Los datos geoespaciales son datos sobre ubicaciones específicas de la superficie terrestre. Puede representar un área geográfica en su conjunto o puede representar un evento asociado con un área geográfica. Algunas industrias buscan el análisis de datos geoespaciales. Implica comprender dónde existen los datos desde una perspectiva espacial y por qué existen allí.
Hay dos tipos de datos geoespaciales: datos vectoriales y datos ráster. Los datos ráster son una matriz de celdas representadas como una cuadrícula, que en su mayoría representa fotografías e imágenes de satélite. En esta publicación, nos centramos en los datos vectoriales, que se representan como coordenadas geográficas de latitud y longitud, así como líneas y polígonos (áreas) que los conectan o abarcan. Los datos vectoriales tienen multitud de casos de uso para obtener información sobre movilidad. Los datos móviles del usuario son uno de esos componentes y se derivan principalmente de la posición geográfica de los dispositivos móviles que utilizan GPS o de los editores de aplicaciones que utilizan SDK o integraciones similares. A los efectos de esta publicación, nos referimos a estos datos como datos de movilidad.
Esta es una serie de dos partes. En este primer post presentamos los datos de movilidad, sus fuentes y un esquema típico de estos datos. Luego, analizamos los diversos casos de uso y exploramos cómo puede utilizar los servicios de AWS para limpiar los datos, cómo el aprendizaje automático (ML) puede ayudar en este esfuerzo y cómo puede hacer un uso ético de los datos para generar imágenes e información. La segunda publicación será de naturaleza más técnica y cubrirá estos pasos en detalle junto con un código de muestra. Esta publicación no tiene un conjunto de datos de muestra ni un código de muestra, sino que cubre cómo usar los datos después de comprarlos en un agregador de datos.
Puedes usar Capacidades geoespaciales de Amazon SageMaker para superponer datos de movilidad en un mapa base y proporcionar visualización en capas para facilitar la colaboración. El visualizador interactivo con tecnología de GPU y los cuadernos de Python brindan una manera perfecta de explorar millones de puntos de datos en una sola ventana y compartir conocimientos y resultados.
Fuentes y esquema
Hay pocas fuentes de datos de movilidad. Además de los pings de GPS y los editores de aplicaciones, se utilizan otras fuentes para aumentar el conjunto de datos, como puntos de acceso Wi-Fi, datos de flujo de ofertas obtenidos mediante la publicación de anuncios en dispositivos móviles y transmisores de hardware específicos colocados por empresas (por ejemplo, en tiendas físicas). ). A menudo resulta difícil para las empresas recopilar estos datos por sí mismas, por lo que pueden adquirirlos a través de agregadores de datos. Los agregadores de datos recopilan datos de movilidad de diversas fuentes, los limpian, agregan ruido y ponen los datos a disposición diariamente para regiones geográficas específicas. Debido a la naturaleza de los datos en sí y a que son difíciles de obtener, la precisión y la calidad de estos datos pueden variar considerablemente, y depende de las empresas evaluarlos y verificarlos mediante el uso de métricas como usuarios activos diarios, pings diarios totales, y promedio de pings diarios por dispositivo. La siguiente tabla muestra cómo podría verse un esquema típico de una fuente de datos diaria enviada por agregadores de datos.
| Atributo | Descripción |
| Identificación o criada | ID de publicidad móvil (MAID) del dispositivo (hash) |
| lat | Latitud del dispositivo |
| GNL | Longitud del dispositivo |
| geohash | Ubicación Geohash del dispositivo |
| tipo de dispositivo | Sistema operativo del dispositivo = IDFA o GAID |
| precisión_horizontal | Precisión de las coordenadas GPS horizontales (en metros) |
| fecha y hora | Marca de tiempo del evento |
| ip | Dirección IP |
| alt | Altitud del dispositivo (en metros) |
| velocidad | Velocidad del dispositivo (en metros/segundo) |
| país | Código ISO de dos dígitos para el país de origen |
| estado | Códigos que representan el estado |
| ciudad | Códigos que representan la ciudad |
| código postal | Código postal donde se ve el ID del dispositivo |
| portador | Portador del dispositivo |
| fabricante_dispositivo | Fabricante del dispositivo |
Use cases
Los datos de movilidad tienen aplicaciones generalizadas en diversas industrias. Los siguientes son algunos de los casos de uso más comunes:
- Métricas de densidad – El análisis del tráfico peatonal se puede combinar con la densidad de población para observar actividades y visitas a puntos de interés (PDI). Estas métricas presentan una imagen de cuántos dispositivos o usuarios están deteniendo e interactuando activamente con una empresa, que puede usarse aún más para seleccionar el sitio o incluso analizar patrones de movimiento alrededor de un evento (por ejemplo, personas que viajan para un día de juego). Para obtener dicha información, los datos sin procesar entrantes pasan por un proceso de extracción, transformación y carga (ETL) para identificar actividades o compromisos a partir del flujo continuo de pings de ubicación del dispositivo. Podemos analizar las actividades identificando las paradas realizadas por el usuario o el dispositivo móvil agrupando pings utilizando modelos ML en Amazon SageMaker.
- Viajes y trayectorias – La información de ubicación diaria de un dispositivo se puede expresar como una colección de actividades (paradas) y viajes (movimiento). Un par de actividades pueden representar un viaje entre ellas, y rastrear el viaje realizado por el dispositivo en movimiento en el espacio geográfico puede conducir a mapear la trayectoria real. Los patrones de trayectoria de los movimientos de los usuarios pueden generar información interesante, como patrones de tráfico, consumo de combustible, planificación urbana y más. También puede proporcionar datos para analizar la ruta tomada desde puntos publicitarios como una valla publicitaria, identificar las rutas de entrega más eficientes para optimizar las operaciones de la cadena de suministro o analizar rutas de evacuación en desastres naturales (por ejemplo, evacuación por huracanes).
