Con la llegada de la IA generativa, los modelos básicos (FM) actuales, como los modelos de lenguaje grande (LLM) Claude 2 y Llama 2, pueden realizar una variedad de tareas generativas como respuesta a preguntas, resúmenes y creación de contenido en datos de texto. Sin embargo, los datos del mundo real existen en múltiples modalidades, como texto, imágenes, video y audio. Tomemos como ejemplo una presentación de diapositivas de PowerPoint. Podría contener información en forma de texto o incrustada en gráficos, tablas e imágenes.
En esta publicación, presentamos una solución que utiliza FM multimodales como el Incorporaciones multimodales de Amazon Titan modelo y LLaVA 1.5 y servicios de AWS, incluidos lecho rocoso del amazonas y Amazon SageMaker para realizar tareas generativas similares en datos multimodales.
Resumen de la solución
La solución proporciona una implementación para responder preguntas utilizando información contenida en el texto y elementos visuales de una presentación de diapositivas. El diseño se basa en el concepto de recuperación de generación aumentada (RAG). Tradicionalmente, RAG se ha asociado con datos textuales que pueden ser procesados por LLM. En esta publicación, ampliamos RAG para incluir también imágenes. Esto proporciona una poderosa capacidad de búsqueda para extraer contenido contextualmente relevante de elementos visuales como tablas y gráficos junto con texto.
Hay diferentes formas de diseñar una solución RAG que incluya imágenes. Hemos presentado un enfoque aquí y continuaremos con un enfoque alternativo en la segunda publicación de esta serie de tres partes.
Esta solución incluye los siguientes componentes:
- Modelo de incrustaciones multimodales de Amazon Titan – Este FM se utiliza para generar incrustaciones para el contenido en la plataforma de diapositivas utilizada en esta publicación. Como modelo multimodal, este modelo Titan puede procesar texto, imágenes o una combinación como entrada y generar incrustaciones. El modelo Titan Multimodal Embeddings genera vectores (incrustaciones) de 1,024 dimensiones y se accede a él a través de Amazon Bedrock.
- Asistente de Lenguaje y Visión Grande (LLaVA) – LLaVA es un modelo multimodal de código abierto para la comprensión visual y del lenguaje y se utiliza para interpretar los datos de las diapositivas, incluidos elementos visuales como gráficos y tablas. Usamos la versión de 7 mil millones de parámetros. LLaVA 1.5-7b en esta solución.
- Amazon SageMaker – El modelo LLaVA se implementa en un punto final de SageMaker utilizando los servicios de alojamiento de SageMaker y utilizamos el punto final resultante para ejecutar inferencias contra el modelo LLaVA. También utilizamos los cuadernos de SageMaker para organizar y demostrar esta solución de principio a fin.
- Amazon OpenSearch sin servidor – OpenSearch Serverless es una configuración sin servidor bajo demanda para Servicio Amazon OpenSearch. Utilizamos OpenSearch Serverless como base de datos vectorial para almacenar incrustaciones generadas por el modelo Titan Multimodal Embeddings. Un índice creado en la colección OpenSearch Serverless sirve como almacén de vectores para nuestra solución RAG.
- Ingestión de Amazon OpenSearch (OSI) – OSI es un recopilador de datos sin servidor totalmente administrado que entrega datos a los dominios del servicio OpenSearch y a las colecciones de OpenSearch Serverless. En esta publicación, utilizamos una canalización OSI para entregar datos al almacén de vectores OpenSearch Serverless.
Arquitectura de soluciones
El diseño de la solución consta de dos partes: ingesta e interacción del usuario. Durante la ingesta, procesamos la plataforma de diapositivas de entrada convirtiendo cada diapositiva en una imagen, generamos incrustaciones para estas imágenes y luego completamos el almacén de datos vectoriales. Estos pasos se completan antes de los pasos de interacción del usuario.
En la fase de interacción del usuario, una pregunta del usuario se convierte en incrustaciones y se ejecuta una búsqueda de similitud en la base de datos vectorial para encontrar una diapositiva que potencialmente podría contener respuestas a la pregunta del usuario. Luego proporcionamos esta diapositiva (en forma de archivo de imagen) al modelo LLaVA y a la pregunta del usuario como un mensaje para generar una respuesta a la consulta. Todo el código de esta publicación está disponible en el GitHub repositorio
El siguiente diagrama ilustra la arquitectura de ingesta.
