Esta publicación está coescrita con Ramesh Daddala, Jitendra Kumar Dash y Pavan Kumar Bijja de Bristol Myers Squibb.
Bristol Myers Squibb (BMS) es una empresa biofarmacéutica global cuya misión es descubrir, desarrollar y ofrecer medicamentos innovadores que ayuden a los pacientes a superar enfermedades graves. BMS innova constantemente y logra importantes éxitos clínicos y regulatorios. En colaboración con AWS, BMS identificó una necesidad empresarial de migrar y modernizar su plataforma personalizada de extracción, transformación y carga (ETL) a una solución nativa de AWS para reducir las complejidades, los recursos y la inversión para actualizar cuando se instalen nuevos Spark, Python o Pegamento AWS Se lanzan versiones. Además de utilizar servicios nativos administrados de AWS que BMS no necesitaba preocuparse por actualizar, BMS buscaba ofrecer un servicio ETL a usuarios empresariales no técnicos que pudieran componer visualmente flujos de trabajo de transformación de datos y ejecutarlos sin problemas en AWS Glue Apache Spark. Motor de integración de datos sin servidor basado en. Estudio de pegamento de AWS es una interfaz gráfica que facilita la creación, ejecución y monitoreo de trabajos ETL en AWS Glue. Ofrecer este servicio redujo el costo y el mantenimiento operativo de BMS y ofreció flexibilidad a los usuarios comerciales para realizar trabajos de ETL con facilidad.
Durante los últimos cinco años, BMS ha utilizado un marco personalizado llamado Enterprise Data Lake Services (EDLS) para crear trabajos ETL para usuarios empresariales. Aunque este marco cumplió con sus objetivos de ETL, fue difícil de mantener y actualizar. La plataforma EDLS de BMS alberga más de 5 puestos de trabajo y está creciendo un 5,000 % interanual (año tras año). Cada vez que se lanzaba la versión más nueva de Apache Spark (y la versión correspondiente de AWS Glue), se requería un importante soporte operativo y cambios manuales que requerían mucho tiempo para actualizar los trabajos de ETL existentes. Actualizar, probar e implementar manualmente más de 15 trabajos cada pocos trimestres consumía mucho tiempo, era propenso a errores, era costoso y no era sostenible. Como estaba pendiente otra versión del marco EDLS, BMS decidió evaluar soluciones administradas alternativas para reducir sus desafíos operativos y de actualización.
En esta publicación, compartimos cómo BMS se modernizará aprovechando el éxito de la prueba de concepto dirigida a la plataforma ETL de BMS utilizando AWS Glue Studio.
Resumen de la solución
Esta solución aborda los requisitos EDLS de BMS para superar los desafíos utilizando un marco ETL personalizado que requería mantenimiento frecuente y actualizaciones de componentes (que requieren ciclos de prueba extensos), evita la complejidad y reduce el costo general de la infraestructura subyacente derivada de la prueba de concepto. BMS tenía los siguientes objetivos:
- Desarrolle trabajos ETL utilizando flujos de trabajo visuales proporcionados por Estudio de pegamento de AWS editor visual. El editor visual de AWS Glue Studio es un entorno de código bajo que le permite componer flujos de trabajo de transformación de datos, ejecutarlos sin problemas en el motor de integración de datos sin servidor basado en AWS Glue Apache Spark e inspeccionar el esquema y los resultados de los datos en cada paso del trabajo. .
- Migre más de 5,000 trabajos ETL existentes utilizando AWS Glue Studio nativo de forma automatizada y escalable.
Pasos y metadatos del trabajo EDLS
Cada trabajo EDLS comprende uno o más pasos de trabajo encadenados y ejecutados en un orden predefinido orquestado por el marco ETL personalizado. Cada paso del trabajo incorpora las siguientes funciones ETL:
- Ingesta de archivos – La ingesta de archivos le permite ingerir o enumerar archivos de múltiples fuentes de archivos, como Servicio de almacenamiento simple de Amazon (Amazon S3), SFTP y más. Los metadatos contienen configuraciones para el paso de ingesta de archivos para conectarse a puntos finales de Amazon S3 o SFTP e ingerir archivos en la ubicación de destino. Recupera los archivos especificados y los metadatos disponibles para mostrarlos en la interfaz de usuario.