- Análisis de la zona de captación - Un zona de captación Se refiere a los lugares desde donde un área determinada atrae a sus visitantes, que pueden ser clientes o clientes potenciales. Las empresas minoristas pueden utilizar esta información para determinar la ubicación óptima para abrir una nueva tienda, o determinar si dos ubicaciones de tiendas están demasiado cerca una de la otra con áreas de captación superpuestas y están obstaculizando el negocio de la otra. También pueden averiguar de dónde provienen los clientes reales, identificar clientes potenciales que pasan por el área viajando al trabajo o a casa, analizar métricas de visitas similares para los competidores y más. Las empresas de tecnología de marketing (MarTech) y tecnología de publicidad (AdTech) también pueden utilizar este análisis para optimizar las campañas de marketing identificando la audiencia cercana a la tienda de una marca o clasificando las tiendas por rendimiento para la publicidad exterior.
Hay varios otros casos de uso, incluida la generación de inteligencia de ubicación para bienes raíces comerciales, el aumento de datos de imágenes satelitales con números de afluencia, la identificación de centros de entrega para restaurantes, la determinación de la probabilidad de evacuación de vecindarios, el descubrimiento de patrones de movimiento de personas durante una pandemia y más.
Retos y uso ético
El uso ético de los datos de movilidad puede generar muchos conocimientos interesantes que pueden ayudar a las organizaciones a mejorar sus operaciones, realizar un marketing eficaz o incluso lograr una ventaja competitiva. Para utilizar estos datos de forma ética, se deben seguir varios pasos.
Comienza con la recopilación de datos en sí. Aunque la mayoría de los datos de movilidad permanecen libres de información de identificación personal (PII), como nombre y dirección, los recolectores y agregadores de datos deben tener el consentimiento del usuario para recopilar, usar, almacenar y compartir sus datos. Es necesario cumplir con las leyes de privacidad de datos como GDPR y CCPA porque permiten a los usuarios determinar cómo las empresas pueden usar sus datos. Este primer paso es un avance sustancial hacia el uso ético y responsable de los datos de movilidad, pero se puede hacer más.
A cada dispositivo se le asigna un ID de publicidad móvil (MAID) con hash, que se utiliza para anclar los pings individuales. Esto se puede ofuscar aún más mediante el uso Amazonas Macie, Objeto Lambda de Amazon S3, Amazon Comprehend, o incluso el Estudio de pegamento de AWS Detectar transformación PII. Para obtener más información, consulte Técnicas comunes para detectar datos PHI y PII utilizando los servicios de AWS.
Además de la PII, se debe considerar enmascarar la ubicación del hogar del usuario, así como otros lugares sensibles como bases militares o lugares de culto.
El último paso para un uso ético es derivar y exportar únicamente métricas agregadas de Amazon SageMaker. Esto significa obtener métricas como el número promedio o el número total de visitantes en lugar de patrones de viaje individuales; obtener tendencias diarias, semanales, mensuales o anuales; o indexar patrones de movilidad sobre datos disponibles públicamente, como los datos del censo.
Resumen de la solución
Como se mencionó anteriormente, los servicios de AWS que puede utilizar para el análisis de datos de movilidad son las capacidades geoespaciales de Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend y Amazon SageMaker. Las capacidades geoespaciales de Amazon SageMaker facilitan a los científicos de datos y a los ingenieros de aprendizaje automático la creación, el entrenamiento y la implementación de modelos utilizando datos geoespaciales. Puede transformar o enriquecer de manera eficiente conjuntos de datos geoespaciales a gran escala, acelerar la creación de modelos con modelos de aprendizaje automático previamente entrenados y explorar predicciones de modelos y datos geoespaciales en un mapa interactivo utilizando gráficos acelerados en 3D y herramientas de visualización integradas.
La siguiente arquitectura de referencia muestra un flujo de trabajo que utiliza ML con datos geoespaciales.
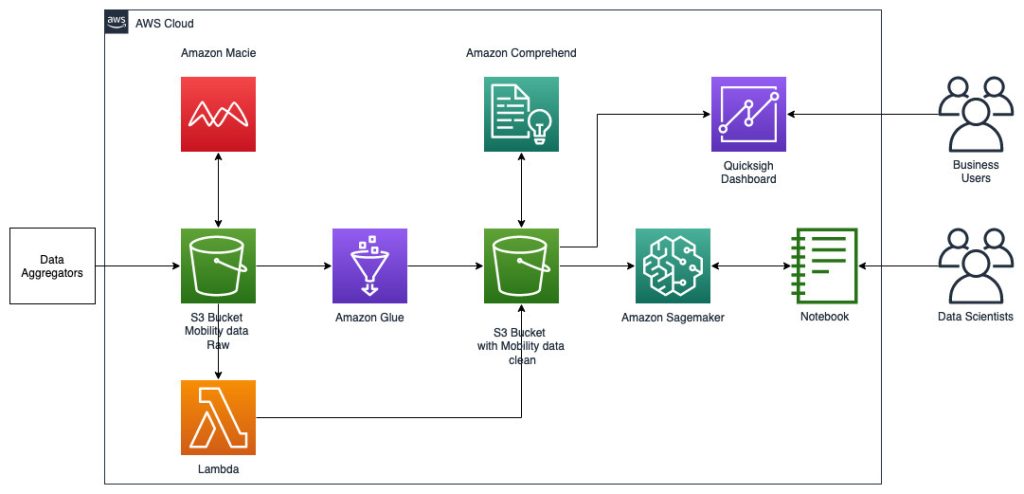
En este flujo de trabajo, los datos sin procesar se agregan de varias fuentes de datos y se almacenan en un Servicio de almacenamiento simple de Amazon (S3) cubo. Amazon Macie se utiliza en este depósito de S3 para identificar y redactar PII. Luego se utiliza AWS Glue para limpiar y transformar los datos sin procesar al formato requerido, luego los datos modificados y limpios se almacenan en un depósito S3 separado. Para aquellas transformaciones de datos que no son posibles a través de AWS Glue, utilice AWS Lambda para modificar y limpiar los datos sin procesar. Cuando se limpian los datos, puede utilizar Amazon SageMaker para crear, entrenar e implementar modelos de aprendizaje automático en los datos geoespaciales preparados. También puedes utilizar el Empleos de procesamiento geoespacial característica de las capacidades geoespaciales de Amazon SageMaker para preprocesar los datos, por ejemplo, utilizando una función de Python y declaraciones SQL para identificar actividades a partir de los datos de movilidad sin procesar. Los científicos de datos pueden realizar este proceso conectándose a través de cuadernos de Amazon SageMaker. También puedes usar Amazon QuickSight para visualizar resultados comerciales y otras métricas importantes a partir de los datos.
