Pegamento AWS es un servicio de integración de datos sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones.
Los clientes de AWS Glue a menudo tienen que cumplir estrictos requisitos de seguridad, que a veces implican bloquear la conectividad de red permitida para el trabajo o ejecutar dentro de una VPC específica para acceder a otro servicio. Para ejecutarse dentro de la VPC, los trabajos deben asignarse a una única subred, pero la subred más adecuada puede cambiar con el tiempo (por ejemplo, según el uso y la disponibilidad), por lo que es posible que prefiera tomar esa decisión en tiempo de ejecución, según en tu propia estrategia.
Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA) es un servicio de AWS para ejecutar flujos de trabajo de Airflow administrados, que permiten escribir lógica personalizada para coordinar cómo se ejecutan tareas como los trabajos de AWS Glue.
En esta publicación, mostramos cómo ejecutar un trabajo de AWS Glue como parte de un flujo de trabajo de Airflow, con una selección dinámica configurable de la subred de VPC asignada al trabajo en tiempo de ejecución.
Resumen de la solución
Para ejecutarse dentro de una VPC, a un trabajo de AWS Glue se le debe asignar al menos una conexión que incluya la configuración de red. Cualquier conexión permite especificar una VPC, una subred y un grupo de seguridad, pero para simplificar, esta publicación utiliza conexiones de tipo: RED, que solo define la configuración de la red y no involucra sistemas externos.
Si el trabajo tiene una subred fija asignada por una sola conexión, en caso de una interrupción del servicio en el Zonas de disponibilidad o si la subred no está disponible por otros motivos, el trabajo no se puede ejecutar. Además, cada nodo (conductor o trabajador) en un trabajo de AWS Glue requiere una dirección IP asignada desde la subred. Cuando se ejecutan muchos trabajos grandes al mismo tiempo, esto podría provocar una escasez de direcciones IP y que el trabajo se ejecute con menos nodos de los previstos o no se ejecute en absoluto.
Los trabajos de extracción, transformación y carga (ETL) de AWS Glue permiten especificar múltiples conexiones con múltiples configuraciones de red. Sin embargo, el trabajo siempre intentará utilizar la configuración de red de las conexiones en el orden indicado y elegirá la primera que pase el controles de salud y tiene al menos dos direcciones IP para comenzar el trabajo, lo que podría no ser la opción óptima.
Con esta solución, puede mejorar y personalizar ese comportamiento reordenando las conexiones dinámicamente y definiendo la prioridad de selección. Si es necesario volver a intentarlo, las conexiones se vuelven a priorizar según la estrategia, porque las condiciones podrían haber cambiado desde la última ejecución.
Como resultado, ayuda a evitar que el trabajo no se ejecute o se ejecute por debajo de su capacidad debido a la escasez de direcciones IP de subred o incluso a una interrupción, al mismo tiempo que se cumplen los requisitos de conectividad y seguridad de la red.
El siguiente diagrama ilustra la arquitectura de la solución.

Requisitos previos
Para seguir los pasos de la publicación, necesita un usuario que pueda iniciar sesión en Consola de administración de AWS y tiene permiso para acceder a Amazon MWAA, Nube privada virtual de Amazon (Amazon VPC) y AWS Glue. La región de AWS donde elija implementar la solución necesita la capacidad de crear una VPC y dos direcciones IP elásticas. La cuota regional predeterminada para ambos tipos de recursos es cinco, por lo que es posible que tengas que solicitar un aumento a través de la consola.
También necesitas un Gestión de identidades y accesos de AWS (IAM) rol adecuado para ejecutar trabajos de AWS Glue si aún no tiene uno. Para obtener instrucciones, consulte Cree un rol de IAM para AWS Glue.
Implementar un entorno Airflow y VPC
Primero, implementará un nuevo entorno Airflow, incluida la creación de una nueva VPC con dos subredes públicas y dos privadas. Esto se debe a que Amazon MWAA requiere tolerancia a fallas en la zona de disponibilidad, por lo que debe ejecutarse en dos subredes en dos zonas de disponibilidad diferentes en la región. Las subredes públicas se utilizan para que NAT Gateway pueda proporcionar acceso a Internet para las subredes privadas.
Complete los siguientes pasos:
- Crear una Formación en la nube de AWS plantilla en su computadora copiando la plantilla de la siguiente guía de inicio rápido en un archivo de texto local.
