Los modelos de lenguajes grandes (LLM) se están volviendo cada vez más populares y constantemente se exploran nuevos casos de uso. En general, puede crear aplicaciones impulsadas por LLM incorporando ingeniería rápida en su código. Sin embargo, hay casos en los que solicitar un LLM existente no es suficiente. Aquí es donde el ajuste del modelo puede resultar útil. La ingeniería rápida consiste en guiar la salida del modelo mediante la elaboración de indicaciones de entrada, mientras que el ajuste fino consiste en entrenar el modelo en conjuntos de datos personalizados para que se adapte mejor a tareas o dominios específicos.
Antes de poder ajustar un modelo, necesita encontrar un conjunto de datos específico de la tarea. Un conjunto de datos que se utiliza comúnmente es el Conjunto de datos de rastreo común. El corpus Common Crawl contiene petabytes de datos, recopilados periódicamente desde 2008, y contiene datos sin procesar de páginas web, extractos de metadatos y extractos de texto. Además de determinar qué conjunto de datos se debe utilizar, es necesario limpiar y procesar los datos según las necesidades específicas del ajuste.
Recientemente trabajamos con un cliente que quería preprocesar un subconjunto del último conjunto de datos de Common Crawl y luego ajustar su LLM con datos limpios. El cliente buscaba cómo lograr esto de la manera más rentable en AWS. Después de discutir los requisitos, recomendamos usar Amazon EMR sin servidor como su plataforma para el preprocesamiento de datos. EMR Serverless es ideal para el procesamiento de datos a gran escala y elimina la necesidad de mantenimiento de la infraestructura. En términos de costo, solo cobra en función de los recursos y la duración utilizados para cada trabajo. El cliente pudo preprocesar cientos de TB de datos en una semana utilizando EMR Serverless. Después de preprocesar los datos, utilizaron Amazon SageMaker para afinar el LLM.
En esta publicación, lo guiaremos a través del caso de uso del cliente y la arquitectura utilizada.
En las siguientes secciones, primero presentamos el conjunto de datos de rastreo común y cómo explorar y filtrar los datos que necesitamos. Atenea amazónica solo cobra por el tamaño de los datos que escanea y se utiliza para explorar y filtrar los datos rápidamente, a la vez que es rentable. EMR Serverless proporciona una opción rentable y sin mantenimiento para el procesamiento de datos de Spark y se utiliza para procesar los datos filtrados. A continuación, utilizamos JumpStart de Amazon SageMaker para afinar el modelo llama 2 con el conjunto de datos preprocesados. SageMaker JumpStart proporciona un conjunto de soluciones para los casos de uso más comunes que se pueden implementar con solo unos pocos clics. No necesita escribir ningún código para ajustar un LLM como Llama 2. Finalmente, implementamos el modelo ajustado usando Amazon SageMaker y compare las diferencias en la producción de texto para la misma pregunta entre los modelos Llama 2 original y mejorado.
El siguiente diagrama ilustra la arquitectura de esta solución.
Antes de profundizar en los detalles de la solución, complete los siguientes pasos previos:
Common Crawl es un conjunto de datos de corpus abierto que se obtiene rastreando más de 50 mil millones de páginas web. Incluye cantidades masivas de datos no estructurados en varios idiomas, desde 2008 y alcanzando el nivel de petabytes. Se actualiza continuamente.
En el entrenamiento de GPT-3, el conjunto de datos Common Crawl representa el 60% de sus datos de entrenamiento, como se muestra en el siguiente diagrama (fuente: Los modelos de lenguaje son aprendices con pocas posibilidades).
Otro conjunto de datos importante que vale la pena mencionar es el Conjunto de datos C4. C4, abreviatura de Colossal Clean Crawled Corpus, es un conjunto de datos derivado del posprocesamiento del conjunto de datos Common Crawl. En el documento LLaMA de Meta, describieron los conjuntos de datos utilizados, donde Common Crawl representa el 67 % (utilizando 3.3 TB de datos) y C4 el 15 % (utilizando 783 GB de datos). El artículo enfatiza la importancia de incorporar datos preprocesados de manera diferente para mejorar el rendimiento del modelo. A pesar de que los datos C4 originales son parte de Common Crawl, Meta optó por la versión reprocesada de estos datos.
