Los clientes se enfrentan a crecientes amenazas y vulnerabilidades de seguridad en toda la infraestructura y los recursos de aplicaciones a medida que su huella digital se ha ampliado y el impacto empresarial de esos activos digitales ha crecido. Un desafío común de ciberseguridad ha sido doble:
- Consumir registros de recursos digitales que vienen en diferentes formatos y esquemas y automatizar el análisis de los hallazgos de amenazas en función de esos registros.
- Ya sea que los registros provengan de Amazon Web Services (AWS), otros proveedores de la nube, dispositivos locales o de borde, los clientes necesitan centralizar y estandarizar los datos de seguridad.
Además, los análisis para identificar amenazas a la seguridad deben ser capaces de escalarse y evolucionar para adaptarse a un panorama cambiante de actores de amenazas, vectores de seguridad y activos digitales.
Un enfoque novedoso para resolver este complejo escenario de análisis de seguridad combina la ingesta y el almacenamiento de datos de seguridad utilizando Lago de seguridad de Amazon y analizar los datos de seguridad con aprendizaje automático (ML) utilizando Amazon SageMaker. Amazon Security Lake es un servicio especialmente diseñado que centraliza automáticamente los datos de seguridad de una organización desde la nube y las fuentes locales en un lago de datos especialmente diseñado y almacenado en su cuenta de AWS. Amazon Security Lake automatiza la administración central de datos de seguridad, normaliza los registros de los servicios integrados de AWS y de servicios de terceros y administra el ciclo de vida de los datos con retención personalizable y también automatiza el almacenamiento en niveles. Amazon Security Lake ingiere archivos de registro en el Marco de esquema de ciberseguridad abierto (OCSF), con soporte para socios como Cisco Security, CrowdStrike, Palo Alto Networks y registros OCSF de recursos fuera de su entorno de AWS. Este esquema unificado agiliza el consumo y el análisis posteriores porque los datos siguen un esquema estandarizado y se pueden agregar nuevas fuentes con cambios mínimos en la canalización de datos. Una vez que los datos del registro de seguridad se almacenan en Amazon Security Lake, la pregunta es cómo analizarlos. Un enfoque eficaz para analizar los datos del registro de seguridad es utilizar ML; específicamente, detección de anomalías, que examina los datos de actividad y tráfico y los compara con una línea de base. La línea de base define qué actividad es estadísticamente normal para ese entorno. La detección de anomalías va más allá de la firma de un evento individual y puede evolucionar con un reentrenamiento periódico; Luego se puede actuar sobre el tráfico clasificado como anormal o anómalo con prioridad y urgencia. Amazon SageMaker es un servicio totalmente administrado que permite a los clientes preparar datos y crear, entrenar e implementar modelos de aprendizaje automático para cualquier caso de uso con infraestructura, herramientas y flujos de trabajo totalmente administrados, incluidas ofertas sin código para analistas de negocios. SageMaker admite dos algoritmos de detección de anomalías integrados: Información sobre propiedad intelectual y Bosque de corte aleatorio. También puede utilizar SageMaker para crear su propio modelo de detección de valores atípicos personalizado utilizando algoritmos procedente de múltiples marcos de ML.
En esta publicación, aprenderá cómo preparar datos obtenidos de Amazon Security Lake y luego entrenar e implementar un modelo de aprendizaje automático utilizando un algoritmo de IP Insights en SageMaker. Este modelo identifica el tráfico o comportamiento anómalo de la red que luego puede integrarse como parte de una solución de seguridad de extremo a extremo más amplia. Una solución de este tipo podría invocar una verificación de autenticación multifactor (MFA) si un usuario inicia sesión desde un servidor inusual o en un momento inusual, notificar al personal si hay un escaneo de red sospechoso proveniente de nuevas direcciones IP, alertar a los administradores si la red es inusual. Se utilizan protocolos o puertos, o enriquecer el resultado de la clasificación de conocimientos de IP con otras fuentes de datos, como Servicio de guardia de Amazon y puntuaciones de reputación de propiedad intelectual para clasificar los hallazgos de amenazas.