- En la consola de AWS CloudFormation, elija Stacks en el panel de navegación.
- Elige Crear pila con la opción Con nuevos recursos (estándar).
- Elige Subir un archivo de plantilla y elija el archivo de plantilla local.
- Elige Siguiente.
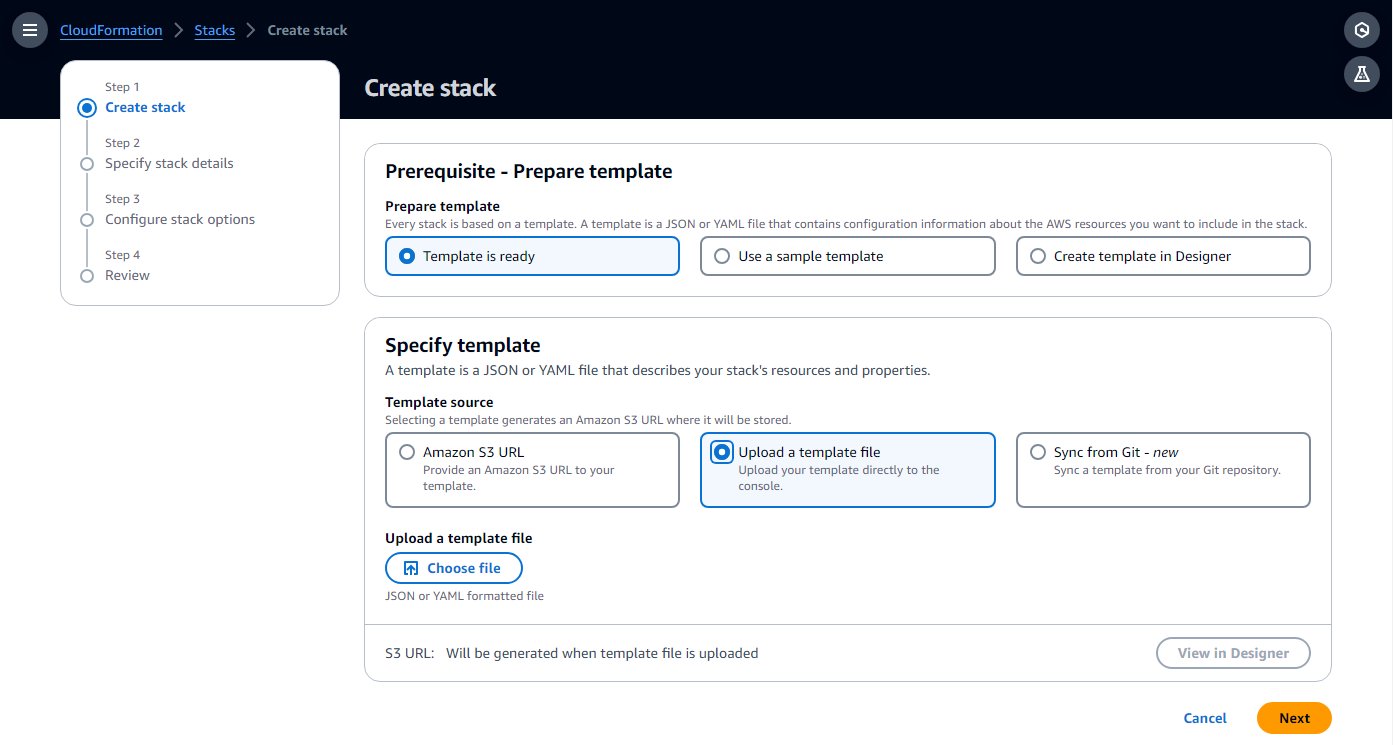
- Complete los pasos de configuración, ingrese un nombre para el entorno y deje el resto de los parámetros como predeterminados.
- En el último paso, reconozca que se crearán recursos y elija Enviar.
La creación puede tardar entre 20 y 30 minutos, hasta que el estado de la pila cambie a CREATE_COMPLETE.
El recurso que consumirá la mayor parte del tiempo es el entorno Airflow. Mientras se crea, puede continuar con los siguientes pasos, hasta que se le solicite abrir la interfaz de usuario de Airflow.
- en la pila Recursos , tenga en cuenta los ID de la VPC y las dos subredes privadas (
PrivateSubnet1yPrivateSubnet2), para utilizar en el siguiente paso.