Capacidades geoespaciales de Amazon SageMaker y trabajos de procesamiento geoespacial
Una vez que los datos se obtienen y se introducen en Amazon S3 con una alimentación diaria y se limpian para detectar datos confidenciales, se pueden importar a Amazon SageMaker mediante un Estudio Amazon SageMaker cuaderno con una imagen geoespacial. La siguiente captura de pantalla muestra una muestra de pings diarios de dispositivos cargados en Amazon S3 como un archivo CSV y luego cargados en un marco de datos de pandas. El cuaderno de imágenes geoespaciales de Amazon SageMaker Studio viene precargado con bibliotecas geoespaciales como GDAL, GeoPandas, Fiona y Shapely, y facilita el procesamiento y análisis de estos datos.
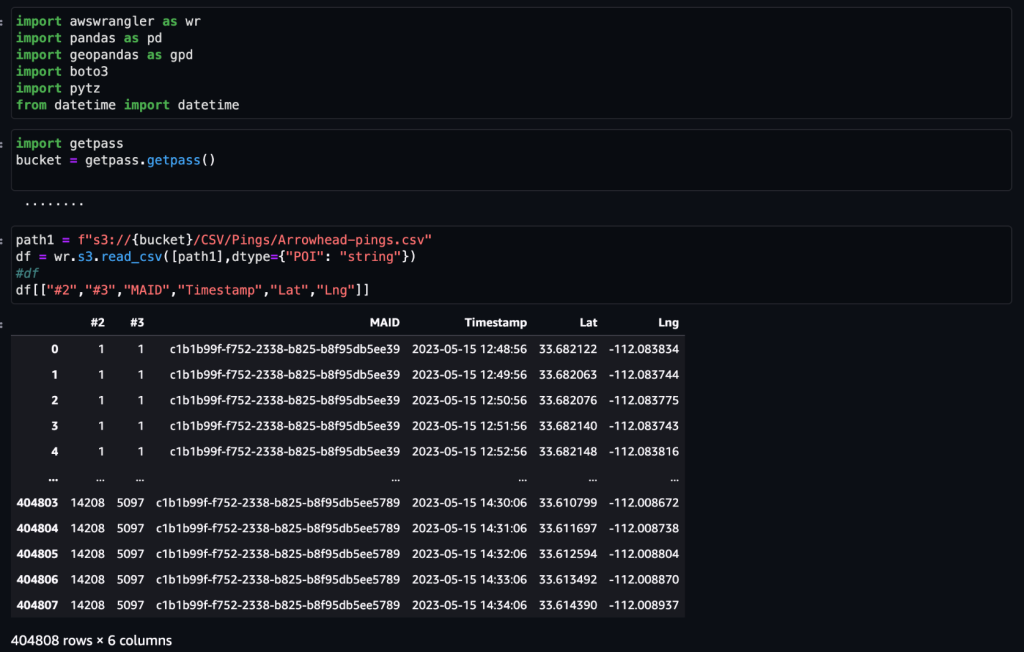
Este conjunto de datos de muestra contiene aproximadamente 400,000 5,000 pings diarios de 14,000 dispositivos de 15 2023 lugares únicos registrados por usuarios que visitaron Arrowhead Mall, un popular complejo de centros comerciales en Phoenix, Arizona, el XNUMX de mayo de XNUMX. La captura de pantalla anterior muestra un subconjunto de columnas en el esquema de datos. El MAID La columna representa la ID del dispositivo y cada MAID genera pings cada minuto que transmiten la latitud y longitud del dispositivo, registrados en el archivo de muestra como Lat y Lng columnas
Las siguientes son capturas de pantalla de la herramienta de visualización de mapas de las capacidades geoespaciales de Amazon SageMaker impulsadas por Foursquare Studio, que muestran el diseño de los pings de los dispositivos que visitan el centro comercial entre las 7:00 a. m. y las 6:00 p. m.
La siguiente captura de pantalla muestra pings del centro comercial y sus alrededores.

A continuación se muestran pings desde el interior de varias tiendas del centro comercial.
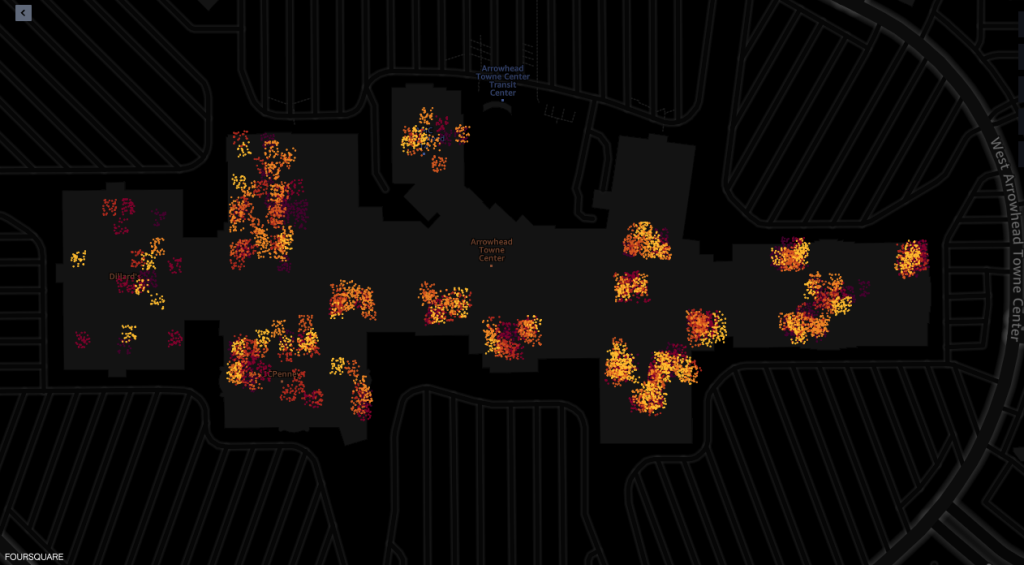
Cada punto en las capturas de pantalla representa un ping desde un dispositivo determinado en un momento determinado. Un grupo de pings representa lugares populares donde los dispositivos se reunieron o se detuvieron, como tiendas o restaurantes.