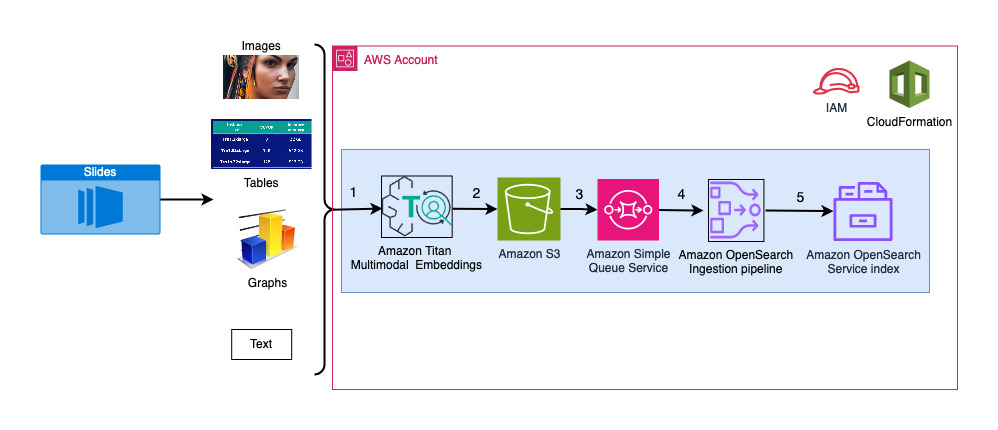
Los pasos del flujo de trabajo son los siguientes:
- Las diapositivas se convierten en archivos de imagen (uno por diapositiva) en formato JPG y se pasan al modelo Titan Multimodal Embeddings para generar incrustaciones. En esta publicación, utilizamos la plataforma de diapositivas titulada Entrene e implemente Stable Diffusion utilizando AWS Trainium y AWS Inferentia de la Cumbre de AWS en Toronto, junio de 2023, para demostrar la solución. La plataforma de muestra tiene 31 diapositivas, por lo que generamos 31 conjuntos de incrustaciones de vectores, cada uno con 1,024 dimensiones. Agregamos campos de metadatos adicionales a estas incrustaciones de vectores generados y creamos un archivo JSON. Estos campos de metadatos adicionales se pueden utilizar para realizar consultas de búsqueda enriquecidas utilizando las potentes capacidades de búsqueda de OpenSearch.
- Las incrustaciones generadas se reúnen en un único archivo JSON que se carga en Servicio de almacenamiento simple de Amazon (Amazon S3).
- Vía Notificaciones de eventos de Amazon S3, un evento se coloca en un Servicio de cola simple de Amazon (Amazon SQS).
- Este evento en la cola SQS actúa como un activador para ejecutar la canalización OSI, que a su vez ingiere los datos (archivo JSON) como documentos en el índice de OpenSearch Serverless. Tenga en cuenta que el índice de OpenSearch Serverless está configurado como receptor de esta canalización y se crea como parte de la colección de OpenSearch Serverless.
El siguiente diagrama ilustra la arquitectura de interacción del usuario.
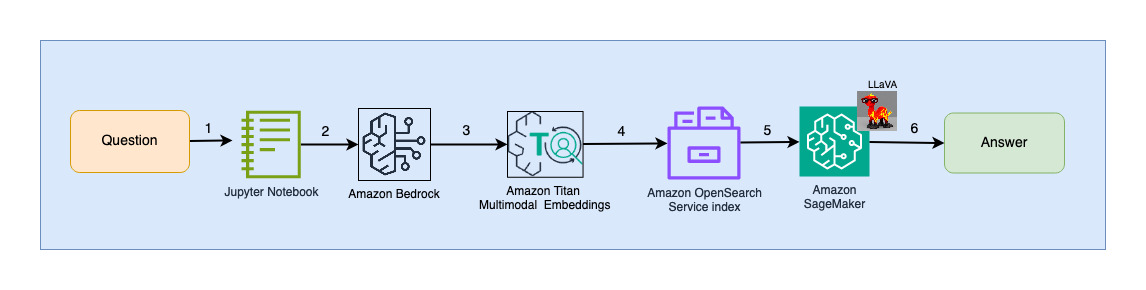
Los pasos del flujo de trabajo son los siguientes:
- Un usuario envía una pregunta relacionada con el conjunto de diapositivas que se ha ingerido.