Crear conexiones de AWS Glue
La plantilla de CloudFormation implementa dos subredes privadas. En este paso, creará una conexión de AWS Glue para cada uno de ellos para que los trabajos de AWS Glue puedan ejecutarse en ellos. Amazon MWAA agregó recientemente la capacidad de ejecutar el clúster Airflow en VPC compartidas, lo que reduce los costos y simplifica la administración de la red. Para obtener más información, consulte Presentamos la compatibilidad con VPC compartida en Amazon MWAA.
Complete los siguientes pasos para crear las conexiones:
- En la consola de AWS Glue, elija Conexiones de datos en el panel de navegación.
- Elige Crear conexión.
- Elige Nuestra red como fuente de datos.
- Elija la VPC y la subred privada (
PrivateSubnet1) creado por la pila de CloudFormation. - Utilice el grupo de seguridad predeterminado.
- Elige Siguiente.
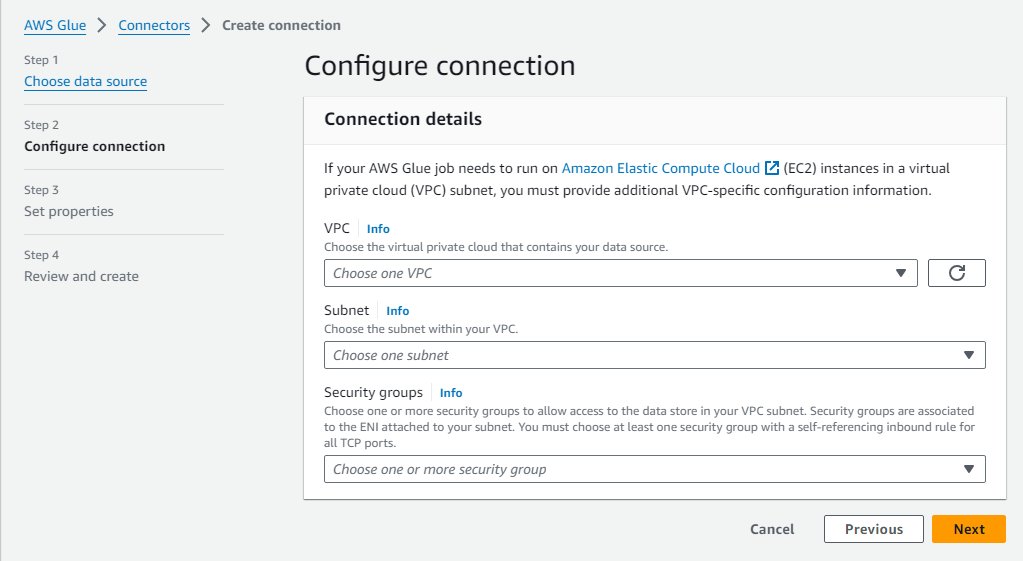
- Para el nombre de la conexión, ingrese
MWAA-Glue-Blog-Subnet1. - Revisa los detalles y completa la creación.
- Repita estos pasos usando
PrivateSubnet2y nombra la conexiónMWAA-Glue-Blog-Subnet2.
Crear el trabajo de AWS Glue
Ahora crea el trabajo de AWS Glue que el flujo de trabajo de Airflow activará más adelante. El trabajo utiliza las conexiones creadas en la sección anterior, pero en lugar de asignarlas directamente en el trabajo, como lo haría normalmente, en este escenario deja vacía la lista de conexiones del trabajo y deja que el flujo de trabajo decida cuál usar en tiempo de ejecución.
El script del trabajo en este caso no es significativo y solo pretende demostrar que el trabajo se ejecutó en una de las subredes, según la conexión.
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación, luego elija Editor de scripts.
- Deje las opciones predeterminadas (motor Spark y Empezar de nuevo) y elige Crear guion.
- Reemplace el script de marcador de posición con el siguiente código Python:
- Cambie el nombre del trabajo a
AirflowBlogJob. - En Detalles del trabajo pestaña, para Rol de IAM, elija cualquier rol e ingrese 2 para el número de trabajadores (solo por frugalidad).
- Guarde estos cambios para que se cree el trabajo.
