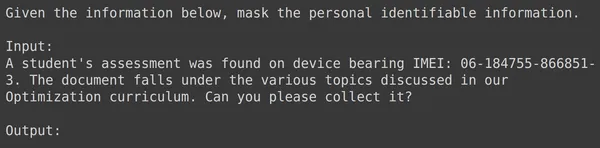
División de datos en conjuntos de entrenamiento y prueba
Podemos ver que text_input contiene los datos donde cada fila contiene el contexto al comienzo de los datos que indican enmascarar la PII y luego seguido de los datos de entrada y seguido de la palabra salida, donde el modelo necesita generar la salida. Ahora necesitamos dividir el marco de datos en entrenar y probar:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- Comenzamos filtrando los datos para que contengan las columnas text_input y salida. Estas son las columnas que espera la biblioteca Google Fine-Tune para entrenar a Géminis
- Gemini obtendrá text_input y aprenderá a escribir el resultado.
- Dividimos los datos en df_train que contiene las 1900 filas de nuestros datos originales.
- Y un df_test que contiene alrededor de 100 filas de los datos originales.
- Entrenamos a Gemini en df_train y luego lo probamos tomando 3-4 ejemplos de df_test para ver el resultado generado por él.
Entonces, ejecutar el código filtrará nuestros datos y los dividirá en entrenar y probar. Finalmente, hemos terminado con la parte de preprocesamiento de datos.
Afinando el modelo Géminis
Siga los pasos que se mencionan a continuación para ajustar su modelo Gemini:
Configuración de parámetros de ajuste
En esta sección, veremos el proceso de ajuste del modelo Gemini. Para esto trabajaremos con el siguiente código:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Importe la biblioteca google.generativeai: esta biblioteca proporciona API para interactuar con los servicios de IA generativa de Google.
- Proporcione el nombre del modelo base: este es el nombre del modelo previamente entrenado con el que queremos trabajar como punto de partida para nuestro modelo ajustado. En este momento, el único modelo ajustable es models/gemini-1.0-pro-001, lo almacenamos en la variable bm_name.
- Proporcione el nombre del modelo ajustado: este es el nombre que queremos darle a nuestro modelo ajustado. Aquí le damos el nombre de “modelo pii”.
- Crear un objeto de operación de modelo ajustado: este objeto representa la operación de creación de un modelo ajustado. Se necesitan los siguientes argumentos:
- source_model: El nombre del modelo base
- Training_data: los datos de entrenamiento para el modelo ajustado que acabamos de crear, que es df_train.
- id: El ID/nombre del modelo ajustado
- epoch_count: el número de épocas de entrenamiento. Para este ejemplo, usaremos 2 épocas.
- lote_size: el tamaño del lote para el entrenamiento. Para este ejemplo, usaremos el valor de 4.
- learning_rate: la tasa de aprendizaje para la capacitación. Aquí le proporcionamos un valor de 0.001.
- Hemos terminado de proporcionar los parámetros. La ejecución de este código creará un objeto modelo ajustado. Ahora necesitamos comenzar el proceso de formación del Gemini LLM. Para ello trabajamos con el siguiente código.
Hemos terminado de configurar los parámetros. La ejecución de este código creará un objeto modelo optimizado. Ahora necesitamos comenzar el proceso de formación del Gemini LLM. Para ello trabajamos con el siguiente código:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)Creando un modelo ajustado
Aquí, usamos la función .get_tuned_model() de la biblioteca genai, pasando el nombre de nuestro modelo definido, iniciando el proceso de entrenamiento. Luego, imprimimos el modelo, como se muestra en la siguiente imagen:
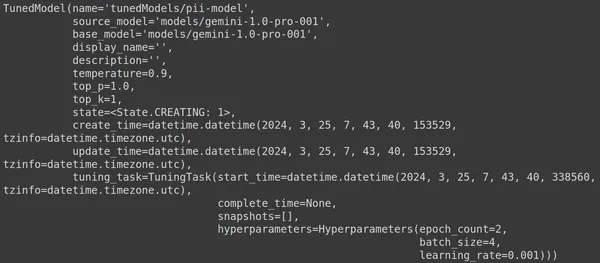
El modelo es de tipo TunedModel. Aquí podemos observar diferentes parámetros para el modelo que hemos definido. Ellos son:
- nombre: esta variable contiene el nombre que hemos proporcionado para nuestro modelo sintonizado
- source_model: Este es el modelo fuente que estamos afinando, que en nuestro ejemplo es models/gemini-1.0-pro
- base_model: Este es nuevamente el modelo base que estamos afinando, que en nuestro ejemplo es models/Gemini-1.0-pro. El modelo base puede incluso ser un modelo previamente ajustado. Aquí estamos igual para ambos.
