
Imagen del autor
Mistral AI, una de las empresas de investigación de IA líderes en el mundo, ha lanzado recientemente el modelo base para Mistral 7B v0.2.
Este modelo de lenguaje de código abierto se dio a conocer durante el evento hackathon de la compañía el 23 de marzo de 2024.
Los modelos Mistral 7B tienen 7.3 millones de parámetros, lo que los hace extremadamente potentes. Superan a Llama 2 13B y Llama 1 34B en casi todos los puntos de referencia. El último modelo V0.2 introduce una ventana de contexto de 32k, entre otros avances, mejorando su capacidad para procesar y generar texto.
Además, la versión que se anunció recientemente es el modelo base de la variante adaptada a las instrucciones, “Mistral-7B-Instruct-V0.2”, que se lanzó a principios del año pasado.
En este tutorial, le mostraré cómo acceder y ajustar este modelo de lenguaje en Hugging Face.
Estaremos afinando el modelo base Mistral 7B-v0.2 usando la funcionalidad AutoTrain de Hugging Face.
Abrazando la cara es conocido por democratizar el acceso a modelos de aprendizaje automático, permitiendo a los usuarios cotidianos desarrollar soluciones avanzadas de IA.
AutoTrain, una función de Hugging Face, automatiza el proceso de entrenamiento de modelos, haciéndolo accesible y eficiente.
Ayuda a los usuarios a seleccionar los mejores parámetros y técnicas de entrenamiento al ajustar los modelos, lo cual es una tarea que de otro modo puede resultar desalentadora y consumir mucho tiempo.
Aquí hay 5 pasos para ajustar su modelo Mistral-7B:
1. Configuración del entorno
Primero debe crear una cuenta con Hugging Face y luego crear un repositorio de modelos.
Para lograr esto, simplemente siga los pasos proporcionados en este liga y vuelve a este tutorial.
Entrenaremos el modelo en Python. Cuando se trata de seleccionar un entorno de portátil para la capacitación, puede utilizar Cuadernos Kaggle or Colaboración de Google, los cuales brindan acceso gratuito a GPU.
Si el proceso de capacitación lleva demasiado tiempo, es posible que desee cambiar a una plataforma en la nube como AWS Sagemaker o Azure ML.
Finalmente, realice las siguientes instalaciones de pip antes de comenzar a codificar con este tutorial:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Preparando su conjunto de datos
En este tutorial, usaremos el conjunto de datos de alpaca en Hugging Face, que se ve así:
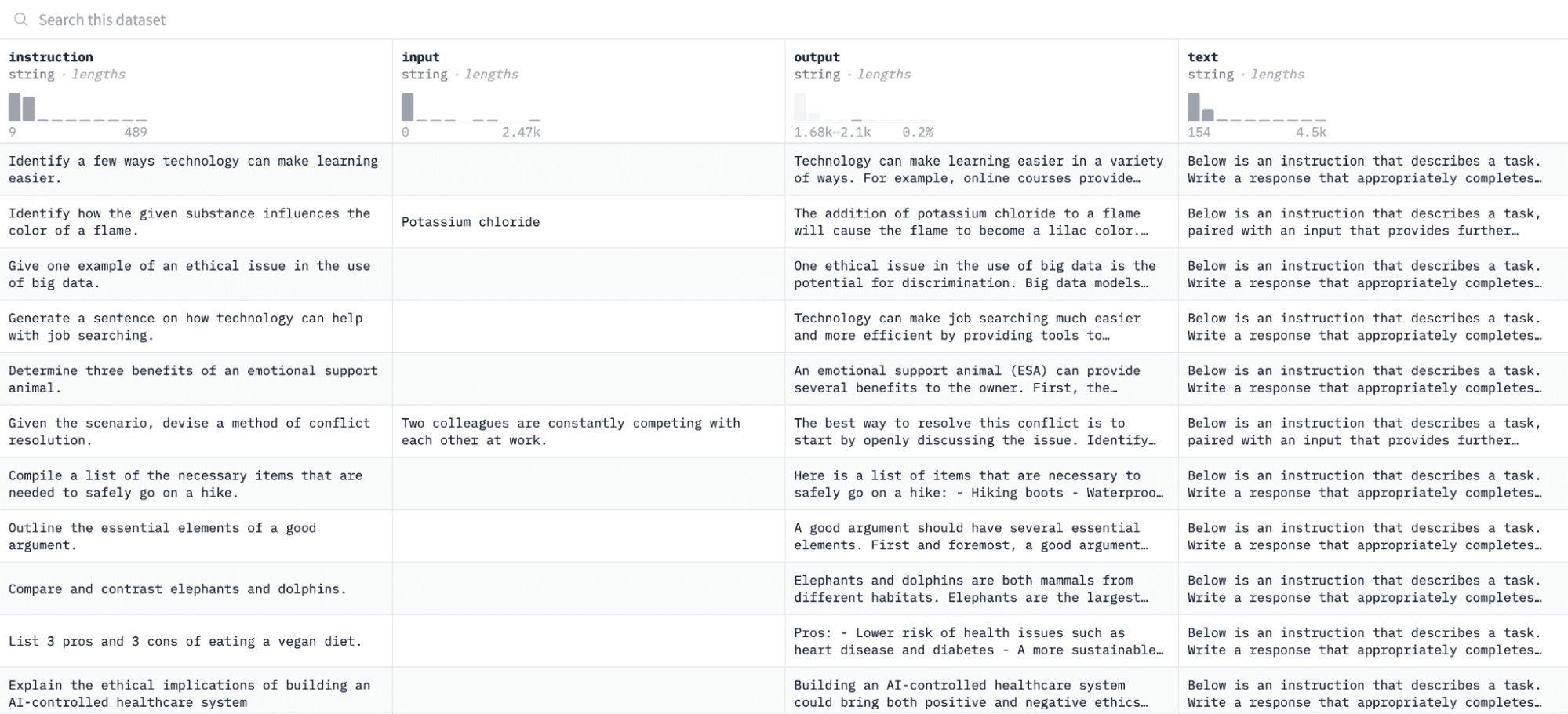
Afinaremos el modelo en pares de instrucciones y resultados y evaluaremos su capacidad para responder a la instrucción dada en el proceso de evaluación.