- La entrada del usuario se convierte en incrustaciones utilizando el modelo Titan Multimodal Embeddings al que se accede a través de Amazon Bedrock. Se realiza una búsqueda vectorial OpenSearch utilizando estas incrustaciones. Realizamos una búsqueda de k vecinos más cercanos (k = 1) para recuperar la incrustación más relevante que coincida con la consulta del usuario. Al configurar k=1 se recupera la diapositiva más relevante para la pregunta del usuario.
- Los metadatos de la respuesta de OpenSearch Serverless contienen una ruta a la imagen correspondiente a la diapositiva más relevante.
- Se crea un mensaje combinando la pregunta del usuario y la ruta de la imagen y se proporciona a LLaVA alojado en SageMaker. El modelo LLaVA es capaz de comprender la pregunta del usuario y responderla examinando los datos de la imagen.
- El resultado de esta inferencia se devuelve al usuario.
Estos pasos se analizan en detalle en las siguientes secciones. Ver el Resultados sección para capturas de pantalla y detalles sobre el resultado.
Requisitos previos
Para implementar la solución provista en esta publicación, debe tener un Cuenta de AWS y familiaridad con FM, Amazon Bedrock, SageMaker y OpenSearch Service.
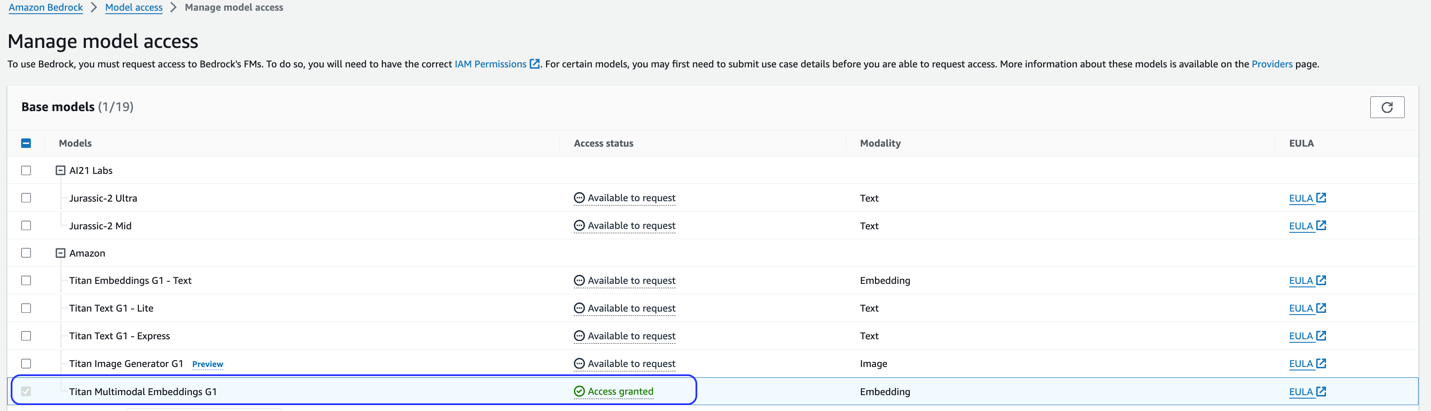
Esta solución utiliza el modelo Titan Multimodal Embeddings. Asegúrese de que este modelo esté habilitado para su uso en Amazon Bedrock. En la consola de Amazon Bedrock, elija Modelo de acceso en el panel de navegación. Si Titan Multimodal Embeddings está habilitado, el estado de acceso indicará Acceso permitido.