Conceder permisos de AWS Glue al rol del entorno Airflow
El rol creado para Airflow por la plantilla de CloudFormation proporciona los permisos básicos para ejecutar flujos de trabajo pero no para interactuar con otros servicios como AWS Glue. En un proyecto de producción, definiría sus propias plantillas con estos permisos adicionales, pero en esta publicación, para simplificar, agregará los permisos adicionales como una política en línea. Complete los siguientes pasos:
- En la consola de IAM, elija Roles en el panel de navegación.
- Localice el rol creado por la plantilla; comenzará con el nombre que asignó a la pila de CloudFormation y luego
-MwaaExecutionRole-. - En la página de detalles del rol, en el Agregar permisos menú, seleccione Crear política en línea.
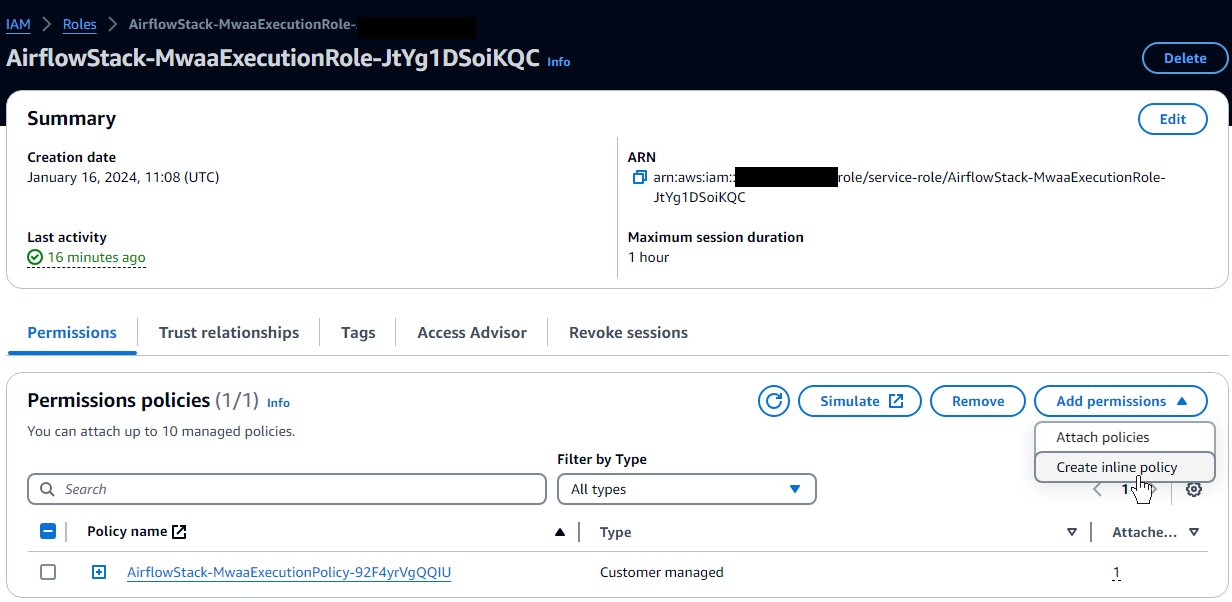
- Cambie del modo Visual al modo JSON e ingrese el siguiente JSON en el cuadro de texto. Se supone que el rol de AWS Glue que tiene sigue la convención de comenzar con
AWSGlueServiceRole. Para mayor seguridad, puede reemplazar el recurso comodín en elec2:DescribeSubnetspermiso con los ARN de las dos subredes privadas de la pila de CloudFormation. - Elige Siguiente.
- Participar
GlueRelatedPermissionscomo nombre de la política y complete la creación.
En este ejemplo, utilizamos un trabajo de script ETL; para un trabajo visual, debido a que genera el script automáticamente al guardar, la función Airflow necesitaría permiso para escribir en la ruta del script configurada en Servicio de almacenamiento simple de Amazon (Amazon S3).
Crear el DAG de flujo de aire
Un flujo de trabajo de Airflow se basa en un gráfico acíclico dirigido (DAG), que se define mediante un archivo Python que especifica mediante programación las diferentes tareas involucradas y sus interdependencias. Complete los siguientes scripts para crear el DAG:
- Cree un archivo local llamado
glue_job_dag.pyutilizando un editor de texto.
En cada uno de los siguientes pasos, proporcionamos un fragmento de código para ingresar al archivo y una explicación de lo que hace.