- Verificación de la calidad de los datos – El módulo de calidad de datos le permite realizar controles de calidad en una gran cantidad de datos y generar informes que describen y validan la calidad de los datos. El paso de calidad de datos utiliza un objeto de origen ingerido EDLS de Amazon S3 y ejecuta una o varias comprobaciones de conformidad de datos configuradas por el inquilino.
- Unión de transformación de datos – Este es uno de los submódulos del módulo de transformación de datos que puede realizar uniones entre los conjuntos de datos utilizando un SQL personalizado basado en la configuración de metadatos.
- Ingesta de base de datos – El paso de ingesta de la base de datos es uno de los componentes de servicio importantes en EDLS, que le facilita obtener e importar los datos deseados de la base de datos y exportarlos a un archivo específico en la ubicación de su elección.
- Transformación de datos – El módulo de transformación de datos realiza varias transformaciones de datos en los datos de origen utilizando reglas basadas en JSON. Cada capacidad de transformación de datos tiene su propia regla JSON y, según la regla JSON específica que proporcione, EDLS realiza la transformación de datos en los archivos disponibles en la ubicación de Amazon S3.
- Persistencia de datos – El módulo de persistencia de datos es uno de los componentes de servicio importantes en EDLS, que le permite obtener los datos deseados de la fuente y conservarlos en un Servicio de base de datos relacional de Amazon (Amazon RDS) base de datos.
Los metadatos correspondientes a cada paso del trabajo incluyen fuentes de ingesta, reglas de transformación, comprobaciones de calidad de datos y destinos de datos almacenados en una instancia de RDS.
Utilidad de migración
La solución implica crear una utilidad Python que lee metadatos EDLS de la base de datos RDS y traduce cada uno de los pasos del trabajo a una representación de nodo JSON del editor visual de AWS Glue Studio equivalente.
AWS Glue Studio proporciona dos tipos de transformaciones:
- Transformaciones nativas de AWS Glue – Están disponibles para todos los usuarios y son administrados por AWS Glue.
- Transformaciones visuales personalizadas – Esta nueva funcionalidad le permite cargar transformaciones personalizadas utilizadas en AWS Glue Studio. Las transformaciones visuales personalizadas amplían las transformaciones administradas, lo que le permite buscar y utilizar transformaciones desde la interfaz de AWS Glue Studio.
El siguiente es un diagrama de alto nivel que muestra el flujo de secuencia de migración de un trabajo de BMS EDLS a un trabajo de editor visual de AWS Glue Studio.

La migración de trabajos de BMS EDLS a AWS Glue Studio incluye los siguientes pasos:
- La utilidad Python lee metadatos existentes de la base de datos de metadatos EDLS.
- Para cada tipo de paso del trabajo, según los metadatos del trabajo, la utilidad Python selecciona la transformación nativa de AWS Glue, si está disponible, o una transformación visual personalizada (cuando falta la funcionalidad nativa).
- La utilidad Python analiza la información de dependencia de los metadatos y crea un objeto JSON que representa un flujo de trabajo visual representado como un gráfico acíclico dirigido (DAG).
- El objeto JSON se envía al API de pegamento de AWS, creando el trabajo ETL de AWS Glue. Estos trabajos se representan visualmente en el editor visual de AWS Glue Studio mediante una serie de orígenes, transformaciones (nativas y personalizadas) y destinos.
Ejemplo de generación de trabajos ETL con AWS Glue Studio
El siguiente diagrama de flujo muestra un trabajo ETL de muestra que ingiere incrementalmente los datos RDBMS de origen en AWS Glue en función de las marcas de tiempo modificadas mediante un SQL personalizado y los combina con los datos de destino en Amazon S3.
