
Foto de Google Mente profunda
El aprendizaje profundo es una rama del modelo de aprendizaje automático basado en redes neuronales. En el otro modelo de máquina, el procesamiento de datos para encontrar características significativas a menudo se realiza manualmente o depende de la experiencia en el campo; sin embargo, el aprendizaje profundo puede imitar el cerebro humano para descubrir las características esenciales, aumentando el rendimiento del modelo.
Existen muchas aplicaciones para modelos de aprendizaje profundo, incluido el reconocimiento facial, la detección de fraude, la conversión de voz a texto, la generación de texto y muchas más. El aprendizaje profundo se ha convertido en un enfoque estándar en muchas aplicaciones avanzadas de aprendizaje automático y no tenemos nada que perder aprendiendo sobre ellas.
Para desarrollar este modelo de aprendizaje profundo, existen varios marcos de biblioteca en los que podemos confiar en lugar de trabajar desde cero. En este artículo, analizaremos dos bibliotecas diferentes que podemos utilizar para desarrollar modelos de aprendizaje profundo: PyTorch y Lighting AI. Entremos en ello.
PyTorch es un marco de biblioteca de código abierto para entrenar redes neuronales de aprendizaje profundo. PyTorch fue desarrollado por el grupo Meta en 2016 y ha ganado popularidad. El aumento de popularidad se debió a la función PyTorch que combina la biblioteca backend de GPU de Torch con lenguaje Python. Esta combinación hace que el paquete sea fácil de seguir para el usuario pero sigue siendo potente para desarrollar el modelo de aprendizaje profundo.
Hay algunos destacados Características de PyTorch que están habilitados por las bibliotecas, incluida una interfaz agradable, capacitación distribuida y un proceso de experimentación rápido y flexible. Debido a que hay muchos usuarios de PyTorch, el desarrollo y la inversión de la comunidad también fueron masivos. Es por eso que aprender PyTorch sería beneficioso a largo plazo.
El bloque de construcción de PyTorch es un tensor, una matriz multidimensional utilizada para codificar todos los parámetros de entrada, salida y modelo. Puedes imaginar un tensor como la matriz NumPy pero con la capacidad de ejecutarse en GPU.
Probemos la biblioteca PyTorch. Se recomienda realizar el tutorial en la nube, como Google Colab si no tienes acceso a un sistema GPU (aunque aún podría funcionar con una CPU). Pero, si desea comenzar en local, necesitamos instalar la biblioteca a través de esta página. Seleccione el sistema apropiado y las especificaciones que tenga.
Por ejemplo, el siguiente código es para la instalación de pip si tiene un sistema compatible con CUDA.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Una vez finalizada la instalación, probemos algunas capacidades de PyTorch para desarrollar el modelo de aprendizaje profundo. Haremos un modelo de clasificación de imágenes simple con PyTorch en este tutorial basado en su tutorial web. Caminaríamos sobre el código y tendríamos una explicación de lo que sucedió dentro del código.
Primero, descargaríamos el conjunto de datos con PyTorch. Para este ejemplo, usaríamos el conjunto de datos MNIST, que es el conjunto de datos de clasificación escritos a mano.
from torchvision import datasets train = datasets.MNIST( root="image_data", train=True, download=True
) test = datasets.MNIST( root="image_data", train=False, download=True,
)
Descargamos tanto el tren MNIST como los conjuntos de datos de prueba a nuestra carpeta raíz. Veamos cómo se ve nuestro conjunto de datos.
import matplotlib.pyplot as plt for i, (img, label) in enumerate(list(train)[:10]): plt.subplot(2, 5, i+1) plt.imshow(img, cmap="gray") plt.title(f'Label: {label}') plt.axis('off') plt.show()

Cada imagen es un número de un solo dígito entre cero y nueve, lo que significa que tenemos diez etiquetas. A continuación, desarrollemos un clasificador de imágenes basado en este conjunto de datos.
