EMR de Amazon proporciona un marco Apache Hadoop administrado que hace que su ejecución sea sencilla, rápida y rentable Apache HBase. Apache HBase es un gran almacén de datos masivo distribuido y escalable en el ecosistema Apache Hadoop. Es una base de datos versionada, no relacional y de código abierto que se ejecuta sobre el sistema de archivos distribuido Apache Hadoop (HDFS). Está construido para acceso aleatorio, estrictamente consistente y en tiempo real para tablas con miles de millones de filas y millones de columnas. El monitoreo de los clústeres de HBase es fundamental para identificar los cuellos de botella en la estabilidad y el rendimiento y evitarlos de manera proactiva. En esta publicación, discutimos cómo puede usar Servicio administrado de Amazon para Prometheus y Grafana gestionado por Amazon para monitorear, alertar y visualizar métricas de HBase.
HBase tiene soporte integrado para exportar métricas a través del subsistema de métricas de Hadoop a archivos o Ganglia oa través de JMX. Puedes usar Distribución de AWS para OpenTelemetry or Exportadores Prometheus JMX para recopilar métricas expuestas por HBase. En esta publicación, mostramos cómo usar los exportadores de Prometheus. Estos exportadores se comportan como pequeños servidores web que convierten las métricas internas de la aplicación al formato Prometheus y las sirven en /metrics camino. Un servidor Prometheus ejecutándose en un Nube informática elástica de Amazon (Amazon EC2) instancia recopila estas métricas y escrituras remotas a un espacio de trabajo de Amazon Managed Service for Prometheus. Luego usamos Amazon Managed Grafana para crear tableros y ver estas métricas usando un servicio administrado de Amazon para el espacio de trabajo de Prometheus como su fuente de datos.
Esta solución se puede extender a otras plataformas de big data como Apache Spark y Apache Presto que también usan JMX para exponer sus métricas.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de nuestra solución.
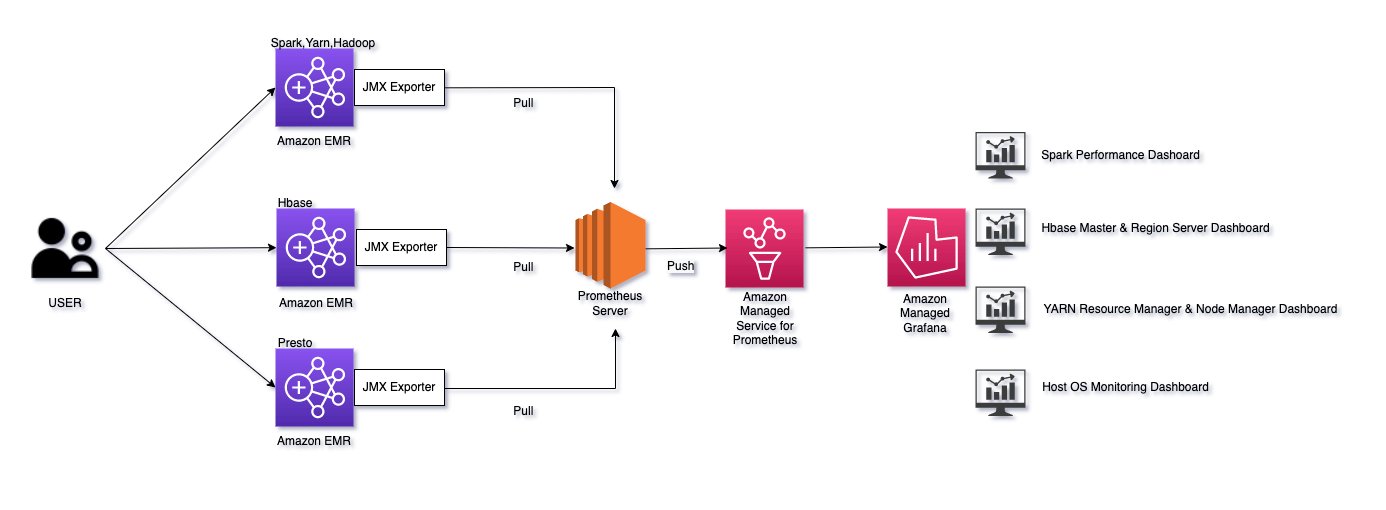
Esta publicación usa un Formación en la nube de AWS plantilla para realizar las siguientes acciones:
- Instale un servidor Prometheus de código abierto en una instancia EC2.
