Esta publicación fue escrita en colaboración con Ankur Goyal y Karthikeyan Chokappa del negocio Digital y de Nube de PwC Australia.
La inteligencia artificial (IA) y el aprendizaje automático (ML) se están convirtiendo en una parte integral de los sistemas y procesos, permitiendo tomar decisiones en tiempo real, impulsando así mejoras en los resultados y en los resultados en todas las organizaciones. Sin embargo, poner en producción un modelo de ML a escala es un desafío y requiere un conjunto de mejores prácticas. Muchas empresas ya cuentan con científicos de datos e ingenieros de aprendizaje automático que pueden crear modelos de última generación, pero llevar los modelos a producción y mantenerlos a escala sigue siendo un desafío. Los flujos de trabajo manuales limitan las operaciones del ciclo de vida del aprendizaje automático para ralentizar el proceso de desarrollo, aumentar los costos y comprometer la calidad del producto final.
Las operaciones de aprendizaje automático (MLOps) aplican los principios de DevOps a los sistemas de aprendizaje automático. Así como DevOps combina desarrollo y operaciones para ingeniería de software, MLOps combina ingeniería de ML y operaciones de TI. Con el rápido crecimiento de los sistemas de ML y en el contexto de la ingeniería de ML, MLOps proporciona las capacidades necesarias para manejar las complejidades únicas de la aplicación práctica de los sistemas de ML. En general, los casos de uso de ML requieren una solución integrada fácilmente disponible para industrializar y optimizar el proceso que lleva un modelo de ML desde el desarrollo hasta la implementación de producción a escala utilizando MLOps.
Para abordar estos desafíos de los clientes, PwC Australia desarrolló Machine Learning Ops Accelerator como un conjunto de capacidades tecnológicas y de procesos estandarizados para mejorar la operacionalización de modelos de IA/ML que permiten la colaboración multifuncional entre equipos a lo largo de las operaciones del ciclo de vida de ML. PwC Machine Learning Ops Accelerator, construido sobre los servicios nativos de AWS, ofrece una solución adecuada que se integra fácilmente en los casos de uso de ML con facilidad para clientes de todas las industrias. En esta publicación, nos centramos en crear e implementar un caso de uso de ML que integre varios componentes del ciclo de vida de un modelo de ML, permitiendo la integración continua (CI), la entrega continua (CD), la capacitación continua (CT) y el monitoreo continuo (CM).
Resumen de la solución
En MLOps, un viaje exitoso desde los datos hasta los modelos de ML y las recomendaciones y predicciones en sistemas y procesos comerciales implica varios pasos cruciales. Implica tomar el resultado de un experimento o prototipo y convertirlo en un sistema de producción con controles estándar, calidad y circuitos de retroalimentación. Es mucho más que una simple automatización. Se trata de mejorar las prácticas organizativas y ofrecer resultados que sean repetibles y reproducibles a escala.
Solo una pequeña fracción de un caso de uso de ML en el mundo real comprende el modelo en sí. En la Figura 1 se muestran los diversos componentes necesarios para construir una capacidad de ML avanzada integrada y operarla continuamente a escala. Como se ilustra en el siguiente diagrama, PwC MLOps Accelerator comprende siete capacidades integradas clave y pasos iterativos que permiten CI, CD, CT y CM de un caso de uso de ML. La solución aprovecha las características nativas de AWS de Amazon SageMaker, construyendo un marco flexible y extensible en torno a esto.