Resumen de la solución
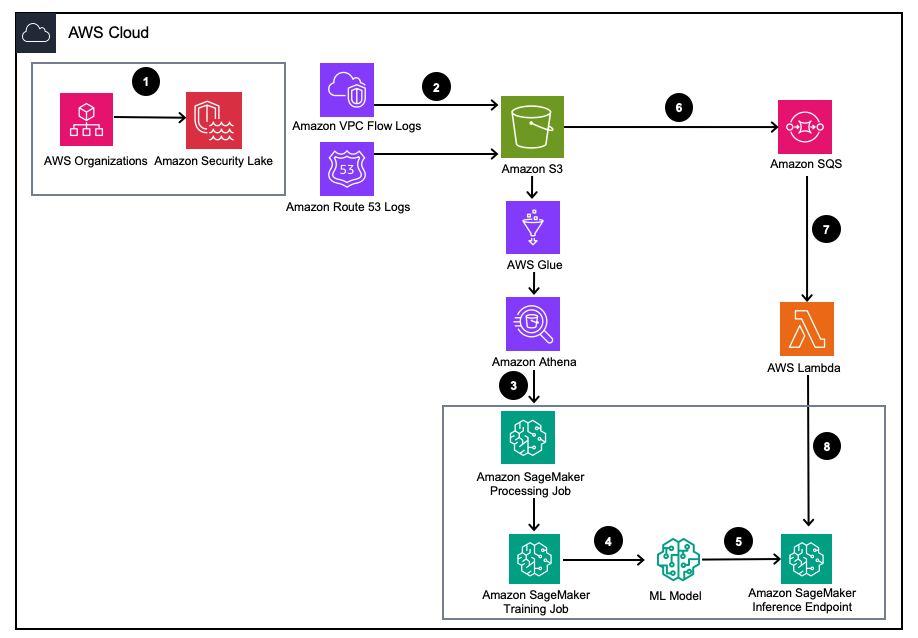
Figura 1 – Arquitectura de la solución
- Habilite Amazon Security Lake con Organizaciones de AWS para cuentas de AWS, regiones de AWS y entornos de TI externos.
- Configurar fuentes de Security Lake desde Nube privada virtual de Amazon (Amazon VPC) Registros de flujo y Ruta Amazonas53 Registros DNS en el depósito de Amazon Security Lake S3.
- Procese los datos de registro de Amazon Security Lake mediante un trabajo de procesamiento de SageMaker para diseñar funciones. Usar Atenea amazónica para consultar datos de registro OCSF estructurados desde Servicio de almacenamiento simple de Amazon (Amazon S3) a Pegamento AWS tablas administradas por AWS LakeFormation.
- Entrene un modelo de SageMaker ML utilizando un trabajo de entrenamiento de SageMaker que consuma los registros procesados de Amazon Security Lake.
- Implemente el modelo de ML entrenado en un punto final de inferencia de SageMaker.
- Almacene nuevos registros de seguridad en un depósito de S3 y ponga en cola los eventos en Servicio de cola simple de Amazon (Amazon SQS).
- Suscríbete un AWS Lambda función a la cola SQS.
- Invoque el punto final de inferencia de SageMaker utilizando una función Lambda para clasificar los registros de seguridad como anomalías en tiempo real.
Requisitos previos
Para implementar la solución, primero debe completar los siguientes requisitos previos:
- Habilitar el lago de seguridad de Amazon dentro de su organización o una sola cuenta con los registros de flujo de VPC y los registros de resolución de Route 53 habilitados.
- Asegúrese de que el Administración de acceso e identidad de AWS (IAM) Al rol utilizado por SageMaker que procesa trabajos y cuadernos se le ha otorgado una política de IAM que incluye la Permiso de acceso a consultas de suscriptores de Amazon Security Lake para las tablas y bases de datos administradas de Amazon Security Lake administradas por AWS Lake Formation. Este trabajo de procesamiento debe ejecutarse desde una cuenta de análisis o herramientas de seguridad para seguir cumpliendo con Arquitectura de referencia de seguridad de AWS (AWS SRA).
- Asegúrese de que al rol de IAM utilizado por la función Lambda se le haya otorgado una política de IAM que incluya Permiso de acceso a datos del suscriptor de Amazon Security Lake.