En esta sección, cubrimos formas comunes de interactuar, filtrar y procesar el conjunto de datos de rastreo común.
El conjunto de datos sin procesar de Common Crawl incluye tres tipos de archivos de datos: datos de páginas web sin procesar (WARC), metadatos (WAT) y extracción de texto (WET).
Los datos recopilados después de 2013 se almacenan en formato WARC e incluyen los metadatos correspondientes (WAT) y datos de extracción de texto (WET). El conjunto de datos se encuentra en Amazon S3, se actualiza mensualmente y se puede acceder a él directamente a través de AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzEl conjunto de datos Common Crawl también proporciona una tabla de índice para filtrar datos, que se denomina cc-index-table.
La tabla de índice cc es un índice de los datos existentes y proporciona un índice basado en tablas de archivos WARC. Permite buscar fácilmente información, como qué archivo WARC corresponde a una URL específica.
Por ejemplo, puede crear una tabla de Athena para asignar datos de índice cc con el siguiente código:
Las declaraciones SQL anteriores demuestran cómo crear una tabla de Athena, agregar particiones y ejecutar una consulta.
Filtrar datos del conjunto de datos de rastreo común
Como puede ver en la instrucción SQL de creación de tabla, hay varios campos que pueden ayudar a filtrar los datos. Por ejemplo, si desea obtener el recuento de documentos chinos durante un período específico, la declaración SQL podría ser la siguiente:
Si desea realizar un procesamiento adicional, puede guardar los resultados en otro depósito de S3.
Analizar los datos filtrados
El proyecto Repositorio de GitHub de rastreo común proporciona varios ejemplos de PySpark para procesar los datos sin procesar.
Veamos un ejemplo de ejecución. server_count.py (script de ejemplo proporcionado por el repositorio Common Crawl de GitHub) en los datos ubicados en s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Primero, necesita un entorno Spark, como EMR Spark. Por ejemplo, puede lanzar un clúster de Amazon EMR en EC2 en us-east-1 (porque el conjunto de datos está en us-east-1). El uso de un EMR en el clúster EC2 puede ayudarle a realizar pruebas antes de enviar trabajos al entorno de producción.
Después de iniciar un EMR en el clúster EC2, debe iniciar sesión SSH en el nodo principal del clúster. Luego, empaquete el entorno Python y envíe el script (consulte la documentación conda para instalar Miniconda):
Puede llevar tiempo procesar todas las referencias en warc.path. Para fines de demostración, puede mejorar el tiempo de procesamiento con las siguientes estrategias:
- Descargar el archivo
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gza su máquina local, descomprímalo y luego cárguelo en HDFS o Amazon S3. Esto se debe a que el archivo .gzip no se puede dividir. Debe descomprimirlo para procesar este archivo en paralelo. - Modificar el
warc.patharchivo, elimine la mayoría de sus líneas y conserve solo dos líneas para que el trabajo se ejecute mucho más rápido.
Una vez completado el trabajo, podrá ver el resultado en s3://xxxx-common-crawl/output/, en formato Parquet.
Implementar lógica de posesión personalizada
El repositorio Common Crawl de GitHub proporciona un enfoque común para procesar archivos WARC. Generalmente, puedes extender el CCSparkJob para anular un solo método (process_record), que es suficiente para muchos casos.
Veamos un ejemplo para obtener reseñas de IMDB de películas recientes. Primero, necesitas filtrar archivos en el sitio IMDB:
Luego puede obtener listas de archivos WARC que contienen datos de revisión de IMDB y guardar los nombres de los archivos WARC como una lista en un archivo de texto.