Para acceder y preparar este conjunto de datos, ejecute las siguientes líneas de código:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")La primera función cargará el conjunto de datos de Alpaca usando la biblioteca "conjuntos de datos" y lo limpiará para garantizar que no incluyamos instrucciones vacías. La segunda función estructura tus datos en un formato que AutoTrain pueda entender.
Después de ejecutar el código anterior, el conjunto de datos se cargará, formateará y guardará en la ruta especificada. Cuando abra su conjunto de datos formateado, debería ver una sola columna denominada "texto_formateado".
3. Configurar tu entorno de entrenamiento
Ahora que ha preparado correctamente el conjunto de datos, procedamos a configurar el entorno de entrenamiento de su modelo.
Para hacer esto, debe definir los siguientes parámetros:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Aquí hay un desglose de las especificaciones anteriores:
- Puedes especificar cualquier nombre del proyecto. Aquí es donde se almacenarán todos sus archivos de proyecto y capacitación.
- El nombre del modelo El parámetro es el modelo que desea ajustar. En este caso, he especificado una ruta al Modelo base Mistral-7B v0.2 en Cara Abrazadora.
- El token_hf La variable debe configurarse en su token Hugging Face, que se puede obtener navegando a este enlace.
- tú repositorio_id debe configurarse en el repositorio de modelos de Hugging Face que creó en el primer paso de este tutorial. Por ejemplo, mi ID de repositorio es NatasshaS/Modelo2.
4. Configurar los parámetros del modelo.
Antes de ajustar nuestro modelo, debemos definir los parámetros de entrenamiento, que controlan aspectos del comportamiento del modelo, como la duración del entrenamiento y la regularización.
Estos parámetros influyen en aspectos clave como cuánto tiempo se entrena el modelo, cómo aprende de los datos y cómo evita el sobreajuste.
Puede configurar los siguientes parámetros para su modelo:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Establecer variables de entorno
Preparemos ahora nuestro entorno de entrenamiento configurando algunas variables de entorno.
Este paso garantiza que la función AutoTrain utilice la configuración deseada para ajustar el modelo, como el nombre de nuestro proyecto y las preferencias de entrenamiento:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Iniciar la formación modelo
Finalmente, comencemos a entrenar el modelo usando el tren automático dominio. Este paso implica especificar su modelo, conjunto de datos y configuraciones de entrenamiento, como se muestra a continuación:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Asegúrese de cambiar el Ruta de datos hasta donde se encuentra su conjunto de datos de entrenamiento.
7. Evaluación del modelo
Una vez que su modelo haya terminado de entrenar, debería ver aparecer una carpeta en su directorio con el mismo título que el nombre de su proyecto.
