Introducción
ChatGPT
En el panorama dinámico de los negocios modernos, la intersección del aprendizaje automático y las operaciones (MLOps) ha surgido como una fuerza poderosa que remodela los enfoques tradicionales para la optimización de la conversión de ventas. El artículo lo lleva al papel transformador que desempeñan las estrategias MLOps para revolucionar el éxito de la conversión de ventas. A medida que las empresas se esfuerzan por lograr una mayor eficiencia y mejores interacciones con los clientes, la integración de técnicas de aprendizaje automático en las operaciones ocupa un lugar central. Esta exploración revela estrategias innovadoras que aprovechan MLOps no solo para optimizar los procesos de ventas sino también para desbloquear un éxito sin precedentes en la conversión de prospectos en clientes leales. Únase a nosotros en un viaje a través de las complejidades de MLOps y descubra cómo su aplicación estratégica está remodelando el panorama de la conversión de ventas.
OBJETIVOS DE APRENDIZAJE
- Importancia del modelo de optimización de ventas
- Limpieza de datos, transformación de conjuntos de datos y preprocesamiento de conjuntos de datos
- Creación de detección de fraude de extremo a extremo utilizando Kedro y Deepcheck
- Implementación del modelo usando streamlit y huggingface
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué es el modelo de optimización de ventas?
Un modelo de optimización de ventas es un modelo de aprendizaje automático de un extremo a otro para maximizar la venta de productos y mejorar la tasa de conversión. El modelo toma varios parámetros como entradas, como impresión, grupo de edad, sexo, tasa de clics y costo por clic. Una vez entrenado, el modelo predice la cantidad de personas que comprarán el producto después de ver el anuncio.
Requisitos previos necesarios
1) Clonar el repositorio
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) Crear y activar el entorno virtual.
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4) Instale Kedro, Kedro-viz, Streamlit y Deepcheck
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-vizDescripción de datos
Realicemos un análisis de datos fundamental utilizando la implementación de Python en un conjunto de datos de Kaggle. Para descargar el conjunto de datos, haga clic en haga clic aquí
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()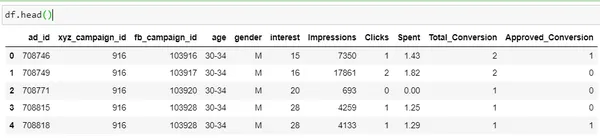
| Columna | Descripción |
| ad_id | Una identificación única para cada anuncio |
| xyz_campaign_id | Un ID asociado a cada campaña publicitaria de la empresa XYZ. |
| fb_campaign_id | Una identificación asociada con cómo Facebook rastrea cada campaña. |
| edad | Edad de la persona a quien se muestra el anuncio |
| género | Género de la persona a quien se le muestra el anuncio |
| intereses | un código que especifica la categoría a la que pertenece el interés de la persona (los intereses son los mencionados en el perfil público de Facebook de la persona) |
| Impresiones | el número de veces que se mostró el anuncio. |
| Clicks | Número de clics para ese anuncio. |
| Gastado | Monto pagado por la empresa xyz a Facebook, para mostrar ese anuncio |
| Total conversión |
Total Número de personas que preguntaron sobre el producto después de ver el anuncio. |
| Aprobado conversión |
Total Número de personas que compraron el producto después de ver el anuncio. |
Aquí el "Conversión aprobada”es la columna de destino. Nuestro
El objetivo es diseñar un modelo que aumente la venta del producto una vez que la gente vea
el anuncio.
Desarrollo de modelos utilizando Kedro
Para construir este proyecto de un extremo a otro, utilizaremos la herramienta Kedro. Kedro es una herramienta de código abierto que se utiliza para crear un modelo de aprendizaje automático listo para producción y que ofrece una serie de beneficios.
- Maneja la complejidad: Proporciona una estructura para probar datos que se pueden enviar a producción después de una prueba exitosa.
- Normalización: Proporciona una plantilla estándar para el proyecto. Haciendo que sea más fácil de entender para los demás.
- Listo para producción: El código se puede enviar fácilmente a producción con código exploratorio que puede pasar a experimentos modulares, reproducibles y mantenibles.
Leer Más: Tutorial de Kedro Framework
Estructura de tubería
Para crear un proyecto en Kedro, siga los pasos a continuación.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizUsando kedro diseñaremos el modelo de canalización de un extremo a otro que se muestra a continuación.
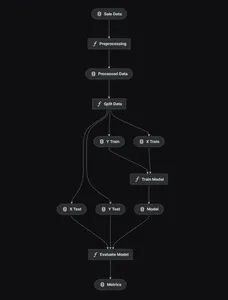
Preprocesamiento de datos
- Compruebe si faltan valores y trátelos.
- Creando dos nuevas columnas CTR y CPC.
- Conversión de variable de columna en numérica.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_dataDividir datos
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_testArriba, el conjunto de datos se divide en un conjunto de datos de entrenamiento y un conjunto de datos de prueba para fines de entrenamiento del modelo.
Entrenamiento de modelos
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
Usaremos el módulo RandomForestRegressor para entrenar el modelo. Solo con RandomForestRegressor pasamos otros parámetros como n_estimators random_state y max_samples.
