AWS Glue es un servicio de integración de datos sin servidor que simplifica el descubrimiento, la preparación, el movimiento y la integración de datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones. Actualmente, AWS Glue procesa los trabajos de los clientes mediante el motor de procesamiento distribuido de Apache Spark para cargas de trabajo grandes o el motor de procesamiento de un solo nodo de Python para cargas de trabajo más pequeñas. A los clientes les gusta Python por su facilidad de uso y su rica colección de bibliotecas de procesamiento de datos integradas, pero puede resultarles difícil escalar Python más allá de un solo nodo de cómputo. Esta limitación dificulta que los clientes procesen grandes conjuntos de datos. Los clientes quieren una solución que les permita continuar usando las herramientas familiares de Python y los trabajos de AWS Glue en conjuntos de datos de todos los tamaños, incluso aquellos que no caben en una sola instancia.
Nos complace anunciar el lanzamiento de un nuevo tipo de trabajo de AWS Glue: Ray. Ray es un marco de trabajo unificado de código abierto que simplifica la escalabilidad de las cargas de trabajo de IA y Python. Ray comenzó como un proyecto de código abierto en RISELab en la Universidad de Berkeley. Si su aplicación está escrita en Python, puede escalarla con Ray en un clúster distribuido en un entorno de múltiples nodos. Ray es nativo de Python y puedes combinarlo con el AWS SDK para pandas para preparar, integrar y transformar sus datos para ejecutar sus análisis de datos y cargas de trabajo de ML en combinación. Puede usar AWS Glue for Ray con Glue Studio Notebooks, SageMaker Studio Notebook o una notebook local o IDE de su elección.
Esta publicación proporciona una introducción a AWS Glue for Ray y le muestra cómo comenzar a usar Ray para distribuir sus cargas de trabajo de Python.
¿Qué es AWS Glue para Ray?
A los clientes les gusta la experiencia sin servidor y el tiempo de inicio rápido que ofrece AWS Glue. Con la introducción de Ray, nos hemos asegurado de que obtenga la misma experiencia. También nos hemos asegurado de que pueda utilizar el trabajo de AWS Glue y las primitivas de sesión interactiva de AWS Glue para acceder al motor de Ray. Los trabajos de AWS Glue son sistemas de disparar y olvidar en los que el cliente envía su código Ray a la API de trabajos de AWS Glue y AWS Glue aprovisiona automáticamente los recursos informáticos necesarios y ejecuta el trabajo. Las API de sesión interactiva de AWS Glue permiten la exploración interactiva de los datos con el fin de desarrollar el trabajo. Independientemente de la opción utilizada, solo se le factura por la duración del cálculo utilizado. Con AWS Glue for Ray, también presentamos un nuevo trabajador basado en Graviton2 (Z.2x) que ofrece 8 CPU virtuales y 64 GB de RAM.
AWS Glue for Ray consta de dos componentes principales:
- Núcleo de rayos – El marco de computación distribuida
- Conjunto de datos de rayos – El marco de datos distribuidos basado en Apache Arrow
Al ejecutar un trabajo de Ray, AWS Glue aprovisiona el Cúmulo de rayos para usted y ejecuta estos trabajos de Python distribuidos en una infraestructura de escalado automático sin servidor. El clúster en AWS Glue for Ray constará exactamente de un nodo principal y uno o más nodos trabajadores.
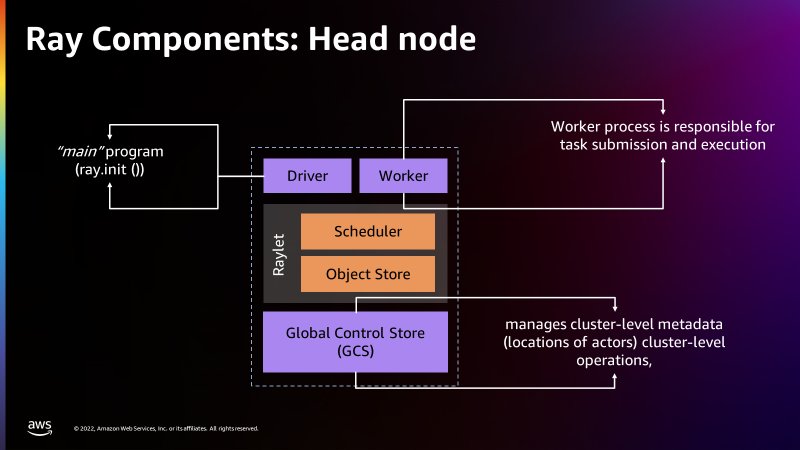
El nodo principal es idéntico a los otros nodos de trabajo con la excepción de que ejecuta procesos singleton para la administración de clústeres y el proceso del controlador Ray. El controlador es un proceso de trabajo especial en el nodo principal que ejecuta la aplicación de nivel superior en Python que inicia el trabajo de Ray. El nodo trabajador tiene procesos que son responsables de enviar y ejecutar tareas.