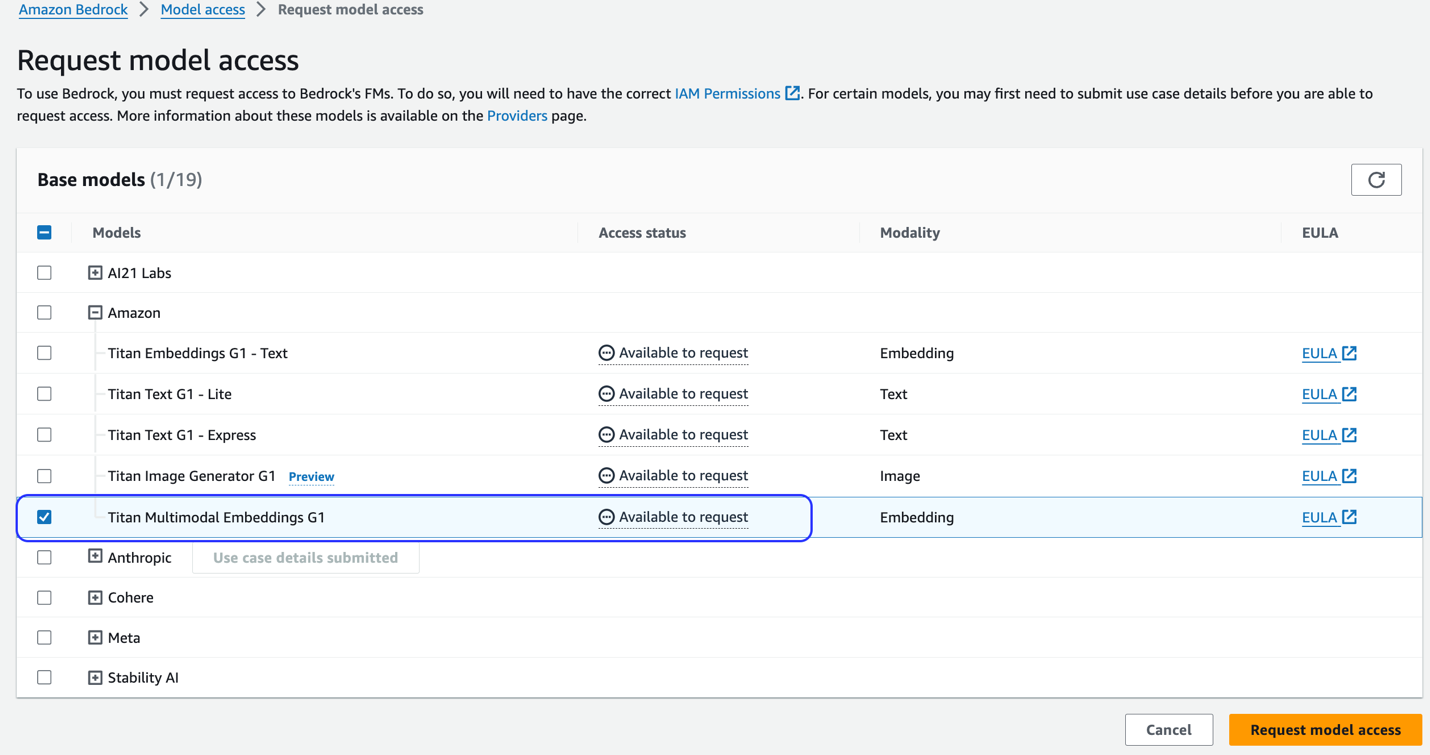
Si el modelo no está disponible, habilite el acceso al modelo eligiendo Administrar el acceso al modelo, Seleccionando Incrustaciones multimodales Titan G1y eligiendo Solicitar acceso al modelo. El modelo está habilitado para su uso inmediatamente.
Utilice una plantilla de AWS CloudFormation para crear la pila de soluciones
Utilice uno de los siguientes Formación en la nube de AWS plantillas (según su región) para lanzar los recursos de la solución.
| Región de AWS | Enlace |
|---|---|
us-east-1 |
|
us-west-2 |
Después de que la pila se haya creado correctamente, navegue hasta la página de la pila. Salidas pestaña en la consola de AWS CloudFormation y anote el valor de MultimodalCollectionEndpoint, que utilizamos en los pasos siguientes.
