En esta publicación, demostramos cómo utilizar la poda estructural basada en búsqueda de arquitectura neuronal (NAS) para comprimir un modelo BERT ajustado para mejorar el rendimiento del modelo y reducir los tiempos de inferencia. Los modelos de lenguaje previamente entrenados (PLM) están experimentando una rápida adopción comercial y empresarial en las áreas de herramientas de productividad, servicio al cliente, búsqueda y recomendaciones, automatización de procesos comerciales y creación de contenido. La implementación de puntos finales de inferencia PLM generalmente se asocia con una mayor latencia y mayores costos de infraestructura debido a los requisitos informáticos y una eficiencia computacional reducida debido a la gran cantidad de parámetros. La poda de un PLM reduce el tamaño y la complejidad del modelo al tiempo que conserva sus capacidades predictivas. Los PLM podados logran una menor huella de memoria y una menor latencia. Lo demostramos al podar un PLM y compensar el recuento de parámetros y el error de validación para una tarea objetivo específica, y podemos lograr tiempos de respuesta más rápidos en comparación con el modelo PLM base.
La optimización multiobjetivo es un área de toma de decisiones que optimiza más de una función objetivo, como el consumo de memoria, el tiempo de entrenamiento y los recursos informáticos, para optimizarlos simultáneamente. La poda estructural es una técnica para reducir el tamaño y los requisitos computacionales de PLM mediante la poda de capas o neuronas/nodos mientras se intenta preservar la precisión del modelo. Al eliminar capas, la poda estructural logra tasas de compresión más altas, lo que conduce a una escasez estructurada compatible con el hardware que reduce los tiempos de ejecución y de respuesta. La aplicación de una técnica de poda estructural a un modelo PLM da como resultado un modelo más liviano con una menor huella de memoria que, cuando se aloja como un punto final de inferencia en SageMaker, ofrece una eficiencia de recursos mejorada y un costo reducido en comparación con el PLM optimizado original.
Los conceptos ilustrados en esta publicación se pueden aplicar a aplicaciones que utilizan funciones de PLM, como sistemas de recomendación, análisis de opiniones y motores de búsqueda. Específicamente, puede utilizar este enfoque si tiene equipos dedicados de aprendizaje automático (ML) y ciencia de datos que ajustan sus propios modelos de PLM utilizando conjuntos de datos de dominios específicos e implementan una gran cantidad de puntos finales de inferencia utilizando Amazon SageMaker. Un ejemplo es un minorista en línea que implementa una gran cantidad de puntos finales de inferencia para resúmenes de texto, clasificación de catálogos de productos y clasificación de opiniones sobre productos. Otro ejemplo podría ser un proveedor de atención médica que utiliza puntos finales de inferencia PLM para la clasificación de documentos clínicos, reconocimiento de entidades nombradas a partir de informes médicos, chatbots médicos y estratificación del riesgo del paciente.
