Para crear cualquier aplicación de IA generativa, es imperativo enriquecer los grandes modelos de lenguaje (LLM) con nuevos datos. Aquí es donde entra en juego la técnica de recuperación de generación aumentada (RAG). RAG es una arquitectura de aprendizaje automático (ML) que utiliza documentos externos (como Wikipedia) para aumentar su conocimiento y lograr resultados de última generación en tareas intensivas en conocimiento. . Para ingerir estas fuentes de datos externas, las bases de datos Vector han evolucionado, que pueden almacenar incrustaciones de vectores de la fuente de datos y permitir búsquedas de similitudes.
En esta publicación, mostramos cómo crear una canalización de ingesta de extracción, transformación y carga (ETL) de RAG para incorporar grandes cantidades de datos en un Servicio Amazon OpenSearch agrupar y utilizar Servicio de base de datos relacional de Amazon (Amazon RDS) para PostgreSQL con la extensión pgvector como almacén de datos vectoriales. Cada servicio implementa algoritmos de k-vecino más cercano (k-NN) o vecino más cercano aproximado (ANN) y métricas de distancia para calcular la similitud. Introducimos la integración de Ray en el mecanismo de recuperación de documentos contextuales del RAG. Ray es una biblioteca informática distribuida de propósito general, Python y código abierto. Permite el procesamiento de datos distribuidos para generar y almacenar incrustaciones de una gran cantidad de datos, paralelizando entre múltiples GPU. Usamos un clúster Ray con estas GPU para ejecutar ingesta y consultas en paralelo para cada servicio.
En este experimento, intentamos analizar los siguientes aspectos del servicio OpenSearch y la extensión pgvector en Amazon RDS:
- Como almacén de vectores, la capacidad de escalar y manejar un gran conjunto de datos con decenas de millones de registros para RAG
- Posibles cuellos de botella en el proceso de ingesta de RAG
- Cómo lograr un rendimiento óptimo en los tiempos de ingesta y recuperación de consultas para OpenSearch Service y Amazon RDS
Para comprender más sobre los almacenes de datos vectoriales y su papel en la creación de aplicaciones de IA generativa, consulte El papel de los almacenes de datos vectoriales en las aplicaciones de IA generativa.
Descripción general del servicio OpenSearch
OpenSearch Service es un servicio administrado para análisis, búsqueda e indexación segura de datos comerciales y operativos. OpenSearch Service admite datos a escala de petabytes con la capacidad de crear múltiples índices en texto y datos vectoriales. Con una configuración optimizada, apunta a una alta recuperación de las consultas. El servicio OpenSearch admite ANN y búsqueda exacta de k-NN. OpenSearch Service admite una selección de algoritmos de la NSLIB, FAISSy Lucene bibliotecas para impulsar la búsqueda k-NN. Creamos el índice ANN para OpenSearch con el algoritmo Hierarchical Navigable Small World (HNSW) porque se considera un mejor método de búsqueda para grandes conjuntos de datos. Para obtener más información sobre la elección del algoritmo de índice, consulte Elija el algoritmo k-NN para su caso de uso de mil millones de escalas con OpenSearch.
Descripción general de Amazon RDS para PostgreSQL con pgvector
La extensión pgvector agrega una búsqueda de similitud de vectores de código abierto a PostgreSQL. Al utilizar la extensión pgvector, PostgreSQL puede realizar búsquedas de similitudes en incrustaciones de vectores, brindando a las empresas una solución rápida y competente. pgvector proporciona dos tipos de búsquedas de similitud de vectores: vecino más cercano exacto, que da como resultado una recuperación del 100%, y vecino más cercano aproximado (ANN), que proporciona un mejor rendimiento que la búsqueda exacta con una compensación en la recuperación. Para búsquedas a través de un índice, puede elegir cuántos centros usar en la búsqueda; más centros proporcionarán una mejor recuperación con una compensación de rendimiento.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.

Veamos los componentes clave con más detalle.
Conjunto de datos
Usamos datos de OSCAR como nuestro corpus y el conjunto de datos SQUAD para proporcionar preguntas de muestra. Estos conjuntos de datos se convierten primero en archivos Parquet. Luego usamos un clúster de Ray para convertir los datos de Parquet en incrustaciones. Las incrustaciones creadas se incorporan a OpenSearch Service y Amazon RDS con pgvector.
