En el panorama actual de interacciones uno a uno con los clientes para realizar pedidos, la práctica predominante sigue dependiendo de asistentes humanos, incluso en entornos como cafeterías con servicio de autoservicio y establecimientos de comida rápida. Este enfoque tradicional plantea varios desafíos: depende en gran medida de procesos manuales, lucha por escalar de manera eficiente con las crecientes demandas de los clientes, introduce la posibilidad de errores humanos y opera dentro de horas específicas de disponibilidad. Además, en mercados competitivos, las empresas que se adhieren únicamente a procesos manuales pueden tener dificultades para ofrecer un servicio eficiente y competitivo. A pesar de los avances tecnológicos, el modelo centrado en el ser humano sigue profundamente arraigado en el procesamiento de pedidos, lo que genera estas limitaciones.
La posibilidad de utilizar tecnología para asistencia personalizada en el procesamiento de pedidos ha estado disponible desde hace algún tiempo. Sin embargo, las soluciones existentes a menudo pueden clasificarse en dos categorías: sistemas basados en reglas que exigen mucho tiempo y esfuerzo para su instalación y mantenimiento, o sistemas rígidos que carecen de la flexibilidad necesaria para interacciones humanas con los clientes. Como resultado, las empresas y organizaciones enfrentan desafíos para implementar dichas soluciones de manera rápida y eficiente. Afortunadamente, con la llegada de IA generativa y modelos de lenguaje grande (LLM), ahora es posible crear sistemas automatizados que puedan manejar el lenguaje natural de manera eficiente y con un cronograma de avance acelerado.
lecho rocoso del amazonas es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability AI y Amazon a través de una única API, junto con un amplio conjunto de capacidades que usted Necesitamos crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable. Además de Amazon Bedrock, puede utilizar otros servicios de AWS como JumpStart de Amazon SageMaker y Amazon lex para crear agentes de procesamiento de pedidos de IA generativa totalmente automatizados y fácilmente adaptables.
En esta publicación, le mostramos cómo crear un agente de procesamiento de pedidos con capacidad de voz utilizando Amazon Lex, Amazon Bedrock y AWS Lambda.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de nuestra solución.
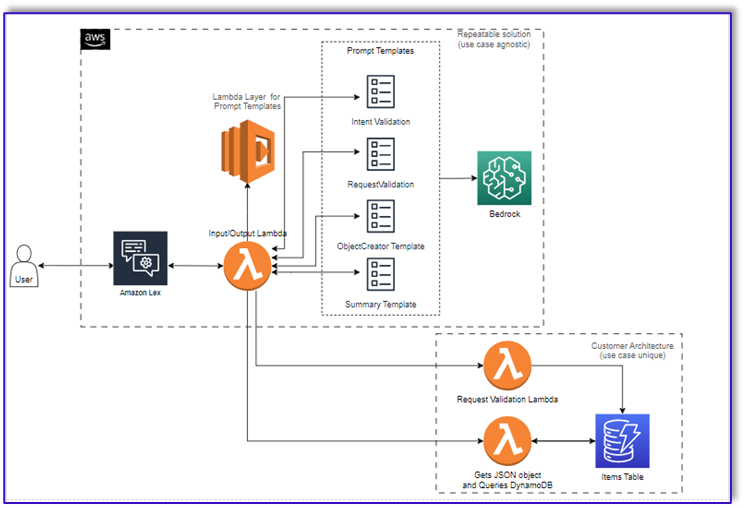
El flujo de trabajo consta de los siguientes pasos:
- Un cliente realiza el pedido mediante Amazon Lex.
- El bot de Amazon Lex interpreta las intenciones del cliente y activa una
DialogCodeHook.
- Una función Lambda extrae la plantilla de solicitud adecuada de la capa Lambda y da formato a las solicitudes del modelo agregando la entrada del cliente en la plantilla de solicitud asociada.
- El
RequestValidation El mensaje verifica el pedido con el elemento del menú y le informa al cliente a través de Amazon Lex si hay algo que quiere pedir que no forma parte del menú y le brindará recomendaciones. El mensaje también realiza una validación preliminar para determinar si el pedido está completo.
- El
ObjectCreator El mensaje convierte las solicitudes de lenguaje natural en una estructura de datos (formato JSON).
- La función Lambda del validador de clientes verifica los atributos requeridos para el pedido y confirma si toda la información necesaria está presente para procesar el pedido.
- Una función Lambda del cliente toma la estructura de datos como entrada para procesar el pedido y pasa el total del pedido a la función Lambda orquestadora.
- La función Lambda de orquestación llama al punto final de Amazon Bedrock LLM para generar un resumen final del pedido que incluye el total del pedido desde el sistema de base de datos del cliente (por ejemplo, Amazon DynamoDB).
- El resumen del pedido se comunica al cliente a través de Amazon Lex. Una vez que el cliente confirme el pedido, se procesará el pedido.