- Crear apropiado Gestión de identidades y accesos de AWS (IAM) roles y grupo de seguridad para la instancia EC2 que ejecuta el servidor Prometheus.
- Cree un clúster de EMR con una configuración de HBase en Amazon S3.
- Instale exportadores JMX en todos los nodos de EMR.
- Cree grupos de seguridad adicionales para que los nodos maestro y trabajador de EMR se conecten con el servidor Prometheus que se ejecuta en la instancia EC2.
- Cree un espacio de trabajo en Amazon Managed Service para Prometheus.
Requisitos previos
Para implementar esta solución, asegúrese de tener los siguientes requisitos previos:
Implementar la plantilla de CloudFormation
Implemente la plantilla de CloudFormation en el us-east-1 Región:
![]()
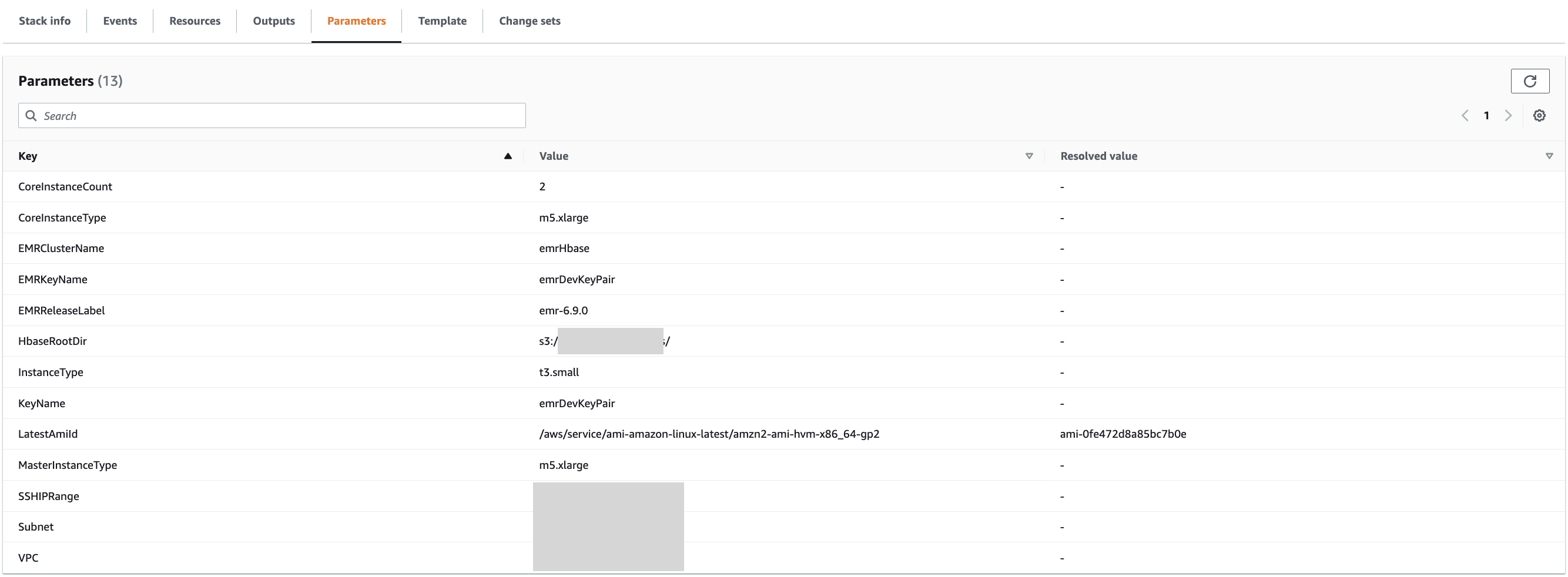
La plantilla tardará entre 15 y 20 minutos en completarse. La plantilla requiere los siguientes campos:
- Nombre de pila – Introduzca un nombre para la pila
- VPC – Elija una VPC existente
- Subred – Elija una subred existente
- EMRClústerNombre - Utilizar
EMRHBase - HBaseRootDir – Proporcione un nuevo directorio raíz de HBase (por ejemplo,
s3://hbase-root-dir/). - Tipo de instancia maestra – Usar m5x.grande
- Tipo de instancia principal – Usar m5x.grande
- Número de instancias principales – Introduzca 2
- SSHIPRango - Utilizar
<your ip address>/32(puedes ir a https://checkip.amazonaws.com/ para comprobar su dirección IP) - NombreClaveEMR – Elija un par de claves para el clúster EMR
- EMRRleaseEtiqueta - Utilizar
emr-6.9.0 - Tipo de instancia – Utilice el tipo de instancia EC2 para instalar el servidor Prometheus
Habilitar escrituras remotas en el servidor Prometheus
El servidor Prometheus se ejecuta en una instancia EC2. Puede encontrar el nombre de host de la instancia en la pila de CloudFormation. Salidas pestaña para la clave PrometheusServerPublicDNSName.