Resumen de la solución
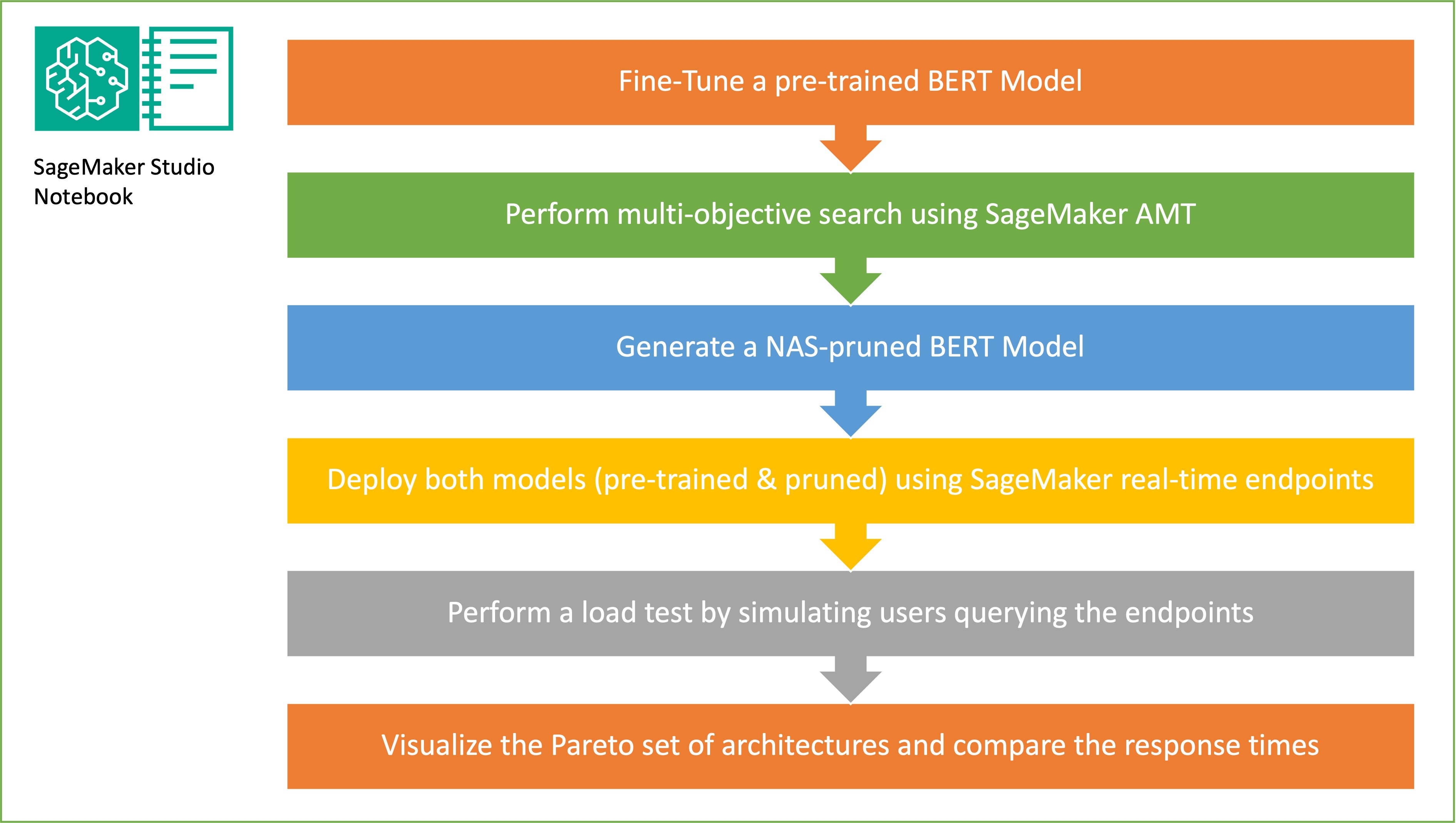
En esta sección, presentamos el flujo de trabajo general y explicamos el enfoque. Primero, utilizamos un Estudio Amazon SageMaker cuaderno para ajustar un modelo BERT previamente entrenado en una tarea objetivo utilizando un conjunto de datos específico de dominio. BERTI (Representaciones de codificador bidireccional de Transformers) es un modelo de lenguaje previamente entrenado basado en arquitectura del transformador Se utiliza para tareas de procesamiento del lenguaje natural (PNL). La búsqueda de arquitectura neuronal (NAS) es un enfoque para automatizar el diseño de redes neuronales artificiales y está estrechamente relacionado con la optimización de hiperparámetros, un enfoque ampliamente utilizado en el campo del aprendizaje automático. El objetivo de NAS es encontrar la arquitectura óptima para un problema determinado buscando en un gran conjunto de arquitecturas candidatas utilizando técnicas como la optimización sin gradientes u optimizando las métricas deseadas. El rendimiento de la arquitectura normalmente se mide mediante métricas como la pérdida de validación. Ajuste automático de modelos de SageMaker (AMT) automatiza el tedioso y complejo proceso de encontrar las combinaciones óptimas de hiperparámetros del modelo ML que produzcan el mejor rendimiento del modelo. AMT utiliza algoritmos de búsqueda inteligentes y evaluaciones iterativas utilizando una variedad de hiperparámetros que usted especifica. Elige los valores de hiperparámetros que crean un modelo que funciona mejor, según lo medido por métricas de rendimiento como la precisión y la puntuación F-1.