En mi caso, esta carpeta se titula “mistralai” como se ve en la imagen a continuación:
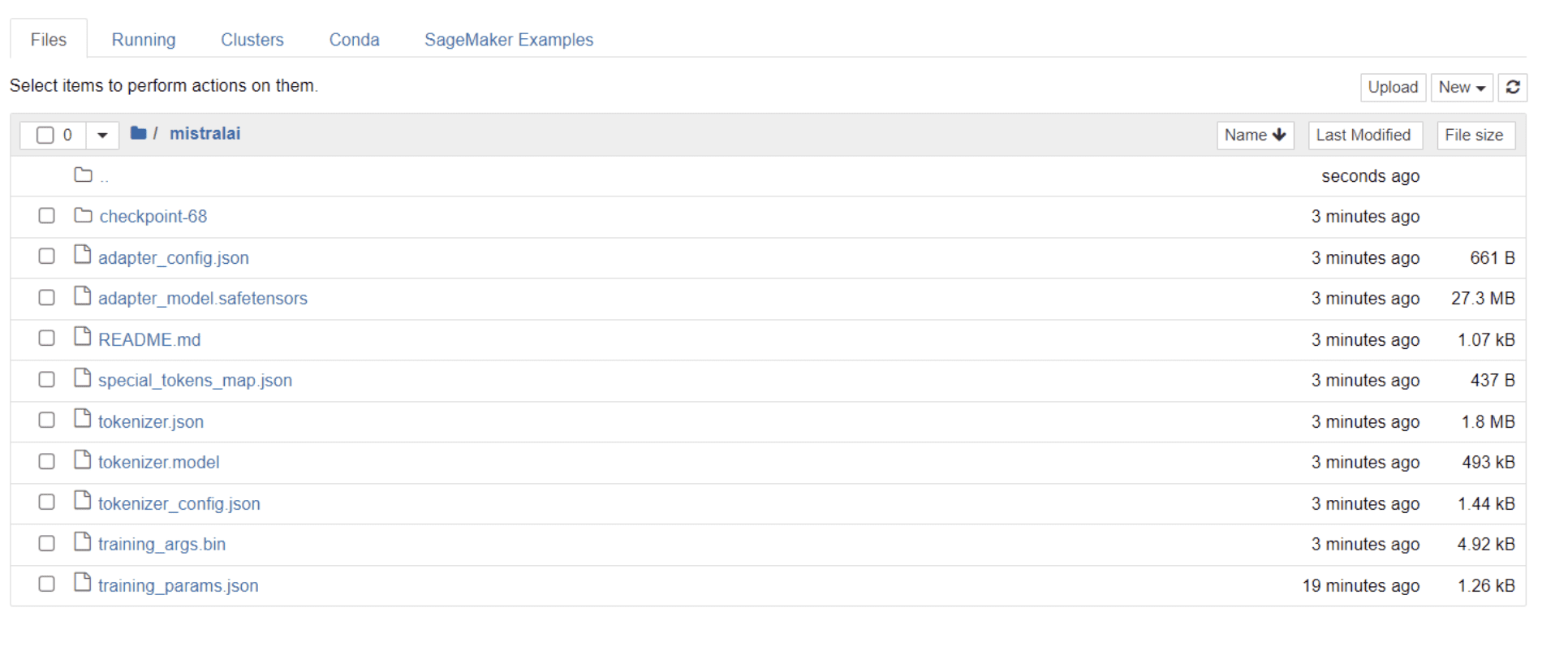
Dentro de esta carpeta, puede encontrar archivos que abarcan los pesos, hiperparámetros y detalles de arquitectura de su modelo.
Comprobemos ahora si este modelo ajustado es capaz de responder con precisión a una pregunta de nuestro conjunto de datos. Para lograr esto, primero debemos ejecutar las siguientes líneas de código para generar 5 entradas y salidas de muestra de nuestro conjunto de datos:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")Debería ver una respuesta similar a esta, que muestra cinco puntos de datos de muestra:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Vamos a escribir una de las instrucciones anteriores en el modelo y comprobaremos si genera un resultado preciso. Aquí hay una función para proporcionar una instrucción al modelo y obtener una respuesta del mismo:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerFinalmente, ingrese una pregunta en esta función como se muestra a continuación:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Su modelo debe generar una respuesta idéntica a su salida correspondiente en el conjunto de datos de entrenamiento, como se muestra a continuación:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andTenga en cuenta que la respuesta puede parecer incompleta o cortada debido a la cantidad de tokens que hemos especificado. Siéntase libre de ajustar el valor "max_length" para permitir una respuesta más amplia.
Si has llegado hasta aquí, ¡enhorabuena!
Ha perfeccionado con éxito un modelo de lenguaje de última generación, aprovechando el poder de Mistral 7B v-0.2 junto con las capacidades de Hugging Face.
Pero el viaje no termina aquí.
Como siguiente paso, recomiendo experimentar con diferentes conjuntos de datos o modificar ciertos parámetros de entrenamiento para optimizar el rendimiento del modelo. Ajustar los modelos a mayor escala mejorará su utilidad, así que intente experimentar con conjuntos de datos más grandes o formatos diferentes, como archivos PDF y de texto.
Esta experiencia resulta invaluable cuando se trabaja con datos del mundo real en organizaciones, que a menudo son confusos y desestructurados.
Natassha Selvaraj es un científico de datos autodidacta apasionado por la escritura. Natassha escribe sobre todo lo relacionado con la ciencia de datos, una verdadera maestra en todos los temas de datos. Puedes conectarte con ella en Etiqueta LinkedIn o mirala Canal de Youtube.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