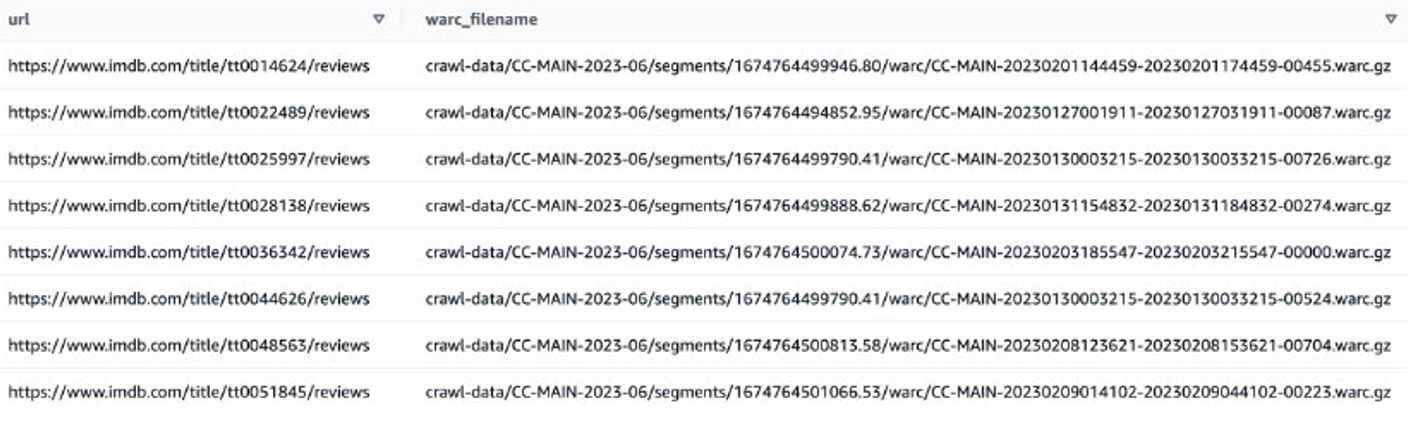
Alternativamente, puede usar EMR Spark para obtener la lista de archivos WARC y almacenarla en Amazon S3. Por ejemplo:
El archivo de salida debería ser similar a s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
El siguiente paso es extraer reseñas de usuarios de estos archivos WARC. Puedes extender el CCSparkJob para anular el process_record() método:
Puede guardar el script anterior como imdb_extractor.py, que utilizará en los siguientes pasos. Una vez que haya preparado los datos y los scripts, puede utilizar EMR Serverless para procesar los datos filtrados.
EMR sin servidor
EMR Serverless es una opción de implementación sin servidor para ejecutar aplicaciones de análisis de big data utilizando marcos de código abierto como Apache Spark y Hive sin configurar, administrar ni escalar clústeres o servidores.
Con EMR Serverless, puede ejecutar cargas de trabajo de análisis a cualquier escala con escalado automático que cambia el tamaño de los recursos en segundos para satisfacer los cambios en los volúmenes de datos y los requisitos de procesamiento. EMR Serverless aumenta y reduce automáticamente los recursos para proporcionar la cantidad adecuada de capacidad para su aplicación, y usted solo paga por lo que usa.
El procesamiento del conjunto de datos de rastreo común es generalmente una tarea de procesamiento única, lo que lo hace adecuado para cargas de trabajo EMR Serverless.
Cree una aplicación EMR sin servidor
Puede crear una aplicación EMR Serverless en la consola de EMR Studio. Complete los siguientes pasos:
- En la consola de EMR Studio, elija Aplicaciones bajo Sin servidor en el panel de navegación.
- Elige Crear aplicación.

- Proporcione un nombre para la aplicación y elija una versión de Amazon EMR.