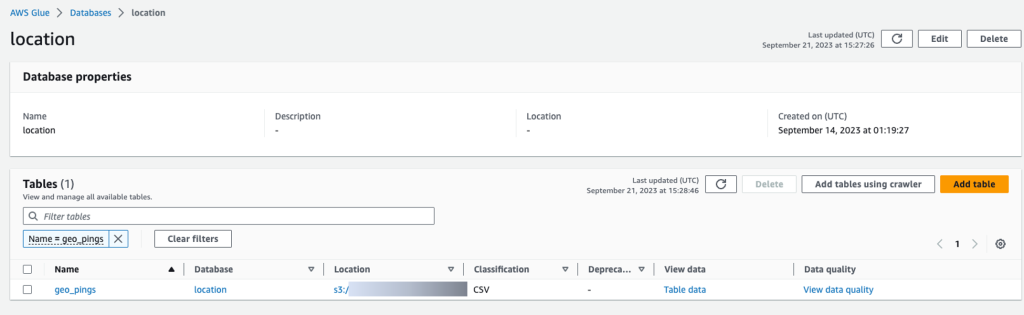
Como parte del ETL inicial, estos datos sin procesar se pueden cargar en tablas mediante AWS Glue. Puede crear un rastreador de AWS Glue para identificar el esquema de los datos y las tablas de formularios apuntando a la ubicación de los datos sin procesar en Amazon S3 como origen de datos.

Como se mencionó anteriormente, los datos sin procesar (los pings diarios del dispositivo), incluso después del ETL inicial, representarán un flujo continuo de pings de GPS que indican las ubicaciones del dispositivo. Para extraer información útil a partir de estos datos, necesitamos identificar paradas y viajes (trayectorias). Esto se puede lograr utilizando el Empleos de procesamiento geoespacial Característica de las capacidades geoespaciales de SageMaker. Procesamiento de Amazon SageMaker utiliza una experiencia administrada y simplificada en SageMaker para ejecutar cargas de trabajo de procesamiento de datos con el contenedor geoespacial diseñado específicamente. SageMaker administra completamente la infraestructura subyacente para un trabajo de procesamiento de SageMaker. Esta característica permite que se ejecute código personalizado en datos geoespaciales almacenados en Amazon S3 ejecutando un contenedor de aprendizaje automático geoespacial en un trabajo de procesamiento de SageMaker. Puede ejecutar operaciones personalizadas en datos geoespaciales abiertos o privados escribiendo código personalizado con bibliotecas de código abierto y ejecutar la operación a escala utilizando trabajos de procesamiento de SageMaker. El enfoque basado en contenedores resuelve las necesidades relacionadas con la estandarización del entorno de desarrollo con bibliotecas de código abierto de uso común.
Para ejecutar cargas de trabajo de tan gran escala, necesita un clúster de computación flexible que pueda escalar desde decenas de instancias para procesar una manzana de una ciudad hasta miles de instancias para el procesamiento a escala planetaria. La gestión manual de un clúster informático de bricolaje es lenta y costosa. Esta característica es particularmente útil cuando el conjunto de datos de movilidad involucra más de unas pocas ciudades en varios estados o incluso países y se puede utilizar para ejecutar un enfoque de aprendizaje automático de dos pasos.
El primer paso es utilizar el algoritmo de agrupación espacial de aplicaciones con ruido (DBSCAN) basado en la densidad para agrupar las paradas de los pings. El siguiente paso es utilizar el método de máquinas de vectores de soporte (SVM) para mejorar aún más la precisión de las paradas identificadas y también para distinguir las paradas con interacciones con un PDI de las paradas sin uno (como en casa o en el trabajo). También puede utilizar el trabajo de procesamiento de SageMaker para generar viajes y trayectorias a partir de los pings diarios del dispositivo identificando paradas consecutivas y mapeando la ruta entre las paradas de origen y de destino.
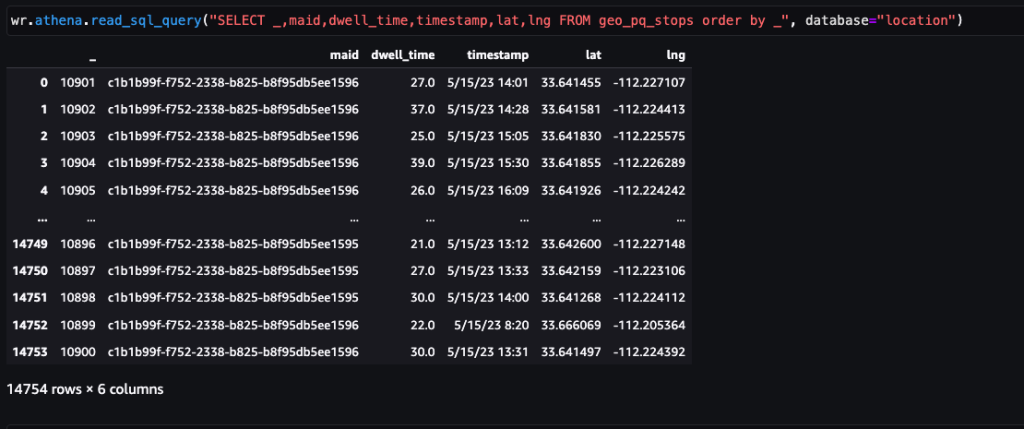
Después de procesar los datos sin procesar (pings diarios del dispositivo) a escala con trabajos de procesamiento geoespacial, el nuevo conjunto de datos llamado paradas debe tener el siguiente esquema.
| Atributo | Descripción |
| Identificación o criada | ID de publicidad móvil del dispositivo (con hash) |
| lat | Latitud del centroide del grupo de paradas |
| GNL | Longitud del centroide del grupo de paradas |
| geohash | Ubicación Geohash del PDI |
| tipo de dispositivo | Sistema operativo del dispositivo (IDFA o GAID) |
| fecha y hora | Hora de inicio de la parada |
| tiempo de permanencia | Tiempo de permanencia de la parada (en segundos) |
| ip | Dirección IP |
| alt | Altitud del dispositivo (en metros) |
| país | Código ISO de dos dígitos para el país de origen |
| estado | Códigos que representan el estado |
| ciudad | Códigos que representan la ciudad |
| código postal | Código postal donde se ve el ID del dispositivo |
| portador | Portador del dispositivo |
| fabricante_dispositivo | Fabricante del dispositivo |
Las paradas se consolidan agrupando los pings por dispositivo. La agrupación basada en la densidad se combina con parámetros como que el umbral de parada sea de 300 segundos y la distancia mínima entre paradas sea de 50 metros. Estos parámetros se pueden ajustar según su caso de uso.
