Imagen del autor
El uso de canalizaciones de Scikit-learn puede simplificar sus pasos de preprocesamiento y modelado, reducir la complejidad del código, garantizar la coherencia en el preprocesamiento de datos, ayudar con el ajuste de hiperparámetros y hacer que su flujo de trabajo esté más organizado y sea más fácil de mantener. Al integrar múltiples transformaciones y el modelo final en una sola entidad, Pipelines mejora la reproducibilidad y hace que todo sea más eficiente.
En este tutorial, trabajaremos con el Rotación bancaria conjunto de datos de Kaggle para entrenar un clasificador de bosque aleatorio. Compararemos el enfoque convencional de preprocesamiento de datos y entrenamiento de modelos con un método más eficiente que utiliza canalizaciones de Scikit-learn y ColumnTransformers.
En el proceso de procesamiento de datos, aprenderemos cómo transformar columnas categóricas y numéricas individualmente. Comenzaremos con un estilo de código tradicional y luego mostraremos una mejor manera de realizar un procesamiento similar.
Después de extraer los datos del archivo zip, cargue el archivo `train.csv` con “id” como columna de índice. Elimine columnas innecesarias y mezcle el conjunto de datos.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
Tenemos columnas categóricas, enteras y flotantes. El conjunto de datos parece bastante limpio.

Código simple de aprendizaje de Scikit
Como científico de datos, he escrito este código varias veces. Nuestro objetivo es completar los valores faltantes para características tanto categóricas como numéricas. Para lograr esto, usaremos un `SimpleImputer` con diferentes estrategias para cada tipo de característica.
Una vez completados los valores faltantes, convertiremos características categóricas en números enteros y aplicaremos una escala mínima-máxima a las características numéricas.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
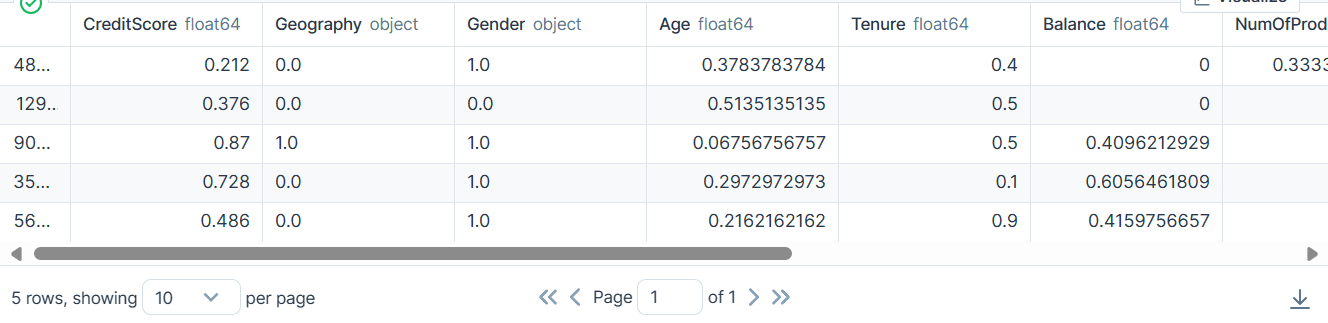
bank_df.head()
Como resultado, obtuvimos un conjunto de datos limpio y transformado solo con valores enteros o flotantes.
Código de canalizaciones de Scikit-learn
Convirtamos el código anterior usando `Pipeline` y `ColumnTransformer`. En lugar de aplicar la técnica de preprocesamiento, crearemos dos canalizaciones. Uno es para columnas numéricas y el otro es para columnas categóricas.
- En el proceso numérico, utilizamos una imputación simple con una estrategia de "media" y aplicamos un escalador mínimo-máximo para la normalización.
- En el canal categórico, utilizamos el imputador simple con la estrategia "más_frecuente" y el codificador original para convertir las categorías en valores numéricos.
Combinamos las dos canalizaciones utilizando ColumnTransformer y proporcionamos a cada una el índice de columnas. Le ayudará a aplicar estas canalizaciones en determinadas columnas. Por ejemplo, se aplicará una canalización de transformador categórico solo a las columnas 1 y 2.
Nota: el resto = "paso a través" significa que las columnas que no han sido procesadas se agregarán al final. En nuestro caso, es la columna de destino.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Después de la transformación, la matriz resultante contiene un valor de transformación numérico al principio y un valor de transformación categórico al final, según el orden de las tuberías en el transformador de columna.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
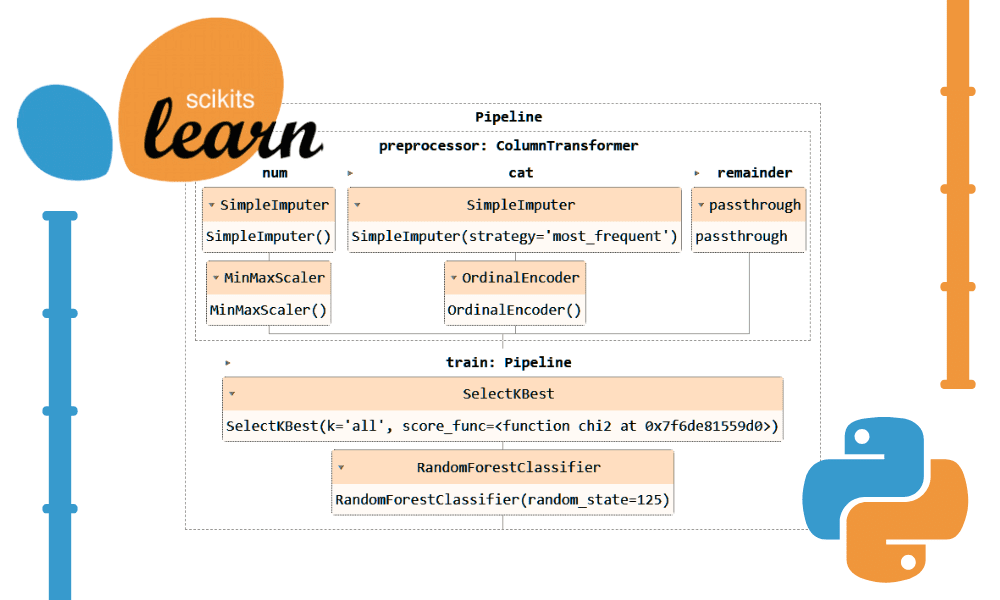
Puede ejecutar el objeto de canalización en Jupyter Notebook para visualizar la canalización. Asegúrese de tener la última versión de Scikit-learn.
preproc_pipe

