Lagos de datos impulsados por AWS, respaldados por la disponibilidad inigualable de Servicio de almacenamiento simple de Amazon (Amazon S3), puede manejar la escala, la agilidad y la flexibilidad necesarias para combinar diferentes enfoques de datos y análisis. A medida que los lagos de datos han crecido en tamaño y han madurado en su uso, se puede dedicar una cantidad significativa de esfuerzo a mantener la coherencia de los datos con los eventos comerciales. Para garantizar que los archivos se actualicen de manera coherente desde el punto de vista transaccional, un número creciente de clientes utiliza formatos de tablas transaccionales de código abierto, como iceberg apache, apache hudiy Lago Delta de la Fundación Linux que le ayudan a almacenar datos con altas tasas de compresión, interactuar de forma nativa con sus aplicaciones y marcos y simplificar el procesamiento de datos incremental en lagos de datos creados en Amazon S3. Estos formatos permiten transacciones, actualizaciones y eliminaciones ACID (atomicidad, coherencia, aislamiento, durabilidad), y funciones avanzadas como viajes en el tiempo e instantáneas que anteriormente solo estaban disponibles en los almacenes de datos. Cada formato de almacenamiento implementa esta funcionalidad de maneras ligeramente diferentes; para una comparación, consulte Elegir un formato de tabla abierta para su lago de datos transaccionales en AWS.
En 2023, AWS anunció disponibilidad general para Apache Iceberg, Apache Hudi y Linux Foundation Delta Lake en Amazon Athena para Apache Spark, lo que elimina la necesidad de instalar un conector separado o dependencias asociadas y administrar versiones, y simplifica los pasos de configuración necesarios para usar estos marcos.
En esta publicación, le mostramos cómo usar Spark SQL en Atenea amazónica cuadernos y trabajar con formatos de mesa Iceberg, Hudi y Delta Lake. Demostramos operaciones comunes como la creación de bases de datos y tablas, la inserción de datos en las tablas, la consulta de datos y la visualización de instantáneas de las tablas en Amazon S3 utilizando Spark SQL en Athena.
Requisitos previos
Complete los siguientes requisitos previos:
Descargue e importe cuadernos de ejemplo desde Amazon S3
Para seguir adelante, descargue los cuadernos analizados en esta publicación desde las siguientes ubicaciones:
Después de descargar los cuadernos, impórtelos a su entorno Athena Spark siguiendo las instrucciones Para importar un cuaderno sección en Administrar archivos de cuaderno.
Navegue a la sección específica Formato de tabla abierta
Si está interesado en el formato de tabla Iceberg, navegue hasta Trabajar con tablas Apache Iceberg .
Si está interesado en el formato de tabla Hudi, navegue hasta Trabajar con tablas de Apache Hudi .
Si está interesado en el formato de tabla de Delta Lake, navegue hasta Trabajar con tablas Delta Lake de la base de Linux .
Trabajar con tablas Apache Iceberg
Cuando usa cuadernos Spark en Athena, puede ejecutar consultas SQL directamente sin tener que usar PySpark. Hacemos esto usando magia de celda, que son encabezados especiales en una celda del cuaderno que cambian el comportamiento de la celda. Para SQL, podemos agregar el %%sql magic, que interpretará todo el contenido de la celda como una declaración SQL que se ejecutará en Athena.
En esta sección, mostramos cómo puede usar SQL en Apache Spark para Athena para crear, analizar y administrar tablas de Apache Iceberg.
Configurar una sesión de cuaderno
Para utilizar Apache Iceberg en Athena, mientras crea o edita una sesión, seleccione el iceberg apache opción ampliando el Propiedades de Apache Spark sección. Completará previamente las propiedades como se muestra en la siguiente captura de pantalla.