OSCAR (Corpus agregado rastreado supergrande abierto) es un enorme corpus multilingüe obtenido mediante la clasificación del idioma y el filtrado del Rastreo común corpus utilizando el ungoliante arquitectura. Los datos se distribuyen por idioma tanto en forma original como deduplicada. El conjunto de datos de Oscar Corpus tiene aproximadamente 609 millones de registros y ocupa alrededor de 4.5 TB como archivos JSONL sin formato. Luego, los archivos JSONL se convierten al formato Parquet, lo que minimiza el tamaño total a 1.8 TB. Además, redujimos el conjunto de datos a 25 millones de registros para ahorrar tiempo durante la ingesta.
SQuAD (Stanford Question Answering Dataset) es un conjunto de datos de comprensión lectora que consta de preguntas planteadas por trabajadores colectivos en un conjunto de artículos de Wikipedia, donde la respuesta a cada pregunta es un segmento de texto, o lapso, del pasaje de lectura correspondiente, o la pregunta podría no tener respuesta. Usamos EQUIPO, con licencia como CC-BY-SA 4.0, para proporcionar preguntas de muestra. Tiene aproximadamente 100,000 preguntas con más de 50,000 preguntas sin respuesta escritas por trabajadores colectivos para que parezcan preguntas con respuesta.
Clúster de rayos para ingestión y creación de incrustaciones de vectores
En nuestras pruebas, descubrimos que las GPU tienen el mayor impacto en el rendimiento al crear las incorporaciones. Por lo tanto, decidimos utilizar un clúster de Ray para convertir nuestro texto sin formato y crear las incrustaciones. Ray es un marco informático unificado de código abierto que permite a los ingenieros de ML y a los desarrolladores de Python escalar aplicaciones de Python y acelerar las cargas de trabajo de ML. Nuestro grupo constaba de 5 g4dn.12xlarge Nube informática elástica de Amazon (Amazon EC2) instancias. Cada instancia se configuró con 4 GPU NVIDIA T4 Tensor Core, 48 vCPU y 192 GiB de memoria. Para nuestros registros de texto, terminamos fragmentando cada uno en 1,000 partes con una superposición de 100 partes. Esto asciende a aproximadamente 200 por registro. Para el modelo utilizado para crear incrustaciones, nos decidimos por todo-mpnet-base-v2 para crear un espacio vectorial de 768 dimensiones.
configuración de la infraestructura
Utilizamos los siguientes tipos de instancias RDS y configuraciones de clúster de servicios OpenSearch para configurar nuestra infraestructura.
Las siguientes son nuestras propiedades de tipo de instancia RDS:
- Tipo de instancia: db.r7g.12xlarge
- Almacenamiento asignado: 20 TB
- Multi-AZ: Verdadero
- Almacenamiento cifrado: Verdadero
- Habilitar información sobre rendimiento: verdadero
- Retención de Performance Insight: 7 días
- Tipo de almacenamiento: gp3
- IOPS aprovisionadas: 64,000 XNUMX
- Tipo de índice: FIV
- Número de listas: 5,000
- Función de distancia: L2
Las siguientes son las propiedades de nuestro clúster de OpenSearch Service:
- Version: 2.5
- Nodos de datos: 10
- Tipo de instancia de nodo de datos: r6g.4xlarge
- Nodos primarios: 3
- Tipo de instancia de nodo principal: r6g.xlarge
- Índice: motor HNSW:
nmslib - Intervalo de actualización: 30 segundos
ef_construction: 256- teléfono: 16
- Función de distancia: L2
Usamos configuraciones grandes tanto para el clúster de OpenSearch Service como para las instancias de RDS para evitar cuellos de botella en el rendimiento.
Implementamos la solución utilizando un Kit de desarrollo en la nube de AWS (CDK de AWS) montón, como se describe en la siguiente sección.
Implemente la pila de CDK de AWS
La pila de AWS CDK nos permite elegir OpenSearch Service o Amazon RDS para la ingesta de datos.