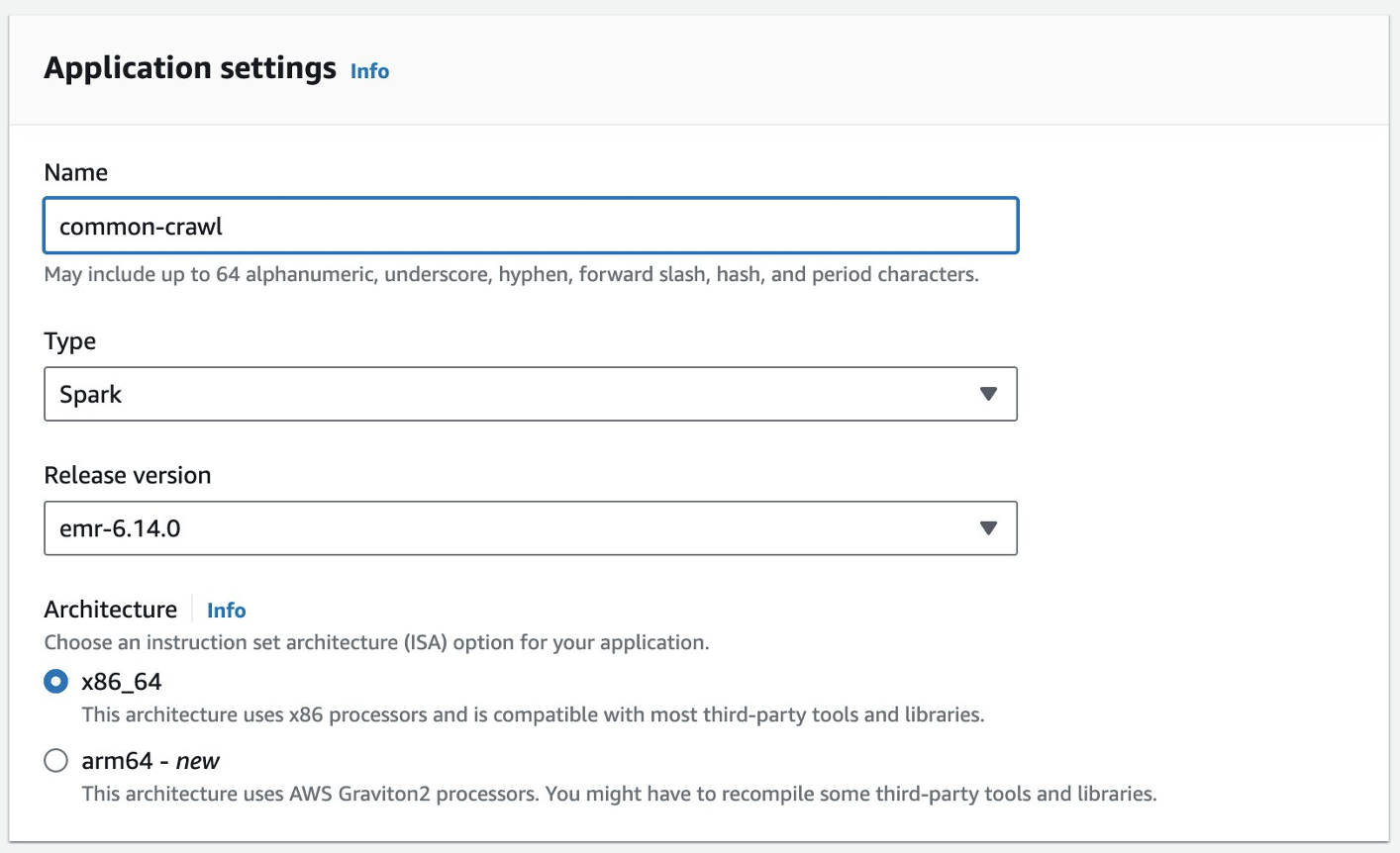
- Si se requiere acceso a los recursos de VPC, agregue una configuración de red personalizada.

- Elige Crear aplicación.
Su entorno sin servidor Spark estará entonces listo.
Antes de poder enviar un trabajo a EMR Spark Serverless, aún necesita crear una función de ejecución. Referirse a Introducción a Amazon EMR sin servidor para más información.
Procese datos de rastreo común con EMR Serverless
Una vez que su aplicación EMR Spark Serverless esté lista, complete los siguientes pasos para procesar los datos:
- Prepare un entorno Conda y cárguelo en Amazon S3, que se utilizará como entorno en EMR Spark Serverless.
- Cargue los scripts que se ejecutarán en un depósito de S3. En el siguiente ejemplo, hay dos scripts:
- imbd_extractor.py – Lógica personalizada para extraer contenidos del conjunto de datos. El contenido se puede encontrar anteriormente en esta publicación.
- cc-pyspark/sparkcc.py – El marco de ejemplo PySpark del Repositorio de GitHub de rastreo común, que es necesario incluir.
- Envíe el trabajo de PySpark a EMR Serverless Spark. Defina los siguientes parámetros para ejecutar este ejemplo en su entorno:
- ID de aplicación – El ID de la aplicación de su aplicación EMR Serverless.
- rol-de-ejecución-arn – Su función de ejecución de EMR Serverless. Para crearlo, consulte Crear un rol en tiempo de ejecución del trabajo.