La siguiente captura de pantalla muestra aproximadamente 15,000 400,000 paradas identificadas a partir de XNUMX XNUMX pings. También está presente un subconjunto del esquema anterior, donde la columna Dwell Time representa la duración de la parada, y el Lat y Lng Las columnas representan la latitud y longitud de los centroides del grupo de paradas por dispositivo por ubicación.
Después de ETL, los datos se almacenan en formato de archivo Parquet, que es un formato de almacenamiento en columnas que facilita el procesamiento de grandes cantidades de datos.
La siguiente captura de pantalla muestra las paradas consolidadas a partir de pings por dispositivo dentro del centro comercial y sus alrededores.

Después de identificar las paradas, este conjunto de datos se puede combinar con datos de puntos de interés disponibles públicamente o datos de puntos de interés personalizados específicos del caso de uso para identificar actividades, como la interacción con las marcas.
La siguiente captura de pantalla muestra las paradas identificadas en los principales puntos de interés (tiendas y marcas) dentro del Arrowhead Mall.
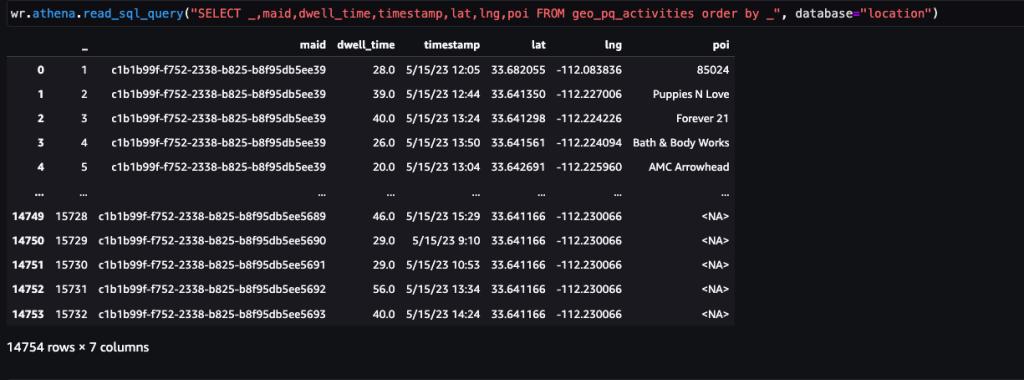
Los códigos postales de las casas se han utilizado para enmascarar la ubicación de casa de cada visitante para mantener la privacidad en caso de que sea parte de su viaje en el conjunto de datos. La latitud y la longitud en tales casos son las coordenadas respectivas del centroide del código postal.
La siguiente captura de pantalla es una representación visual de dichas actividades. La imagen de la izquierda muestra las paradas de las tiendas y la imagen de la derecha da una idea del diseño del centro comercial.

Este conjunto de datos resultante se puede visualizar de varias maneras, que analizamos en las siguientes secciones.
Métricas de densidad
Podemos calcular y visualizar la densidad de actividades y visitas.
ejemplo 1 – La siguiente captura de pantalla muestra las 15 tiendas más visitadas del centro comercial.

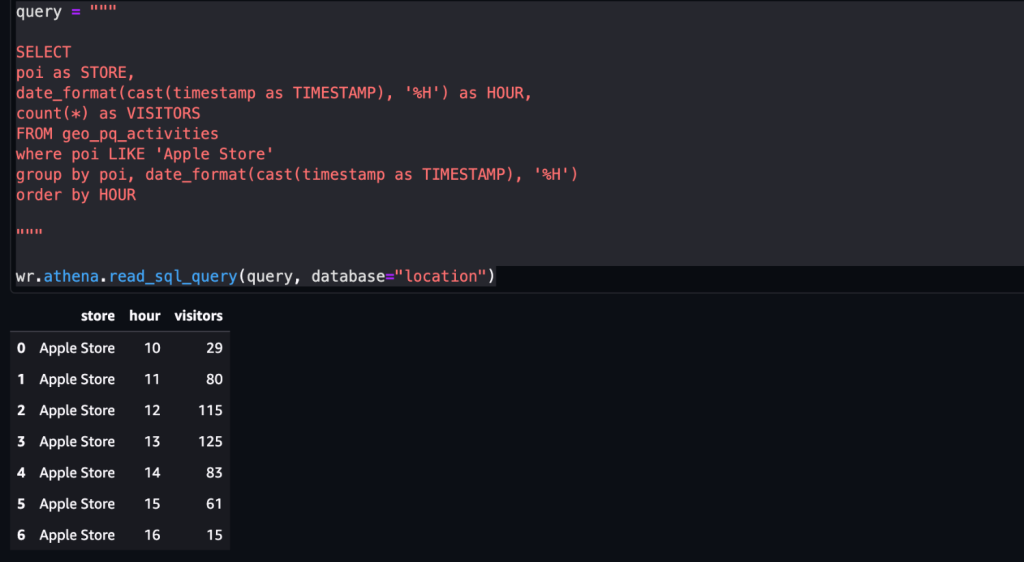
ejemplo 2 – La siguiente captura de pantalla muestra el número de visitas a la Apple Store por cada hora.