Necesitamos transformar el conjunto de datos de imágenes en un tensor para desarrollar un modelo de aprendizaje profundo con PyTorch. Como nuestra imagen es un objeto PIL, podemos usar la función PyTorch ToTensor para realizar la transformación. Además, podemos transformar automáticamente la imagen con la función de conjuntos de datos.
from torchvision.transforms import ToTensor
train = datasets.MNIST( root="data", train=True, download=True, transform=ToTensor()
) test = datasets.MNIST( root="data", train=False, download=True, transform=ToTensor()
)
Al pasar la función de transformación al parámetro de transformación, podemos controlar cómo serían los datos. A continuación, empaquetaríamos los datos en el objeto DataLoader para que el modelo PyTorch pudiera acceder a los datos de nuestra imagen.
from torch.utils.data import DataLoader
size = 64 train_dl = DataLoader(train, batch_size=size)
test_dl = DataLoader(test, batch_size=size) for X, y in test_dl: print(f"Shape of X [N, C, H, W]: {X.shape}") print(f"Shape of y: {y.shape} {y.dtype}") break
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
En el código anterior, creamos un objeto DataLoader para los datos de entrenamiento y prueba. Cada iteración del lote de datos devolvería 64 características y etiquetas en el objeto anterior. Además, la forma de nuestra imagen es 28 * 28 (alto * ancho).
A continuación, desarrollaríamos el objeto modelo de red neuronal.
from torch import nn #Change to 'cuda' if you have access to GPU
device = 'cpu' class NNModel(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.lr_stack = nn.Sequential( nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): x = self.flatten(x) logits = self.lr_stack(x) return logits model = NNModel().to(device)
print(model)
NNModel( (flatten): Flatten(start_dim=1, end_dim=-1) (lr_stack): Sequential( (0): Linear(in_features=784, out_features=128, bias=True) (1): ReLU() (2): Linear(in_features=128, out_features=128, bias=True) (3): ReLU() (4): Linear(in_features=128, out_features=10, bias=True) )
)
En el objeto de arriba, creamos un modelo neuronal con una estructura de pocas capas. Para desarrollar el objeto Modelo neuronal, utilizamos el método de subclasificación con la función nn.module y creamos las capas de la red neuronal dentro de __init__.
Inicialmente convertimos los datos de la imagen 2D en valores de píxeles dentro de la capa con la función de aplanar. Luego, usamos la función secuencial para envolver nuestra capa en una secuencia de capas. Dentro de la función secuencial, tenemos nuestra capa modelo:
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
Por secuencia, lo que sucede arriba es:
- Primero, la entrada de datos, que tiene 28 * 28 características, se transforma utilizando una función lineal en la capa lineal y tiene 128 características como salida.
- ReLU es una función de activación no lineal que está presente entre la entrada y la salida del modelo para introducir no linealidad.
- 128 entidades ingresadas a la capa lineal y tienen 128 entidades de salida
- Otra función de activación de ReLU
- 128 entidades como entrada en la capa lineal y 10 entidades como salida (nuestra etiqueta de conjunto de datos solo tiene 10 etiquetas).
Por último, la función directa está presente para el proceso de entrada real del modelo. A continuación, el modelo necesitaría una función de pérdida y una función de optimización.
from torch.optim import SGD loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-3)
Para el siguiente código, simplemente preparamos la capacitación y las pruebas antes de ejecutar la actividad de modelado.
import torch
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) model.train() for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) loss.backward() optimizer.step() optimizer.zero_grad() if batch % 100 == 0: loss, current = loss.item(), (batch + 1) * len(X) print(f"loss: {loss:>2f} [{current:>5d}/{size:>5d}]") def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>2f} n")
Ahora estamos listos para ejecutar nuestro entrenamiento modelo. Decidiríamos cuántas épocas (iteraciones) queremos realizar con nuestro modelo. Para este ejemplo, digamos que queremos que se ejecute cinco veces.
epoch = 5
for i in range(epoch): print(f"Epoch {i+1}n-------------------------------") train(train_dl, model, loss_fn, optimizer) test(test_dl, model, loss_fn)
print("Done!")
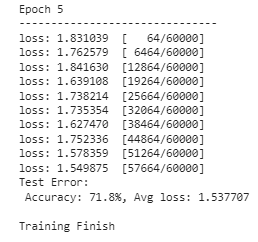
El modelo ahora ha terminado su entrenamiento y puede usarse para cualquier actividad de predicción de imágenes. El resultado podría variar, así que espere resultados diferentes a los de la imagen de arriba.
Son solo algunas de las cosas que PyTorch puede hacer, pero puede ver que construir un modelo con PyTorch es fácil. Si está interesado en el modelo previamente entrenado, PyTorch tiene un Placa del Motor Puedes entrar.