- SSH en la instancia EC2 usando el par de claves:
- Copie el valor de Punto final: URL de escritura remota desde la consola del espacio de trabajo de Amazon Managed Service para Prometheus.

- Editar
remote_write urlin/etc/prometheus/conf/prometheus.yml:
Debería verse como el siguiente código:

- Ahora necesitamos reiniciar el servidor Prometheus para recoger los cambios:
Permita que Amazon Managed Grafana lea desde un espacio de trabajo de Amazon Managed Service for Prometheus
Necesitamos agregar el espacio de trabajo de Amazon Managed Prometheus como fuente de datos en Amazon Managed Grafana. Puede pasar directamente al paso 3 si ya tiene un espacio de trabajo de Amazon Managed Grafana y desea utilizarlo para las métricas de HBase.
- Primero, creemos un espacio de trabajo en Amazon Managed Grafana. Puede seguir el apéndice para crear un espacio de trabajo mediante la consola de Amazon Managed Grafana o ejecutar la siguiente API desde su terminal (proporcione el ARN de su función):
- En la consola de Amazon Managed Grafana, elija Configurar usuarios y seleccione un usuario al que desee permitir que inicie sesión en los paneles de Grafana.
Asegúrese de que su tipo de usuario de IAM Identity Center sea admin. Necesitamos esto para crear tableros. Puede asignar la función de espectador a todos los demás usuarios.


- Inicie sesión en la URL del espacio de trabajo de Amazon Managed Grafana con sus credenciales de administrador.
- Elige Fuentes de datos de AWS en el panel de navegación.

- Service, escoger Servicio administrado de Amazon para Prometheus.

- Regiones, escoger Este de los Estados Unidos (Virginia del Norte).
Crear un panel de HBase
Grafana labs tiene un panel de control de código abierto que puede usar. Por ejemplo, puede seguir las instrucciones de las siguientes Tablero HBase. Comience a crear su tablero y elija la opción de importación. Proporcione la URL del tablero o ingrese 12722 y elige Carga. Asegúrese de que su espacio de trabajo de Prometheus esté seleccionado en la página siguiente. Debería ver las métricas de HBase en el tablero.

Métricas clave de HBase para monitorear
HBase tiene una amplia gama de métricas para HMaster y RegionServer. Las siguientes son algunas métricas importantes a tener en cuenta.
