En los últimos años, los lagos de datos se han convertido en una arquitectura convencional y la validación de la calidad de los datos es un factor crítico para mejorar la reutilización y la coherencia de los datos. Calidad de datos de AWS Glue reduce el esfuerzo necesario para validar datos de días a horas y proporciona recomendaciones informáticas, estadísticas e información sobre los recursos necesarios para ejecutar la validación de datos.
La calidad de datos de AWS Glue se basa en Dee Qu, una herramienta de código abierto desarrollada y utilizada en Amazon para calcular métricas de calidad de datos y verificar restricciones de calidad de datos y cambios en la distribución de datos para que pueda concentrarse en describir cómo deben verse los datos en lugar de implementar algoritmos.
En esta publicación, proporcionamos resultados comparativos de la ejecución de conjuntos de reglas de calidad de datos cada vez más complejos sobre un conjunto de datos de prueba predefinido. Como parte de los resultados, mostramos cómo AWS Glue Data Quality proporciona información sobre el tiempo de ejecución de los trabajos de extracción, transformación y carga (ETL), los recursos medidos en términos de unidades de procesamiento de datos (DPU) y cómo se puede realizar un seguimiento del costo. de ejecutar AWS Glue Data Quality para canalizaciones ETL mediante la definición de informes de costos personalizados en AWS Cost Explorer.
Resumen de la solución
Comenzamos definiendo nuestro conjunto de datos de prueba para explorar cómo la calidad de datos de AWS Glue escala automáticamente según los conjuntos de datos de entrada.
Detalles del conjunto de datos
El conjunto de datos de prueba contiene 104 columnas y 1 millón de filas almacenadas en formato Parquet. Puede descargar el conjunto de datos o recrearlo localmente usando el script Python proporcionado en el repositorio. Si opta por ejecutar el script del generador, deberá instalar el pandas y Mimetismo paquetes en su entorno Python:
El esquema del conjunto de datos es una combinación de variables numéricas, categóricas y de cadena para tener suficientes atributos para utilizar una combinación de calidad de datos de AWS Glue integrada. tipos de reglas. El esquema replica algunos de los atributos más comunes que se encuentran en los datos del mercado financiero, como el ticker de instrumentos, los volúmenes negociados y las previsiones de precios.
Conjuntos de reglas de calidad de datos
Clasificamos algunos de los tipos de reglas integradas de calidad de datos de AWS Glue para definir la estructura de referencia. Las categorías consideran si las reglas realizan comprobaciones de columnas que no requieren inspección a nivel de fila (reglas simples), análisis fila por fila (reglas medias) o comprobaciones de tipos de datos, comparando eventualmente los valores de las filas con otras fuentes de datos (reglas complejas). ). La siguiente tabla resume estas reglas.
| Reglas simples | Reglas medias | Reglas complejas |
| ColumnCount | DistinctValuesCount | valores de columna |
| Tipo de datos de columna | Esta completo | Integridad |
| ColumnExist | Suma | Integridad referencial |
| NombresdecolumnaCoincidenciaPatrón | Desviación Estándar | Correlación de columnas |
| Recuento de filas | Media | Coincidencia de recuento de filas |
| Longitud de columna | . | . |
Definimos ocho trabajos ETL de AWS Glue diferentes donde ejecutamos los conjuntos de reglas de calidad de datos. Cada trabajo tiene un número diferente de reglas de calidad de datos asociadas. Cada trabajo también tiene un asociado etiqueta de asignación de costos definida por el usuario que utilizamos para crear un informe de costos de calidad de datos en AWS Cost Explorer más adelante.
Proporcionamos la definición en texto plano para cada conjunto de reglas en la siguiente tabla.
| Nombre del trabajo | Reglas simples | Reglas medias | Reglas complejas | Número de reglas | Etiqueta | Definición |
| conjunto de reglas-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | – |
| conjunto de reglas-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Enlace |
| conjunto de reglas-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Enlace |
| conjunto de reglas-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Enlace |
| conjunto de reglas-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Enlace |
| conjunto de reglas-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Enlace |
| conjunto de reglas-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Enlace |
| conjunto de reglas-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Enlace |
Cree los trabajos ETL de AWS Glue que contienen los conjuntos de reglas de calidad de datos
Subimos el conjunto de datos de prueba a Servicio de almacenamiento simple de Amazon (Amazon S3) y también dos archivos CSV adicionales que usaremos para evaluar las reglas de integridad referencial en AWS Glue Data Quality (isocódigos.csv y intercambios.csv) después de que se hayan agregado al catálogo de datos de AWS Glue. Complete los siguientes pasos:
- En la consola de Amazon S3, cree un nuevo depósito S3 en su cuenta y cargue el conjunto de datos de prueba.
- Cree una carpeta en el depósito de S3 llamada
isocodesy subir el isocódigos.csv archivo. - Cree otra carpeta en el depósito de S3 llamada Exchange y cargue el intercambios.csv archivo.
- En la consola de AWS Glue, ejecute dos rastreadores de AWS Glue, uno para cada carpeta para registrar el contenido CSV en el catálogo de datos de AWS Glue (
data_quality_catalog). Para obtener instrucciones, consulte Agregar un rastreador de AWS Glue.
Los rastreadores de AWS Glue generan dos tablas (exchanges y isocodes) como parte del catálogo de datos de AWS Glue.