Requisitos previos
Antes de continuar con la instalación, en cdk, bin, src.tc, cambie los valores booleanos de Amazon RDS y OpenSearch Service a verdadero o falso, según sus preferencias.
También necesita un servicio vinculado Gestión de identidades y accesos de AWS (IAM) para el dominio del servicio OpenSearch. Para obtener más detalles, consulte Biblioteca de construcciones del servicio Amazon OpenSearch. También puede ejecutar el siguiente comando para crear el rol:
Esta pila de AWS CDK implementará la siguiente infraestructura:
- una VPC
- Un host de salto (dentro de la VPC)
- Un clúster del servicio OpenSearch (si se utiliza el servicio OpenSearch para la ingesta)
- Una instancia de RDS (si utiliza Amazon RDS para la ingesta)
- An Gerente de sistemas de AWS documento para implementar el clúster Ray
- An Servicio de almacenamiento simple de Amazon (Amazon S3) depósito
- An Pegamento AWS trabajo para convertir los archivos JSONL del conjunto de datos OSCAR a archivos Parquet
- Reloj en la nube de Amazon de los tableros
Descargar los datos
Ejecute los siguientes comandos desde el host de salto:
Antes de clonar el repositorio de git, asegúrese de tener un perfil de Hugging Face y acceso al corpus de datos de OSCAR. Debe utilizar el nombre de usuario y la contraseña para clonar los datos de OSCAR:
Convertir archivos JSONL a Parquet
La pila de AWS CDK creó el trabajo ETL de AWS Glue oscar-jsonl-parquet para convertir los datos de OSCAR de JSONL al formato Parquet.
Después de ejecutar el oscar-jsonl-parquet trabajo, los archivos en formato Parquet deberían estar disponibles en la carpeta parquet en el depósito S3.
Descarga las preguntas
Desde su servidor de salto, descargue los datos de las preguntas y cárguelos en su depósito S3:
Configurar el clúster de Ray
Como parte de la implementación de la pila de AWS CDK, creamos un documento de Systems Manager llamado CreateRayCluster.
Para ejecutar el documento, complete los siguientes pasos:
- En la consola de Systems Manager, en Documentos en el panel de navegación, elija Me pertenece, es mio, yo soy el dueno.
- Abra la
CreateRayClusterdocumento. - Elige Ejecutar.
La página de ejecución del comando tendrá los valores predeterminados completados para el clúster.
La configuración predeterminada solicita 5 g4dn.12xlarge. Asegúrese de que su cuenta tenga límites para admitir esto. El límite de servicio relevante es la ejecución de instancias G y VT bajo demanda. El valor predeterminado para esto es 64, pero esta configuración requiere 240 CPUS.
- Después de revisar la configuración del clúster, seleccione el host de salto como destino para el comando de ejecución.
Este comando realizará los siguientes pasos:
- Copie los archivos del clúster de Ray
- Configurar el clúster de Ray
- Configurar los índices del servicio OpenSearch
- Configurar las tablas RDS
Puede monitorear la salida de los comandos en la consola de Systems Manager. Este proceso tardará entre 10 y 15 minutos para el lanzamiento inicial.
Ejecutar ingesta
Desde el host de salto, conéctese al clúster de Ray:
La primera vez que se conecte al host, instale los requisitos. Estos archivos ya deberían estar presentes en el nodo principal.
Para cualquiera de los métodos de ingesta, si recibe un error como el siguiente, está relacionado con credenciales caducadas. La solución alternativa actual (al momento de escribir este artículo) es colocar archivos de credenciales en el nodo principal de Ray. Para evitar riesgos de seguridad, no utilice usuarios de IAM para la autenticación cuando desarrolle software específico o trabaje con datos reales. En su lugar, utilice la federación con un proveedor de identidad como AWS IAM Identity Center (sucesor del inicio de sesión único de AWS).
Normalmente, las credenciales se almacenan en el archivo. ~/.aws/credentials en sistemas Linux y macOS, y %USERPROFILE%.awscredentials en Windows, pero estas son credenciales a corto plazo con un token de sesión. Tampoco puede anular el archivo de credenciales predeterminado, por lo que debe crear credenciales a largo plazo sin el token de sesión utilizando un nuevo usuario de IAM.