El enfoque de ajuste descrito en esta publicación es genérico y se puede aplicar a cualquier conjunto de datos basado en texto. La tarea asignada al BERT PLM puede ser una tarea basada en texto, como análisis de sentimientos, clasificación de texto o preguntas y respuestas. En esta demostración, la tarea objetivo es un problema de clasificación binaria en el que se utiliza BERT para identificar, a partir de un conjunto de datos que consta de una colección de pares de fragmentos de texto, si el significado de un fragmento de texto se puede inferir del otro fragmento. Usamos el Reconocer el conjunto de datos de vinculación textual de la suite de evaluación comparativa GLUE. Realizamos una búsqueda multiobjetivo utilizando SageMaker AMT para identificar las subredes que ofrecen compensaciones óptimas entre el recuento de parámetros y la precisión de la predicción para la tarea objetivo. Al realizar una búsqueda multiobjetivo, comenzamos definiendo la precisión y el recuento de parámetros como los objetivos que pretendemos optimizar.
Dentro de la red BERT PLM, puede haber subredes modulares e independientes que permiten que el modelo tenga capacidades especializadas, como la comprensión del lenguaje y la representación del conocimiento. BERT PLM utiliza una subred de autoatención de múltiples encabezados y una subred de retroalimentación. Una capa de autoatención de múltiples encabezados permite a BERT relacionar diferentes posiciones de una sola secuencia para calcular una representación de la secuencia al permitir que múltiples encabezados presten atención a múltiples señales de contexto. La entrada se divide en varios subespacios y la atención propia se aplica a cada uno de los subespacios por separado. Múltiples cabezales en un PLM de transformador permiten que el modelo atienda de manera conjunta información de diferentes subespacios de representación. Una subred de retroalimentación es una red neuronal simple que toma la salida de la subred de autoatención de múltiples encabezados, procesa los datos y devuelve las representaciones finales del codificador.
El objetivo del muestreo aleatorio de subredes es entrenar modelos BERT más pequeños que puedan funcionar suficientemente bien en las tareas específicas. Tomamos muestras de 100 subredes aleatorias del modelo BERT base ajustado y evaluamos 10 redes simultáneamente. Las subredes entrenadas se evalúan según las métricas objetivas y el modelo final se elige en función de las compensaciones encontradas entre las métricas objetivas. Visualizamos el Frente de Pareto para las subredes muestreadas, que contiene el modelo podado que ofrece el equilibrio óptimo entre la precisión del modelo y el tamaño del modelo. Seleccionamos la subred candidata (modelo BERT podado por NAS) en función del tamaño del modelo y la precisión del modelo que estamos dispuestos a intercambiar. A continuación, alojamos los puntos finales, el modelo base BERT previamente entrenado y el modelo BERT podado por NAS utilizando SageMaker. Para realizar pruebas de carga, utilizamos Langosta, una herramienta de prueba de carga de código abierto que puedes implementar usando Python. Realizamos pruebas de carga en ambos puntos finales usando Locust y visualizamos los resultados usando el frente de Pareto para ilustrar la compensación entre tiempos de respuesta y precisión para ambos modelos. El siguiente diagrama proporciona una descripción general del flujo de trabajo explicado en esta publicación.
Requisitos previos
Para este puesto se requieren los siguientes requisitos previos:
También es necesario aumentar el cuota de servicio para acceder al menos a tres instancias de ml.g4dn.xlarge en SageMaker. El tipo de instancia ml.g4dn.xlarge es la instancia de GPU rentable que le permite ejecutar PyTorch de forma nativa. Para aumentar la cuota de servicio, complete los siguientes pasos:
- En la consola, navegue hasta Cuotas de servicio.
- Administrar cuotas, escoger Amazon SageMaker, A continuación, elija Ver cuotas.