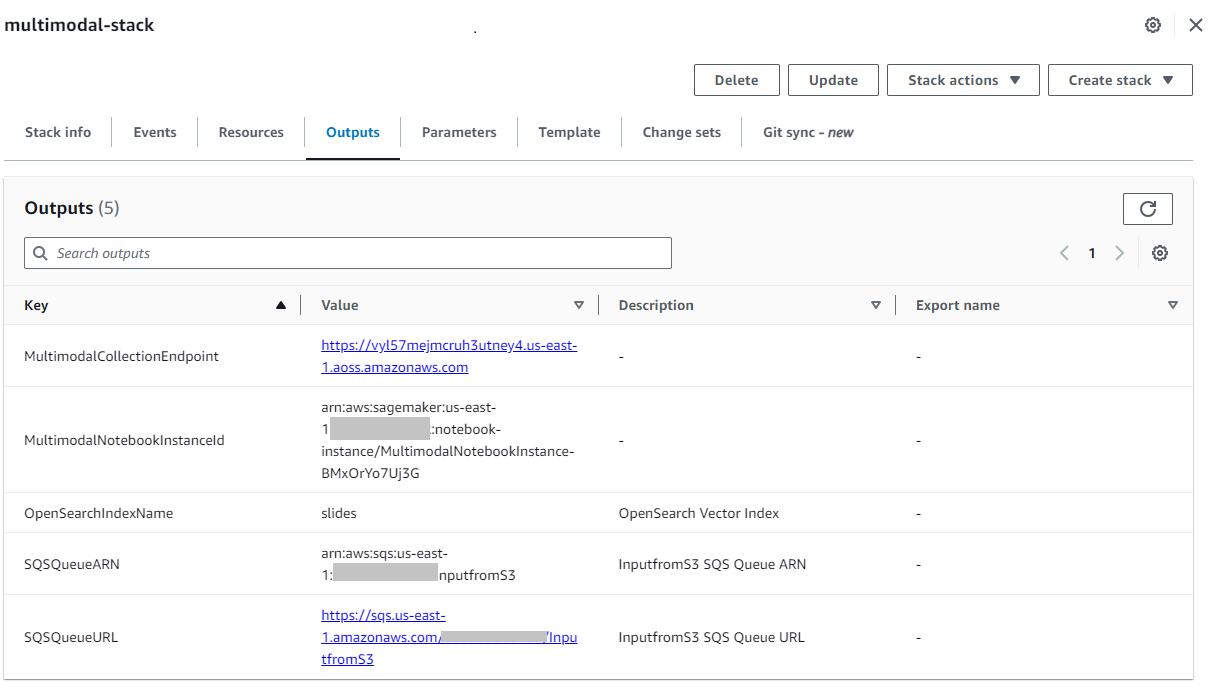
La plantilla de CloudFormation crea los siguientes recursos:
- IAM roles - La siguiente Gestión de identidades y accesos de AWS (IAM) se crean roles. Actualice estos roles para aplicar permisos de privilegios mínimos.
SMExecutionRolecon Amazon S3, SageMaker, OpenSearch Service y acceso completo a Bedrock.OSPipelineExecutionRolecon acceso a acciones específicas de Amazon SQS y OSI.
- Cuaderno SageMaker – Todo el código de esta publicación se ejecuta a través de este cuaderno.
- Colección sin servidor de OpenSearch – Esta es la base de datos vectorial para almacenar y recuperar incrustaciones.
- canalización OSI – Este es el canal para la ingesta de datos en OpenSearch Serverless.
- Cucharón S3 – Todos los datos de esta publicación se almacenan en este depósito.
- Cola SQS – Los eventos para desencadenar la ejecución de la canalización OSI se colocan en esta cola.
La plantilla de CloudFormation configura la canalización OSI con el procesamiento de Amazon S3 y Amazon SQS como origen y un índice OpenSearch Serverless como receptor. Cualquier objeto creado en el depósito S3 especificado y el prefijo (multimodal/osi-embeddings-json) activará notificaciones SQS, que utiliza la canalización OSI para ingerir datos en OpenSearch Serverless.
La plantilla de CloudFormation también crea del sistema,, cifradoy acceso a los datos políticas necesarias para la colección OpenSearch Serverless. Actualice estas políticas para aplicar permisos con privilegios mínimos.
Tenga en cuenta que en los cuadernos de SageMaker se hace referencia al nombre de la plantilla de CloudFormation. Si se cambia el nombre de la plantilla predeterminada, asegúrese de actualizar el mismo en globales.py
Prueba la solución
Una vez que se hayan completado los pasos previos y la pila de CloudFormation se haya creado correctamente, ya estará listo para probar la solución:
- En la consola de SageMaker, elija Cuadernos en el panel de navegación.