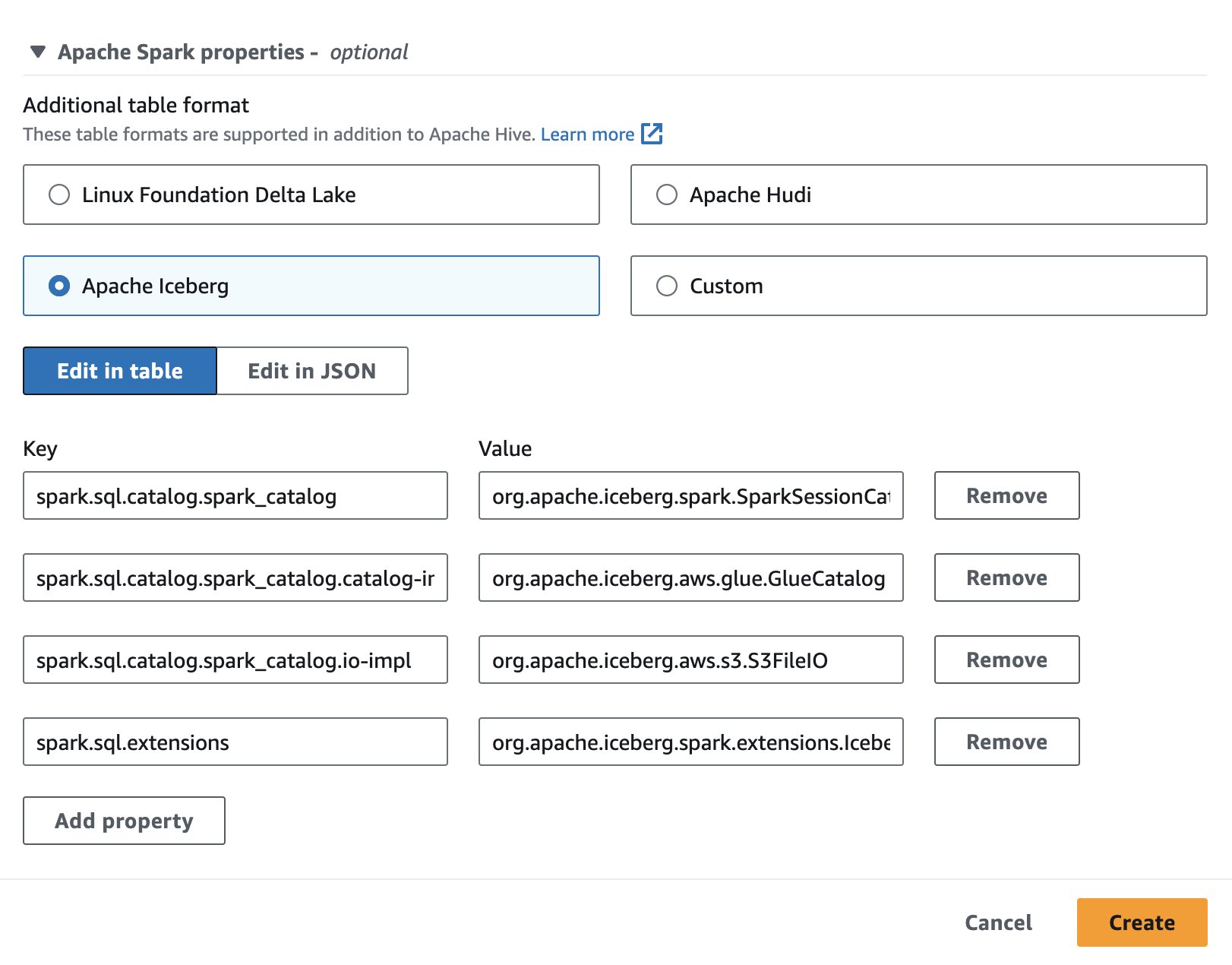
Para conocer los pasos, consulte Editar detalles de la sesión or Creando tu propio cuaderno.
El código utilizado en esta sección está disponible en el SparkSQL_iceberg.ipynb archivo para seguir.
Crear una base de datos y una tabla Iceberg
Primero, creamos una base de datos en el catálogo de datos de AWS Glue. Con el siguiente SQL, podemos crear una base de datos llamada icebergdb:
A continuación, en la base de datos. icebergdb, creamos una tabla Iceberg llamada noaa_iceberg apuntando a una ubicación en Amazon S3 donde cargaremos los datos. Ejecute la siguiente declaración y reemplace la ubicación. s3://<your-S3-bucket>/<prefix>/ con su depósito S3 y prefijo:
Insertar datos en la tabla
Para poblar el noaa_iceberg Tabla Iceberg, insertamos datos de la tabla Parquet sparkblogdb.noaa_pq que se creó como parte de los requisitos previos. Puedes hacer esto usando un Insertar en declaración en Spark:
Alternativamente, puede utilizar CREAR TABLA COMO SELECCIONAR con la cláusula USING iceberg para crear una tabla Iceberg e insertar datos de una tabla fuente en un solo paso:
Consultar la tabla Iceberg
Ahora que los datos están insertados en la tabla Iceberg, podemos comenzar a analizarlos. Ejecutemos un Spark SQL para encontrar la temperatura mínima registrada por año para el 'SEATTLE TACOMA AIRPORT, WA US' ubicación:
Obtenemos el siguiente resultado.