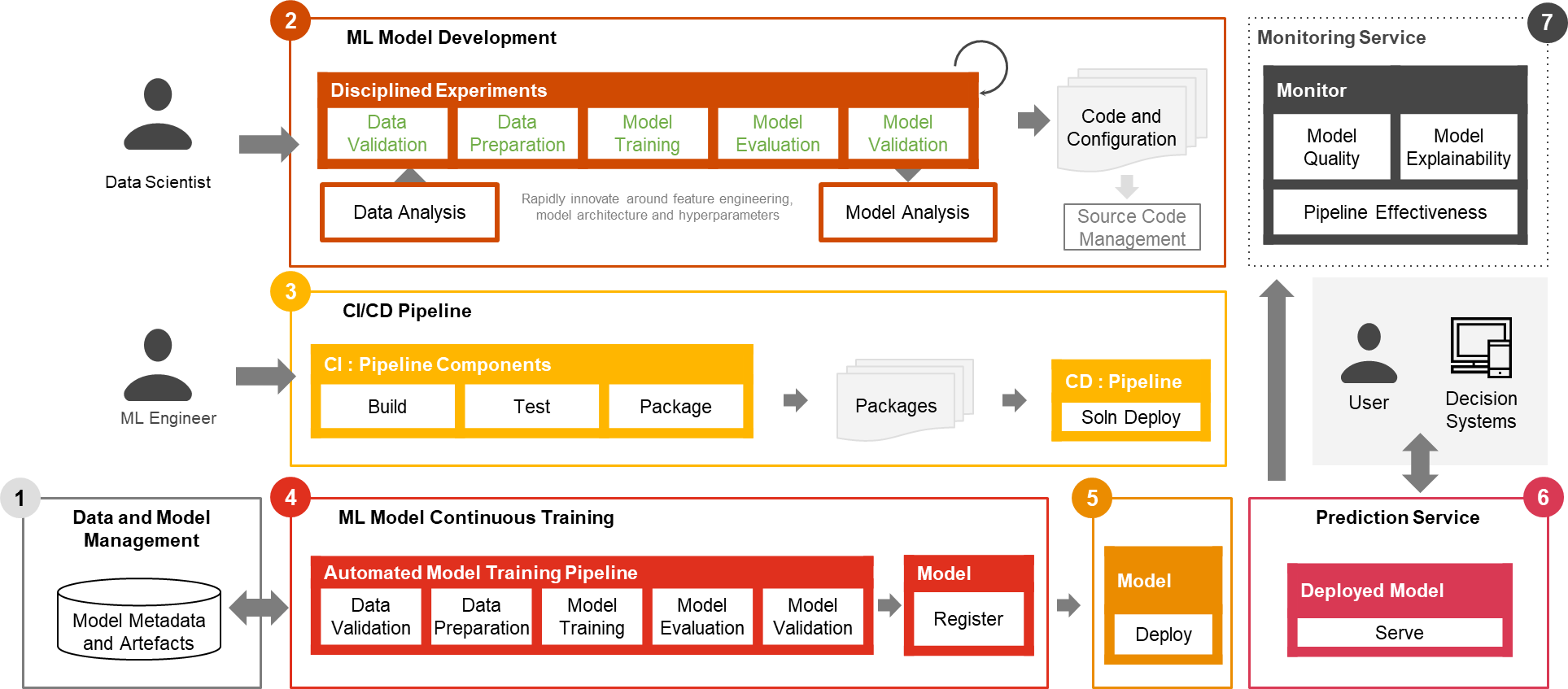
Figura 1: Capacidades del acelerador de operaciones de aprendizaje automático de PwC
En un escenario empresarial real, pueden existir pasos y etapas de prueba adicionales para garantizar una validación e implementación rigurosas de modelos en diferentes entornos.
- Gestión de datos y modelos. Proporcionar una capacidad central que gobierna los artefactos de ML a lo largo de su ciclo de vida. Permite auditabilidad, trazabilidad y cumplimiento. También promueve la capacidad de compartir, reutilizar y descubrir los activos de ML.
- Desarrollo de modelos de aprendizaje automático permite a varias personas desarrollar un proceso de capacitación de modelos sólido y reproducible, que comprende una secuencia de pasos, desde la validación y transformación de datos hasta la capacitación y evaluación de modelos.
- Integración/entrega continua facilita la creación, prueba y empaquetado automatizados del proceso de capacitación del modelo y su implementación en el entorno de ejecución de destino. Las integraciones con flujos de trabajo de CI/CD y control de versiones de datos promueven las mejores prácticas de MLOps, como la gobernanza y el monitoreo para el desarrollo iterativo y el control de versiones de datos.
- Entrenamiento continuo del modelo ML la capacidad ejecuta el proceso de capacitación basándose en desencadenantes de reentrenamiento; es decir, a medida que hay nuevos datos disponibles o el rendimiento del modelo decae por debajo de un umbral preestablecido. Registra el modelo entrenado si califica como candidato de modelo exitoso y almacena los artefactos de entrenamiento y los metadatos asociados.