| MAESTRO | Nombre de la métrica | Descripción métrica |
| . | hadoop_HBase_numservidores de regiones | Número de servidores de regiones activas |
| . | hadoop_HBase_numdeadregionservers | Número de servidores de regiones muertas |
| . | hadoop_HBase_ritcount | Número de regiones en transición |
| . | hadoop_HBase_ritcountoverthreshold | Número de regiones que han estado en transición durante más tiempo que un umbral de tiempo (predeterminado: 60 segundos) |
| . | hadoop_HBase_ritduration_99th_percentile | Tiempo máximo que tarda el 99% de las regiones en permanecer en estado de transición |
| SERVIDOR DE REGIÓN | Nombre de la métrica | Descripción métrica |
| . | hadoop_HBase_regioncount | Número de regiones alojadas por el servidor de regiones |
| . | hadoop_HBase_storefilecount | Número de archivos de almacenamiento gestionados actualmente por el servidor de la región |
| . | hadoop_HBase_storefilesize | Tamaño agregado de los archivos de la tienda |
| . | hadoop_HBase_hlogfilecount | Número de registros de escritura anticipada aún no archivados |
| . | hadoop_HBase_hlogfilesize | Tamaño de todos los archivos de registro de escritura anticipada |
| . | hadoop_HBase_totalrequestcount | Número total de solicitudes recibidas |
| . | hadoop_HBase_readrequestcount | Número de solicitudes de lectura recibidas |
| . | hadoop_HBase_writerequestcount | Número de solicitudes de escritura recibidas |
| . | hadoop_HBase_numopenconnections | Número de conexiones abiertas en la capa RPC |
| . | hadoop_HBase_numactivehandler | Número de controladores de RPC que atienden solicitudes de forma activa |
| tienda de memoria | . | . |
| . | hadoop_HBase_memstoresize | Tamaño total de la memoria del almacén de memoria del servidor de la región |
| . | hadoop_HBase_flushqueuelength | Profundidad actual de la cola de vaciado de memstore (si aumenta, nos estamos quedando atrás con la limpieza de memstores en Amazon S3) |
| . | hadoop_HBase_flushtime_99th_percentile | Latencia del percentil 99 para la operación de descarga |
| . | hadoop_HBase_updatestiempobloqueado | Se han bloqueado el número de actualizaciones de milisegundos para que se pueda vaciar el memstore |
| Caché de bloque | . | . |
| . | hadoop_HBase_blockcachesize | Tamaño de caché de bloque |
| . | hadoop_HBase_blockcachefreesize | Bloquear tamaño libre de caché |
| . | hadoop_HBase_blockcachehitcount | Número de aciertos de caché de bloque |
| . | hadoop_HBase_blockcachemisscount | Número de errores de caché de bloque |
| . | hadoop_HBase_blockcacheexpresshitpercent | Porcentaje del tiempo que las solicitudes con el caché activado llegan al caché |
| . | hadoop_HBase_blockcachecounthitpercent | Porcentaje de aciertos de caché de bloque |