- El siguiente fragmento agrega las importaciones de módulos Python requeridas. Los módulos ya están instalados en Airflow; Si ese no fuera el caso, necesitarías usar un
requirements.txtarchivo para indicar a Airflow qué módulos instalar. También define los clientes Boto3 que el código utilizará más adelante. De forma predeterminada, usarán el mismo rol y región que Airflow, es por eso que configuraste antes el rol con los permisos adicionales requeridos. - El siguiente fragmento agrega tres funciones para implementar la estrategia de orden de conexión, que define cómo reordenar las conexiones dadas para establecer su prioridad. Este es sólo un ejemplo; puede crear su código personalizado para implementar su propia lógica, según sus necesidades. El código primero verifica las IP disponibles en cada subred de conexión y separa las que tienen suficientes IP disponibles para ejecutar el trabajo a plena capacidad y las que podrían usarse porque tienen al menos dos IP disponibles, que es el mínimo que necesita un trabajo. comenzar. Si la estrategia se fija en
random, aleatorizará el orden dentro de cada uno de los grupos de conexiones descritos anteriormente y agregará cualquier otra conexión. Si la estrategia escapacity, las ordenará desde la mayoría de las IP gratuitas hasta la menor. - El siguiente código crea el DAG con la tarea de ejecución de trabajo, que actualiza el trabajo con el orden de conexión definido por la estrategia, lo ejecuta y espera los resultados. El nombre del trabajo, las conexiones y la estrategia provienen de variables de Airflow, por lo que se pueden configurar y actualizar fácilmente. Tiene configurados dos reintentos con retroceso exponencial, por lo que si la tarea falla, repetirá la tarea completa incluida la selección de conexión. Quizás ahora la mejor opción sea otra conexión, o la subred previamente elegida al azar está en una zona de disponibilidad que actualmente está sufriendo una interrupción y, al elegir una diferente, puede recuperarse.
Crear el flujo de trabajo de flujo de aire
Ahora crea un flujo de trabajo que invoca el trabajo de AWS Glue que acaba de crear:
- En la consola de Amazon S3, ubique el depósito creado por la plantilla de CloudFormation, que tendrá un nombre que comenzará con el nombre de la pila y luego
-environmentbucket-(por ejemplo,myairflowstack-environmentbucket-ap1qks3nvvr4). - Dentro de ese depósito, cree una carpeta llamada
dags, y dentro de esa carpeta, sube el archivo DAGglue_job_dag.pyque creaste en la sección anterior. - En la consola de Amazon MWAA, navegue hasta el entorno que implementó con la pila de CloudFormation.
Si el estado aún no es Disponible, espere hasta que llegue a ese estado. No deberían pasar más de 30 minutos desde que implementó la pila de CloudFormation.
- Elija el enlace del entorno en la tabla para ver los detalles del entorno.
Está configurado para recoger DAG del depósito y la carpeta que utilizó en los pasos anteriores. Airflow monitoreará esa carpeta en busca de cambios.
- Elige Abrir la interfaz de usuario de flujo de aire para abrir una nueva pestaña accediendo a la interfaz de usuario de Airflow, utilizando la seguridad IAM integrada para iniciar sesión.
Si hay algún problema con el archivo DAG que creó, mostrará un error en la parte superior de la página indicando las líneas afectadas. En ese caso, revisa los pasos y vuelve a subir. Después de unos segundos, lo analizará y actualizará o eliminará el mensaje de error.
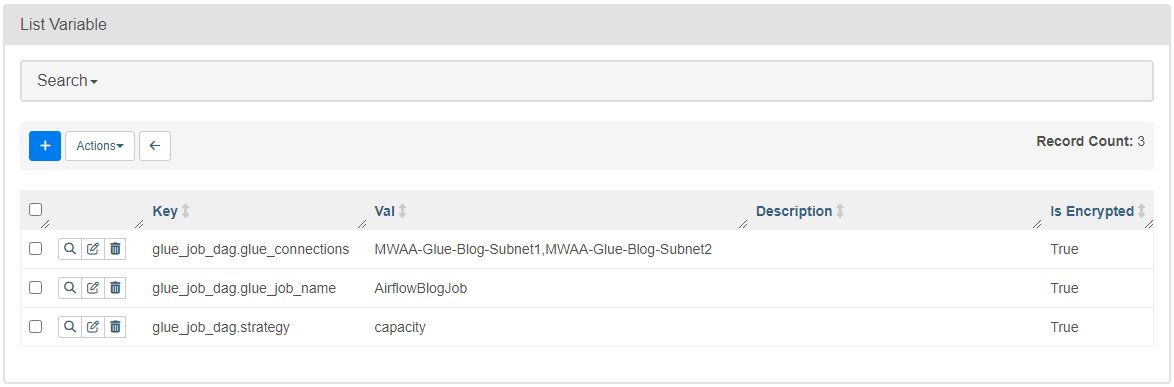
- En Administración menú, seleccione Variables.