- Seleccione
MultimodalNotebookInstanceinstancia del cuaderno y elija Abrir JupyterLab.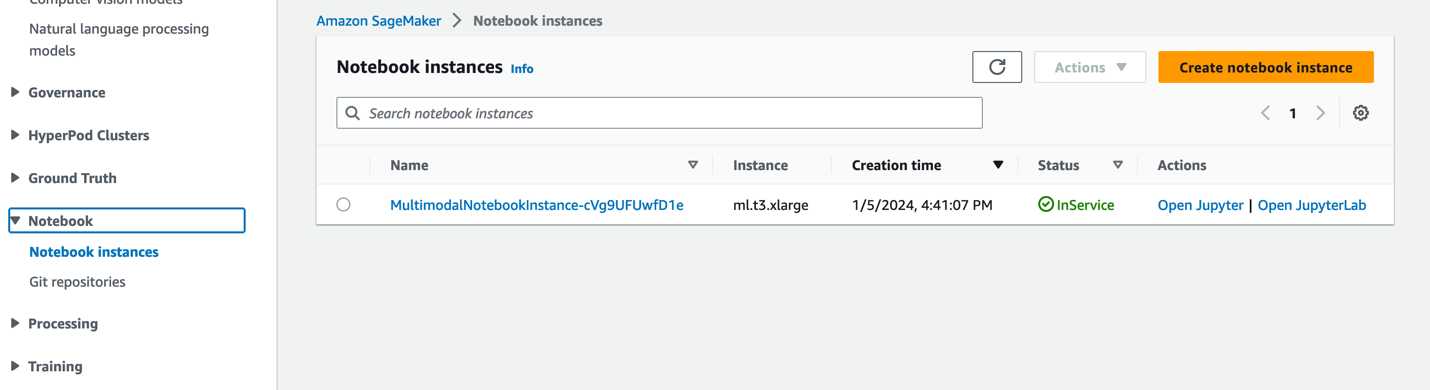
- In Explorador de archivos, vaya a la carpeta de cuadernos para ver los cuadernos y los archivos auxiliares.
Los cuadernos están numerados en la secuencia en la que se ejecutan. Las instrucciones y comentarios en cada cuaderno describen las acciones realizadas por ese cuaderno. Ejecutamos estos cuadernos uno por uno.
- Elige 0_deploy_llava.ipynb para abrirlo en JupyterLab.
- En Ejecutar menú, seleccione Ejecutar todas las celdas para ejecutar el código en este cuaderno.
Este cuaderno implementa el modelo LLaVA-v1.5-7B en un punto final de SageMaker. En este cuaderno, descargamos el modelo LLaVA-v1.5-7B de HuggingFace Hub, reemplazamos el script inference.py con llama_inferencia.pyy cree un archivo model.tar.gz para este modelo. El archivo model.tar.gz se carga en Amazon S3 y se utiliza para implementar el modelo en el punto final de SageMaker. El llama_inferencia.py El script tiene código adicional para permitir leer un archivo de imagen de Amazon S3 y ejecutar inferencias en él.
- Elige 1_data_prep.ipynb para abrirlo en JupyterLab.
- En Ejecutar menú, seleccione Ejecutar todas las celdas para ejecutar el código en este cuaderno.
Este cuaderno descarga el conjunto de diapositivas, convierte cada diapositiva en formato de archivo JPG y las carga en el depósito S3 utilizado para esta publicación.
- Elige 2_ingestión_de_datos.ipynb para abrirlo en JupyterLab.
- En Ejecutar menú, seleccione Ejecutar todas las celdas para ejecutar el código en este cuaderno.
Hacemos lo siguiente en este cuaderno:
- Creamos un índice en la colección OpenSearch Serverless. Este índice almacena los datos de incrustaciones para la plataforma de diapositivas. Vea el siguiente código:
- Usamos el modelo Titan Multimodal Embeddings para convertir las imágenes JPG creadas en el cuaderno anterior en incrustaciones vectoriales. Estas incrustaciones y metadatos adicionales (como la ruta S3 del archivo de imagen) se almacenan en un archivo JSON y se cargan en Amazon S3. Tenga en cuenta que se crea un único archivo JSON, que contiene documentos para todas las diapositivas (imágenes) convertidas en incrustaciones. El siguiente fragmento de código muestra cómo una imagen (en forma de cadena codificada en Base64) se convierte en incrustaciones:
- Esta acción activa la canalización de OpenSearch Ingestion, que procesa el archivo y lo ingiere en el índice de OpenSearch Serverless. El siguiente es un ejemplo del archivo JSON creado. (En el código de ejemplo se muestra un vector con cuatro dimensiones. El modelo Titan Multimodal Embeddings genera 1,024 dimensiones).
