Introducción
En el acelerado mundo actual de la entrega de alimentos locales, garantizar la satisfacción del cliente es clave para las empresas. Grandes actores como Zomato y Swiggy dominan esta industria. Los clientes esperan comida fresca; si reciben artículos estropeados, agradecen un reembolso o un vale de descuento. Sin embargo, determinar manualmente la frescura de los alimentos resulta engorroso para los clientes y el personal de la empresa. Una solución es automatizar este proceso utilizando modelos de aprendizaje profundo. Estos modelos pueden predecir la frescura de los alimentos, lo que permite que los empleados revisen solo las quejas marcadas para su validación final. Si el modelo confirma la frescura de los alimentos, puede desestimar automáticamente la queja. En este artículo construiremos un detector de calidad de los alimentos mediante aprendizaje profundo.
El aprendizaje profundo, un subconjunto de la inteligencia artificial, ofrece una utilidad significativa en este contexto. Específicamente, se pueden emplear CNN (redes neuronales convolucionales) para entrenar modelos utilizando imágenes de alimentos para discernir su frescura. La precisión de nuestro modelo depende completamente de la calidad del conjunto de datos. Idealmente, incorporar imágenes de comida reales a partir de las quejas de los chatbots de los usuarios en aplicaciones de entrega de alimentos hiperlocales mejoraría enormemente la precisión. Sin embargo, al carecer de acceso a dichos datos, confiamos en un conjunto de datos ampliamente utilizado conocido como "conjunto de datos de clasificación fresca y podrida", accesible en Kaggle. Para explorar el código completo de aprendizaje profundo, simplemente haga clic en el botón "Copiar y editar" proporcionado esta página.
OBJETIVOS DE APRENDIZAJE
- Conozca la importancia de la calidad de los alimentos en la satisfacción del cliente y el crecimiento empresarial.
- Descubra cómo el aprendizaje profundo ayuda a construir el detector de calidad de los alimentos.
- Adquiera experiencia práctica a través de una implementación paso a paso de este modelo.
- Comprender los desafíos y soluciones involucradas en su implementación.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Comprender el uso del aprendizaje profundo en el detector de calidad de los alimentos
Aprendizaje profundo, un subconjunto de Inteligencia artificial , emplea principalmente conjuntos de datos espaciales para construir modelos. Las redes neuronales dentro del aprendizaje profundo se utilizan para entrenar estos modelos, imitando la funcionalidad del cerebro humano.
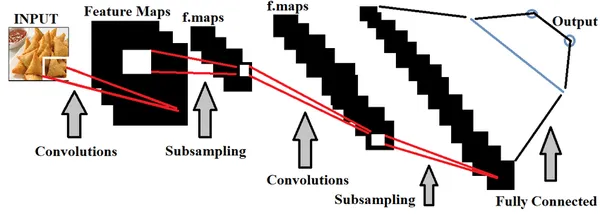
En el contexto de la detección de la calidad de los alimentos, entrenar modelos de aprendizaje profundo con conjuntos extensos de imágenes de alimentos es esencial para distinguir con precisión entre alimentos de buena y mala calidad. Podemos hacer ajuste de hiperparámetros en base a los datos que se están alimentando, con el fin de hacer el modelo más preciso.
Importancia de la calidad de los alimentos en la entrega hiperlocal
La integración de esta función en la entrega de alimentos hiperlocal ofrece varios beneficios. El modelo evita sesgos hacia clientes específicos y predice con precisión, reduciendo así el tiempo de resolución de quejas. Además, podemos emplear esta función durante el proceso de empaque del pedido para inspeccionar la calidad de los alimentos antes de la entrega, garantizando que los clientes reciban alimentos frescos de manera constante.