La siguiente figura proporciona una introducción simple a la arquitectura Ray. La arquitectura ilustra cómo Ray puede programar trabajos a través de procesos llamados Raylets. El Raylet administra los recursos compartidos en cada nodo y se comparte entre los trabajos que se ejecutan simultáneamente. Para obtener más información sobre cómo funciona Ray, consulte Ray.io.

La siguiente figura muestra los componentes del nodo trabajador y el almacén de objetos de memoria compartida:

Hay un Almacén de control global en el nodo principal que puede tratar cada máquina por separado como nodos, de forma similar a como Apache Spark trata a los trabajadores como nodos. La siguiente figura muestra los componentes del nodo principal y el Almacén de control global que administra los metadatos a nivel de clúster.
AWS Glue for Ray viene incluido con Ray Core, Conjunto de datos de rayos, Modín (pandas distribuidos) y AWS SDK para pandas (en Modin) para una integración distribuida perfecta en otros servicios de AWS. Ray Core es la base de Ray y el marco básico para distribuir funciones y clases de Python. Ray Dataset es un marco de datos distribuido basado en Apache Arrow y es más parecido a un marco de datos en Apache Spark. Modin es una biblioteca diseñada para distribuir aplicaciones de pandas en un clúster de Ray sin ninguna modificación y es compatible con los datos de los conjuntos de datos de Ray. El SDK de AWS incluido para pandas (anteriormente AWS Data Wrangler) es una capa de abstracción en la parte superior de Modin para permitir la creación de marcos de datos de pandas desde (y escribir en) muchas fuentes de AWS como Amazon Simple Storage Service (Amazon S3), Amazon Redshift , Amazon DynamoDB, Amazon OpenSearch Service y otros.
También puede instalar sus propias bibliotecas de Python compatibles con ARM a través de pip, ya sea a través de la configuración ambiental de Ray en @ray.remote o a través --additional-python-modules.
Para obtener más información sobre Ray, visite el Repositorio GitHub.
¿Por qué usar AWS Glue para Ray?
Muchos de nosotros comenzamos nuestro viaje de datos en AWS con Python, buscando preparar datos para ML y ciencia de datos, y mover datos a escala con las API de AWS y Boto3. Ray le permite llevar esas habilidades, paradigmas, marcos y bibliotecas familiares a AWS Glue y hacer que se escalen para manejar conjuntos de datos masivos con cambios mínimos en el código. Puede usar las mismas herramientas de procesamiento de datos que tiene actualmente (como las bibliotecas de Python para la limpieza de datos, el cálculo y el aprendizaje automático) en conjuntos de datos de todos los tamaños. AWS Glue for Ray permite la ejecución distribuida de sus scripts de Python en clústeres de varios nodos.
AWS Glue for Ray está diseñado para lo siguiente:
- Aplicaciones paralelas de tareas (por ejemplo, cuando desea aplicar varias transformaciones en paralelo)
- Acelerar su carga de trabajo de Python y usar bibliotecas nativas de Python.
- Ejecutar la misma carga de trabajo en cientos de fuentes de datos.
- Ingestión de ML e inferencia de lotes paralelos en datos
Resumen de la solución
Para este post, utilizarás el Parquet Conjunto de datos de reseñas de clientes de Amazon almacenado en el depósito público de S3. El objetivo es realizar transformaciones utilizando el conjunto de datos de Ray y luego volver a escribirlo en Amazon S3 en el formato de archivo Parquet.
Configurar Amazon S3
El primer paso es crear un depósito de Amazon S3 para almacenar el conjunto de datos de Parquet transformado como resultado final.
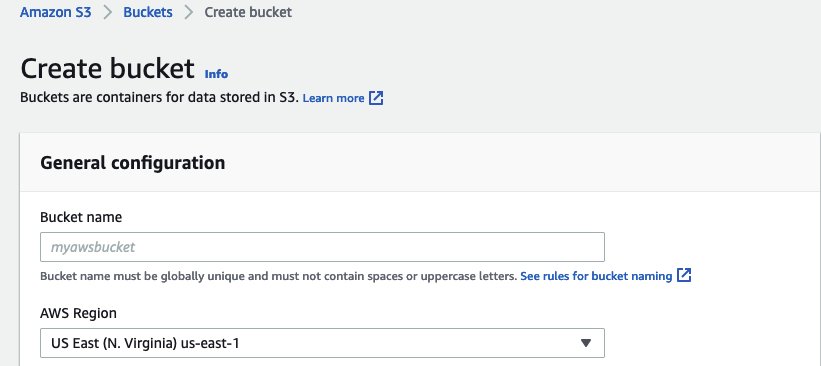
- En Consola de Amazon S3, escoger cubos en el panel de navegación.