Evaluación
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}Una vez que se entrena el modelo, se evalúa utilizando una serie de métricas clave como MAE, MSE, RMSE y R2-score.
Rastreador de experimentos
Para realizar un seguimiento del rendimiento del modelo y seleccionar el mejor modelo, utilizaremos el rastreador de experimentos. La funcionalidad del rastreador de experimentos es guardar toda la información sobre el experimento cuando se ejecuta la aplicación. Para habilitar el rastreador de experimentos en Kedro, podemos actualizar el archivo catalog.xml. El parámetro versionado debe establecerse en Verdadero. A continuación se muestra el ejemplo.
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: TrueEsto ayuda a rastrear el resultado del modelo y guardar la versión del modelo. Aquí, utilizaremos el rastreador de experimentos en el paso de evaluación para realizar un seguimiento del rendimiento del modelo durante la fase de desarrollo.
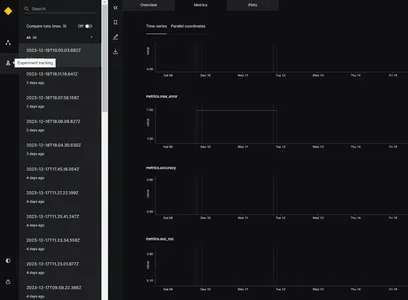
Cuando se ejecuta el modelo, generará diferentes métricas de evaluación, como MAE, MSE, RMSE y puntuación R2 para diferentes marcas de tiempo, como se muestra en la imagen. Sobre la base de las métricas de evaluación anteriores, se puede seleccionar el mejor modelo.
Deepcheck: para monitoreo de datos y modelos
Cuando el modelo se implementa en producción, existe la posibilidad de que la calidad de los datos cambie con el tiempo y, debido a esto, el rendimiento del modelo también puede cambiar. Para solucionar este problema necesitamos monitorear los datos en el entorno de producción. Para ello, utilizaremos una herramienta de código abierto Deepcheck. Deepcheck tiene bibliotecas incorporadas como Label-drift y Feature-Drift que se pueden integrar fácilmente con el código del modelo.
- FeatureDrift: – Una deriva significa un cambio en la distribución de datos a lo largo del tiempo debido al cual se degrada el rendimiento del modelo. FeatureDift significa que se ha producido un cambio en una única característica del conjunto de datos.
- Labeldrift: – Labeldrift ocurre cuando las etiquetas reales de un conjunto de datos cambian con el tiempo. Ocurre principalmente debido a cambios en los criterios de la etiqueta.
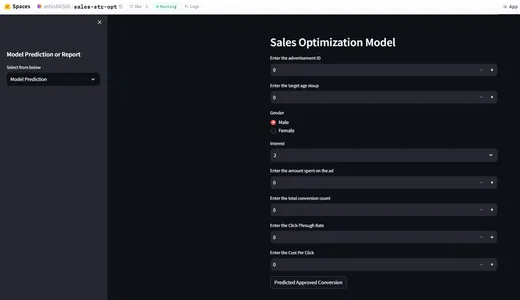
Integración de predicción y monitoreo de modelos con Streamlit
Ahora crearemos una interfaz de usuario para interactuar con el modelo y realizar predicciones sobre los parámetros de entrada dados para verificar la tasa de conversión.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
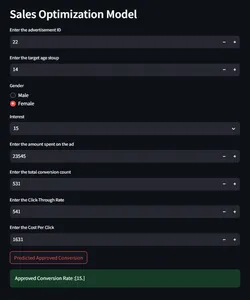
Implementación mediante HuggingFace
Ahora que hemos creado un modelo de optimización de ventas de un extremo a otro, implementaremos el modelo utilizando HuggingFace. En huggingface, necesitamos configurar el archivo README.md para la implementación del modelo. Huggingface se encarga de CI/CD. Como siempre que hay un cambio en el archivo, realizará un seguimiento de los cambios y volverá a implementar la aplicación. A continuación se muestra la configuración del archivo readme.md.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseDemostración de la aplicación HuggingFace
Para la versión en la nube haga clic haga clic aquí
Conclusión
- Las aplicaciones de aprendizaje automático pueden proporcionar una tasa de conversión de prueba en un mercado desconocido, lo que ayuda a las empresas a conocer la demanda del producto.
- Al utilizar el modelo de optimización de ventas, las empresas pueden dirigirse a su público adecuado.
- Esta aplicación ayuda a aumentar los ingresos comerciales.
- El monitoreo de datos en tiempo real también puede ayudar a rastrear el cambio de modelo y el cambio de comportamiento del usuario.
Preguntas frecuentes
R. El propósito del modelo de optimización de ventas es predecir la cantidad de clientes que comprarán el producto después de ver el anuncio.
R. El seguimiento de los datos ayuda a realizar un seguimiento del conjunto de datos y del comportamiento del modelo.
R. Sí, huggingface es de uso gratuito con la función básica 2 vCPU y 16 GB de RAM.
R. No existen reglas estrictas para seleccionar informes en la etapa de monitoreo del modelo; deepcheck tiene muchas bibliotecas incorporadas, como deriva de modelo y deriva de distribución.
R. Streamlit ayuda en la implementación local, lo que ayuda a corregir errores durante la fase de desarrollo.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