Ahora crearemos el Gestión de identidades y accesos de AWS (YO SOY) papel que serán asumidos por los trabajos ETL en tiempo de ejecución:
- En la consola de IAM, cree una nueva función de IAM denominada
AWSGlueDataQualityPerformanceRole - Tipo de entidad de confianza, seleccione Servicio de AWS.
- Servicio o caso de uso, escoger pegamento.
- Elige Siguiente.

- Políticas de permisos, introduzca
AWSGlueServiceRole - Elige Siguiente.

- Cree y adjunte una nueva política en línea (
AWSGlueDataQualityBucketPolicy) con el siguiente contenido. Reemplace el marcador de posición con el nombre del depósito S3 que creó anteriormente:
A continuación, creamos uno de los trabajos ETL de AWS Glue, ruleset-5.
- En la consola de AWS Glue, debajo de Empleos de ETL en el panel de navegación, elija ETL visuales.
- En Crear trabajo sección, elija ETL visuales.x

- En el editor visual, agregue un Fuente de datos: depósito S3 nodo fuente:
- URL de S3, ingrese a la carpeta S3 que contiene el conjunto de datos de prueba.
- Formato de datos, escoger parquet.

- Crea un nuevo nodo de acción, Transformar: Evaluar-Datos-Catálogo:
- Padres de nodo, elija el nodo que creó.
- Agregue la definición del conjunto de reglas-5 bajo editor de conjunto de reglas.

- Desplácese hasta el final y debajo Configuración de rendimiento, habilitar Datos de caché.

- under Detalles del trabajo, Para Rol de IAM, escoger
AWSGlueDataQualityPerformanceRole.
- En Etiquetas sección, definir dqjob etiquetar como rs5.
Esta etiqueta será diferente para cada uno de los trabajos ETL de calidad de datos; los usamos en AWS Cost Explorer para revisar el costo de los trabajos ETL.

- Elige Guardar.
- Repita estos pasos con el resto de los conjuntos de reglas para definir todos los trabajos ETL.

Ejecute los trabajos ETL de AWS Glue
Complete los siguientes pasos para ejecutar los trabajos ETL:
- En la consola de AWS Glue, elija ETL visuales bajo Empleos de ETL en el panel de navegación.
- Seleccione el trabajo ETL y elija Ejecutar trabajo.
- Repita para todos los trabajos de ETL.

Cuando los trabajos ETL estén completos, el Supervisión de ejecución de trabajos La página mostrará los detalles del trabajo. Como se muestra en la siguiente captura de pantalla, un horas de UPD Se proporciona una columna para cada trabajo ETL.