- Ubicación del archivo WARC – La ubicación de sus archivos WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtcontiene la lista de archivos WARC filtrada, que obtuvo anteriormente en esta publicación. - spark.sql.warehouse.dir – La ubicación predeterminada del almacén (use su directorio S3).
- chispa.archivos – La ubicación S3 del entorno Conda preparado.
- spark.submit.pyArchivos – El script PySpark preparado sparkcc.py.
Ver el siguiente código:
Una vez completado el trabajo, las reseñas extraídas se almacenan en Amazon S3. Para comprobar el contenido, puede utilizar Amazon S3 Select, como se muestra en la siguiente captura de pantalla.
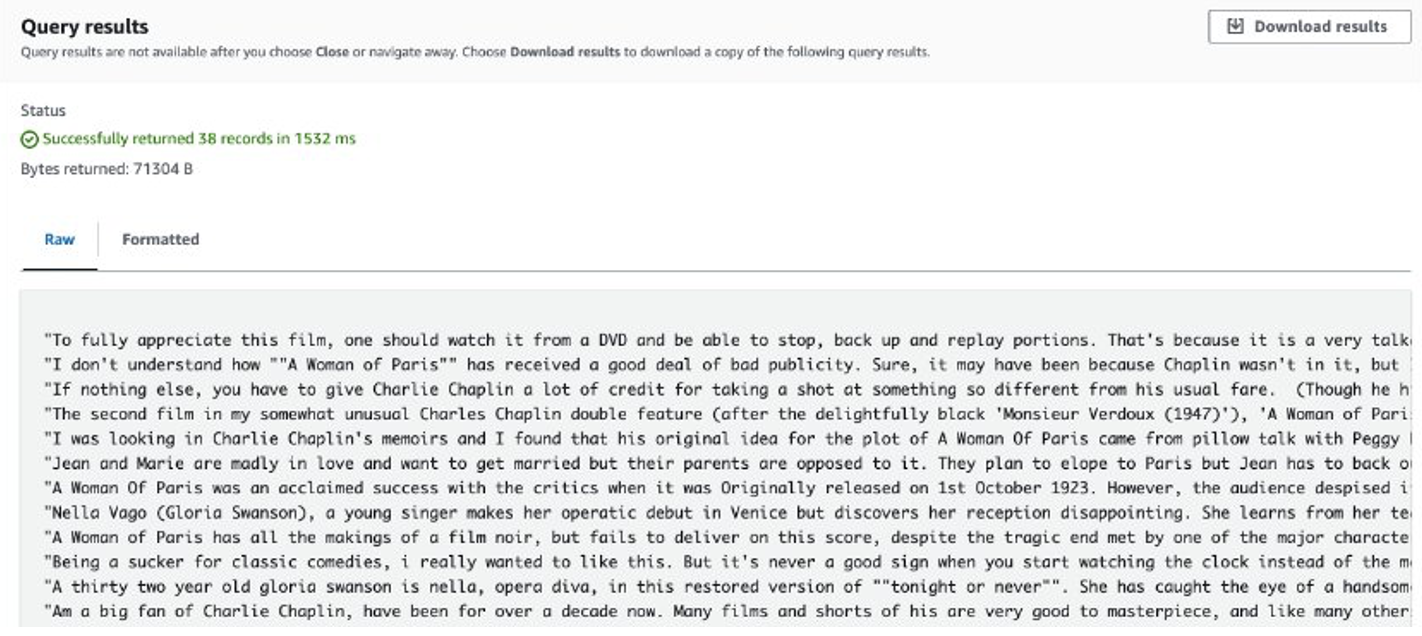
Consideraciones
Los siguientes son los puntos a considerar cuando se trata de cantidades masivas de datos con código personalizado:
- Es posible que algunas bibliotecas de Python de terceros no estén disponibles en Conda. En tales casos, puede cambiar a un entorno virtual Python para crear el entorno de ejecución de PySpark.
- Si hay una gran cantidad de datos para procesar, intente crear y utilizar varias aplicaciones EMR Serverless Spark para paralelizarlos. Cada aplicación trata con un subconjunto de listas de archivos.