Desarrollo de un detector de calidad de los alimentos
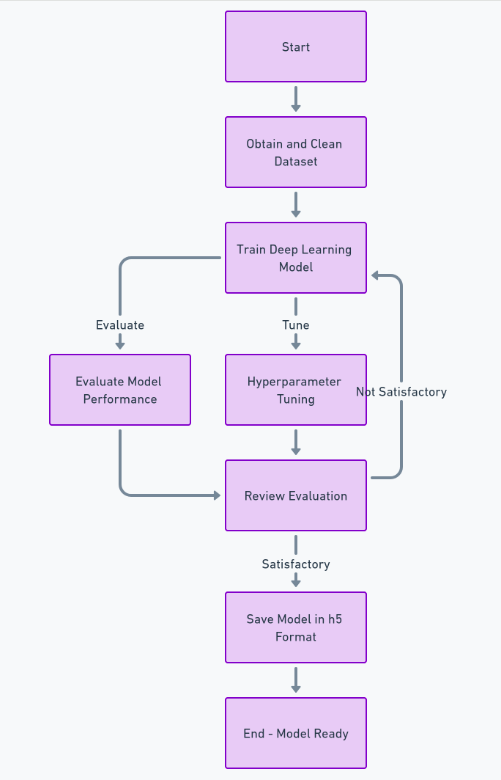
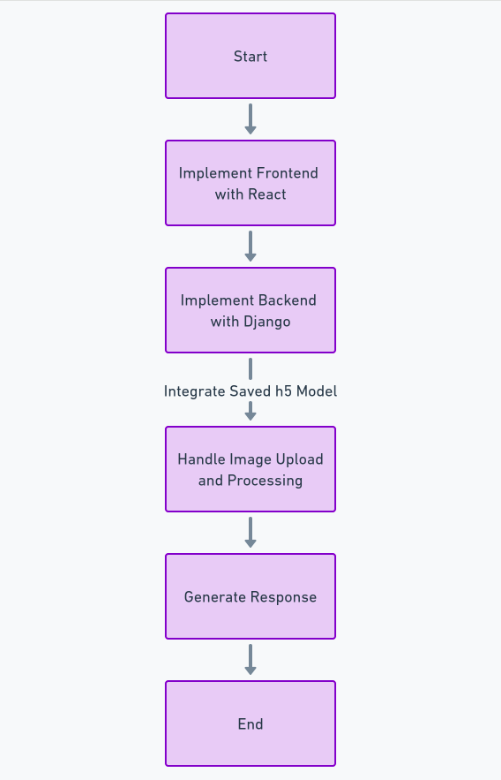
Para crear completamente esta función, debemos seguir muchos pasos, como obtener y limpiar el conjunto de datos, entrenar el modelo de aprendizaje profundo, evaluar el rendimiento y realizar ajustes de hiperparámetros y, finalmente, guardar el modelo en h5 formato. Después de esto, podemos implementar la interfaz usando Reaccionary el backend usando el marco de Python Django Usaremos Django para manejar la carga de imágenes y procesarla.
Acerca del conjunto de datos
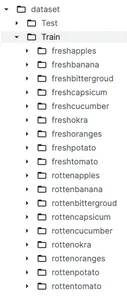
Antes de profundizar en el preprocesamiento de datos y la construcción de modelos, es fundamental comprender el conjunto de datos. Como se discutió anteriormente, usaremos un conjunto de datos de Kaggle llamado Clasificación de alimentos frescos y podridos. Este conjunto de datos se divide en dos categorías principales denominadas Entrenar y Probar que se utilizan con fines de formación y pruebas, respectivamente. Debajo de la carpeta del tren, tenemos 9 subcarpetas de frutas y verduras frescas y 9 subcarpetas de frutas y verduras podridas.
Características clave del conjunto de datos
- Variedad de imágenes: Este conjunto de datos contiene muchas imágenes de alimentos con mucha variación en términos de ángulo, fondo y condiciones de iluminación. Esto ayuda a que el modelo no esté sesgado y sea más preciso.
- Imágenes de alta calidad: Este conjunto de datos tiene imágenes de muy buena calidad capturadas por varias cámaras profesionales.
Carga y preparación de datos
En esta sección, primero cargaremos las imágenes usando 'tensorflow.keras.preprocesamiento.imagen.cargar_img'Funciona y visualiza las imágenes usando la biblioteca matplotlib. El preprocesamiento de estas imágenes para el entrenamiento de modelos es realmente importante. Esto implica limpiar y organizar las imágenes para que sean adecuadas para el modelo.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)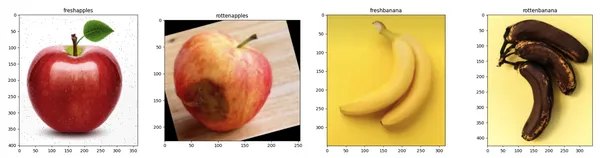
Ahora carguemos las imágenes de entrenamiento y prueba en variables. Cambiaremos el tamaño de todas las imágenes al mismo alto y ancho de 180.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
Construcción del modelo
Ahora construyamos el modelo de aprendizaje profundo utilizando el algoritmo secuencial de 'tensorflow.keras'. Agregaremos 3 capas de convolución y un optimizador Adam. Antes de detenernos en la parte práctica, primero comprendamos cuáles son los términos 'Modelo secuencial','Adam optimizador'y'Capa de convolución' significar.
Modelo secuencial
El modelo secuencial comprende una pila de capas, ofreciendo una estructura fundamental en Keras. Es ideal para escenarios en los que su red neuronal presenta un tensor de entrada único y un tensor de salida único. Agrega capas en el orden secuencial de ejecución, lo que lo hace adecuado para construir modelos sencillos con capas apiladas. Esta simplicidad hace que el modelo secuencial sea muy útil y más fácil de implementar.