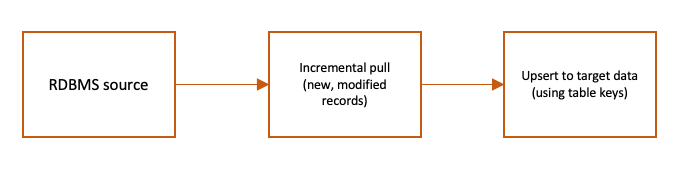
El flujo ETL anterior se puede representar mediante el editor visual de AWS Glue Studio mediante una combinación de transformaciones visuales nativas y personalizadas.
Transformación visual personalizada para ingesta incremental
Después de POC, BMS y AWS identificaron que será necesario aprovechar las transformaciones personalizadas para ejecutar un subconjunto de trabajos aprovechando su servicio EDLS actual, donde la funcionalidad de Glue Studio no será una opción natural. El requisito del equipo de BMS era ingerir datos de varias bases de datos sin depender de la existencia de registros de transacciones o esquemas específicos, por lo que Servicio de migración de bases de datos de AWS (AWS DMS) no era una opción para ellos. AWS Glue Studio proporciona la transformación visual de consultas SQL nativas, donde se puede utilizar una consulta SQL personalizada para transformar los datos de origen. Sin embargo, para consultar la tabla de la base de datos de origen en función de una columna de marca de tiempo modificada para recuperar registros nuevos y modificados desde la última ejecución de ETL, es necesario conservar el estado de la columna de marca de tiempo anterior para poder usarlo en la ejecución de ETL actual. Este debe ser un proceso recurrente y también se puede resumir en varias fuentes RDBMS, incluidas Oracle, MySQL, Microsoft SQL Server, SAP Hana y más.
AWS Glue proporciona una función de marcador de trabajos para realizar un seguimiento de los datos que ya se procesaron durante una ejecución ETL anterior. Un marcador de trabajo de AWS Glue admite una o más columnas como claves de marcador para determinar datos nuevos y procesados, y requiere que las claves aumenten o disminuyan secuencialmente sin espacios. Aunque esto funciona para muchos casos de uso de carga incremental, el requisito es ingerir datos de diferentes fuentes sin depender de ningún esquema específico, por lo que no utilizamos un marcador de trabajo de AWS Glue en este caso de uso.