- Es posible que encuentre un problema de desaceleración con Amazon S3 al filtrar o procesar los datos de rastreo común. Esto se debe a que el depósito de S3 que almacena los datos es de acceso público y otros usuarios pueden acceder a los datos al mismo tiempo. Para mitigar este problema, puede agregar un mecanismo de reintento o sincronizar datos específicos del depósito Common Crawl S3 con su propio depósito.
Afina Llama 2 con SageMaker
Una vez preparados los datos, puedes ajustar un modelo Llama 2 con ellos. Puede hacerlo utilizando SageMaker JumpStart, sin escribir ningún código. Para obtener más información, consulte Ajuste Llama 2 para la generación de texto en Amazon SageMaker JumpStart.
En este escenario, se lleva a cabo un ajuste de adaptación del dominio. Con este conjunto de datos, la entrada consta de un archivo CSV, JSON o TXT. Debe colocar todos los datos de la revisión en un archivo TXT. Para hacerlo, puede enviar un trabajo Spark sencillo a EMR Spark Serverless. Consulte el siguiente fragmento de código de muestra:
Después de preparar los datos de entrenamiento, ingrese la ubicación de los datos para Conjunto de datos de entrenamiento, A continuación, elija Entrenar.
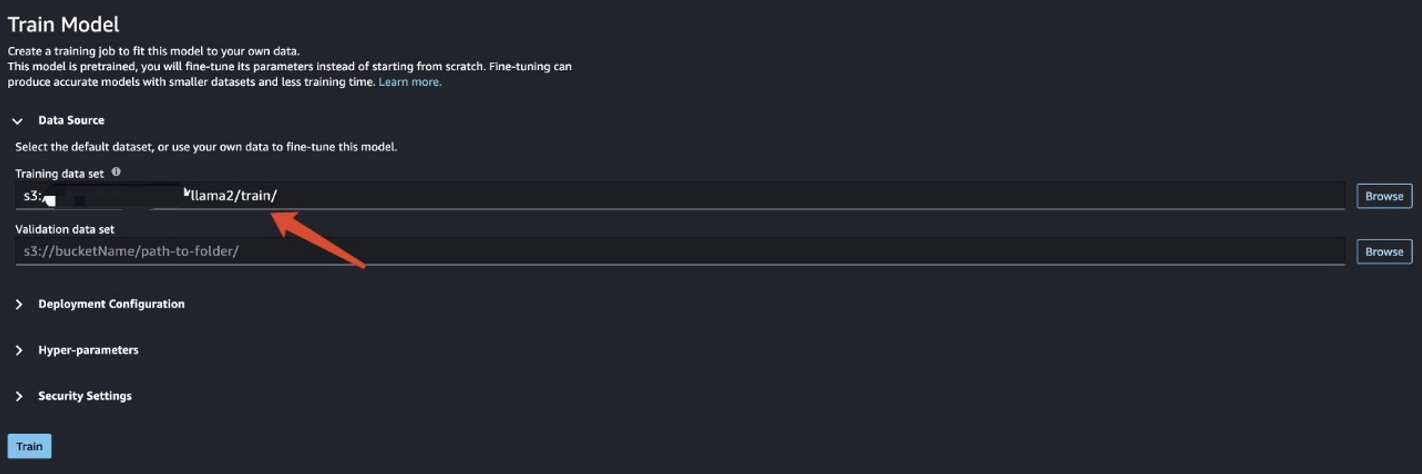
Puede realizar un seguimiento del estado del trabajo de capacitación.
Evaluar el modelo ajustado
Después de completar el entrenamiento, elija Despliegue en SageMaker JumpStart para implementar su modelo ajustado.

Una vez que el modelo se haya implementado correctamente, elija cuaderno abierto, que le redirige a un cuaderno de Jupyter preparado donde puede ejecutar su código Python.

Puede utilizar la imagen Data Science 2.0 y el kernel Python 3 para el cuaderno.

Luego, podrá evaluar el modelo ajustado y el modelo original en este cuaderno.
Las siguientes son dos respuestas devueltas por el modelo original y el modelo ajustado para la misma pregunta.
Proporcionamos a ambos modelos la misma frase: “La reseña de la película 'Una mujer de París: Un drama del destino' es” y les dejamos completar la frase.