Actualizar datos en la tabla Iceberg
Veamos cómo actualizar los datos en nuestra tabla. Queremos actualizar el nombre de la estación. 'SEATTLE TACOMA AIRPORT, WA US' a 'Sea-Tac'. Usando Spark SQL, podemos ejecutar un ACTUALIZAR Declaración contra la mesa Iceberg:
Luego podemos ejecutar la consulta SELECT anterior para encontrar la temperatura mínima registrada para el 'Sea-Tac' ubicación:
Obtenemos el siguiente resultado.

Archivos de datos compactos
Los formatos de tablas abiertas como Iceberg funcionan creando cambios delta en el almacenamiento de archivos y rastreando las versiones de las filas a través de archivos de manifiesto. Más archivos de datos generan más metadatos almacenados en archivos de manifiesto, y los archivos de datos pequeños a menudo generan una cantidad innecesaria de metadatos, lo que resulta en consultas menos eficientes y mayores costos de acceso a Amazon S3. Ejecutando el Iceberg rewrite_data_files El procedimiento en Spark para Athena compactará archivos de datos, combinando muchos archivos pequeños de cambio delta en un conjunto más pequeño de archivos Parquet optimizados para lectura. La compactación de archivos acelera la operación de lectura cuando se solicita. Para ejecutar la compactación en nuestra tabla, ejecute el siguiente Spark SQL:
rewrite_data_files ofrece opciones para especificar su estrategia de clasificación, que puede ayudar a reorganizar y compactar los datos.
Listar instantáneas de tablas
Cada operación de escritura, actualización, eliminación, inserción y compactación en una tabla Iceberg crea una nueva instantánea de una tabla y al mismo tiempo mantiene los datos y metadatos antiguos para aislar la instantánea y viajar en el tiempo. Para enumerar las instantáneas de una tabla Iceberg, ejecute la siguiente instrucción Spark SQL:
Caducar instantáneas antiguas
Se recomienda que las instantáneas caduquen periódicamente para eliminar archivos de datos que ya no son necesarios y para mantener pequeño el tamaño de los metadatos de la tabla. Nunca eliminará los archivos que aún sean necesarios en una instantánea no caducada. En Spark para Athena, ejecute el siguiente SQL para caducar las instantáneas de la tabla icebergdb.noaa_iceberg que son anteriores a una marca de tiempo específica:
Tenga en cuenta que el valor de la marca de tiempo se especifica como una cadena en formato yyyy-MM-dd HH:mm:ss.fff. El resultado dará un recuento de la cantidad de archivos de datos y metadatos eliminados.
Suelta la tabla y la base de datos.
Puede ejecutar el siguiente Spark SQL para limpiar las tablas Iceberg y los datos asociados en Amazon S3 a partir de este ejercicio:
Ejecute el siguiente Spark SQL para eliminar la base de datos icebergdb:
Para obtener más información sobre todas las operaciones que puede realizar en tablas Iceberg usando Spark para Athena, consulte Consultas chispeantes y Procedimientos de chispa en la documentación de Iceberg.
Trabajar con tablas de Apache Hudi
A continuación, mostramos cómo puede usar SQL en Spark para Athena para crear, analizar y administrar tablas de Apache Hudi.
Configurar una sesión de cuaderno
Para utilizar Apache Hudi en Athena, mientras crea o edita una sesión, seleccione el apache hudi opción ampliando el Propiedades de Apache Spark .