- Despliegue del modelo permite el acceso al modelo entrenado registrado para revisarlo y aprobarlo para su lanzamiento en producción y permite empaquetar, probar e implementar el modelo en el entorno del servicio de predicción para el servicio de producción.
- Servicio de predicción La capacidad inicia el modelo implementado para proporcionar predicción a través de patrones en línea, por lotes o de transmisión. El tiempo de ejecución de servicio también captura registros de servicio de modelos para monitoreo y mejoras continuos.
- Monitoreo continuo monitorea el modelo para determinar la efectividad predictiva para detectar el deterioro del modelo y la efectividad del servicio (latencia, canalización y errores de ejecución)
Arquitectura del acelerador de operaciones de aprendizaje automático de PwC
La solución se basa en servicios nativos de AWS que utilizan Amazon SageMaker y tecnología sin servidor para mantener el rendimiento y la escalabilidad altos y los costos de funcionamiento bajos.
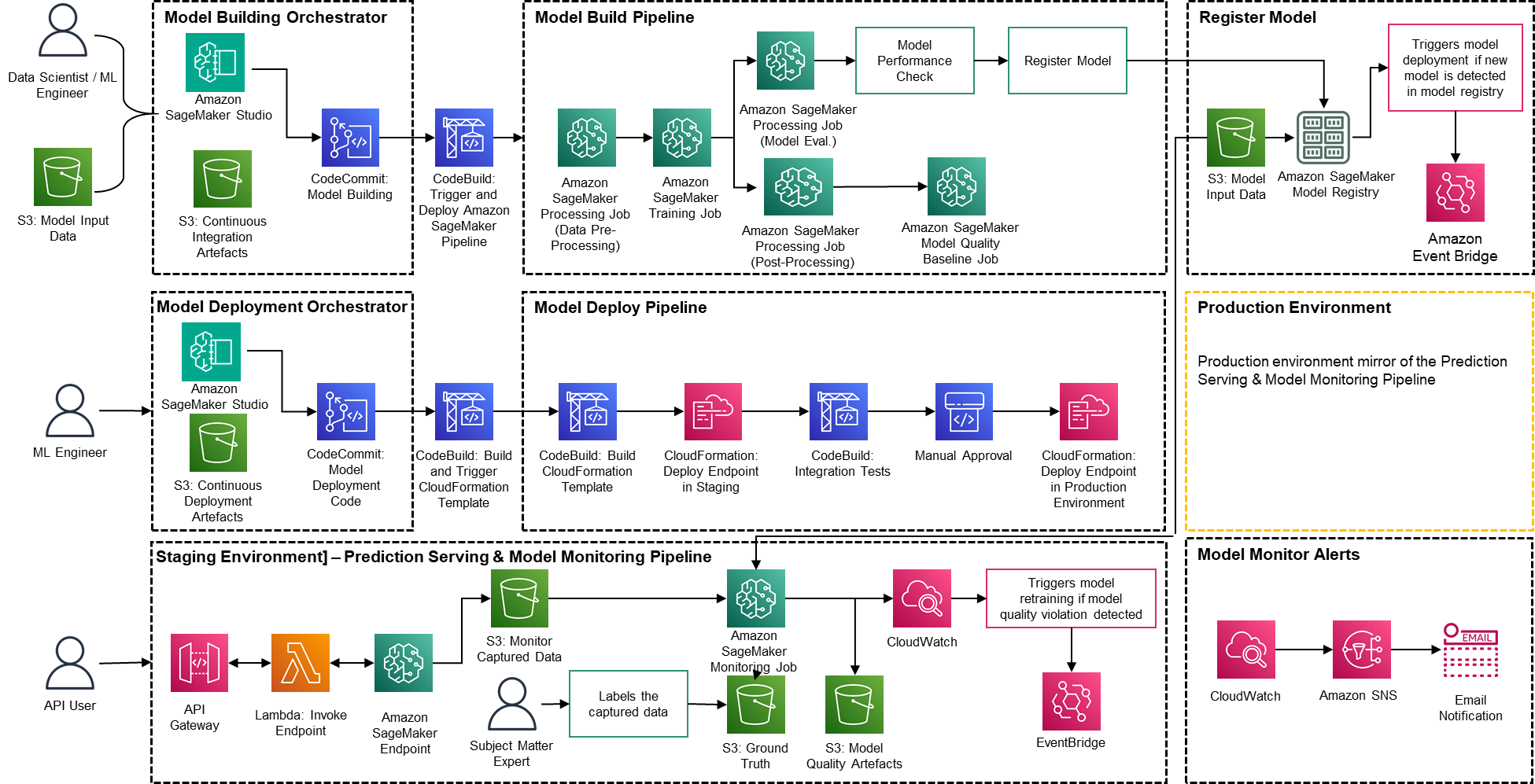
Figura 2: Arquitectura del acelerador de operaciones de aprendizaje automático de PwC
- PwC Machine Learning Ops Accelerator proporciona un derecho de acceso basado en personas para la construcción, el uso y las operaciones que permite a los ingenieros de aprendizaje automático y científicos de datos automatizar la implementación de canalizaciones (capacitación y servicio) y responder rápidamente a los cambios en la calidad del modelo. Administrador de funciones de Amazon SageMaker se utiliza para implementar actividades de aprendizaje automático basadas en roles, y Amazon S3 se utiliza para almacenar datos de entrada y artefactos.