Iluminación IA es una empresa que ofrece varios productos para minimizar el tiempo para entrenar el modelo de aprendizaje profundo de PyTorch y simplificarlo. Uno de sus productos de código abierto es Iluminación PyTorch, que es una biblioteca que ofrece un marco para entrenar e implementar el modelo PyTorch.
Lighting ofrece algunas características, que incluyen flexibilidad de código, sin texto estándar, API mínima y colaboración en equipo mejorada. La iluminación también ofrece características como la utilización de múltiples GPU y un entrenamiento rápido y de baja precisión. Esto convirtió a Lighting en una buena alternativa para desarrollar nuestro modelo PyTorch.
Probemos el desarrollo del modelo con Lighting. Para comenzar, necesitamos instalar el paquete.
pip install lightning
Con Lighting instalado, también instalaríamos otro producto Lighting AI llamado AntorchaMétricas para simplificar la selección de métricas.
pip install torchmetrics
Con todas las bibliotecas instaladas, intentaríamos desarrollar el mismo modelo de nuestro ejemplo anterior utilizando un contenedor de iluminación. A continuación se muestra el código completo para desarrollar el modelo.
import torch
import torchmetrics
import pytorch_lightning as pl
from torch import nn
from torch.optim import SGD # Change to 'cuda' if you have access to GPU
device = 'cpu' class NNModel(pl.LightningModule): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.lr_stack = nn.Sequential( nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10) ) self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10) self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10) def forward(self, x): x = self.flatten(x) logits = self.lr_stack(x) return logits def training_step(self, batch, batch_idx): x, y = batch x, y = x.to(device), y.to(device) pred = self(x) loss = nn.CrossEntropyLoss()(pred, y) self.log('train_loss', loss) # Compute training accuracy acc = self.train_acc(pred.softmax(dim=-1), y) self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True) return loss def configure_optimizers(self): return SGD(self.parameters(), lr=1e-3) def test_step(self, batch, batch_idx): x, y = batch x, y = x.to(device), y.to(device) pred = self(x) loss = nn.CrossEntropyLoss()(pred, y) self.log('test_loss', loss) # Compute test accuracy acc = self.valid_acc(pred.softmax(dim=-1), y) self.log('test_acc', acc, on_step=True, on_epoch=True, prog_bar=True) return loss
Analicemos lo que sucede en el código anterior. La diferencia con el modelo PyTorch que desarrollamos anteriormente es que la clase NNModel ahora usa subclases de LightingModule. Además, asignamos las métricas de precisión para evaluar utilizando TorchMetrics. Luego, agregamos el paso de capacitación y prueba dentro de la clase y configuramos la función de optimización.
Con todos los modelos configurados, ejecutaríamos el entrenamiento del modelo utilizando el objeto DataLoader transformado para entrenar nuestro modelo.
# Create a PyTorch Lightning trainer
trainer = pl.Trainer(max_epochs=5) # Create the model
model = NNModel() # Fit the model
trainer.fit(model, train_dl) # Test the model
trainer.test(model, test_dl) print("Training Finish")
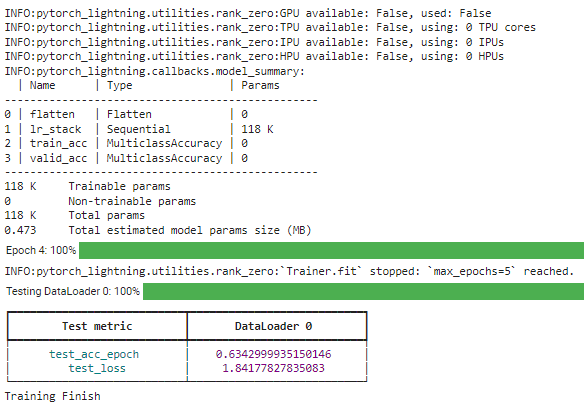
Con la biblioteca de Iluminación, podemos modificar fácilmente la estructura que necesita. Para leer más, puede leer su documentación.
PyTorch es una biblioteca para desarrollar modelos de aprendizaje profundo y nos proporciona un marco sencillo para acceder a muchas API avanzadas. Lighting AI también es compatible con la biblioteca, que proporciona un marco para simplificar el desarrollo del modelo y mejorar la flexibilidad del desarrollo. Este artículo nos presentó tanto las características de la biblioteca como la implementación de código simple.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios de escritura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/introduction-to-deep-learning-libraries-pytorch-and-lightning-ai?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-deep-learning-libraries-pytorch-and-lightning-ai