- Busque "ml-g4dn.xlarge para el uso del trabajo de capacitación" y seleccione el elemento de cuota.
- Elige Solicitar aumento a nivel de cuenta.
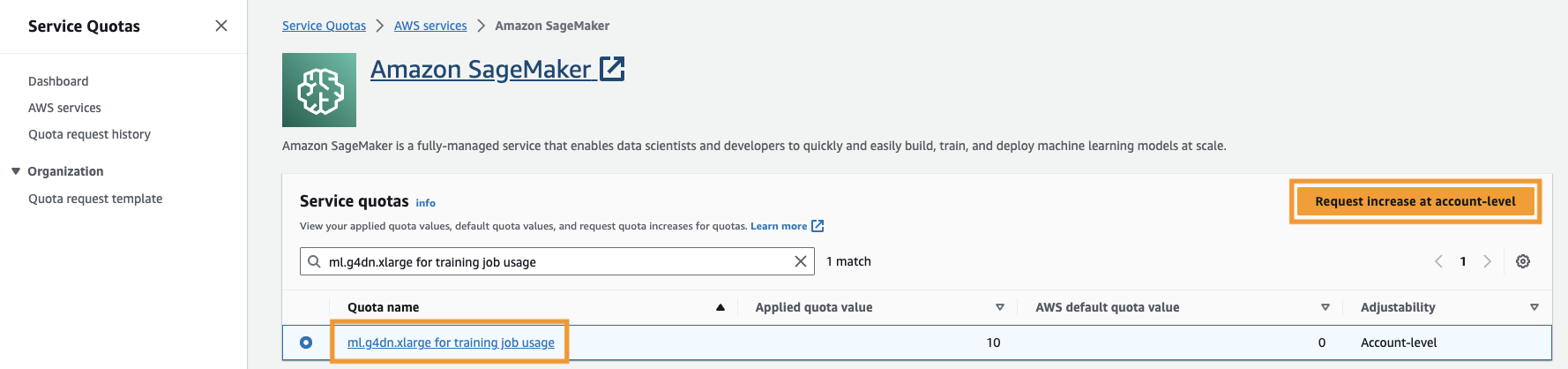
- Aumentar el valor de la cuota, introduzca un valor de 5 o superior.
- Elige SOLICITUD.
La aprobación de la cuota solicitada puede tardar algún tiempo en completarse según los permisos de la cuenta.
- Abra SageMaker Studio desde la consola de SageMaker.

- Elige terminal del sistema bajo Utilidades y archivos.
- Ejecute el siguiente comando para clonar el Repositorio GitHub a la instancia de SageMaker Studio:
- Navegue hasta
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Abra el archivo
nas_for_llm_with_amt.ipynb. - Configurar el entorno con un
ml.g4dn.xlargeinstancia y elige Seleccione.
Configurar el modelo BERT previamente entrenado
En esta sección, importamos el conjunto de datos de Reconocimiento de vinculación textual de la biblioteca de conjuntos de datos y dividimos el conjunto de datos en conjuntos de entrenamiento y validación. Este conjunto de datos consta de pares de oraciones. La tarea del BERT PLM es reconocer, dados dos fragmentos de texto, si el significado de un fragmento de texto se puede inferir del otro. En el siguiente ejemplo, podemos inferir el significado de la primera frase a partir de la segunda frase:
Cargamos el conjunto de datos de vinculación de reconocimiento textual desde el COLA suite de evaluación comparativa a través de biblioteca de conjuntos de datos de Hugging Face dentro de nuestro guión de entrenamiento (./training.py). Dividimos el conjunto de datos de entrenamiento original de GLUE en un conjunto de entrenamiento y validación. En nuestro enfoque, ajustamos el modelo BERT base utilizando el conjunto de datos de entrenamiento, luego realizamos una búsqueda multiobjetivo para identificar el conjunto de subredes que equilibran de manera óptima las métricas objetivas. Utilizamos el conjunto de datos de entrenamiento exclusivamente para ajustar el modelo BERT. Sin embargo, utilizamos datos de validación para la búsqueda multiobjetivo midiendo la precisión en el conjunto de datos de validación reservados.