- La solución utiliza activos de creación de modelos existentes del cliente y crea un marco flexible y extensible en torno a esto utilizando servicios nativos de AWS. Se han creado integraciones entre Amazon S3, Git y AWS CodeCommit que permiten el control de versiones de conjuntos de datos con una gestión futura mínima.
- La plantilla de AWS CloudFormation se genera utilizando Kit de desarrollo en la nube de AWS (AWS CDK). AWS CDK brinda la capacidad de administrar cambios para la solución completa. El proceso automatizado incluye pasos para el almacenamiento de modelos listo para usar y el seguimiento de métricas.
- PwC MLOps Accelerator está diseñado para ser modular y entregarse como infraestructura como código (IaC) para permitir implementaciones automáticas. El proceso de implementación utiliza Compromiso de código de AWS, Construcción de código AWS, AWS CodePipeliney plantilla de AWS CloudFormation. La solución completa de un extremo a otro para poner en funcionamiento un modelo de aprendizaje automático está disponible como código implementable.
- A través de una serie de plantillas de IaC, se implementan tres componentes distintos: creación de modelos, implementación de modelos y servicio de predicción y monitoreo de modelos, utilizando Canalizaciones de Amazon SageMaker
- La canalización de construcción de modelos automatiza el proceso de capacitación y evaluación del modelo y permite la aprobación y el registro del modelo entrenado.
- La canalización de implementación del modelo proporciona la infraestructura necesaria para implementar el modelo de aprendizaje automático para inferencia por lotes y en tiempo real.
- La canalización de servicios de predicción y monitoreo de modelos implementa la infraestructura necesaria para realizar predicciones y monitorear el rendimiento del modelo.
- PwC MLOps Accelerator está diseñado para ser independiente de los modelos de ML, los marcos de ML y los entornos de ejecución. La solución permite el uso familiar de lenguajes de programación como Python y R, herramientas de desarrollo como Jupyter Notebook y marcos de ML a través de un archivo de configuración. Esta flexibilidad hace que sea sencillo para los científicos de datos perfeccionar continuamente los modelos e implementarlos utilizando su lenguaje y entorno preferidos.
- La solución tiene integraciones integradas para usar herramientas prediseñadas o personalizadas para asignar las tareas de etiquetado usando Verdad fundamental de Amazon SageMaker para conjuntos de datos de entrenamiento para proporcionar capacitación y monitoreo continuos.
- La canalización de aprendizaje automático de un extremo a otro está diseñada utilizando características nativas de SageMaker (Estudio Amazon SageMaker , Canalizaciones de creación de modelos de Amazon SageMaker, Experimentos de Amazon SageMakery Puntos finales de Amazon SageMaker).
- La solución utiliza capacidades integradas de Amazon SageMaker para el control de versiones de modelos, el seguimiento del linaje de modelos, el uso compartido de modelos y la inferencia sin servidor con Registro de modelos de Amazon SageMaker.