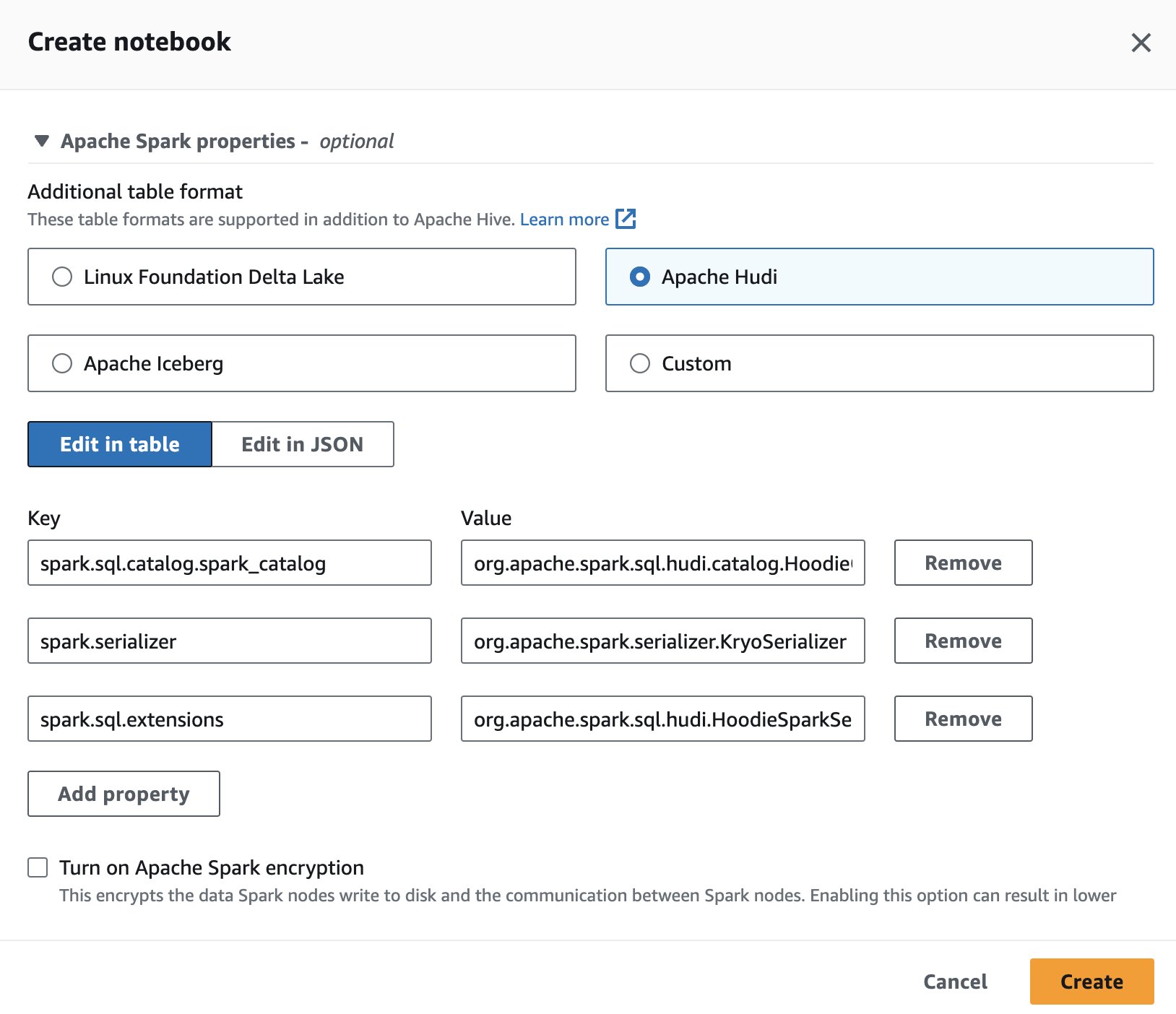
Para conocer los pasos, consulte Editar detalles de la sesión or Creando tu propio cuaderno.
El código utilizado en esta sección debe estar disponible en el SparkSQL_hudi.ipynb archivo para seguir.