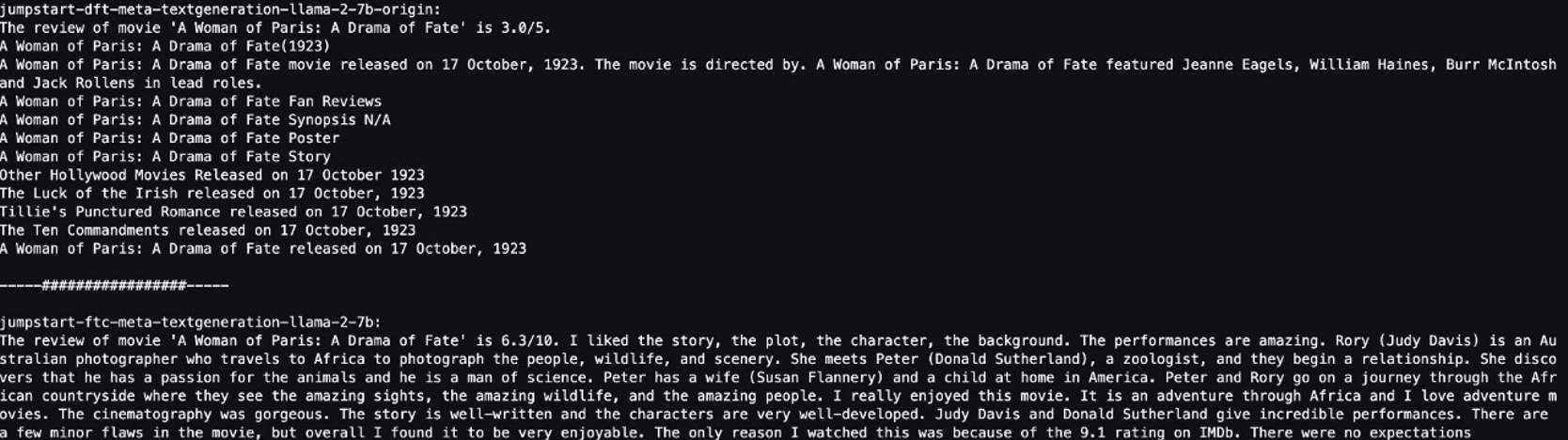
El modelo original genera oraciones sin sentido:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Por el contrario, los resultados del modelo ajustado se parecen más a la reseña de una película:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Obviamente, el modelo ajustado funciona mejor en este escenario específico.
Limpiar
Después de terminar este ejercicio, complete los siguientes pasos para limpiar sus recursos:
- Eliminar el cubo S3 que almacena el conjunto de datos limpio.
- Detenga el entorno EMR Serverless.
- Eliminar el punto final de SageMaker que alberga el modelo LLM.
- Eliminar el dominio de SageMaker que ejecuta sus portátiles.
La aplicación que creó debería detenerse automáticamente después de 15 minutos de inactividad de forma predeterminada.
Generalmente, no es necesario limpiar el entorno de Athena porque no hay cargos cuando no lo estás usando.
Conclusión
En esta publicación, presentamos el conjunto de datos de rastreo común y cómo usar EMR Serverless para procesar los datos para el ajuste fino de LLM. Luego demostramos cómo usar SageMaker JumpStart para ajustar el LLM e implementarlo sin ningún código. Para conocer más casos de uso de EMR Serverless, consulte Amazon EMR sin servidor. Para obtener más información sobre el alojamiento y el ajuste de modelos en Amazon SageMaker JumpStart, consulte la Documentación de Sagemaker JumpStart.
Acerca de los autores
 Shijian Tang es arquitecto de soluciones especialista en análisis en Amazon Web Services.
Shijian Tang es arquitecto de soluciones especialista en análisis en Amazon Web Services.
 mateo liem es gerente senior de arquitectura de soluciones en Amazon Web Services.
mateo liem es gerente senior de arquitectura de soluciones en Amazon Web Services.
 Dalei Xu es arquitecto de soluciones especialista en análisis en Amazon Web Services.
Dalei Xu es arquitecto de soluciones especialista en análisis en Amazon Web Services.
 Yuanjun Xiao es arquitecto senior de soluciones en Amazon Web Services.
Yuanjun Xiao es arquitecto senior de soluciones en Amazon Web Services.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