Revisar el desempeño
La siguiente tabla resume la duración, las horas de DPU y los costos estimados de ejecutar los ocho conjuntos de reglas de calidad de datos diferentes en el mismo conjunto de datos de prueba. Tenga en cuenta que todos los conjuntos de reglas se ejecutaron con el conjunto de datos de prueba completo descrito anteriormente (104 columnas, 1 millón de filas).
| Nombre del trabajo ETL | Número de reglas | Etiqueta | Duración (seg) | # de horas de DPU | # de DPU | Costo ($) |
| conjunto de reglas-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| conjunto de reglas-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| conjunto de reglas-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| conjunto de reglas-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| conjunto de reglas-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| conjunto de reglas-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| conjunto de reglas-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| conjunto de reglas-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
El costo de evaluar un conjunto de reglas vacío es cercano a cero, pero se incluyó porque se puede utilizar como una prueba rápida para validar los roles de IAM asociados a los trabajos de calidad de datos de AWS Glue y los permisos de lectura del conjunto de datos de prueba en Amazon S3. El costo de los trabajos de calidad de datos solo comienza a aumentar después de evaluar conjuntos de reglas con más de 100 reglas, permaneciendo constante por debajo de ese número.
Podemos observar que el costo de ejecutar la calidad de los datos para el conjunto de reglas más grande en el punto de referencia (400 reglas) todavía está ligeramente por encima de $0.50.
Análisis de costos de calidad de datos en AWS Cost Explorer
Para ver las etiquetas de trabajo ETL de calidad de datos en AWS Cost Explorer, debe activar las etiquetas de asignación de costos definidas por el usuario de antemano.
Después de crear y aplicar etiquetas definidas por el usuario a sus recursos, las claves de etiqueta pueden tardar hasta 24 horas en aparecer en su página de etiquetas de asignación de costos para su activación. Luego, las claves de etiqueta pueden tardar hasta 24 horas en activarse.
- en la AWS Explorador de costos consola, elige Informes guardados de Cost Explorer en el panel de navegación.
- Elige Crear nuevo informe.

- Seleccione Costo y uso como tipo de informe.
- Elige Crear reporte.
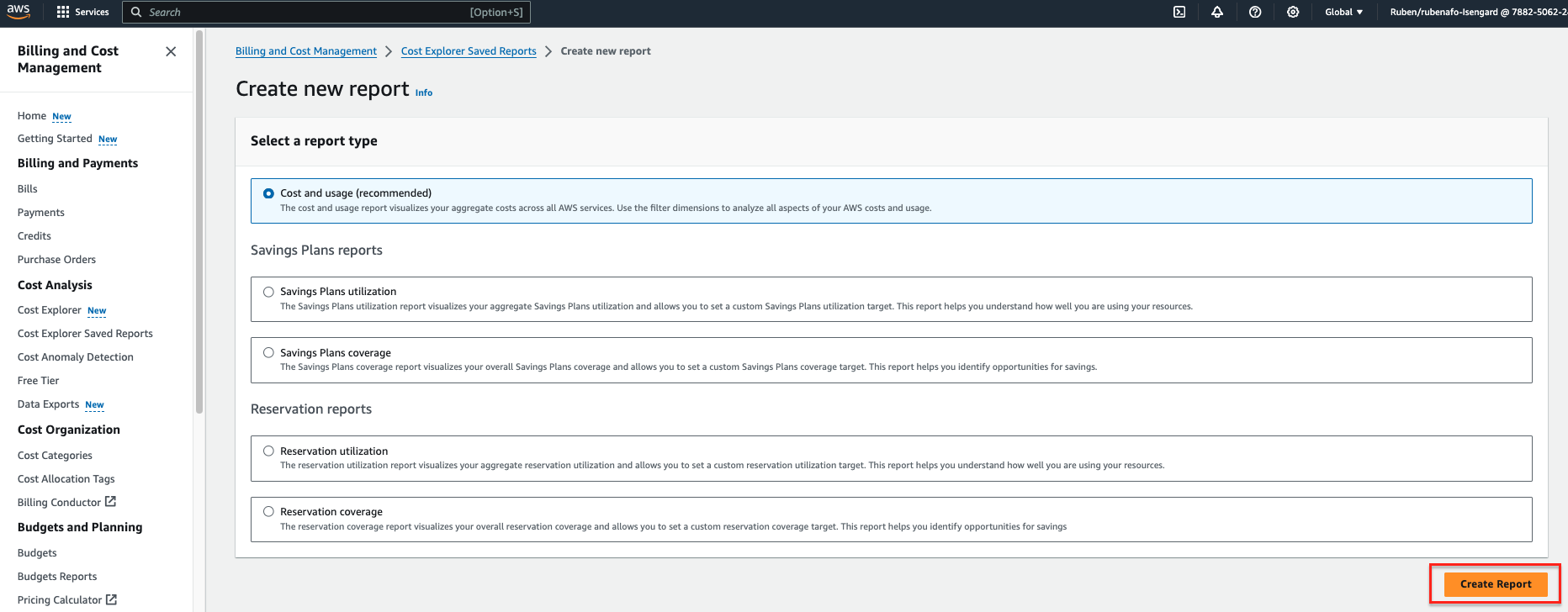
- Intervalo de fechas, ingresa un rango de fechas.
- granularidadescoger Diario.
- Dimensiones, escoger Etiqueta, luego elige el
dqjobetiqueta.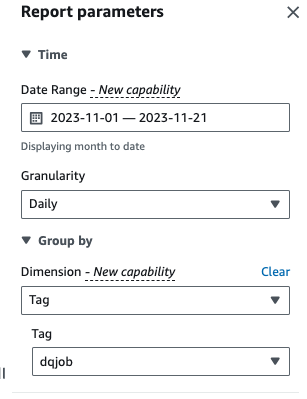
- under Filtros aplicados, elegir la
dqjobetiqueta y las ocho etiquetas utilizadas en los conjuntos de reglas de calidad de datos (rs0, rs1, rs5, rs10, rs50, rs100, rs200 y rs400).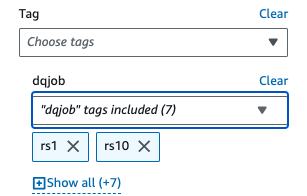
- Elige Aplicá.
Se actualizará el informe de costo y uso. El eje X muestra las etiquetas del conjunto de reglas de calidad de datos como categorías. El Costo y uso El gráfico en AWS Cost Explorer se actualizará y mostrará el costo mensual total de los últimos trabajos ETL de calidad de datos ejecutados, agregados por trabajo ETL.