Implementar la solución
Para configurar el entorno, complete los siguientes pasos:
- Lanzar un Estudio SageMaker o cuaderno SageMaker Jupyter con un
ml.m5.largeejemplo. Nota: El tamaño de la instancia depende de los conjuntos de datos que utilice. - Clonar el GitHub repositorio.
- abre el cuaderno
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - Implementar el política de IAM proporcionada y política de confianza de IAM correspondiente para que su instancia de SageMaker Studio Notebook acceda a todos los datos necesarios en S3, Lake Formation y Athena.
Este blog recorre la parte relevante del código dentro del cuaderno después de implementarlo en su entorno.
Instale las dependencias e importe la biblioteca requerida
Utilice el siguiente código para instalar dependencias, importar las bibliotecas necesarias y crear el depósito de SageMaker S3 necesario para el procesamiento de datos y el entrenamiento de modelos. Una de las bibliotecas requeridas, awswrangler, es un AWS SDK para el marco de datos de pandas que se utiliza para consultar las tablas relevantes dentro del catálogo de datos de AWS Glue y almacenar los resultados localmente en un marco de datos.
Consultar la tabla de registro de flujo de VPC de Amazon Security Lake
Esta parte del código utiliza AWS SDK para pandas para consultar la tabla de AWS Glue relacionada con los registros de flujo de VPC. Como se menciona en los requisitos previos, las tablas de Amazon Security Lake son administradas por Formación del lago AWS, por lo que se deben otorgar todos los permisos adecuados a la función utilizada por el cuaderno de SageMaker. Esta consulta generará varios días de tráfico de registro de flujo de VPC. El conjunto de datos utilizado durante el desarrollo de este blog fue pequeño. Dependiendo de la escala de su caso de uso, debe conocer los límites del SDK de AWS para pandas. Al considerar la escala de terabytes, debe considerar AWS SDK para compatibilidad con pandas Modín.
Cuando vea el marco de datos, verá el resultado de una sola columna con campos comunes que se pueden encontrar en el Actividad de red (4001) clase de la OCSF.
Normalice los datos del registro de flujo de Amazon Security Lake VPC en el formato de capacitación requerido para IP Insights.
El algoritmo IP Insights requiere que los datos de entrenamiento estén en formato CSV y contengan dos columnas. La primera columna debe ser una cadena opaca que corresponda al identificador único de una entidad. La segunda columna debe ser la dirección IPv4 del evento de acceso de la entidad en notación de punto decimal. En el conjunto de datos de muestra para este blog, el identificador único son los ID de instancia de las instancias EC2 asociadas al instance_id valor dentro del dataframe. La dirección IPv4 se derivará de la src_endpoint. Según la forma en que se creó la consulta de Amazon Athena, los datos importados ya están en el formato correcto para entrenar un modelo de IP Insights, por lo que no se requiere ingeniería de funciones adicionales. Si modifica la consulta de otra manera, es posible que deba incorporar funciones de ingeniería adicionales.
Consultar y normalizar la tabla de registros de resolución de Amazon Security Lake Route 53
Tal como lo hizo anteriormente, el siguiente paso del cuaderno ejecuta una consulta similar en la tabla de resolución de Amazon Security Lake Route 53. Dado que utilizará todos los datos compatibles con OCSF en este cuaderno, cualquier tarea de ingeniería de funciones seguirá siendo la misma para los registros de resolución de Route 53 que para los registros de flujo de VPC. Luego combina los dos marcos de datos en un único marco de datos que se utiliza para el entrenamiento. Dado que la consulta de Amazon Athena carga los datos localmente en el formato correcto, no se requiere ingeniería de funciones adicional.