- Elige Crear cubeta.
- nombre del cubo, ingrese un nombre para su depósito de Amazon S3.
- Elige Crear.
Configure un cuaderno Jupyter con una sesión interactiva de AWS Glue
Para nuestro entorno de desarrollo, usamos un cuaderno Jupyter para ejecutar el código.
Debe instalar las sesiones interactivas de AWS Glue localmente o ejecutar sesiones interactivas con un Cuaderno de AWS Glue Studio. El uso de sesiones de AWS Glue Interactive lo ayudará a seguir y ejecutar la serie de pasos de demostración.
Consulte Introducción a las sesiones interactivas de AWS Glue para obtener instrucciones sobre cómo activar un cuaderno en una sesión interactiva de AWS Glue.
Ejecute su código usando Ray en un cuaderno Jupyter
Esta sección lo guía a través de varios párrafos del cuaderno sobre cómo usar AWS Glue for Ray. En este ejercicio, analizamos las opiniones de los clientes del conjunto de datos Parquet de opiniones de clientes de Amazon, realizamos algunas transformaciones de Ray y escribimos los resultados en Amazon S3 en formato Parquet.
- En la consola Jupyter, debajo Nuevo, escoger pitón pegamento.
- Indica que quieres usar a Ray como el motor usando el
%glue_raymagia. - Importe la biblioteca Ray junto con bibliotecas adicionales de Python:
- Inicialice un Ray Cluster con AWS Glue.
- A continuación, leemos una única partición del conjunto de datos, que tiene el formato de archivo Parquet:

- Los archivos de parquet almacenan la cantidad de filas por archivo en los metadatos, por lo que podemos obtener la cantidad total de registros en ds sin realizar una lectura completa de datos:
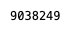
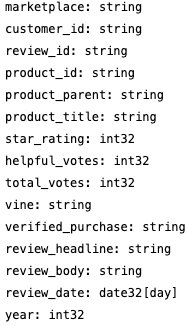
- A continuación, podemos comprobar el esquema de este conjunto de datos. No tenemos que leer los datos reales para obtener el esquema; podemos leerlo desde los metadatos:
- Podemos verificar el tamaño total en bytes para el conjunto de datos completo de Ray:
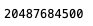
- Podemos ver un registro de muestra del conjunto de datos Ray:


Aplicar transformaciones de conjuntos de datos con Ray
Existen principalmente dos tipos de transformaciones que se pueden aplicar a los conjuntos de datos de rayos:
- Transformaciones uno a uno: cada bloque de entrada contribuirá a un solo bloque de salida, como
add_column(),map_batches()ydrop_column(), Y así sucesivamente. - Transformaciones de todo a todo: los bloques de entrada pueden contribuir a varios bloques de salida, como
sort()ygroupby(), Y así sucesivamente.
En la siguiente serie de pasos, aplicaremos algunas de estas transformaciones en nuestros conjuntos de datos de rayos resultantes de la sección anterior.
- Podemos agregar una nueva columna y verificar el esquema para verificar la columna recién agregada, y luego recuperar un registro de muestra. Esta transformación solo está disponible para los conjuntos de datos que se pueden convertir al formato pandas.

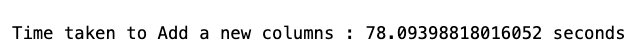
- Dejemos algunas columnas que no necesitamos usando un
drop_columnstransformación y luego verifique el esquema para verificar si esas columnas se eliminan del conjunto de datos Ray:

Los conjuntos de datos de rayos tienen transformaciones integradas, como ordenar el conjunto de datos por la columna clave especificada o la función clave. - A continuación, aplicamos la transformación de clasificación utilizando una de las columnas presentes en el conjunto de datos (
total_votes):
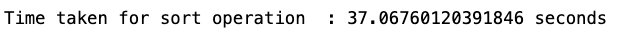
- A continuación, crearemos una función UDF de Python que le permita escribir lógica empresarial personalizada en transformaciones. En nuestro UDF, hemos escrito una lógica para encontrar los productos que tienen una calificación baja (es decir, un total de votos inferior a 100). Creamos un UDF como una función en los lotes de Pandas DataFrame. Para conocer los formatos por lotes de entrada admitidos, consulte la Formato de lote de entrada UDF. También demostramos usando
map_batches()que aplica la función dada a los lotes de registros de este conjunto de datos.Map_batches()utiliza la estrategia informática predeterminada (tareas), que ayuda a distribuir el procesamiento de datos a varios trabajadores de Ray, que se utilizan para ejecutar tareas. Para obtener más información sobre unmap_batches()transformación, consulte la siguiente documentación.