- Elige 3_rag_inference.ipynb para abrirlo en JupyterLab.
- En Ejecutar menú, seleccione Ejecutar todas las celdas para ejecutar el código en este cuaderno.
Este cuaderno implementa la solución RAG: convertimos la pregunta del usuario en incrustaciones, buscamos una imagen similar (diapositiva) de la base de datos de vectores y proporcionamos la imagen recuperada a LLaVA para generar una respuesta a la pregunta del usuario. Usamos la siguiente plantilla de aviso:
El siguiente fragmento de código proporciona el flujo de trabajo de RAG:
Resultados
La siguiente es una recopilación de algunas preguntas y respuestas de los usuarios generadas por nuestra implementación. El Pregunta La columna captura la pregunta del usuario y la Respuesta La columna es la respuesta textual generada por LLaVA. Imagen es la coincidencia de diapositivas k más cercana (k=1) devuelta por la búsqueda vectorial de OpenSearch Serverless. Esta diapositiva es interpretada por LLaVA para dar la respuesta.
Resultados RAG multimodales
| Pregunta | Respuesta | Imagen |
|---|---|---|
| ¿Cómo se compara el rendimiento de Inf2 con instancias EC2 comparables? Necesito números. | Según las diapositivas, las instancias Inf2 de AWS Inferentia2 ofrecen un rendimiento hasta 4 veces mayor y una latencia 10 veces menor en comparación con instancias EC2 comparables. |  |
| Según el volante AI/ML, ¿qué proporcionan los servicios AI/ML de AWS? | Los servicios de IA/ML de AWS brindan mejores capacidades de rentabilidad, nuevas capacidades e inversión en innovación. | 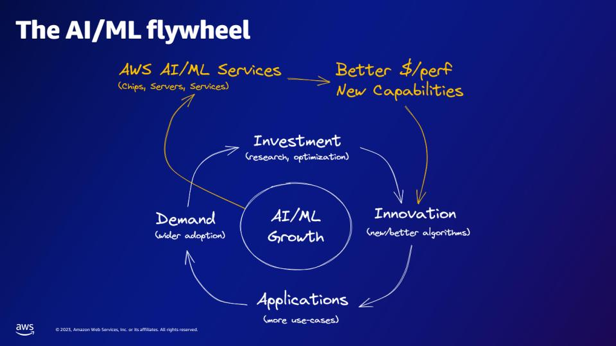 |
| En comparación con GPT-2, ¿cuántos parámetros más tiene GPT-3? ¿Cuál es la diferencia numérica entre el tamaño del parámetro de GPT-2 y GPT-3? | Según la diapositiva, GPT-3 tiene 175 mil millones de parámetros, mientras que GPT-2 tiene 1.5 mil millones de parámetros. La diferencia numérica entre el tamaño de los parámetros de GPT-2 y GPT-3 es 173.5 mil millones. | 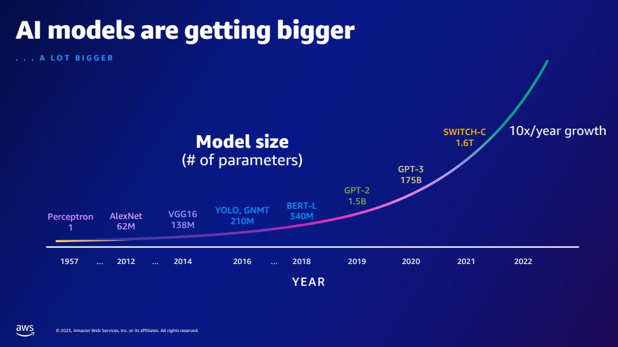 |
| ¿Qué son los quarks en la física de partículas? | No encontré la respuesta a esta pregunta en las diapositivas. |  |
No dude en ampliar esta solución a sus presentaciones de diapositivas. Simplemente actualice la variable SLIDE_DECK en globals.py con una URL a su presentación de diapositivas y ejecute los pasos de ingesta detallados en la sección anterior.