Para crear credenciales a largo plazo, debe generar una clave de acceso de AWS y una clave de acceso secreta de AWS. Puede hacerlo desde la consola de IAM. Para obtener instrucciones, consulte Autenticar con credenciales de usuario de IAM.
Después de crear las claves, conéctese al host de salto usando Gestor de sesiones, una capacidad de Systems Manager, y ejecute el siguiente comando:
Ahora puede volver a ejecutar los pasos de ingesta.
Ingerir datos en el servicio OpenSearch
Si está utilizando el servicio OpenSearch, ejecute el siguiente script para ingerir los archivos:
Cuando esté completo, ejecute el script que ejecuta consultas simuladas:
Ingerir datos en Amazon RDS
Si utiliza Amazon RDS, ejecute el siguiente script para ingerir los archivos:
Cuando esté completo, asegúrese de ejecutar un vacío completo en la instancia de RDS.
Luego ejecute el siguiente script para ejecutar consultas simuladas:
Configurar el panel de Ray
Antes de configurar el panel de Ray, debe instalar el Interfaz de línea de comandos de AWS (AWS CLI) en su máquina local. Para obtener instrucciones, consulte Instale o actualice la última versión de AWS CLI.
Complete los siguientes pasos para configurar el panel:
- Instale la Complemento de administrador de sesión para la CLI de AWS.
- En la cuenta de Isengard, copie las credenciales temporales para bash/zsh y ejecútelas en su terminal local.
- Cree un archivo session.sh en su máquina y copie el siguiente contenido en el archivo:
- Cambie el directorio donde está almacenado este archivo session.sh.
- Ejecuta el comando
Chmod +xpara dar permiso ejecutable al archivo. - Ejecute el siguiente comando:
Por ejemplo:
Verá un mensaje como el siguiente:
Abra una nueva pestaña en su navegador e ingrese localhost:8265.
Verá el panel de Ray y las estadísticas de los trabajos y el clúster en ejecución. Puede realizar un seguimiento de las métricas desde aquí.
Por ejemplo, puede utilizar el panel de Ray para observar la carga en el clúster. Como se muestra en la siguiente captura de pantalla, durante la ingesta, las GPU tienen una utilización cercana al 100 %.
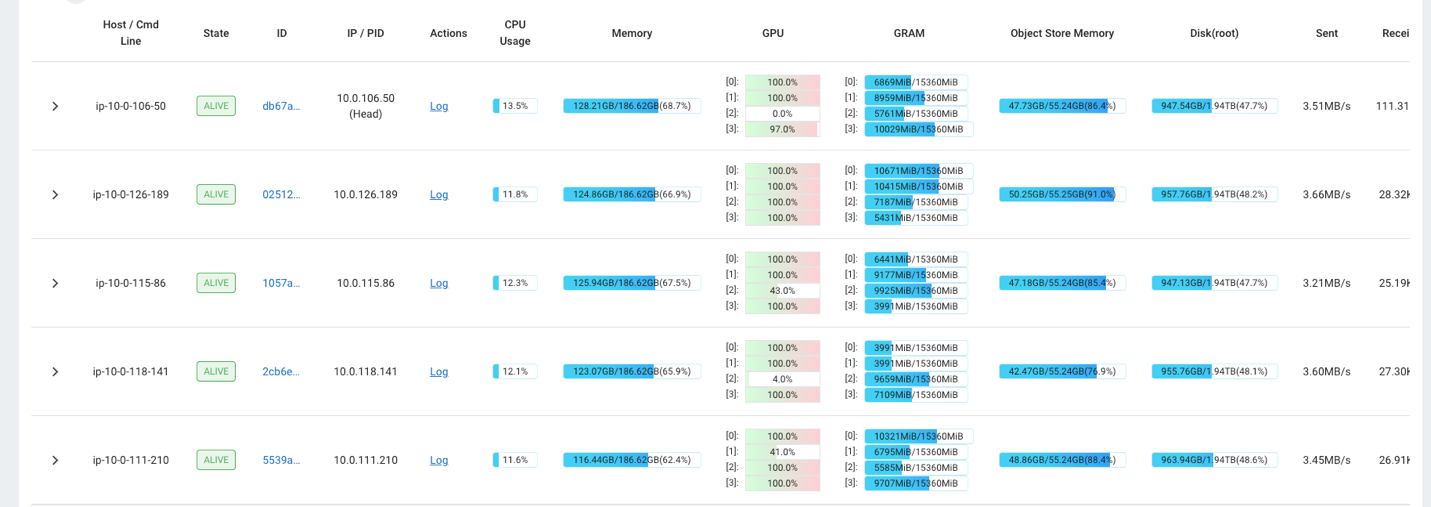
También puedes utilizar la RAG_Benchmarks Panel de CloudWatch para ver la tasa de ingesta y los tiempos de respuesta de consultas.