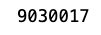
- Si tiene transformaciones complejas que requieren más recursos para el procesamiento de datos, le recomendamos utilizar actores de rayos con configuraciones adicionales con transformaciones aplicables. hemos demostrado con
map_batches()aqui: - A continuación, antes de escribir el conjunto de datos Ray resultante final, aplicaremos
map_batches()transformaciones para filtrar los datos de reseñas de clientes donde el total de votos para un producto determinado es mayor que 0 y las reseñas pertenecen solo al mercado de "EE. UU.". Usandomap_batches()para el funcionamiento del filtro es mejor en términos de rendimiento en comparación confilter()transformación.
- Finalmente, escribimos los datos resultantes en el depósito S3 que creó en un formato de archivo Parquet. Puede usar diferentes API de conjuntos de datos disponibles, como
write_csv()orwrite_json()para diferentes formatos de archivo. Además, puede convertir el conjunto de datos resultante a otro tipo de DataFrame como Mars, Modin o pandas.
Limpiar
Para evitar incurrir en cargos futuros, elimine el depósito de Amazon S3 y el cuaderno de Jupyter.
- En la consola de Amazon S3, elija cubos.
- Elija el depósito que creó.
- Elige Vacío e ingrese el nombre de su depósito.
- Elige Confirmar.
- Elige Borrar e ingrese el nombre de su depósito.
- Elige Eliminar cubo.
- En la consola de AWS Glue, elija Sesiones interactivas
- Elija la sesión interactiva que creó.
- Elija Deliminar para eliminar la sesión interactiva.
Conclusión
En esta publicación, demostramos cómo puede usar AWS Glue for Ray para ejecutar su código de Python en un entorno distribuido. Ahora puede ejecutar sus aplicaciones de datos y ML en un entorno de varios nodos.
Para obtener más detalles sobre cómo diseñar y realizar los esfuerzos de seguimiento y evaluación, refierase a Documentación de Ray para obtener información adicional y casos de uso.
Sobre los autores
 zach mitchell es Arquitecto Sr. de Big Data. Trabaja dentro del equipo de productos para mejorar la comprensión entre los ingenieros de productos y sus clientes mientras guía a los clientes a través de su viaje para desarrollar lagos de datos y otras soluciones de datos en los servicios de análisis de AWS.
zach mitchell es Arquitecto Sr. de Big Data. Trabaja dentro del equipo de productos para mejorar la comprensión entre los ingenieros de productos y sus clientes mientras guía a los clientes a través de su viaje para desarrollar lagos de datos y otras soluciones de datos en los servicios de análisis de AWS.
 ishan gaur trabaja como Sr. Big Data Cloud Engineer (ETL) especializado en AWS Glue. Le apasiona ayudar a los clientes a crear cargas de trabajo ETL distribuidas escalables e implementar canalizaciones de análisis y procesamiento de datos escalables en AWS. Cuando no está en el trabajo, a Ishan le gusta cocinar, viajar con su familia o escuchar música.
ishan gaur trabaja como Sr. Big Data Cloud Engineer (ETL) especializado en AWS Glue. Le apasiona ayudar a los clientes a crear cargas de trabajo ETL distribuidas escalables e implementar canalizaciones de análisis y procesamiento de datos escalables en AWS. Cuando no está en el trabajo, a Ishan le gusta cocinar, viajar con su familia o escuchar música.
 Derek Liu es Arquitecto de soluciones en el equipo de Enterprise con sede en Vancouver, BC. Forma parte de la comunidad de campo de AWS Analytics y disfruta ayudando a los clientes a resolver desafíos de big data a través de los servicios analíticos de AWS.
Derek Liu es Arquitecto de soluciones en el equipo de Enterprise con sede en Vancouver, BC. Forma parte de la comunidad de campo de AWS Analytics y disfruta ayudando a los clientes a resolver desafíos de big data a través de los servicios analíticos de AWS.
 Kinshuk Paharé es gerente principal de productos en AWS Glue.
Kinshuk Paharé es gerente principal de productos en AWS Glue.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/introducing-aws-glue-for-ray-scaling-your-data-integration-workloads-using-python/