- display_name: el nombre para mostrar del modelo sintonizado.
- descripción: Contiene cualquier descripción de nuestro modelo y de qué se trata el modelo.
- temperatura: cuanto mayor sea el valor, más creativas se generarán las respuestas a partir del modelo de lenguaje grande. Aquí está configurado en 0.9 por defecto.
- top_p: define la probabilidad máxima para la selección del token al generar texto. Cuanto más top_p se seleccionan más tokens, es decir, los tokens se seleccionan de una muestra más grande de datos.
- top_k: indica que se tomen muestras de los k tokens siguientes más probables en cada paso. Aquí top_k es 1, lo que implica que el siguiente token más probable es el que se seleccionará, es decir, siempre se seleccionará el token con mayor probabilidad.
- estado: El estado se está creando, implica que el modelo se está afinando actualmente.
- create_time: la hora en que se creó el modelo
- update_time: Es la hora en la que se ajustó el modelo por última vez.
- tuning_task: Contiene los parámetros que hemos definido para el ajuste, que incluyen temperatura, épocas y tamaño de lote.
Iniciando el proceso de capacitación
Incluso podemos obtener el estado y los metadatos del modelo sintonizado a través del siguiente código:
print(operation.metadata)
Aquí muestra el total de pasos, es decir 950, lo cual es predecible. Porque en nuestro ejemplo tenemos 1900 filas de datos de entrenamiento. En cada paso, tomamos un lote de 4, es decir, 4 filas, por lo que para una época completa tenemos 1900/4, es decir, 475 pasos. Hemos establecido 2 épocas para el entrenamiento, lo que implica que 2*475 = 950 pasos.
Monitoreo del progreso de la capacitación
El siguiente código crea una barra de estado que indica qué porcentaje de la capacitación ha finalizado y el tiempo que llevará completar todo el proceso de capacitación:
import time
for status in operation.wait_bar():
time.sleep(30)
El código anterior crea una barra de progreso, cuando se completa implica que nuestro proceso de ajuste ha finalizado.
Visualizando el rendimiento del entrenamiento
El objeto de operación incluso contiene instantáneas del entrenamiento. Que contendrá las métricas de evaluación como la pérdida media por época. Podemos visualizar esto con el siguiente código:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- Aquí obtenemos el modelo final ajustado de la operación.result()
- Cuando entrenamos el modelo, el modelo toma instantáneas a intervalos frecuentes. Estas instantáneas contienen datos como mean_loss. Por lo tanto, extraemos las instantáneas del modelo sintonizado llamando a model.tuning_task.snapshots.
- Creamos un marco de datos a partir de estas instantáneas pasándolas al pd.DataFrame y almacenándolas en la variable de instantáneas.
- Finalmente, creamos un diagrama de líneas a partir de los datos de la instantánea extraída.
Al ejecutar el código se obtendrá el siguiente gráfico:
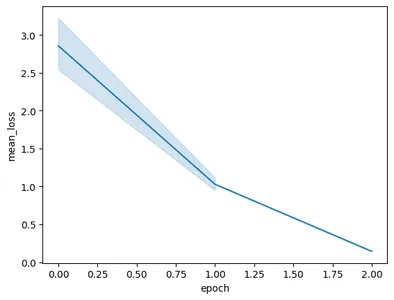
En esta imagen podemos ver que hemos reducido la pérdida de 3 a menos de 0.5 en sólo 2 épocas de entrenamiento. Finalmente, hemos terminado con el entrenamiento del Modelo Géminis.