La extracción de ingesta incremental basada en SQL se puede desarrollar de forma genérica utilizando un transformación visual personalizada utilizando un trabajo de ingesta incremental de muestra de una base de datos MySQL. Los datos incrementales se combinan en la ubicación de destino de Amazon S3 en formato Apache Hudi mediante una operación de escritura upsert.
En el siguiente ejemplo, utilizamos el nodo de fuente de datos MySQL para definir la conexión, pero no se utiliza el DynamicFrame de la fuente de datos en sí. El nodo de transformación personalizado (ingesta incremental de base de datos) actuará como fuente para leer los datos de forma incremental utilizando la consulta SQL personalizada y la marca de tiempo previamente persistente de la última ingesta.
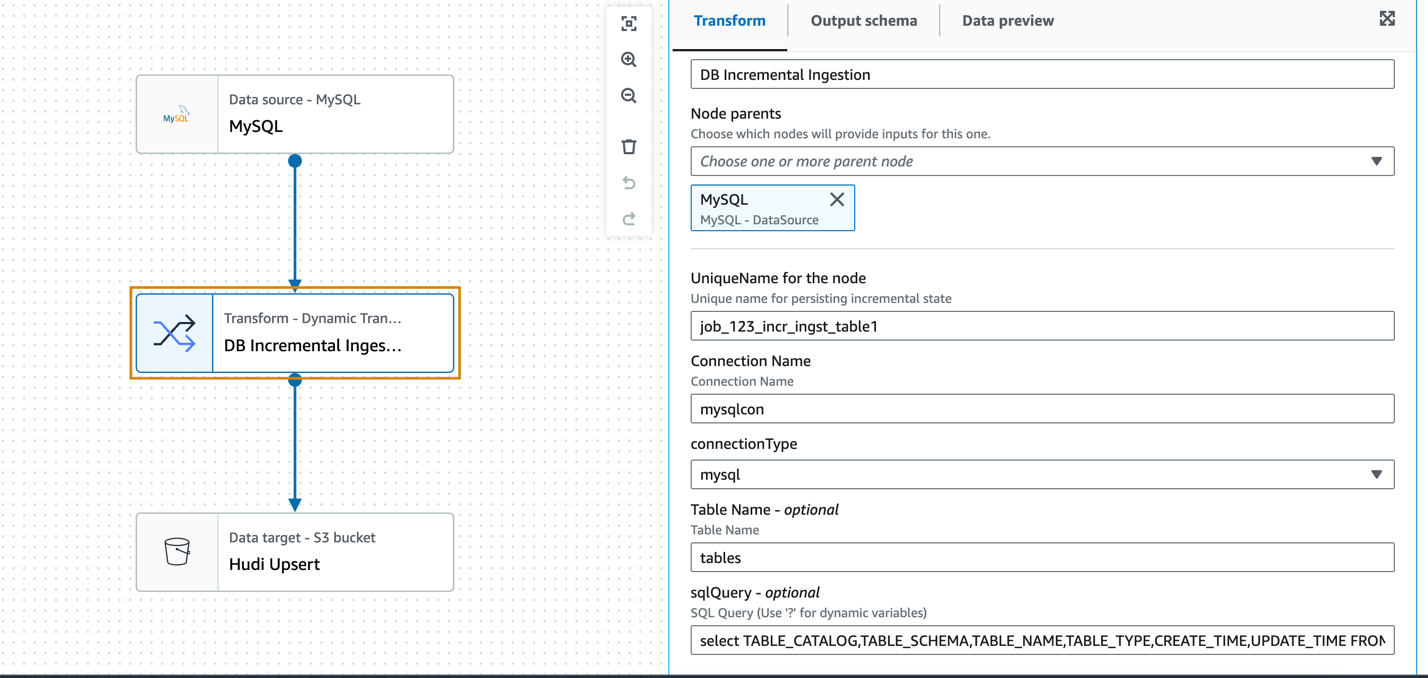
La transformación acepta como parámetros de entrada el nombre de conexión de AWS Glue, el tipo de base de datos, el nombre de la tabla y el SQL personalizado (campo de marca de tiempo parametrizado) preconfigurados.
El siguiente es el código Python de transformación visual de ejemplo:
Para fusionar los datos de origen en el destino de Amazon S3, se puede utilizar un marco de lago de datos como Apache Hudi o Apache Iceberg, que es compatible de forma nativa con AWS Glue 3.0 y versiones posteriores.
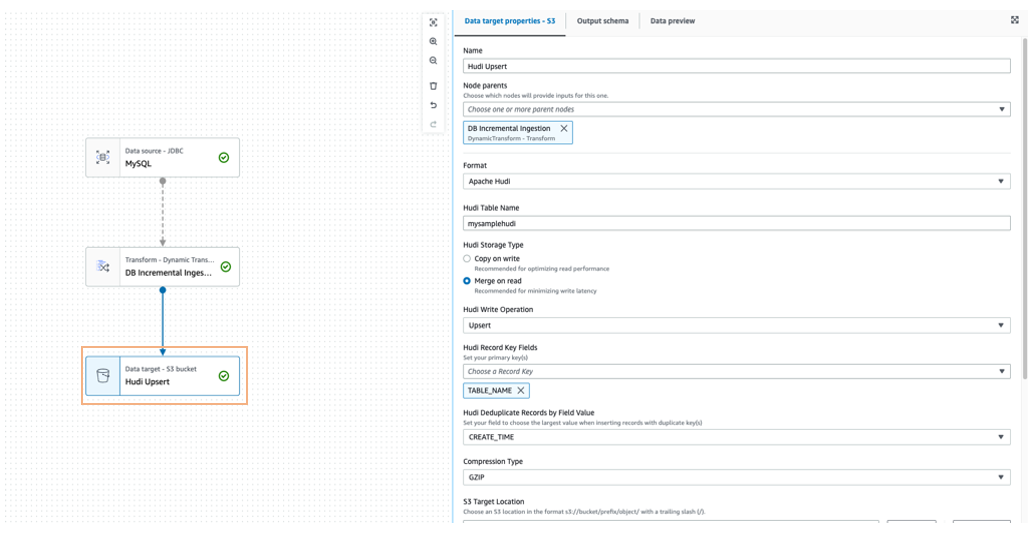
También puedes usar Puente de eventos de Amazon para detectar el cambio final de estado del trabajo de AWS Glue y actualizar el Amazon DynamoDB la última marca de tiempo ingerida de la tabla en consecuencia.