- Agregue tres variables con las siguientes claves y valores:
- Clave
glue_job_dag.glue_connectionscon valorMWAA-Glue-Blog-Subnet1,MWAA-Glue-Blog-Subnet2. - Clave
glue_job_dag.glue_job_namecon valorAirflowBlogJob. - Clave
glue_job_dag.strategycon valorcapacity.
- Clave
Ejecute el trabajo con una asignación de subred dinámica
Ahora está listo para ejecutar el flujo de trabajo y ver la estrategia reordenando dinámicamente las conexiones.
- En la IU de Airflow, elige DAG, y en la fila
glue_job_dag, elige el ícono de reproducir. - En Explorar menú, seleccione Instancias de tareas.
- En la tabla de instancias, desplácese hacia la derecha para mostrar la
Log Urly elija el ícono para abrir el registro.
El registro se actualizará a medida que se ejecute la tarea; puede ubicar la línea que comienza con “Ejecutando trabajo de Glue con el orden de conexión:” y las líneas anteriores que muestran detalles de las IP de conexión y la categoría asignada. Si se produce un error, verá los detalles en este registro.
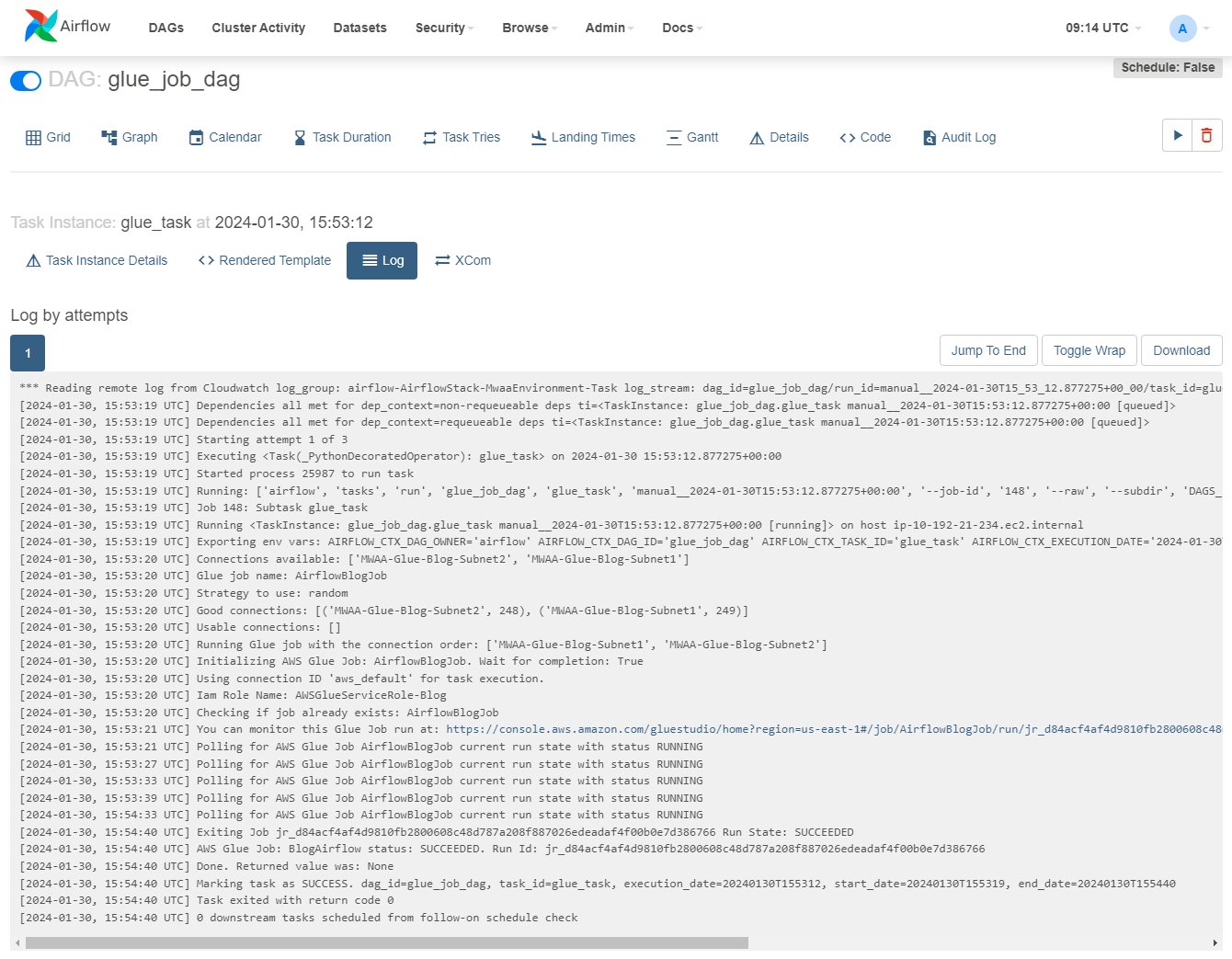
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación, luego elija el trabajo
AirflowBlogJob. - En Ron pestaña, elija la instancia de ejecución, luego el Registros de salida enlace, que abrirá una nueva pestaña.