Viajes y trayectorias
Como se mencionó anteriormente, un par de actividades consecutivas representan un viaje. Podemos utilizar el siguiente enfoque para derivar viajes a partir de los datos de actividades. Aquí, las funciones de ventana se utilizan con SQL para generar el trips tabla, como se muestra en la captura de pantalla.
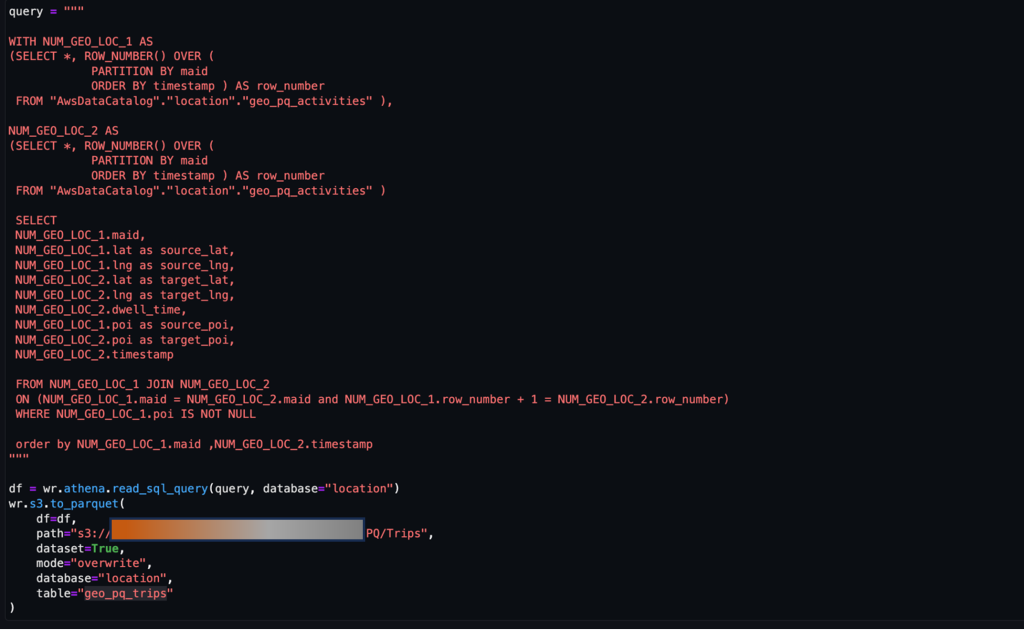
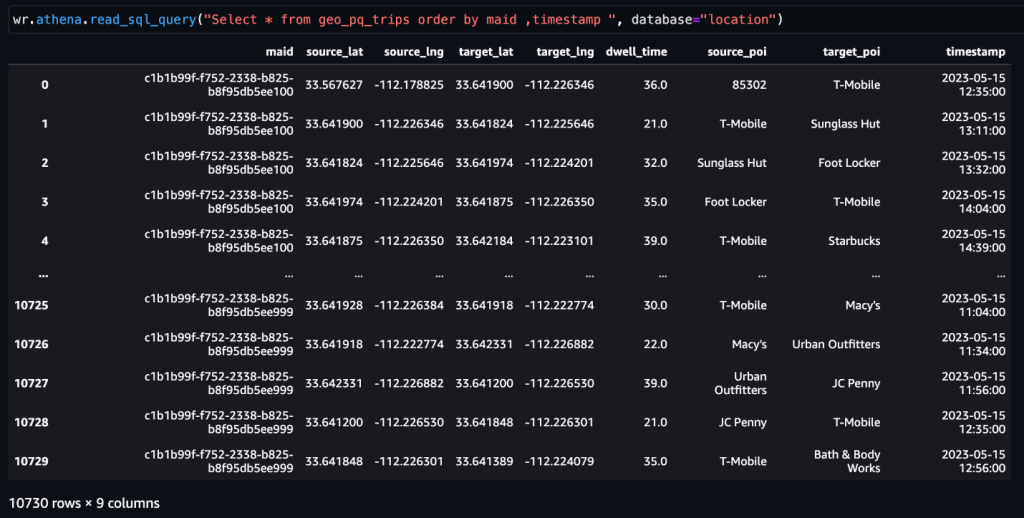
Una vez que el trips Cuando se genera la tabla, se pueden determinar los viajes a un PDI.
Ejemplo 1 - La siguiente captura de pantalla muestra las 10 tiendas principales que dirigen el tráfico peatonal hacia la Apple Store.

ejemplo 2 – La siguiente captura de pantalla muestra todos los viajes al Arrowhead Mall.

ejemplo 3 – El siguiente vídeo muestra los patrones de movimiento dentro del centro comercial.

ejemplo 4 – El siguiente vídeo muestra los patrones de movimiento fuera del centro comercial.