Cree el trabajo de AWS Glue Studio utilizando AWS SDK para Python (Boto3) y la API de AWS Glue
Para el flujo ETL de muestra y el trabajo ETL correspondiente de AWS Glue Studio que mostramos anteriormente, el proceso subyacente CodeGenConfigurationNode struct (una definición de trabajo de AWS Glue extraída mediante el Interfaz de línea de comandos de AWS (CLI de AWS) comando aws glue get-job –job-name <jobname>) se representa como un objeto JSON, que se muestra en el siguiente código:
El objeto JSON (trabajo ETL DAG) representado en el CodeGenConfigurationNode se genera a través de una serie de transformaciones nativas y personalizadas con las respectivas matrices de parámetros de entrada. Esto se puede lograr utilizando codificadores JSON de Python que serializan los objetos de clase en JSON y posteriormente crean el trabajo del editor visual de AWS Glue Studio utilizando la biblioteca Boto3 y la API de AWS Glue.
Las entradas necesarias para configurar las transformaciones de AWS Glue provienen de la base de datos de metadatos de trabajos de EDLS. La utilidad Python lee la información de metadatos, la analiza y configura los nodos automáticamente.
El orden y la secuencia de los nodos provienen de los metadatos de los trabajos EDLS, y un nodo se convierte en la entrada para uno o más nodos posteriores que crean el flujo DAG.
Beneficios de la solución
La ruta de migración ayudará a BMS a lograr sus objetivos principales de descomponer su marco ETL personalizado existente en canalizaciones modulares, visualmente configurables, menos complejas y fácilmente manejables utilizando componentes ETL visuales. La utilidad ayuda a la migración de las canalizaciones ETL heredadas a trabajos nativos de AWS Glue Studio de forma automatizada y escalable.
Con transformaciones ETL visuales consistentes y listas para usar en la interfaz de AWS Glue Studio, BMS podrá crear canales de datos sofisticados sin tener que escribir código.
Las transformaciones visuales personalizadas ampliarán las capacidades de AWS Glue Studio y cumplirán con algunos de los requisitos ETL de BMS donde a las transformaciones nativas les falta esa funcionalidad. Las transformaciones personalizadas ayudarán a definir, reutilizar y compartir la lógica ETL específica del negocio entre todos los equipos. La solución aumenta la coherencia entre los equipos y mantiene actualizados los procesos de ETL al minimizar el esfuerzo y el código duplicados.
Con modificaciones menores, la utilidad de migración se puede reutilizar para automatizar la migración de canalizaciones durante futuras actualizaciones de la versión de AWS Glue.
Conclusión
El resultado exitoso de esta prueba de concepto ha demostrado que la migración de más de 5,000 trabajos de la aplicación personalizada de BMS a servicios nativos de AWS puede generar importantes ganancias de productividad y ahorros de costos. Al migrar a AWS, BMS podrá reducir el esfuerzo necesario para admitir AWS Glue, mejorar la entrega de DevOps y ahorrar aproximadamente un 58 % en el gasto de AWS Glue.
Estos resultados son muy prometedores y BMS está entusiasmado de embarcarse en la siguiente fase de la migración. Creemos que este proyecto tendrá un impacto positivo en el negocio de BMS y nos ayudará a alcanzar nuestros objetivos estratégicos.
Sobre los autores
 Sivaprasad Mahamkali es ingeniero sénior de datos de streaming en AWS Professional Services. Siva lidera las interacciones con los clientes relacionadas con soluciones de transmisión en tiempo real, lagos de datos y análisis mediante código abierto y servicios de AWS. A Siva le gusta escuchar música y le encanta pasar tiempo con su familia.