Consejo
Puede utilizar los paneles de OpenSearch para interactuar con la API de OpenSearch y ejecutar pruebas rápidas en su índice y datos ingeridos. La siguiente captura de pantalla muestra un ejemplo GET del panel de OpenSearch.
Limpiar
Para evitar incurrir en cargos futuros, elimine los recursos que creó. Puede hacerlo eliminando la pila a través de la consola de CloudFormation.

Además, elimine el punto final de inferencia de SageMaker creado para la inferencia de LLaVA. Puede hacer esto descomentando el paso de limpieza en 3_rag_inference.ipynb y ejecutando la celda, o eliminando el punto final a través de la consola de SageMaker: elija Inferencia y Endpoints en el panel de navegación, luego seleccione el punto final y elimínelo.
Conclusión
Las empresas generan contenido nuevo todo el tiempo y las presentaciones de diapositivas son un mecanismo común utilizado para compartir y difundir información internamente con la organización y externamente con los clientes o en conferencias. Con el tiempo, la información valiosa puede permanecer enterrada y oculta en modalidades que no son texto, como gráficos y tablas en estas presentaciones de diapositivas. Puede utilizar esta solución y el poder de los FM multimodales, como el modelo Titan Multimodal Embeddings y LLaVA, para descubrir nueva información o descubrir nuevas perspectivas sobre el contenido en presentaciones de diapositivas.
Le animamos a aprender más explorando JumpStart de Amazon SageMaker, Modelos de Amazon Titan, Amazon Bedrock y OpenSearch Service, y crear una solución utilizando la implementación de muestra proporcionada en esta publicación.
Esté atento a dos publicaciones adicionales como parte de esta serie. La parte 2 cubre otro enfoque que podría adoptar para hablar con su conjunto de diapositivas. Este enfoque genera y almacena inferencias de LLaVA y utiliza esas inferencias almacenadas para responder a las consultas de los usuarios. La parte 3 compara los dos enfoques.
Sobre los autores
 Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
 Manju Prasad es arquitecto senior de soluciones dentro de Cuentas Estratégicas en Amazon Web Services. Se centra en brindar orientación técnica en una variedad de dominios, incluido AI/ML, a un cliente destacado de M&E. Antes de unirse a AWS, diseñó y construyó soluciones para empresas del sector de servicios financieros y también para una startup.
Manju Prasad es arquitecto senior de soluciones dentro de Cuentas Estratégicas en Amazon Web Services. Se centra en brindar orientación técnica en una variedad de dominios, incluido AI/ML, a un cliente destacado de M&E. Antes de unirse a AWS, diseñó y construyó soluciones para empresas del sector de servicios financieros y también para una startup.
 Archana Inapudi es arquitecto senior de soluciones en AWS y brinda soporte a clientes estratégicos. Tiene más de una década de experiencia ayudando a clientes a diseñar y crear análisis de datos y soluciones de bases de datos. Le apasiona utilizar la tecnología para brindar valor a los clientes y lograr resultados comerciales.
Archana Inapudi es arquitecto senior de soluciones en AWS y brinda soporte a clientes estratégicos. Tiene más de una década de experiencia ayudando a clientes a diseñar y crear análisis de datos y soluciones de bases de datos. Le apasiona utilizar la tecnología para brindar valor a los clientes y lograr resultados comerciales.
 antara raisa es arquitecto de soluciones de inteligencia artificial y aprendizaje automático en Amazon Web Services y brinda soporte a clientes estratégicos con sede en Dallas, Texas. También tiene experiencia previa trabajando con grandes socios empresariales en AWS, donde trabajó como arquitecta de soluciones de éxito de socios para clientes nativos digitales.
antara raisa es arquitecto de soluciones de inteligencia artificial y aprendizaje automático en Amazon Web Services y brinda soporte a clientes estratégicos con sede en Dallas, Texas. También tiene experiencia previa trabajando con grandes socios empresariales en AWS, donde trabajó como arquitecta de soluciones de éxito de socios para clientes nativos digitales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