Obtenga la imagen de entrenamiento de IP Insights y entrene el modelo con los datos de OCSF
En la siguiente parte del cuaderno, entrenará un modelo de aprendizaje automático basado en el algoritmo IP Insights y utilizará el modelo consolidado. dataframe de OCSF a partir de diferentes tipos de registros. Puede encontrar una lista de los hiperparámetros de IP Insights esta página. En el siguiente ejemplo, seleccionamos hiperparámetros que generaron el modelo de mejor rendimiento, por ejemplo, 5 para época y 128 para vector_dim. Dado que el conjunto de datos de entrenamiento para nuestra muestra era relativamente pequeño, utilizamos un ml.m5.large instancia. Los hiperparámetros y sus configuraciones de entrenamiento, como el recuento de instancias y el tipo de instancia, deben elegirse en función de sus métricas objetivas y el tamaño de sus datos de entrenamiento. Una capacidad que puede utilizar dentro de Amazon SageMaker para encontrar la mejor versión de su modelo es Amazon SageMaker. ajuste automático del modelo que busca el mejor modelo en un rango de valores de hiperparámetros.
Implementar el modelo entrenado y probar con tráfico válido y anómalo.
Una vez entrenado el modelo, lo implementa en un punto final de SageMaker y envía una serie de combinaciones de identificadores únicos y direcciones IPv4 para probar su modelo. Esta parte del código supone que tiene datos de prueba guardados en su depósito S3. Los datos de prueba son un archivo .csv, donde la primera columna son los ID de instancia y la segunda columna son las IP. Se recomienda probar datos válidos e inválidos para ver los resultados del modelo. El siguiente código implementa su punto final.
Ahora que su punto final está implementado, puede enviar solicitudes de inferencia para identificar si el tráfico es potencialmente anómalo. A continuación se muestra una muestra de cómo deberían verse sus datos formateados. En este caso, el identificador de la primera columna es una identificación de instancia y la segunda columna es una dirección IP asociada, como se muestra a continuación:
Una vez que tenga sus datos en formato CSV, puede enviarlos para inferencia usando el código leyendo su archivo .csv desde un depósito S3:
El resultado de un modelo de IP Insights proporciona una medida de cuán estadísticamente se espera que sean una dirección IP y un recurso en línea. Sin embargo, el rango para esta dirección y recurso es ilimitado, por lo que hay consideraciones sobre cómo determinar si una combinación de ID de instancia y dirección IP debe considerarse anómala.
En el ejemplo anterior, se enviaron al modelo cuatro combinaciones diferentes de identificador e IP. Las dos primeras combinaciones fueron combinaciones válidas de ID de instancia y dirección IP que se esperan según el conjunto de entrenamiento. La tercera combinación tiene el identificador único correcto pero una dirección IP diferente dentro de la misma subred. El modelo debe determinar que existe una anomalía modesta ya que la incorporación es ligeramente diferente de los datos de entrenamiento. La cuarta combinación tiene un identificador único válido pero una dirección IP de una subred inexistente dentro de cualquier VPC del entorno.
Nota: Los datos de tráfico normal y anormal cambiarán según su caso de uso específico, por ejemplo: si desea monitorear el tráfico externo e interno, necesitará un identificador único alineado con cada dirección IP y un esquema para generar los identificadores externos.
Para determinar cuál debe ser su umbral para determinar si el tráfico es anómalo, se puede hacer utilizando el tráfico normal y anormal conocido. Los pasos descritos en este cuaderno de muestra son los siguientes:
- Construya un conjunto de prueba para representar el tráfico normal.
- Agregue tráfico anormal al conjunto de datos.
- Trazar la distribución de
dot_productpuntuaciones para el modelo sobre el tráfico normal y el tráfico anormal. - Seleccione un valor de umbral que distinga el subconjunto normal del subconjunto anormal. Este valor se basa en su tolerancia a falsos positivos.
Configure el monitoreo continuo del nuevo tráfico de registros de flujo de VPC.
Para demostrar cómo se podría usar este nuevo modelo de ML con Amazon Security Lake de manera proactiva, configuraremos una función Lambda para que se invoque en cada PutObject evento dentro del depósito administrado de Amazon Security Lake, específicamente los datos del registro de flujo de VPC. Dentro de Amazon Security Lake existe el concepto de suscriptor, que consume registros y eventos de Amazon Security Lake. A la función Lambda que responde a nuevos eventos se le debe otorgar una suscripción de acceso a datos. Los suscriptores de acceso a datos reciben notificaciones sobre los nuevos objetos de Amazon S3 para una fuente a medida que los objetos se escriben en el depósito de Security Lake. Los suscriptores pueden acceder directamente a los objetos de S3 y recibir notificaciones de nuevos objetos a través de un punto final de suscripción o sondeando una cola de Amazon SQS.