| . | hadoop_HBase_blockcacheevictioncount | Número de desalojos de caché de bloque en el servidor de la región |
| . | hadoop_HBase_l2cachehitratio | Proporción de aciertos de caché de depósito basada en disco local |
| . | hadoop_HBase_l2cachemissratio | Proporción de errores de caché de depósito |
| Compactación | . | . |
| . | hadoop_HBase_majorcompactiontime_99th_percentile | Tiempo en milisegundos necesario para la compactación mayor |
| . | hadoop_HBase_compactiontime_99th_percentile | Tiempo en milisegundos necesario para la compactación menor |
| . | hadoop_HBase_compactionqueuelength | Profundidad actual de la cola de solicitudes de compactación (si aumenta, nos estamos quedando atrás con la compactación del archivo de almacenamiento) |
| . | longitud de la cola de descarga | Número de operaciones de vaciado que esperan ser procesadas en el servidor de la región (un número más alto indica que las operaciones de vaciado son lentas) |
| Colas de IPC | . | . |
| . | hadoop_HBase_tamaño cola | Tamaño total de datos de todas las llamadas RPC en las colas RPC en el servidor de región |
| . | hadoop_HBase_numllamadasencolageneral | Número de llamadas RPC en la cola de procesamiento general en el servidor de región |
| . | hadoop_HBase_processcalltime_99th_percentile | Latencia del percentil 99 para que las llamadas RPC se procesen en el servidor de la región |
| . | hadoop_HBase_queuecalltime_99th_percentile | Latencia del percentil 99 para que las llamadas RPC permanezcan en la cola RPC en el servidor de la región |
| JVM y GC | . | . |
| . | hadoop_HBase_memheapusedm | Montón usado |
| . | hadoop_HBase_memheapmaxm | Montón total |
| . | hadoop_HBase_pausetimewithgc_99th_percentile | Tiempo de pausa en milisegundos |
| . | hadoop_HBase_gccount | Recuento de recogida de basura |
| . | hadoop_HBase_gctimemillis | Tiempo empleado en la recolección de basura, en milisegundos |
| Latencias | . | . |
| . | HBase.región servidor. _ | Latencias de operación, donde es Agregar, Eliminar, Mutar, Obtener, Reproducir o Incrementar, y es mínimo, máximo, media, mediana, percentil_75, percentil_95 o percentil_99 |
| . | HBase.regionserver.slow Contar | Número de operaciones que pensamos que eran lentas, donde es uno de la lista anterior |
| Carga masiva | . | . |
| . | Carga masiva_percentil_99 | hadoop_HBase_bulkload_99th_percentile |
| I / O | . | . |
| . | FsWriteTime_percentil_99 | hadoop_HBase_fswritetime_99th_percentile |
| . | FsReadTime_percentil_99 | hadoop_HBase_fsreadtime_99th_percentile |
| Excepciones | . | . |
| . | excepciones.RegionTooBusyException | . |
| . | excepciones.callQueueTooBig | . |
| . | excepciones.NotServingRegionException | . |
Consideraciones y limitaciones
Tenga en cuenta lo siguiente cuando utilice esta solución:
- Usted puede configurar alertas en Amazon Managed Service para Prometheus y visualizarlos en Grafana gestionado por Amazon.
- Esta arquitectura se puede ampliar fácilmente para incluir otros marcos de código abierto como Apache Spark, Apache Presto y Apache Hive.
- Consulte los detalles de precios para Servicio administrado de Amazon para Prometheus y Grafana gestionado por Amazon.
- Estos scripts son solo para fines de orientación y no están listos para implementaciones de producción. Asegúrese de realizar pruebas exhaustivas.
Limpiar
Para evitar cargos continuos, elimine la pila de CloudFormation y los espacios de trabajo creados en Amazon Managed Grafana y Amazon Managed Service for Prometheus.
Conclusión
En esta publicación, aprendió a monitorear clústeres de EMR HBase y a configurar paneles para visualizar métricas clave. Esta solución puede servir como una plataforma de monitoreo unificada para múltiples clústeres de EMR y otras aplicaciones. Para obtener más información sobre EMR HBase, consulte Guía de lanzamiento y Documento técnico sobre migración de HBase.
Apéndice
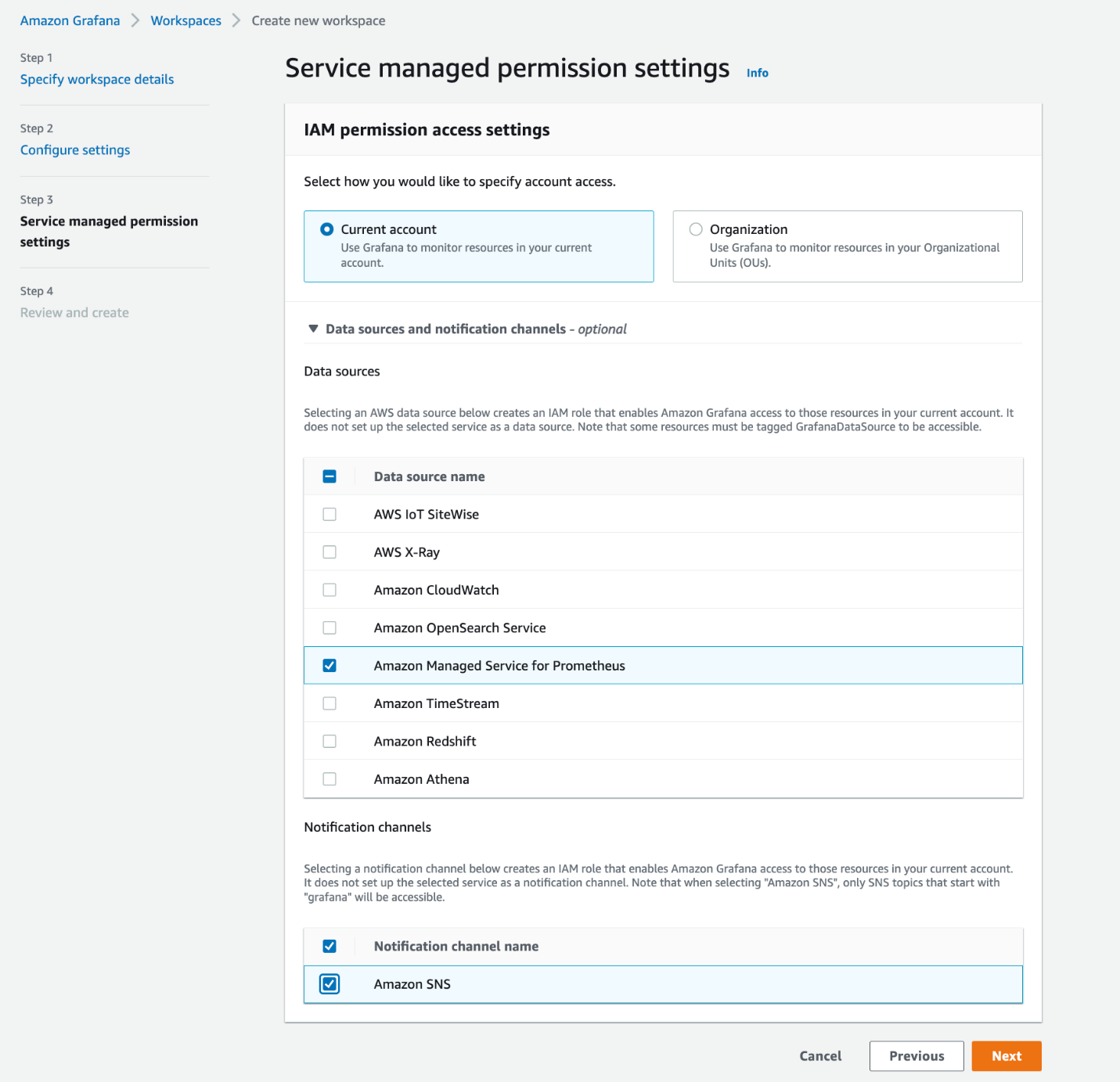
Complete los siguientes pasos para crear un espacio de trabajo en Amazon Managed Grafana:
- Inicie sesión en la consola de Amazon Managed Grafana y elija Crear espacio de trabajo.

- Acceso de autenticación, seleccione Centro de identidad de AWS IAM.
Si no tiene habilitado el Centro de identidad de IAM, consulte Habilitar el centro de identidad de IAM.
- Opcionalmente, para ver las alertas de Prometheus en su espacio de trabajo de Grafana, seleccione Activar las alertas de Grafana.

- En la página siguiente, selecciona Servicio administrado de Amazon para Prometheus como fuente de datos.
- Después de crear el espacio de trabajo, asigne usuarios para acceder a Amazon Managed Grafana.
- Para una configuración inicial, asigne privilegios de administrador al usuario.
Puede agregar otros usuarios solo con acceso de espectador.
Asegúrese de poder iniciar sesión en la URL del espacio de trabajo de Grafana con sus credenciales de usuario del Centro de identidad de IAM.
Sobre la autora
 Anubhav Awasthi es Arquitecto Sr. de Soluciones Especialista en Big Data en AWS. Trabaja con los clientes para brindar orientación arquitectónica para ejecutar soluciones de análisis en Amazon EMR, Amazon Athena, AWS Glue y AWS Lake Formation.
Anubhav Awasthi es Arquitecto Sr. de Soluciones Especialista en Big Data en AWS. Trabaja con los clientes para brindar orientación arquitectónica para ejecutar soluciones de análisis en Amazon EMR, Amazon Athena, AWS Glue y AWS Lake Formation.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/monitor-apache-hbase-on-amazon-emr-using-amazon-managed-service-for-prometheus-and-amazon-managed-grafana/