Adam optimizador
La abreviatura de Adam es "Estimación del momento adaptativo". Sirve como un algoritmo de optimización alternativo al descenso de gradiente estocástico, actualizando los pesos de la red de forma iterativa. Adam Optimizer es beneficioso ya que mantiene una tasa de aprendizaje (LR) para cada peso de red, lo que resulta ventajoso a la hora de manejar el ruido en los datos.
Capa convolucional (Conv2D)
Es el componente principal de las redes neuronales convolucionales (CNN). Se utiliza principalmente para procesar conjuntos de datos espaciales como imágenes. Esta capa aplica una función u operación de convolución a la entrada y luego pasa el resultado a la siguiente capa.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)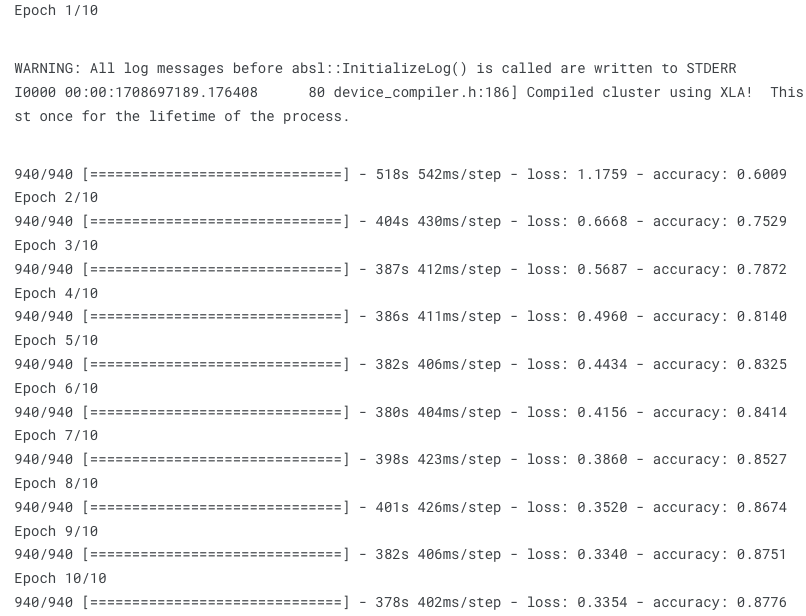
Prueba del detector de calidad de los alimentos
Ahora probemos el modelo dándole una nueva imagen de comida y veamos con qué precisión puede clasificar entre alimentos frescos y podridos.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
Como podemos ver, el modelo ha predicho correctamente. como le hemos dado naranja podrida imagen como entrada, el modelo la ha predicho correctamente como Podrido.
Para el código frontend (React) y backend (Django), puedes ver mi código completo en GitHub aquí: Enlace
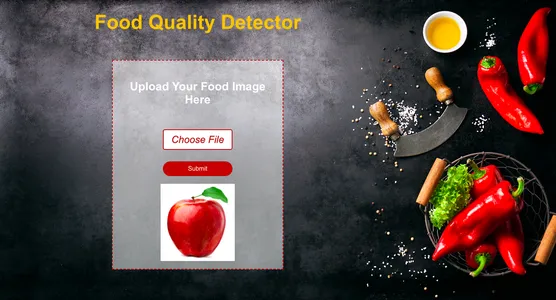
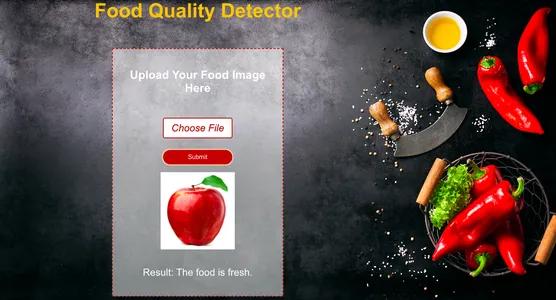
Conclusión
En conclusión, para automatizar las quejas sobre la calidad de los alimentos en aplicaciones de entrega hiperlocal, proponemos construir un modelo de aprendizaje profundo integrado con una aplicación web. Sin embargo, debido a los datos de entrenamiento limitados, es posible que el modelo no detecte con precisión todas las imágenes de alimentos. Esta implementación sirve como un paso fundamental hacia una solución más amplia. El acceso a imágenes cargadas por usuarios en tiempo real dentro de estas aplicaciones mejoraría significativamente la precisión de nuestro modelo.
Puntos clave
- La calidad de los alimentos desempeña un papel fundamental para lograr la satisfacción del cliente en el mercado hiperlocal de entrega de alimentos.
- Puede utilizar la tecnología de aprendizaje profundo para entrenar un predictor preciso de la calidad de los alimentos.
- Obtuvo experiencia práctica con esta guía paso a paso para crear la aplicación web.
- Ha comprendido la importancia de la calidad del conjunto de datos para crear un modelo preciso.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