Sivaprasad Mahamkali es ingeniero sénior de datos de streaming en AWS Professional Services. Siva lidera las interacciones con los clientes relacionadas con soluciones de transmisión en tiempo real, lagos de datos y análisis mediante código abierto y servicios de AWS. A Siva le gusta escuchar música y le encanta pasar tiempo con su familia.
 Dan Gibbar es gerente senior de participación en AWS Professional Services. Dan lidera compromisos de atención médica y ciencias biológicas y colabora con clientes y socios para lograr resultados. Dan disfruta del aire libre, practica triatlones, la música y pasa tiempo con la familia.
Dan Gibbar es gerente senior de participación en AWS Professional Services. Dan lidera compromisos de atención médica y ciencias biológicas y colabora con clientes y socios para lograr resultados. Dan disfruta del aire libre, practica triatlones, la música y pasa tiempo con la familia.
 Shrinath Parikh como arquitecto senior de datos en la nube en AWS. Trabaja con clientes de todo el mundo para ayudarlos con sus casos de uso de análisis de datos, lago de datos, casa del lago de datos, sin servidor, gobernanza y NoSQL. En su tiempo libre, Shrinath disfruta viajar, pasar tiempo con la familia y aprender/construir nuevas herramientas utilizando tecnologías de vanguardia.
Shrinath Parikh como arquitecto senior de datos en la nube en AWS. Trabaja con clientes de todo el mundo para ayudarlos con sus casos de uso de análisis de datos, lago de datos, casa del lago de datos, sin servidor, gobernanza y NoSQL. En su tiempo libre, Shrinath disfruta viajar, pasar tiempo con la familia y aprender/construir nuevas herramientas utilizando tecnologías de vanguardia.
 Ramesh Daddala es director asociado en BMS. Ramesh lidera compromisos de ingeniería de datos empresariales relacionados con servicios de lago de datos empresariales (EDL) y colabora con socios de datos para ofrecer y respaldar capacidades de aprendizaje automático y ingeniería de datos empresariales. Ramesh disfruta del aire libre, viaja y le encanta pasar tiempo con la familia.
Ramesh Daddala es director asociado en BMS. Ramesh lidera compromisos de ingeniería de datos empresariales relacionados con servicios de lago de datos empresariales (EDL) y colabora con socios de datos para ofrecer y respaldar capacidades de aprendizaje automático y ingeniería de datos empresariales. Ramesh disfruta del aire libre, viaja y le encanta pasar tiempo con la familia.
 Jitendra Kumar Dash es un arquitecto de nube senior en BMS con experiencia en servicios de nube híbrida, ingeniería de infraestructura, DevOps, ingeniería de datos y soluciones de análisis de datos. Le apasiona la comida, los deportes y la aventura.
Jitendra Kumar Dash es un arquitecto de nube senior en BMS con experiencia en servicios de nube híbrida, ingeniería de infraestructura, DevOps, ingeniería de datos y soluciones de análisis de datos. Le apasiona la comida, los deportes y la aventura.
 Pavan Kumar Bijja es ingeniero de datos sénior en BMS. Pavan permite servicios analíticos y de ingeniería de datos para el dominio comercial de BMS utilizando capacidades empresariales. Pavan lidera las capacidades de metadatos empresariales en BMS. A Pavan le encanta pasar tiempo con su familia, jugando bádminton y críquet.
Pavan Kumar Bijja es ingeniero de datos sénior en BMS. Pavan permite servicios analíticos y de ingeniería de datos para el dominio comercial de BMS utilizando capacidades empresariales. Pavan lidera las capacidades de metadatos empresariales en BMS. A Pavan le encanta pasar tiempo con su familia, jugando bádminton y críquet.
 Shovan Kanjilal es un arquitecto senior de lago de datos que trabaja con cuentas estratégicas en los servicios profesionales de AWS. Shovan trabaja con los clientes para diseñar soluciones de datos y aprendizaje automático en AWS.
Shovan Kanjilal es un arquitecto senior de lago de datos que trabaja con cuentas estratégicas en los servicios profesionales de AWS. Shovan trabaja con los clientes para diseñar soluciones de datos y aprendizaje automático en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/modernize-your-etl-platform-with-aws-glue-studio-a-case-study-from-bms/