Probando el modelo Géminis perfeccionado
En esta sección, probaremos nuestro modelo con los datos de prueba. Ahora para trabajar con el modelo sintonizado, trabajamos con el siguiente código:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')El código anterior cargará el modelo sintonizado que acabamos de entrenar con los datos de información de identificación personal. Ahora probaremos este modelo con algunos ejemplos de los datos de prueba que hemos reservado. Para esto, imprimamos la entrada de texto aleatoria y su salida correspondiente del conjunto de prueba:
print(df_test['text_input'][1900])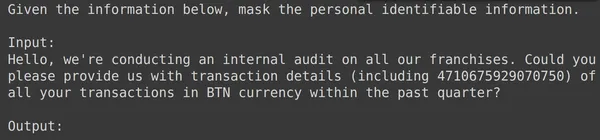
df_test['output'][1900]
Arriba podemos ver una entrada de texto aleatoria y la salida tomada del conjunto de prueba. Ahora pasaremos este text_input al modelo y observaremos el resultado generado:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
Vemos que el modelo logró enmascarar la información de identificación personal para el text_input dado y el resultado generado por el modelo coincide exactamente con el resultado del conjunto de prueba. Ahora probemos esto con algunos ejemplos más:
print(df_test['text_input'][1969])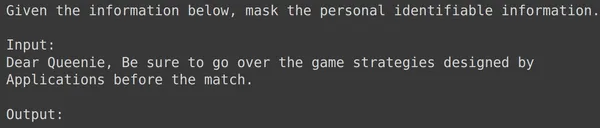
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])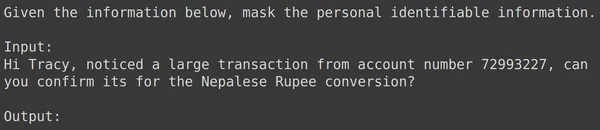
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])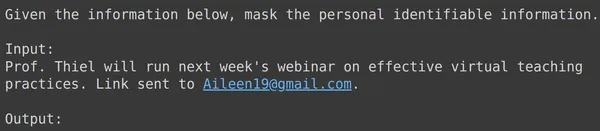
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
En todos los ejemplos anteriores, vemos que el rendimiento de nuestro modelo ajustado es bueno. El modelo pudo aprender de los datos de entrenamiento proporcionados y aplicar el enmascaramiento correctamente para ocultar información personal confidencial. Hemos visto de principio a fin cómo crear un conjunto de datos para realizar ajustes y cómo ajustar el modelo Gemini en un conjunto de datos y los resultados que vemos parecen muy prometedores para un modelo ajustado.
Conclusión
En conclusión, esta guía ha proporcionado un recorrido completo sobre cómo ajustar los modelos Gemini emblemáticos de Google para enmascarar información de identificación personal (PII). Comenzamos explorando la publicación del blog de Google sobre la capacidad de ajuste de los modelos Gemini, destacando la necesidad de ajustar estos modelos para lograr una precisión específica de la tarea. A través de los pasos prácticos descritos en la guía, incluida la preparación del conjunto de datos, el ajuste del modelo Gemini y la prueba de su rendimiento, los usuarios pueden aprovechar el poder de los modelos de lenguaje grandes para tareas de enmascaramiento de PII.
Estas son las conclusiones clave de esta guía:
- Los modelos Gemini proporcionan una potente biblioteca para realizar ajustes, lo que permite a los usuarios adaptarlos a tareas específicas, que incluyen el enmascaramiento de PII, mediante el ajuste eficiente de parámetros (PET).
- La preparación del conjunto de datos es un paso crucial, que implica la instalación de los módulos necesarios, el inicio de OAuth para la seguridad de los datos y el formateo de los datos para la capacitación.
- El proceso de ajuste incluye proporcionar parámetros como el modelo base, el recuento de épocas, el tamaño del lote y la tasa de aprendizaje para entrenar el modelo Gemini en el conjunto de datos preparado.
- El seguimiento del progreso del entrenamiento se facilita mediante actualizaciones de estado y visualizaciones de métricas como la pérdida media por época.
- Probar el modelo ajustado en un conjunto de datos de prueba separado verifica su desempeño para enmascarar con precisión la PII mientras se mantiene la integridad de los datos.
- Los ejemplos proporcionados muestran la eficacia del modelo Gemini perfeccionado para enmascarar con éxito información personal confidencial, lo que indica resultados prometedores para aplicaciones del mundo real.
Preguntas frecuentes
R. El ajuste eficiente de parámetros (PET) es una de las técnicas de ajuste que solo ajusta un pequeño conjunto de parámetros del modelo. Google emplea esto para ajustar rápidamente capas importantes en el modelo Gemini. Adapta eficientemente el modelo a los datos del usuario, mejorando su rendimiento para tareas específicas.
R. Ajustar un modelo Gemini implica proporcionar parámetros como el nombre del modelo base, el recuento de épocas, el tamaño del lote y la tasa de aprendizaje. Estos parámetros influyen en el proceso de entrenamiento y, en última instancia, afectan el rendimiento del modelo.
R. Los usuarios pueden monitorear el progreso del entrenamiento de un modelo Gemini ajustado a través de actualizaciones de estado, visualizaciones de métricas como la pérdida media por época y observando instantáneas del proceso de entrenamiento.
R. Antes de ajustar un modelo Gemini, los usuarios deben instalar las bibliotecas necesarias como google-generativeai y datasets. Además, iniciar OAuth para la seguridad de los datos y formatear el conjunto de datos para la capacitación son pasos importantes.
R. Se puede aplicar un modelo Gemini ajustado en diferentes dominios donde el enmascaramiento de PII es necesario, como la anonimización de datos, la preservación de la privacidad en aplicaciones de PNL y el cumplimiento de regulaciones de protección de datos como el RGPD.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