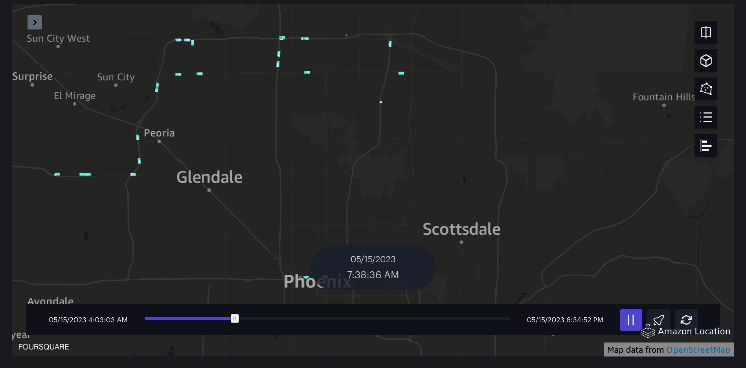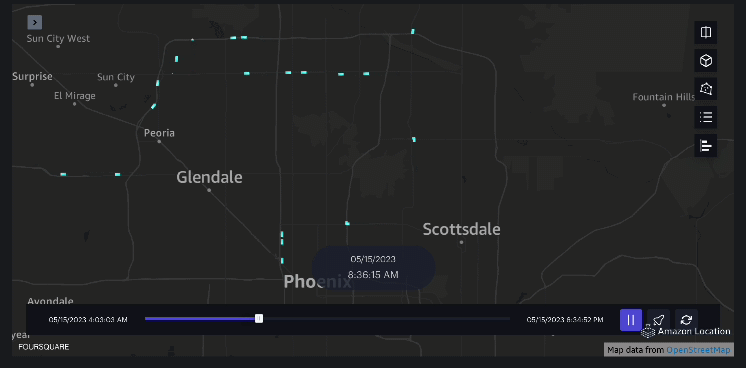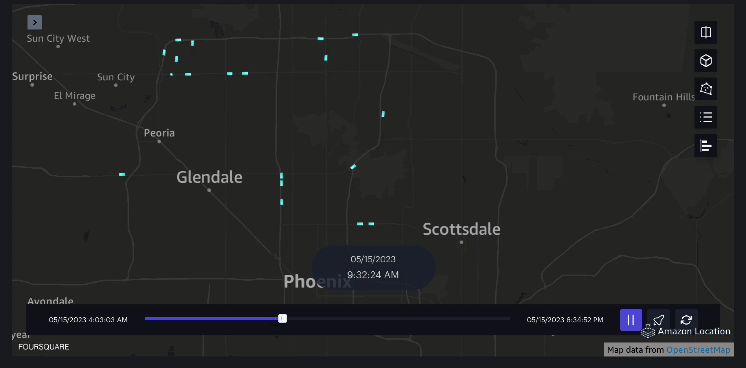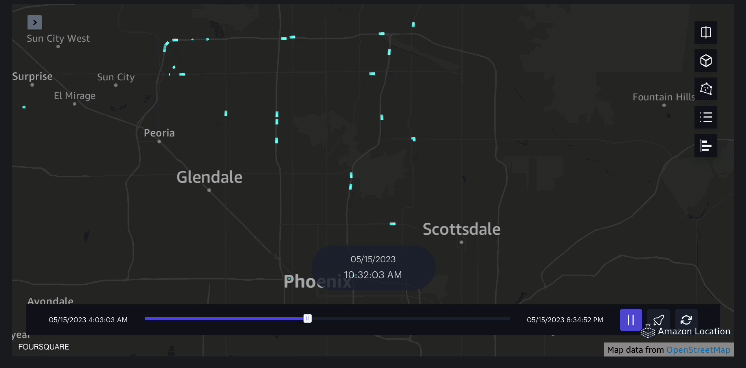
Análisis de la zona de captación
Podemos analizar todas las visitas a un PDI y determinar la zona de influencia.
Ejemplo 1 - La siguiente captura de pantalla muestra todas las visitas a la tienda Macy's.
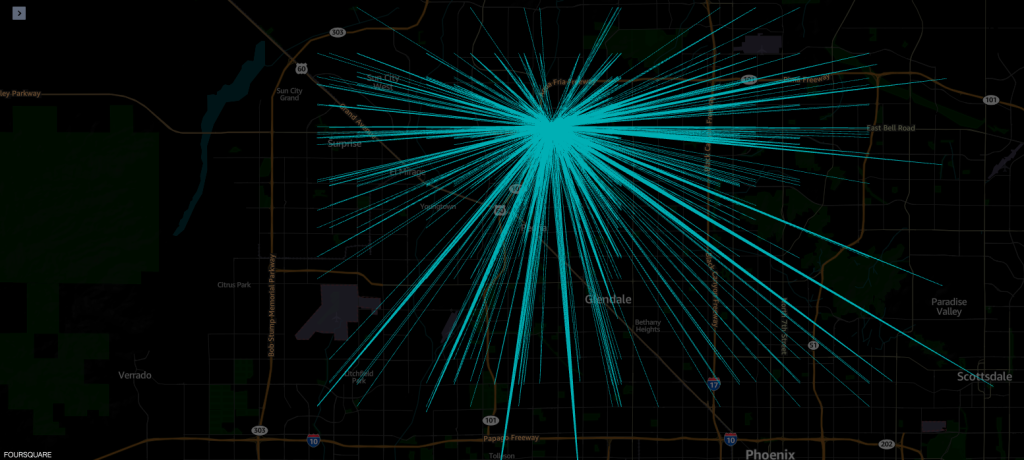
ejemplo 2 – La siguiente captura de pantalla muestra los 10 códigos postales principales del área de origen (límites resaltados) desde donde se produjeron las visitas.
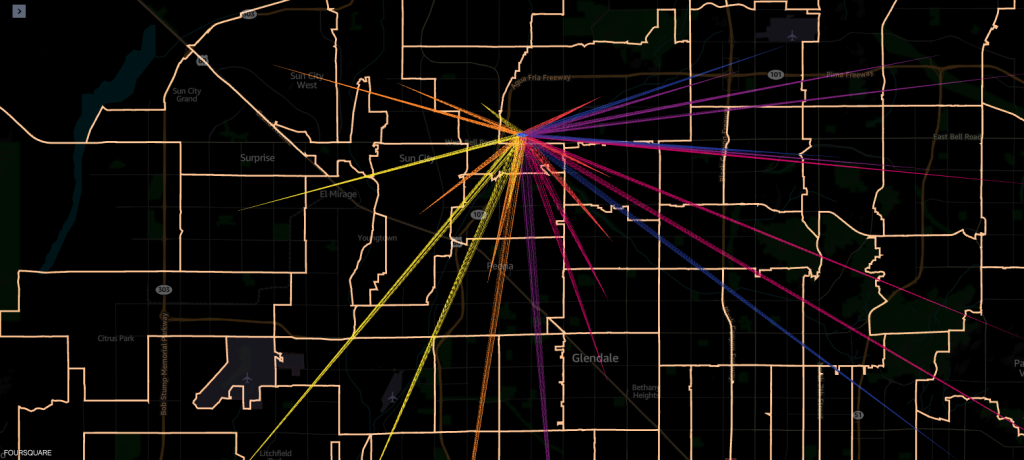
Verificación de la calidad de los datos
Podemos comprobar la calidad de los datos entrantes diarios y detectar anomalías utilizando los paneles y análisis de datos de QuickSight. La siguiente captura de pantalla muestra un panel de ejemplo.