- Abra la Consola de seguridad del lago.
- En el panel de navegación, seleccione Abonados.
- En la página Suscriptores, elija Crear suscriptor.
- Para obtener detalles del suscriptor, ingrese
inferencelambdapara Nombre del suscriptor y un opcional Descripción. - El Provincia se establece automáticamente como la región de AWS seleccionada actualmente y no se puede modificar.
- Fuentes de registros y eventos, escoger Fuentes de eventos y registros específicos y elige Registros de flujo de VPC y registros de ruta 53
- Método de acceso a datos, escoger S3.
- Credenciales de suscriptor, proporcione el ID de su cuenta de AWS de la cuenta donde residirá la función Lambda y un identificador especificado por el usuario. identificación externa.
Nota: Si hace esto localmente dentro de una cuenta, no necesita tener una identificación externa. - Elige Crear.
Crear la función Lambda
Para crear e implementar la función Lambda, puede completar los siguientes pasos o implementar la plantilla SAM prediseñadas 01_ipinsights/01.02-ipcheck.yaml en el repositorio de GitHub. La plantilla SAM requiere que proporcione el ARN de SQS y el nombre del punto final de SageMaker.
- En la consola Lambda, elija Crear función.
- Elige Autor desde cero.
- Nombre de la función, introduzca
ipcheck. - Runtime, escoger 3.10 Python.
- Arquitectura, seleccione x86_64.
- Rol de ejecución, seleccione Cree un nuevo rol con permisos de Lambda.
- Después de crear la función, ingrese el contenido del ipcheck.py archivo del repositorio de GitHub.
- En el panel de navegación, elija Variables de entorno.
- Elige Editar.
- Elige Agregar variable de entorno.
- Para la nueva variable de entorno, ingrese
ENDPOINT_NAMEy para el valor, ingrese el ARN del punto final que se generó durante la implementación del punto final de SageMaker. - Seleccione Guardar.
- Elige Despliegue.
- En el panel de navegación, elija Configuración.
- Seleccione disparadores.
- Seleccione Agregar disparador.
- under Seleccione una fuente, escoger SQS.
- under Cola SQS, ingrese el ARN de la cola SQS principal creada por Security Lake.
- Seleccione la casilla de verificación para Activar gatillo.
- Seleccione Añada.
Validar los resultados de Lambda
- Abra la Consola de Amazon CloudWatch.
- En el panel lateral izquierdo, seleccione Grupos de registros.
- En la barra de búsqueda, ingrese ipcheck y luego seleccione el grupo de registro con el nombre
/aws/lambda/ipcheck. - Seleccione el flujo de registro más reciente en Secuencias de registro.
- Dentro de los registros, debería ver resultados similares a los siguientes para cada nuevo registro de Amazon Security Lake:
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
Esta función Lambda analiza continuamente el tráfico de red que ingiere Amazon Security Lake. Esto le permite crear mecanismos para notificar a sus equipos de seguridad cuando se viola un umbral específico, lo que indicaría un tráfico anómalo en su entorno.
Limpiar
Cuando haya terminado de experimentar con esta solución y para evitar cargos en su cuenta, limpie sus recursos eliminando el depósito S3, el punto final de SageMaker, apagando la computadora adjunta al cuaderno SageMaker Jupyter, eliminando la función Lambda y deshabilitando la seguridad de Amazon. Lago en tu cuenta.