Crear una base de datos y una tabla Hudi
Primero, creamos una base de datos llamada hudidb que se almacenará en el catálogo de datos de AWS Glue seguido de la creación de la tabla Hudi:
Creamos una tabla Hudi que apunta a una ubicación en Amazon S3 donde cargaremos los datos. Tenga en cuenta que la tabla es de Copiar en escrito tipo. Se define por type= 'cow' en la tabla DDL. Hemos definido la estación y la fecha como las múltiples claves principales y preCombinedField como el año. Además, la tabla está dividida por año. Ejecute la siguiente declaración y reemplace la ubicación. s3://<your-S3-bucket>/<prefix>/ con su depósito S3 y prefijo:
Insertar datos en la tabla
Al igual que con Iceberg, utilizamos el Insertar en declaración para llenar la tabla leyendo datos del sparkblogdb.noaa_pq tabla creada en el post anterior:
Consultar la tabla Hudi
Ahora que se creó la tabla, ejecutemos una consulta para encontrar la temperatura máxima registrada para el 'SEATTLE TACOMA AIRPORT, WA US' ubicación:
Actualizar datos en la tabla Hudi
Cambiemos el nombre de la estación. 'SEATTLE TACOMA AIRPORT, WA US' a 'Sea–Tac'. Podemos ejecutar una declaración UPDATE en Spark para que Athena actualización los registros de la noaa_hudi mesa:
Ejecutamos la consulta SELECT anterior para encontrar la temperatura máxima registrada para el 'Sea-Tac' ubicación:
Ejecutar consultas de viaje en el tiempo
Podemos utilizar consultas de viaje en el tiempo en SQL en Athena para analizar instantáneas de datos pasados. Por ejemplo:
Esta consulta verifica los datos de temperatura del aeropuerto de Seattle en un momento específico en el pasado. La cláusula de marca de tiempo nos permite viajar hacia atrás sin alterar los datos actuales. Tenga en cuenta que el valor de la marca de tiempo se especifica como una cadena en formato yyyy-MM-dd HH:mm:ss.fff.
Optimice la velocidad de consulta con clustering
Para mejorar el rendimiento de la consulta, puede realizar clustering en tablas Hudi usando SQL en Spark para Athena:
Mesas compactas
La compactación es un servicio de tabla empleado por Hudi específicamente en tablas Merge On Read (MOR) para fusionar actualizaciones de archivos de registro basados en filas en el archivo base correspondiente basado en columnas periódicamente para producir una nueva versión del archivo base. La compactación no se aplica a las tablas Copiar en escritura (COW) y solo se aplica a las tablas MOR. Puede ejecutar la siguiente consulta en Spark para que Athena realice la compactación en tablas MOR:
Suelta la tabla y la base de datos.
Ejecute el siguiente Spark SQL para eliminar la tabla Hudi que creó y los datos asociados de la ubicación de Amazon S3:
Ejecute el siguiente Spark SQL para eliminar la base de datos hudidb:
Para conocer todas las operaciones que puede realizar en tablas Hudi usando Spark para Athena, consulte DDL de SQL y Procedimientos en la documentación de Hudi.
Trabajar con tablas Delta Lake de la base de Linux
A continuación, mostramos cómo puede usar SQL en Spark para Athena para crear, analizar y administrar tablas de Delta Lake.
Configurar una sesión de cuaderno
Para utilizar Delta Lake en Spark para Athena, mientras crea o edita una sesión, seleccione Lago Delta de la Fundación Linux expandiendo el Propiedades de Apache Spark .

Para conocer los pasos, consulte Editar detalles de la sesión or Creando tu propio cuaderno.
El código utilizado en esta sección debe estar disponible en el SparkSQL_delta.ipynb archivo para seguir.
Crear una base de datos y una tabla de Delta Lake
En esta sección, creamos una base de datos en el catálogo de datos de AWS Glue. Usando el siguiente SQL, podemos crear una base de datos llamada deltalakedb:
A continuación, en la base de datos. deltalakedb, creamos una tabla de Delta Lake llamada noaa_delta apuntando a una ubicación en Amazon S3 donde cargaremos los datos. Ejecute la siguiente declaración y reemplace la ubicación. s3://<your-S3-bucket>/<prefix>/ con su depósito S3 y prefijo:
Insertar datos en la tabla
Usamos un Insertar en declaración para llenar la tabla leyendo datos del sparkblogdb.noaa_pq tabla creada en el post anterior:
También puede usar CREATE TABLE AS SELECT para crear una tabla de Delta Lake e insertar datos de una tabla de origen en una consulta.