- Una vez que el modelo está en producción, la solución monitorea continuamente la calidad de los modelos ML en tiempo real. Monitor de modelo de Amazon SageMaker se utiliza para monitorear continuamente los modelos en producción. Amazon CloudWatch Logs se utiliza para recopilar archivos de registro que monitorean el estado del modelo y se envían notificaciones mediante Amazon SNS cuando la calidad del modelo alcanza ciertos umbrales. Registradores nativos como (boto3) se utilizan para capturar el estado de ejecución y acelerar la resolución de problemas.
Tutorial de la solución
El siguiente tutorial profundiza en los pasos estándar para crear el proceso MLOps para un modelo utilizando PwC MLOps Accelerator. Este tutorial describe un caso de uso de un ingeniero de MLOps que desea implementar la canalización para un modelo de ML desarrollado recientemente utilizando un archivo de definición/configuración simple que es intuitivo.
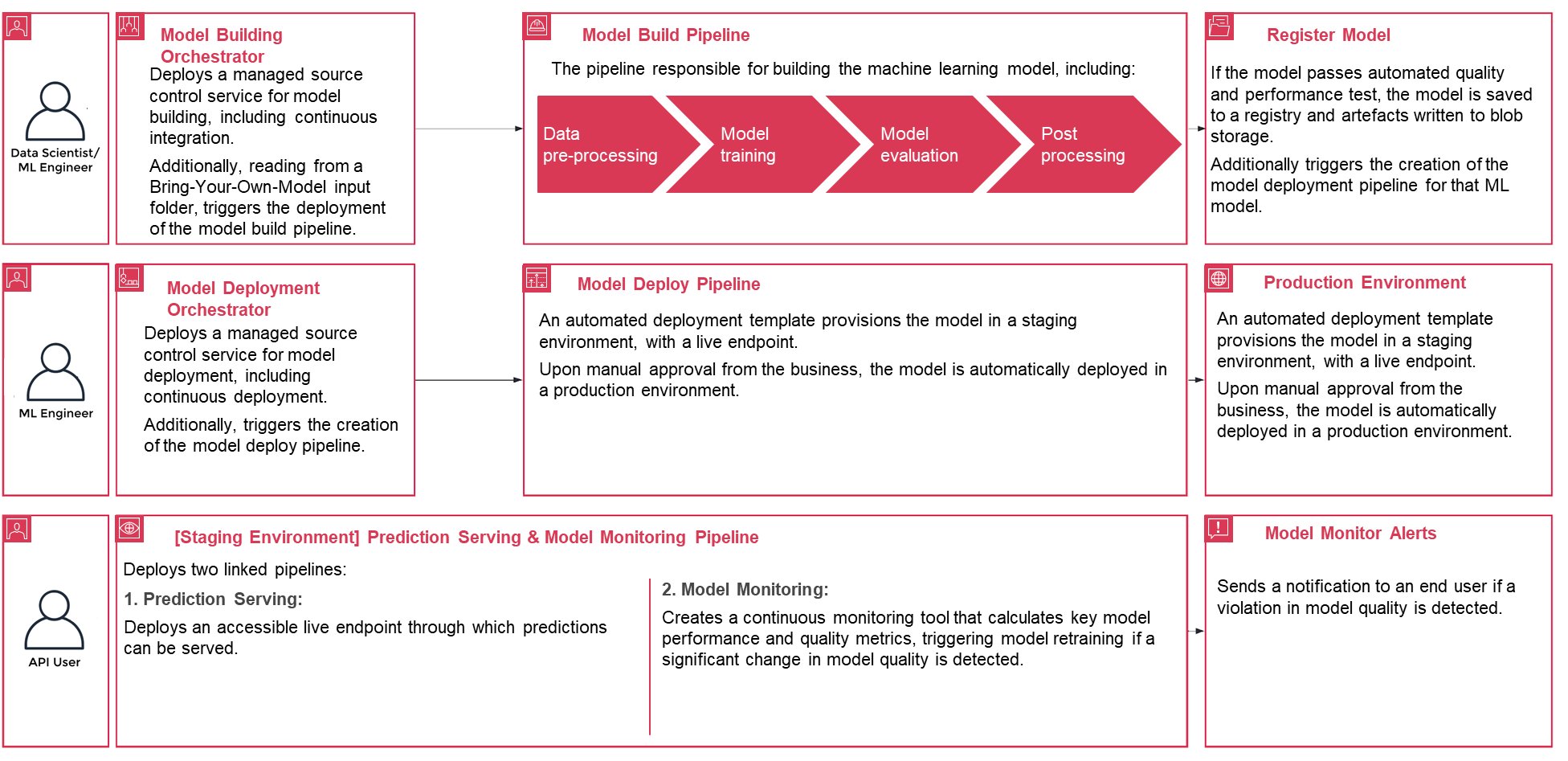
Figura 3: Ciclo de vida del proceso del Acelerador de operaciones de aprendizaje automático de PwC
- Para comenzar, inscríbase en Acelerador PwC MLOps para obtener acceso a los artefactos de la solución. Toda la solución se maneja desde un archivo YAML de configuración (
config.yaml) por modelo. Todos los detalles necesarios para ejecutar la solución están contenidos en ese archivo de configuración y almacenados junto con el modelo en un repositorio Git. El archivo de configuración servirá como entrada para automatizar los pasos del flujo de trabajo al externalizar parámetros y configuraciones importantes fuera del código. - El ingeniero de ML debe completar