Ajuste el BERT PLM utilizando un conjunto de datos específico del dominio
Los casos de uso típicos de un modelo BERT sin formato incluyen la predicción de la siguiente oración o el modelado de lenguaje enmascarado. Para utilizar el modelo BERT básico para tareas posteriores, como el reconocimiento de vinculaciones textuales, tenemos que ajustar aún más el modelo utilizando un conjunto de datos específico de dominio. Puede utilizar un modelo BERT ajustado para tareas como clasificación de secuencias, respuesta a preguntas y clasificación de tokens. Sin embargo, para los fines de esta demostración, utilizamos el modelo ajustado para la clasificación binaria. Ajustamos el modelo BERT previamente entrenado con el conjunto de datos de entrenamiento que preparamos previamente, utilizando los siguientes hiperparámetros:
Guardamos el punto de control del entrenamiento del modelo en un Servicio de almacenamiento simple de Amazon (Amazon S3), para que el modelo se pueda cargar durante la búsqueda multiobjetivo basada en NAS. Antes de entrenar el modelo, definimos métricas como época, pérdida de entrenamiento, número de parámetros y error de validación:
Una vez iniciado el proceso de ajuste, el trabajo de formación tarda unos 15 minutos en completarse.
Realizar una búsqueda multiobjetivo para seleccionar subredes y visualizar los resultados.
En el siguiente paso, realizamos una búsqueda multiobjetivo en el modelo BERT base ajustado mediante el muestreo de subredes aleatorias utilizando SageMaker AMT. Para acceder a una subred dentro de la superred (el modelo BERT ajustado), enmascaramos todos los componentes del PLM que no forman parte de la subred. Enmascarar una superred para encontrar subredes en un PLM es una técnica utilizada para aislar e identificar patrones de comportamiento del modelo. Tenga en cuenta que los transformadores Hugging Face necesitan que el tamaño oculto sea un múltiplo del número de cabezales. El tamaño oculto en un PLM de transformador controla el tamaño del espacio vectorial de estado oculto, lo que afecta la capacidad del modelo para aprender representaciones y patrones complejos en los datos. En un BERT PLM, el vector de estado oculto tiene un tamaño fijo (768). No podemos cambiar el tamaño oculto y, por lo tanto, el número de cabezas debe estar en [1, 3, 6, 12].
A diferencia de la optimización de un solo objetivo, en el entorno de múltiples objetivos, normalmente no tenemos una solución única que optimice todos los objetivos simultáneamente. En cambio, nuestro objetivo es recopilar un conjunto de soluciones que dominen todas las demás soluciones en al menos un objetivo (como el error de validación). Ahora podemos iniciar la búsqueda multiobjetivo a través de AMT configurando las métricas que queremos reducir (error de validación y número de parámetros). Las subredes aleatorias están definidas por el parámetro max_jobs y el número de trabajos simultáneos está definido por el parámetro max_parallel_jobs. El código para cargar el punto de control del modelo y evaluar la subred está disponible en el evaluate_subnetwork.py guión.
El trabajo de ajuste de AMT tarda aproximadamente 2 horas y 20 minutos en ejecutarse. Una vez que el trabajo de ajuste de AMT se ejecuta correctamente, analizamos el historial del trabajo y recopilamos las configuraciones de la subred, como la cantidad de cabezales, la cantidad de capas, la cantidad de unidades y las métricas correspondientes, como el error de validación y la cantidad de parámetros. La siguiente captura de pantalla muestra el resumen de un trabajo exitoso del sintonizador AMT.