Consultar la tabla de Delta Lake
Ahora que los datos están insertados en la tabla de Delta Lake, podemos comenzar a analizarlos. Ejecutemos un Spark SQL para encontrar la temperatura mínima registrada para el 'SEATTLE TACOMA AIRPORT, WA US' ubicación:
Actualizar datos en la tabla del lago Delta.
Cambiemos el nombre de la estación. 'SEATTLE TACOMA AIRPORT, WA US' a 'Sea–Tac'. Podemos ejecutar un ACTUALIZAR declaración sobre Spark para que Athena actualice los registros del noaa_delta mesa:
Podemos ejecutar la consulta SELECT anterior para encontrar la temperatura mínima registrada para el 'Sea-Tac' ubicación, y el resultado debería ser el mismo que antes:
Archivos de datos compactos
En Spark para Athena, puede ejecutar OPTIMIZE en la tabla Delta Lake, que compactará los archivos pequeños en archivos más grandes, de modo que las consultas no se vean sobrecargadas por la sobrecarga de los archivos pequeños. Para realizar la operación de compactación, ejecute la siguiente consulta:
Consulte Optimizaciones en la documentación de Delta Lake para conocer las diferentes opciones disponibles al ejecutar OPTIMIZE.
Eliminar archivos a los que ya no hace referencia una tabla de Delta Lake
Puede eliminar archivos almacenados en Amazon S3 a los que ya no hace referencia una tabla de Delta Lake y que son más antiguos que el umbral de retención ejecutando el comando VACCUM en la tabla usando Spark para Athena:
Consulte Eliminar archivos a los que ya no hace referencia una tabla Delta en la documentación de Delta Lake para conocer las opciones disponibles con VACUUM.
Suelta la tabla y la base de datos.
Ejecute el siguiente Spark SQL para eliminar la tabla Delta Lake que creó:
Ejecute el siguiente Spark SQL para eliminar la base de datos deltalakedb:
La ejecución de DROP TABLE DDL en la tabla y la base de datos de Delta Lake elimina los metadatos de estos objetos, pero no elimina automáticamente los archivos de datos en Amazon S3. Puede ejecutar el siguiente código Python en la celda del cuaderno para eliminar los datos de la ubicación S3:
Para obtener más información sobre las declaraciones SQL que puede ejecutar en una tabla de Delta Lake usando Spark para Athena, consulte la Inicio rápido en la documentación de Delta Lake.
Conclusión
Esta publicación demostró cómo usar Spark SQL en cuadernos Athena para crear bases de datos y tablas, insertar y consultar datos y realizar operaciones comunes como actualizaciones, compactaciones y viajes en el tiempo en tablas Hudi, Delta Lake e Iceberg. Los formatos de tablas abiertas agregan transacciones ACID, actualizaciones y eliminaciones a lagos de datos, superando las limitaciones del almacenamiento de objetos sin formato. Al eliminar la necesidad de instalar conectores separados, la integración integrada de Spark en Athena reduce los pasos de configuración y la sobrecarga de administración cuando se utilizan estos marcos populares para crear lagos de datos confiables en Amazon S3. Para obtener más información sobre cómo seleccionar un formato de tabla abierta para sus cargas de trabajo del lago de datos, consulte Elegir un formato de tabla abierta para su lago de datos transaccionales en AWS.
Acerca de los autores
![]() Patik Shah es arquitecto sénior de análisis en Amazon Athena. Se unió a AWS en 2015 y desde entonces se ha centrado en el espacio de análisis de big data, ayudando a los clientes a crear soluciones escalables y sólidas utilizando los servicios de análisis de AWS.
Patik Shah es arquitecto sénior de análisis en Amazon Athena. Se unió a AWS en 2015 y desde entonces se ha centrado en el espacio de análisis de big data, ayudando a los clientes a crear soluciones escalables y sólidas utilizando los servicios de análisis de AWS.
![]() Raj Devnath es gerente de producto en AWS en Amazon Athena. Le apasiona crear productos que los clientes adoren y ayudarlos a extraer valor de sus datos. Su experiencia se centra en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, domótica y sistemas de comunicación de datos.
Raj Devnath es gerente de producto en AWS en Amazon Athena. Le apasiona crear productos que los clientes adoren y ayudarlos a extraer valor de sus datos. Su experiencia se centra en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, domótica y sistemas de comunicación de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