config.yamlarchivo y desencadenar la canalización MLOps. Los clientes pueden configurar una cuenta de AWS, el repositorio, el modelo, los datos utilizados, el nombre de la canalización, el marco de capacitación, la cantidad de instancias que se usarán para la capacitación, el marco de inferencia y cualquier paso previo y posterior al procesamiento, y muchos otros. configuraciones para comprobar la calidad, el sesgo y la explicabilidad del modelo.

Figura 4: Configuración del acelerador de operaciones de aprendizaje automático YAML
- Se utiliza un archivo YAML simple para configurar los requisitos de entrenamiento, implementación, monitoreo y tiempo de ejecución de cada modelo. Una vez el
config.yamlse configura adecuadamente y se guarda junto con el modelo en su propio repositorio Git, se invoca el orquestador de creación de modelos. También puede leer desde un modelo Bring-Your-Own que se puede configurar a través de YAML para desencadenar la implementación de la canalización de compilación del modelo. - Todo después de este punto está automatizado por la solución y no necesita la participación ni del ingeniero de ML ni del científico de datos. El proceso responsable de construir el modelo ML incluye el preprocesamiento de datos, el entrenamiento del modelo, la evaluación del modelo y el procesamiento OST. Si el modelo pasa pruebas automatizadas de calidad y rendimiento, el modelo se guarda en un registro y los artefactos se escriben en el almacenamiento de Amazon S3 según las definiciones de los archivos YAML. Esto desencadena la creación de la canalización de implementación del modelo para ese modelo de ML.
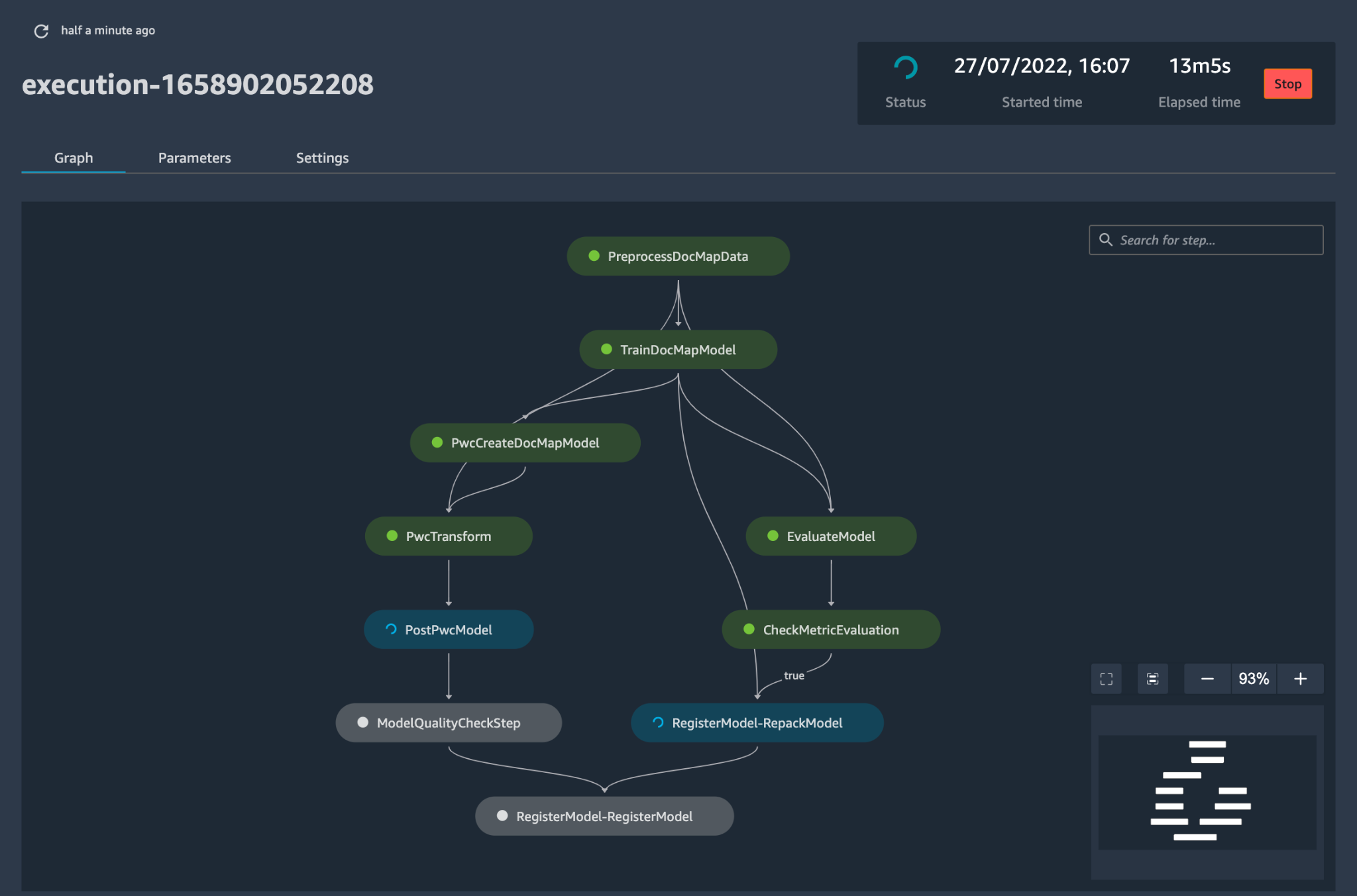
Figura 5: flujo de trabajo de implementación del modelo de muestra
- A continuación, una plantilla de implementación automatizada aprovisiona el modelo en un entorno provisional con un punto final en vivo. Tras la aprobación, el modelo se implementa automáticamente en el entorno de producción.