Limpiar
Para limpiar la infraestructura y evitar cargos adicionales, complete los siguientes pasos:
- Vacíe el depósito de S3 creado inicialmente para almacenar el conjunto de datos de prueba.
- Elimine los trabajos ETL que creó en AWS Glue.
- Eliminar el
AWSGlueDataQualityPerformanceRoleRol de IAM. - Elimine el informe personalizado creado en AWS Cost Explorer.
Conclusión
AWS Glue Data Quality proporciona una forma eficiente de incorporar la validación de la calidad de los datos como parte de las canalizaciones de ETL y se escala automáticamente para adaptarse a volúmenes crecientes de datos. Los tipos de reglas de calidad de datos integrados ofrecen una amplia gama de opciones para personalizar las comprobaciones de calidad de los datos y centrarse en cómo deben verse sus datos en lugar de implementar una lógica indiferenciada.
En este análisis comparativo, mostramos cómo los conjuntos de reglas de calidad de datos de AWS Glue de tamaño común tienen poca o ninguna sobrecarga, mientras que en casos complejos, el costo aumenta linealmente. También revisamos cómo se pueden etiquetar trabajos de calidad de datos de AWS Glue para que la información de costos esté disponible en AWS Cost Explorer para generar informes rápidos.
La calidad de los datos de AWS Glue es generalmente disponible en todas las regiones de AWS donde AWS Glue está disponible. Obtenga más información sobre la calidad de datos de AWS Glue y el catálogo de datos de AWS Glue en Primeros pasos con AWS Glue Data Quality del catálogo de datos de AWS Glue.
Acerca de los autores
 Rubén Alfonso es arquitecto de soluciones de servicios financieros globales en AWS. Le gusta trabajar en desafíos de análisis y IA/ML, y le apasiona la automatización y la optimización. Cuando no está en el trabajo, le gusta encontrar lugares escondidos fuera de las rutas turísticas habituales de Barcelona.
Rubén Alfonso es arquitecto de soluciones de servicios financieros globales en AWS. Le gusta trabajar en desafíos de análisis y IA/ML, y le apasiona la automatización y la optimización. Cuando no está en el trabajo, le gusta encontrar lugares escondidos fuera de las rutas turísticas habituales de Barcelona.
 Kalyan Kumar Neelampudi (KK) es arquitecto de soluciones de socios especialistas (análisis de datos e inteligencia artificial generativa) en AWS. Actúa como asesor técnico y colabora con varios socios de AWS para diseñar, implementar y desarrollar prácticas en torno al análisis de datos y cargas de trabajo de IA/ML. Fuera del trabajo, es un entusiasta del bádminton y un aventurero culinario, explora las cocinas locales y viaja con su pareja para descubrir nuevos gustos y experiencias.
Kalyan Kumar Neelampudi (KK) es arquitecto de soluciones de socios especialistas (análisis de datos e inteligencia artificial generativa) en AWS. Actúa como asesor técnico y colabora con varios socios de AWS para diseñar, implementar y desarrollar prácticas en torno al análisis de datos y cargas de trabajo de IA/ML. Fuera del trabajo, es un entusiasta del bádminton y un aventurero culinario, explora las cocinas locales y viaja con su pareja para descubrir nuevos gustos y experiencias.

gonzalo herreros es Arquitecto Senior de Big Data en el equipo de AWS Glue.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