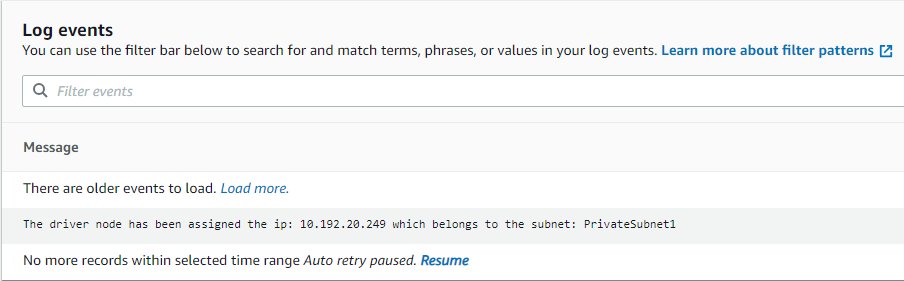
- En la nueva pestaña, use el enlace de flujo de registro para abrirla.
Mostrará la IP que se le asignó al controlador y a qué subred pertenece, la cual debe coincidir con la conexión indicada por Airflow (si no se muestra el registro, elija Currículum para que se actualice tan pronto como esté disponible).
- En la interfaz de usuario de Airflow, edite la variable Airflow
glue_job_dag.strategypara ponerlo enrandom. - Ejecute el DAG varias veces y vea cómo cambia el orden.
Limpiar
Si ya no necesita la implementación, elimine los recursos para evitar cargos adicionales:
- Elimine el script de Python que cargó, para que el depósito de S3 se pueda eliminar automáticamente en el siguiente paso.
- Elimina la pila de CloudFormation.
- Elimine el trabajo de AWS Glue.
- Elimine el script que guardó el trabajo en Amazon S3.
- Elimina las conexiones que creaste como parte de esta publicación.
Conclusión
En esta publicación, mostramos cómo AWS Glue y Amazon MWAA pueden trabajar juntos para crear flujos de trabajo personalizados más avanzados y, al mismo tiempo, minimizar la sobrecarga operativa y de administración. Esta solución le brinda más control sobre cómo se ejecuta su trabajo de AWS Glue para cumplir con requisitos operativos, de red o de seguridad especiales.
Puede implementar su propio entorno Amazon MWAA de varias maneras, como con el plantilla utilizado en esta publicación, en la consola de Amazon MWAA o usando el CLI de AWS. También puede implementar sus propias estrategias para organizar trabajos de AWS Glue, según la arquitectura y los requisitos de su red (por ejemplo, ejecutar el trabajo más cerca de los datos cuando sea posible).
Sobre los autores
 Michael Greenstein es un Arquitecto de Soluciones Especialista en Analítica para el Sector Público.
Michael Greenstein es un Arquitecto de Soluciones Especialista en Analítica para el Sector Público.
 gonzalo herreros es Arquitecto Senior de Big Data en el equipo de AWS Glue.
gonzalo herreros es Arquitecto Senior de Big Data en el equipo de AWS Glue.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/combine-aws-glue-and-amazon-mwaa-to-build-advanced-vpc-selection-and-failover-strategies/