- La solución implementa dos canales vinculados. La prestación de predicciones implementa un punto final en vivo accesible a través del cual se pueden realizar predicciones. El monitoreo de modelos crea una herramienta de monitoreo continuo que calcula métricas clave de calidad y rendimiento del modelo, lo que activa el reentrenamiento del modelo si se detecta un cambio significativo en la calidad del modelo.
- Ahora que ha realizado la creación y la implementación inicial, el ingeniero de MLOps puede configurar alertas de fallas para recibir alertas sobre problemas, por ejemplo, cuando una canalización no realiza el trabajo previsto.
- MLOps ya no se trata de empaquetar, probar e implementar componentes de servicios en la nube similares a una implementación tradicional de CI/CD; es un sistema que debería implementar automáticamente otro servicio. Por ejemplo, la canalización de entrenamiento de modelos implementa automáticamente la canalización de implementación de modelos para habilitar el servicio de predicción, que a su vez habilita el servicio de monitoreo de modelos.
Conclusión
En resumen, MLOps es fundamental para cualquier organización que pretenda implementar modelos de ML en sistemas de producción a escala. PwC desarrolló un acelerador para automatizar la creación, implementación y mantenimiento de modelos de aprendizaje automático mediante la integración de herramientas DevOps en el proceso de desarrollo del modelo.
En esta publicación, exploramos cómo la solución de PwC está impulsada por los servicios de ML nativos de AWS y ayuda a adoptar prácticas de MLOps para que las empresas puedan acelerar su viaje hacia la IA y obtener más valor de sus modelos de ML. Analizamos los pasos que seguiría un usuario para acceder al Acelerador de operaciones de aprendizaje automático de PwC, ejecutar las canalizaciones e implementar un caso de uso de ML que integra varios componentes del ciclo de vida de un modelo de ML.