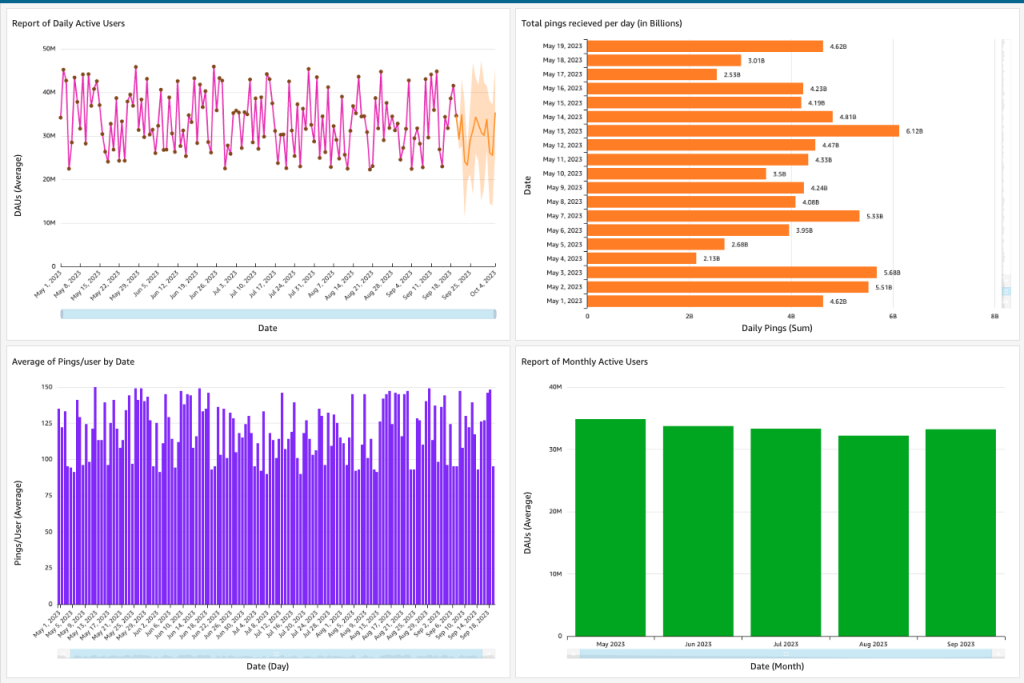
Conclusión
Los datos de movilidad y su análisis para obtener información sobre los clientes y obtener una ventaja competitiva siguen siendo un área de nicho porque es difícil obtener un conjunto de datos consistente y preciso. Sin embargo, estos datos pueden ayudar a las organizaciones a agregar contexto a los análisis existentes e incluso producir nuevos conocimientos sobre los patrones de movimiento de los clientes. Las capacidades geoespaciales y los trabajos de procesamiento geoespacial de Amazon SageMaker pueden ayudar a implementar estos casos de uso y obtener información de una manera intuitiva y accesible.
En esta publicación, demostramos cómo usar los servicios de AWS para limpiar los datos de movilidad y luego usar las capacidades geoespaciales de Amazon SageMaker para generar conjuntos de datos derivados, como paradas, actividades y viajes, utilizando modelos de aprendizaje automático. Luego utilizamos los conjuntos de datos derivados para visualizar patrones de movimiento y generar información.
Puede comenzar a utilizar las capacidades geoespaciales de Amazon SageMaker de dos maneras:
Para obtener más información, visite Capacidades geoespaciales de Amazon SageMaker y Introducción al geoespacial de Amazon SageMaker. Además, visite nuestro Repositorio GitHub, que tiene varios cuadernos de ejemplo sobre las capacidades geoespaciales de Amazon SageMaker.
Acerca de los autores
 Jimy Mateos es un arquitecto de soluciones de AWS, con experiencia en tecnología AI/ML. Jimy tiene su sede en Boston y trabaja con clientes empresariales mientras transforman sus negocios mediante la adopción de la nube y les ayuda a crear soluciones eficientes y sostenibles. Es un apasionado de su familia, los autos y las artes marciales mixtas.
Jimy Mateos es un arquitecto de soluciones de AWS, con experiencia en tecnología AI/ML. Jimy tiene su sede en Boston y trabaja con clientes empresariales mientras transforman sus negocios mediante la adopción de la nube y les ayuda a crear soluciones eficientes y sostenibles. Es un apasionado de su familia, los autos y las artes marciales mixtas.
 Girish Keshav es arquitecto de soluciones en AWS y ayuda a los clientes en su viaje de migración a la nube para modernizar y ejecutar cargas de trabajo de forma segura y eficiente. Trabaja con líderes de equipos de tecnología para orientarlos sobre seguridad de aplicaciones, aprendizaje automático, optimización de costos y sostenibilidad. Vive en San Francisco y le encanta viajar, hacer senderismo, ver deportes y explorar cervecerías artesanales.
Girish Keshav es arquitecto de soluciones en AWS y ayuda a los clientes en su viaje de migración a la nube para modernizar y ejecutar cargas de trabajo de forma segura y eficiente. Trabaja con líderes de equipos de tecnología para orientarlos sobre seguridad de aplicaciones, aprendizaje automático, optimización de costos y sostenibilidad. Vive en San Francisco y le encanta viajar, hacer senderismo, ver deportes y explorar cervecerías artesanales.
 Embarcadero de Ramesh es un líder sénior de arquitectura de soluciones centrado en ayudar a los clientes empresariales de AWS a monetizar sus activos de datos. Asesora a ejecutivos e ingenieros para diseñar y construir soluciones en la nube altamente escalables, confiables y rentables, especialmente enfocadas en aprendizaje automático, datos y análisis. En su tiempo libre disfruta del aire libre, andar en bicicleta y hacer caminatas con su familia.
Embarcadero de Ramesh es un líder sénior de arquitectura de soluciones centrado en ayudar a los clientes empresariales de AWS a monetizar sus activos de datos. Asesora a ejecutivos e ingenieros para diseñar y construir soluciones en la nube altamente escalables, confiables y rentables, especialmente enfocadas en aprendizaje automático, datos y análisis. En su tiempo libre disfruta del aire libre, andar en bicicleta y hacer caminatas con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/