Conclusión
En esta publicación, aprendió cómo preparar datos de tráfico de red provenientes de Amazon Security Lake para el aprendizaje automático y luego entrenó e implementó un modelo de aprendizaje automático utilizando el algoritmo IP Insights en Amazon SageMaker. Todos los pasos descritos en el cuaderno de Jupyter se pueden replicar en una canalización de aprendizaje automático de un extremo a otro. También implementó una función de AWS Lambda que consumió nuevos registros de Amazon Security Lake y envió inferencias basadas en el modelo de detección de anomalías entrenado. Las respuestas del modelo ML recibidas por AWS Lambda podrían notificar de forma proactiva a los equipos de seguridad sobre tráfico anómalo cuando se alcanzan ciertos umbrales. Se puede permitir la mejora continua del modelo incluyendo a su equipo de seguridad en las revisiones del circuito para etiquetar si el tráfico identificado como anómalo fue un falso positivo o no. Esto luego podría agregarse a su conjunto de entrenamiento y también agregarse a su normal conjunto de datos de tráfico al determinar un umbral empírico. Este modelo puede identificar tráfico o comportamiento de red potencialmente anómalo, por lo que puede incluirse como parte de una solución de seguridad más amplia para iniciar una verificación de MFA si un usuario inicia sesión desde un servidor inusual o en un momento inusual, alertar al personal si hay una conexión sospechosa. escaneo de red proveniente de nuevas direcciones IP o combine la puntuación de información de IP con otras fuentes, como Amazon Guard Duty, para clasificar los hallazgos de amenazas. Este modelo puede incluir orígenes de registros personalizados, como Azure Flow Logs o registros locales, agregando orígenes personalizados a su implementación de Amazon Security Lake.
En la parte 2 de esta serie de publicaciones de blog, aprenderá cómo crear un modelo de detección de anomalías utilizando el Bosque de corte aleatorio algoritmo entrenado con fuentes adicionales de Amazon Security Lake que integran datos de registro de seguridad de host y red y aplican la clasificación de anomalías de seguridad como parte de una solución de monitoreo de seguridad integral y automatizada.
Sobre los autores
 joe morotti es un arquitecto de soluciones en Amazon Web Services (AWS), que ayuda a los clientes empresariales en todo el medio oeste de EE. UU. Ha ocupado una amplia gama de funciones técnicas y disfruta mostrando el arte de lo posible de los clientes. En su tiempo libre, disfruta pasar tiempo de calidad con su familia explorando nuevos lugares y analizando en exceso el rendimiento de su equipo deportivo.
joe morotti es un arquitecto de soluciones en Amazon Web Services (AWS), que ayuda a los clientes empresariales en todo el medio oeste de EE. UU. Ha ocupado una amplia gama de funciones técnicas y disfruta mostrando el arte de lo posible de los clientes. En su tiempo libre, disfruta pasar tiempo de calidad con su familia explorando nuevos lugares y analizando en exceso el rendimiento de su equipo deportivo.
 Bishr Tabbaa es arquitecto de soluciones en Amazon Web Services. Bishr se especializa en ayudar a los clientes con aplicaciones de aprendizaje automático, seguridad y observabilidad. Fuera del trabajo, le gusta jugar al tenis, cocinar y pasar tiempo con la familia.
Bishr Tabbaa es arquitecto de soluciones en Amazon Web Services. Bishr se especializa en ayudar a los clientes con aplicaciones de aprendizaje automático, seguridad y observabilidad. Fuera del trabajo, le gusta jugar al tenis, cocinar y pasar tiempo con la familia.
 Sriharsh Adari es arquitecto sénior de soluciones en Amazon Web Services (AWS), donde ayuda a los clientes a trabajar hacia atrás a partir de los resultados comerciales para desarrollar soluciones innovadoras en AWS. A lo largo de los años, ha ayudado a varios clientes en la transformación de plataformas de datos en verticales de la industria. Su área principal de especialización incluye estrategia tecnológica, análisis de datos y ciencia de datos. En su tiempo libre, le gusta jugar al tenis, ver programas de televisión en exceso y jugar a la tabla.
Sriharsh Adari es arquitecto sénior de soluciones en Amazon Web Services (AWS), donde ayuda a los clientes a trabajar hacia atrás a partir de los resultados comerciales para desarrollar soluciones innovadoras en AWS. A lo largo de los años, ha ayudado a varios clientes en la transformación de plataformas de datos en verticales de la industria. Su área principal de especialización incluye estrategia tecnológica, análisis de datos y ciencia de datos. En su tiempo libre, le gusta jugar al tenis, ver programas de televisión en exceso y jugar a la tabla.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