A continuación, visualizamos los resultados utilizando un conjunto de Pareto (también conocido como frontera de Pareto o conjunto óptimo de Pareto), que nos ayuda a identificar conjuntos óptimos de subredes que dominan todas las demás subredes en la métrica objetiva (error de validación):
Primero, recopilamos los datos del trabajo de ajuste de AMT. Luego trazamos el conjunto de Pareto usando matplotlob.pyplot con número de parámetros en el eje x y error de validación en el eje y. Esto implica que cuando pasamos de una subred del conjunto de Pareto a otra, debemos sacrificar el rendimiento o el tamaño del modelo pero mejorar el otro. En definitiva, el conjunto de Pareto nos brinda la flexibilidad de elegir la subred que mejor se adapte a nuestras preferencias. Podemos decidir cuánto queremos reducir el tamaño de nuestra red y cuánto rendimiento estamos dispuestos a sacrificar.

Implemente el modelo BERT optimizado y el modelo de subred optimizado para NAS utilizando SageMaker
A continuación, implementamos el modelo más grande en nuestro conjunto de Pareto que conduce a la menor cantidad de degeneración del rendimiento a un Punto final de SageMaker. El mejor modelo es aquel que proporciona un equilibrio óptimo entre el error de validación y la cantidad de parámetros para nuestro caso de uso.
Comparación de modelos
Tomamos un modelo BERT base previamente entrenado, lo ajustamos utilizando un conjunto de datos de dominio específico, ejecutamos una búsqueda NAS para identificar subredes dominantes en función de las métricas objetivas e implementamos el modelo podado en un punto final de SageMaker. Además, tomamos el modelo BERT base previamente entrenado y lo implementamos en un segundo punto final de SageMaker. A continuación, corrimos Prueba de carga utilizando Locust en ambos puntos finales de inferencia y evaluó el rendimiento en términos de tiempo de respuesta.