Extensibilidad de la solución.
Puede ampliar esta solución para conectar otros almacenes de vectores de AWS o de terceros. Para cada nuevo almacén de vectores, deberá crear scripts para configurar el almacén de datos y para ingerir datos. El resto de la tubería se puede reutilizar según sea necesario.
Conclusión
En esta publicación, compartimos una canalización ETL que puede usar para colocar datos RAG vectorizados tanto en OpenSearch Service como en Amazon RDS con la extensión pgvector como almacenes de datos vectoriales. La solución utilizó un clúster de Ray para proporcionar el paralelismo necesario para absorber un gran corpus de datos. Puede utilizar esta metodología para integrar cualquier base de datos vectorial de su elección para construir tuberías RAG.
Acerca de los autores
 Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
 David cristiana es un arquitecto principal de soluciones con sede en el sur de California. Tiene una licenciatura en Seguridad de la Información y una pasión por la automatización. Sus áreas de enfoque son la cultura y transformación de DevOps, la infraestructura como código y la resiliencia. Antes de unirse a AWS, ocupó puestos en seguridad, DevOps e ingeniería de sistemas, gestionando entornos de nube pública y privada a gran escala.
David cristiana es un arquitecto principal de soluciones con sede en el sur de California. Tiene una licenciatura en Seguridad de la Información y una pasión por la automatización. Sus áreas de enfoque son la cultura y transformación de DevOps, la infraestructura como código y la resiliencia. Antes de unirse a AWS, ocupó puestos en seguridad, DevOps e ingeniería de sistemas, gestionando entornos de nube pública y privada a gran escala.
 Prachi Kulkarni es arquitecto senior de soluciones en AWS. Su especialización es el aprendizaje automático y trabaja activamente en el diseño de soluciones utilizando diversas ofertas de análisis, big data y ML de AWS. Prachi tiene experiencia en múltiples ámbitos, incluidos atención médica, beneficios, comercio minorista y educación, y ha trabajado en diversos puestos en ingeniería y arquitectura de productos, gestión y éxito del cliente.
Prachi Kulkarni es arquitecto senior de soluciones en AWS. Su especialización es el aprendizaje automático y trabaja activamente en el diseño de soluciones utilizando diversas ofertas de análisis, big data y ML de AWS. Prachi tiene experiencia en múltiples ámbitos, incluidos atención médica, beneficios, comercio minorista y educación, y ha trabajado en diversos puestos en ingeniería y arquitectura de productos, gestión y éxito del cliente.
 Richa Gupta es arquitecto de soluciones en AWS. Le apasiona diseñar soluciones de extremo a extremo para los clientes. Su especialización es el aprendizaje automático y cómo se puede utilizar para crear nuevas soluciones que conduzcan a la excelencia operativa e impulsen los ingresos comerciales. Antes de unirse a AWS, trabajó como ingeniera de software y arquitecta de soluciones, creando soluciones para grandes operadores de telecomunicaciones. Fuera del trabajo, le gusta explorar nuevos lugares y le encantan las actividades de aventura.
Richa Gupta es arquitecto de soluciones en AWS. Le apasiona diseñar soluciones de extremo a extremo para los clientes. Su especialización es el aprendizaje automático y cómo se puede utilizar para crear nuevas soluciones que conduzcan a la excelencia operativa e impulsen los ingresos comerciales. Antes de unirse a AWS, trabajó como ingeniera de software y arquitecta de soluciones, creando soluciones para grandes operadores de telecomunicaciones. Fuera del trabajo, le gusta explorar nuevos lugares y le encantan las actividades de aventura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