Para comenzar su viaje de MLOps en la nube de AWS a escala y ejecutar sus cargas de trabajo de producción de ML, inscríbase en Operaciones de aprendizaje automático de PwC.
Acerca de los autores
 Kiran Kumar Ballari es arquitecto principal de soluciones en Amazon Web Services (AWS). Es un evangelista al que le encanta ayudar a los clientes a aprovechar las nuevas tecnologías y crear soluciones industriales repetibles para resolver sus problemas. Le apasiona especialmente la ingeniería de software, la IA generativa y ayudar a las empresas con el desarrollo de productos de IA/ML.
Kiran Kumar Ballari es arquitecto principal de soluciones en Amazon Web Services (AWS). Es un evangelista al que le encanta ayudar a los clientes a aprovechar las nuevas tecnologías y crear soluciones industriales repetibles para resolver sus problemas. Le apasiona especialmente la ingeniería de software, la IA generativa y ayudar a las empresas con el desarrollo de productos de IA/ML.
 Ankur Goyal es director de la práctica digital y de nube de PwC Australia, centrado en datos, análisis e inteligencia artificial. Ankur tiene una amplia experiencia en el apoyo a organizaciones de los sectores público y privado para impulsar transformaciones tecnológicas y diseñar soluciones innovadoras aprovechando los activos y tecnologías de datos.
Ankur Goyal es director de la práctica digital y de nube de PwC Australia, centrado en datos, análisis e inteligencia artificial. Ankur tiene una amplia experiencia en el apoyo a organizaciones de los sectores público y privado para impulsar transformaciones tecnológicas y diseñar soluciones innovadoras aprovechando los activos y tecnologías de datos.
 Karthikeyan Chokappa (KC) es gerente de la práctica digital y de nube de PwC Australia, enfocado en datos, análisis e inteligencia artificial. A KC le apasiona diseñar, desarrollar e implementar soluciones de análisis de extremo a extremo que transforman los datos en valiosos activos de decisión para mejorar el rendimiento y la utilización y reducir el costo total de propiedad de las cosas conectadas e inteligentes.
Karthikeyan Chokappa (KC) es gerente de la práctica digital y de nube de PwC Australia, enfocado en datos, análisis e inteligencia artificial. A KC le apasiona diseñar, desarrollar e implementar soluciones de análisis de extremo a extremo que transforman los datos en valiosos activos de decisión para mejorar el rendimiento y la utilización y reducir el costo total de propiedad de las cosas conectadas e inteligentes.
 Rama Lankalapalli es arquitecto de soluciones de socio sénior en AWS y trabaja con PwC para acelerar las migraciones y modernizaciones de sus clientes a AWS. Trabaja en diversas industrias para acelerar la adopción de la nube de AWS. Su experiencia radica en la arquitectura de soluciones en la nube eficientes y escalables, impulsando la innovación y la modernización de las aplicaciones de los clientes aprovechando los servicios de AWS y estableciendo bases de nube resilientes.
Rama Lankalapalli es arquitecto de soluciones de socio sénior en AWS y trabaja con PwC para acelerar las migraciones y modernizaciones de sus clientes a AWS. Trabaja en diversas industrias para acelerar la adopción de la nube de AWS. Su experiencia radica en la arquitectura de soluciones en la nube eficientes y escalables, impulsando la innovación y la modernización de las aplicaciones de los clientes aprovechando los servicios de AWS y estableciendo bases de nube resilientes.
 Jeejee Unwalla es un arquitecto de soluciones senior en AWS que disfruta guiar a los clientes en la resolución de desafíos y pensar estratégicamente. Le apasiona la tecnología, los datos y permitir la innovación.
Jeejee Unwalla es un arquitecto de soluciones senior en AWS que disfruta guiar a los clientes en la resolución de desafíos y pensar estratégicamente. Le apasiona la tecnología, los datos y permitir la innovación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/driving-advanced-analytics-outcomes-at-scale-using-amazon-sagemaker-powered-pwcs-machine-learning-ops-accelerator/