Primero, importamos las bibliotecas Locust y Boto3 necesarias. Luego, construimos metadatos de solicitud y registramos la hora de inicio que se utilizará para las pruebas de carga. Luego, la carga útil se pasa a la API de invocación del punto final de SageMaker a través de BotoClient para simular solicitudes de usuarios reales. Usamos Locust para generar múltiples usuarios virtuales para enviar solicitudes en paralelo y medir el rendimiento del punto final bajo la carga. Las pruebas se ejecutan aumentando el número de usuarios para cada uno de los dos puntos finales, respectivamente. Una vez completadas las pruebas, Locust genera un archivo CSV de estadísticas de solicitud para cada uno de los modelos implementados.
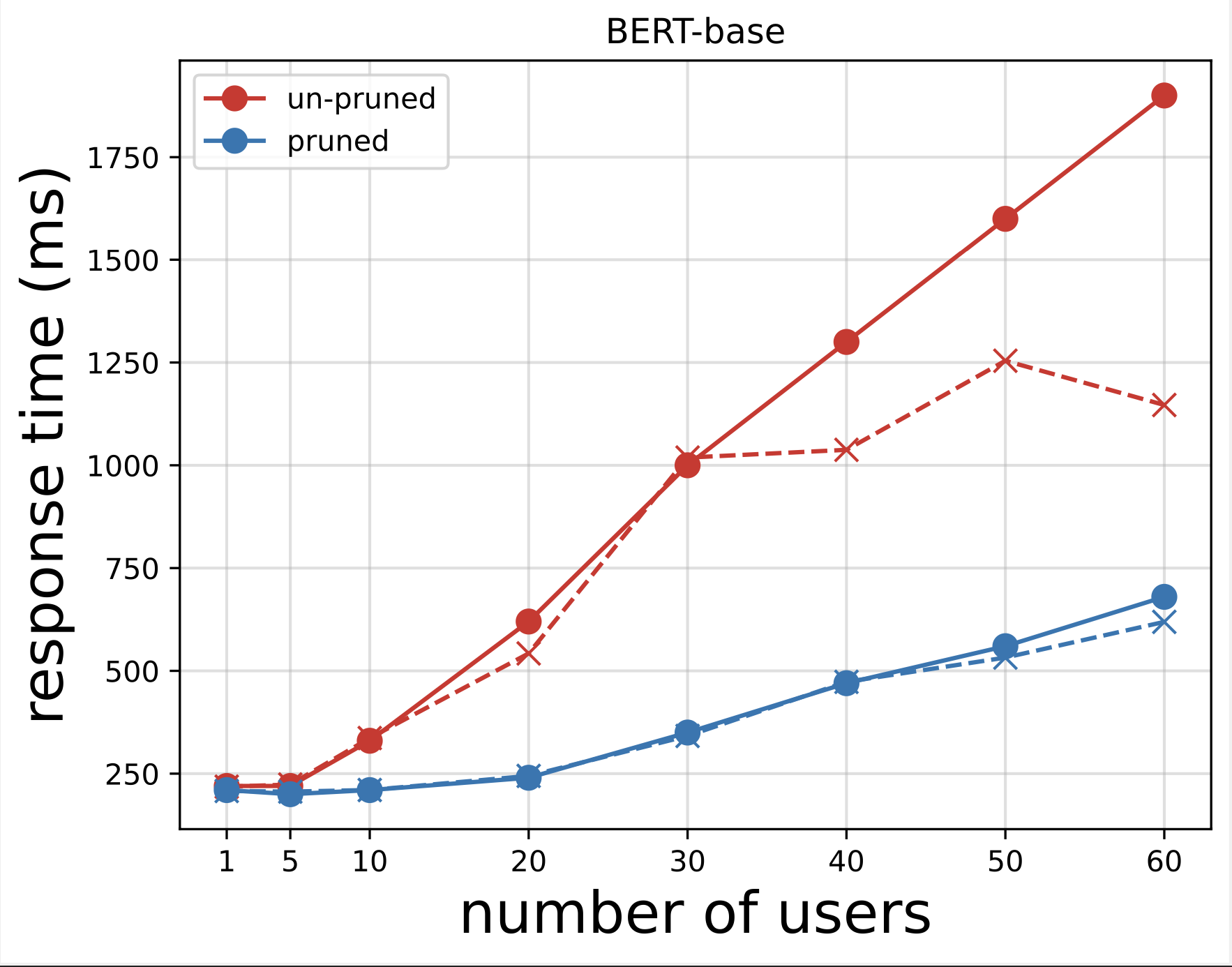
A continuación, generamos los gráficos de tiempo de respuesta a partir de los archivos CSV descargados después de ejecutar las pruebas con Locust. El propósito de trazar el tiempo de respuesta frente a la cantidad de usuarios es analizar los resultados de las pruebas de carga visualizando el impacto del tiempo de respuesta de los puntos finales del modelo. En el siguiente gráfico, podemos ver que el punto final del modelo podado por NAS logra un tiempo de respuesta más bajo en comparación con el punto final del modelo BERT base.
En el segundo gráfico, que es una extensión del primer gráfico, observamos que después de alrededor de 70 usuarios, SageMaker comienza a acelerar el punto final del modelo BERT base y genera una excepción. Sin embargo, para el terminal del modelo recortado por NAS, la limitación se produce entre 90 y 100 usuarios y con un tiempo de respuesta menor.

En los dos gráficos, observamos que el modelo podado tiene un tiempo de respuesta más rápido y escala mejor en comparación con el modelo no podado. A medida que aumentamos la cantidad de puntos finales de inferencia, como es el caso de los usuarios que implementan una gran cantidad de puntos finales de inferencia para sus aplicaciones PLM, los beneficios de costos y la mejora del rendimiento comienzan a ser bastante sustanciales.
Limpiar
Para eliminar los puntos finales de SageMaker para el modelo BERT base ajustado y el modelo podado NAS, complete los siguientes pasos:
- En la consola de SageMaker, elija Inferencia y Endpoints en el panel de navegación.
- Seleccione el punto final y elimínelo.