Para entrenar y evaluar nuestro modelo, necesitamos dividir nuestro conjunto de datos en dos subconjuntos: entrenamiento y prueba.
Para hacer esto, primero crearemos variables dependientes e independientes y las convertiremos en matrices NumPy. Luego, usaremos la función `train_test_split` para dividir el conjunto de datos en dos subconjuntos.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Código simple de aprendizaje de Scikit
La forma convencional de escribir código de entrenamiento es realizar primero la selección de características usando "SelectKBest" y luego proporcionar la nueva característica a nuestro modelo de Clasificador de bosque aleatorio.
Primero entrenaremos el modelo usando el conjunto de entrenamiento y evaluaremos los resultados usando el conjunto de datos de prueba.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Logramos una puntuación de precisión razonablemente buena.
0.8613035487063481Código de canalizaciones de Scikit-learn
Usemos la función `Pipeline` para combinar ambos pasos de entrenamiento en una canalización. Luego podemos ajustar el modelo al conjunto de entrenamiento y evaluarlo en el conjunto de prueba.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Logramos resultados similares, pero el código parece ser más eficiente y sencillo. Es bastante fácil agregar o eliminar nuevos pasos del proceso de capacitación.
0.8613035487063481
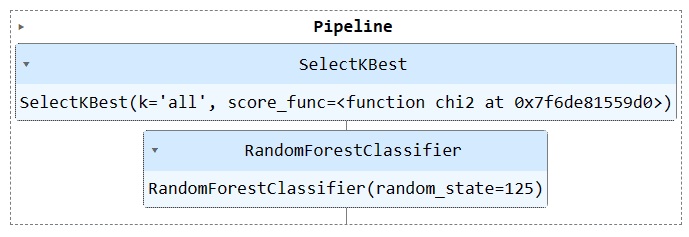
Ejecute el objeto de canalización para visualizar la canalización.
train_pipe
Ahora, combinaremos el proceso de preprocesamiento y el de capacitación creando otro canal y agregando ambos canales.
Aquí está el código completo:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Salida:
0.8592837955201874
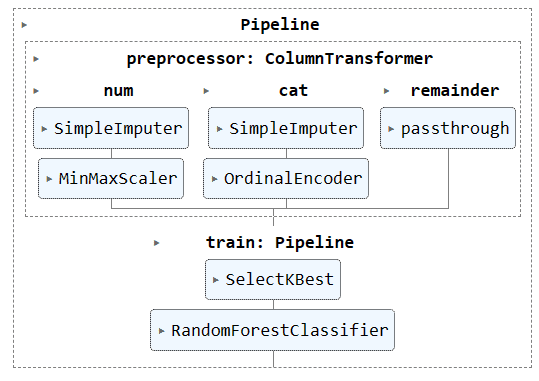
Visualizando el pipeline completo.
complete_pipe

Una de las principales ventajas de utilizar canalizaciones es que puede guardar la canalización con el modelo. Durante la inferencia, solo necesita cargar el objeto de canalización, que estará listo para procesar los datos sin procesar y brindarle predicciones precisas. No es necesario volver a escribir las funciones de procesamiento y transformación en el archivo de la aplicación, ya que funcionará de inmediato. Esto hace que el flujo de trabajo del aprendizaje automático sea más eficiente y ahorra tiempo.
Primero guardemos la tubería usando el skops-dev/skops biblioteca.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Luego, cargue la canalización guardada y muéstrela.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Como podemos ver, hemos cargado correctamente la canalización.
Para evaluar nuestra canalización cargada, haremos predicciones en el conjunto de prueba y luego calcularemos la precisión y las puntuaciones F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Resulta que tenemos que centrarnos en las clases minoritarias para mejorar nuestra puntuación en F1.
Accuracy: 86.0% F1: 0.76
Los archivos y el código del proyecto están disponibles en Espacio de trabajo de Deepnote. El espacio de trabajo tiene dos cuadernos: uno con el canal Scikit-learn y otro sin él.
En este tutorial, aprendimos cómo las canalizaciones de Scikit-learn pueden ayudar a optimizar los flujos de trabajo de aprendizaje automático al encadenar secuencias de transformaciones y modelos de datos. Al combinar el preprocesamiento y el entrenamiento de modelos en un único objeto Pipeline, podemos simplificar el código, garantizar transformaciones de datos consistentes y hacer que nuestros flujos de trabajo sean más organizados y reproducibles.
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