Alternativamente, desde el cuaderno de SageMaker Studio, ejecute los siguientes comandos proporcionando los nombres de los puntos finales:
Conclusión
En esta publicación, analizamos cómo utilizar NAS para podar un modelo BERT ajustado. Primero entrenamos un modelo BERT base utilizando datos específicos del dominio y lo implementamos en un punto final de SageMaker. Realizamos una búsqueda multiobjetivo en el modelo BERT base ajustado utilizando SageMaker AMT para una tarea objetivo. Visualizamos el frente de Pareto y seleccionamos el modelo BERT podado por NAS óptimo de Pareto e implementamos el modelo en un segundo punto final de SageMaker. Realizamos pruebas de carga utilizando Locust para simular que los usuarios consultaban ambos puntos finales y medimos y registramos los tiempos de respuesta en un archivo CSV. Trazamos el tiempo de respuesta frente al número de usuarios para ambos modelos.
Observamos que el modelo BERT podado funcionó significativamente mejor tanto en el tiempo de respuesta como en el umbral de limitación de instancias. Concluimos que el modelo podado por NAS era más resistente a una mayor carga en el terminal, manteniendo un tiempo de respuesta más bajo incluso cuando más usuarios estresaban el sistema en comparación con el modelo BERT base. Puede aplicar la técnica NAS descrita en esta publicación a cualquier modelo de lenguaje grande para encontrar un modelo podado que pueda realizar la tarea objetivo con un tiempo de respuesta significativamente menor. Puede optimizar aún más el enfoque utilizando la latencia como parámetro además de la pérdida de validación.
Aunque usamos NAS en esta publicación, la cuantificación es otro enfoque común utilizado para optimizar y comprimir modelos PLM. La cuantificación reduce la precisión de los pesos y activaciones en una red entrenada desde punto flotante de 32 bits a anchos de bits más bajos, como enteros de 8 o 16 bits, lo que da como resultado un modelo comprimido que genera una inferencia más rápida. La cuantificación no reduce la cantidad de parámetros; en cambio, reduce la precisión de los parámetros existentes para obtener un modelo comprimido. La poda de NAS elimina las redes redundantes en un PLM, lo que crea un modelo disperso con menos parámetros. Normalmente, la poda y la cuantificación de NAS se utilizan juntas para comprimir PLM grandes para mantener la precisión del modelo, reducir las pérdidas de validación al tiempo que se mejora el rendimiento y se reduce el tamaño del modelo. Las otras técnicas comúnmente utilizadas para reducir el tamaño de los PLM incluyen destilación del conocimiento, factorización de matricesy cascadas de destilación.
El enfoque propuesto en la publicación del blog es adecuado para equipos que usan SageMaker para entrenar y ajustar los modelos utilizando datos específicos del dominio e implementar los puntos finales para generar inferencia. Si está buscando un servicio totalmente administrado que ofrezca una variedad de modelos básicos de alto rendimiento necesarios para crear aplicaciones de IA generativa, considere usar lecho rocoso del amazonas. Si está buscando modelos de código abierto previamente capacitados para una amplia gama de casos de uso empresarial y desea acceder a plantillas de soluciones y cuadernos de ejemplos, considere usar JumpStart de Amazon SageMaker. Una versión previamente entrenada del modelo con carcasa base Hugging Face BERT que utilizamos en esta publicación también está disponible en SageMaker JumpStart.
Acerca de los autores
 Aparajithan Vaidyanathan es arquitecto principal de soluciones empresariales en AWS. Es un arquitecto de la nube con más de 24 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, distribuidos y a gran escala. Se especializa en IA generativa e ingeniería de datos de aprendizaje automático. Es un aspirante a corredor de maratón y sus pasatiempos incluyen caminar, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
Aparajithan Vaidyanathan es arquitecto principal de soluciones empresariales en AWS. Es un arquitecto de la nube con más de 24 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, distribuidos y a gran escala. Se especializa en IA generativa e ingeniería de datos de aprendizaje automático. Es un aspirante a corredor de maratón y sus pasatiempos incluyen caminar, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
 Aaron Klein es un científico aplicado senior en AWS que trabaja en métodos automatizados de aprendizaje automático para redes neuronales profundas.
Aaron Klein es un científico aplicado senior en AWS que trabaja en métodos automatizados de aprendizaje automático para redes neuronales profundas.
 Jacek Golebiowski es un científico aplicado sénior en AWS.
Jacek Golebiowski es un científico aplicado sénior en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