Requisitos previos
Esta publicación asume que tiene una cuenta de AWS activa y está familiarizado con los siguientes conceptos y servicios:
Además, para acceder a Amazon Bedrock desde las funciones de Lambda, debe asegurarse de que el tiempo de ejecución de Lambda tenga las siguientes bibliotecas:
- boto3>=1.28.57
- awscli>=1.29.57
- botocore>=1.31.57
Esto se puede hacer con un capa lambda o utilizando una AMI específica con las bibliotecas necesarias.
Además, estas bibliotecas son necesarias al llamar a la API de Amazon Bedrock desde Estudio Amazon SageMaker. Esto se puede hacer ejecutando una celda con el siguiente código:
%pip install --no-build-isolation --force-reinstall
"boto3>=1.28.57"
"awscli>=1.29.57"
"botocore>=1.31.57"
Finalmente, crea la siguiente política y luego la adjunta a cualquier rol que acceda a Amazon Bedrock:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
Crear una tabla DynamoDB
En nuestro escenario específico, hemos creado una tabla de DynamoDB como nuestro sistema de base de datos de clientes, pero también puede usar Servicio de base de datos relacional de Amazon (Amazon RDS). Complete los siguientes pasos para aprovisionar su tabla de DynamoDB (o personalice la configuración según sea necesario para su caso de uso):
- En la consola DynamoDB, elija Mesas en el panel de navegación.
- Elige Crear una tabla.
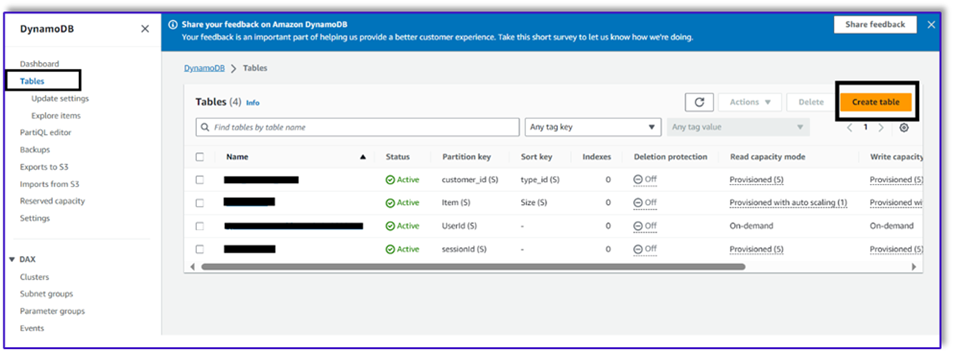
- Nombre de la tabla, ingrese un nombre (por ejemplo,
ItemDetails).
- Clave de partición, ingresa una clave (para esta publicación, usamos
Item).
- Ordenar clave, ingresa una clave (para esta publicación, usamos
Size).
- Elige Crear una tabla.

Ahora puede cargar los datos en la tabla de DynamoDB. Para esta publicación, utilizamos un archivo CSV. Puede cargar los datos en la tabla de DynamoDB usando código Python en un cuaderno de SageMaker.
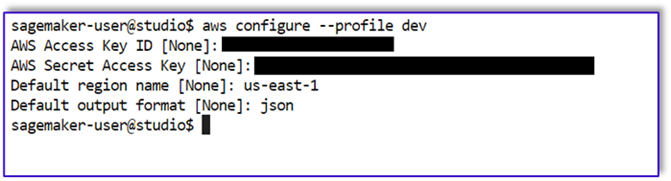
Primero, necesitamos configurar un perfil llamado dev.
- Abra una nueva terminal en SageMaker Studio y ejecute el siguiente comando:
aws configure --profile dev
Este comando le pedirá que ingrese su ID de clave de acceso a AWS, clave de acceso secreta, región de AWS predeterminada y formato de salida.
- Regrese al cuaderno de SageMaker y escriba un código Python para configurar una conexión a DynamoDB usando la biblioteca Boto3 en Python. Este fragmento de código crea una sesión utilizando un perfil de AWS específico llamado dev y luego crea un cliente DynamoDB usando esa sesión. El siguiente es el ejemplo de código para cargar los datos:
%pip install boto3
import boto3
import csv
# Create a session using a profile named 'dev'
session = boto3.Session(profile_name='dev')
# Create a DynamoDB resource using the session
dynamodb = session.resource('dynamodb')
# Specify your DynamoDB table name
table_name = 'your_table_name'
table = dynamodb.Table(table_name)
# Specify the path to your CSV file
csv_file_path = 'path/to/your/file.csv'
# Read CSV file and put items into DynamoDB
with open(csv_file_path, 'r', encoding='utf-8-sig') as csvfile:
csvreader = csv.reader(csvfile)
# Skip the header row
next(csvreader, None)
for row in csvreader:
# Extract values from the CSV row
item = {
'Item': row[0], # Adjust the index based on your CSV structure
'Size': row[1],
'Price': row[2]
}
# Put item into DynamoDB
response = table.put_item(Item=item)
print(f"Item added: {response}")
print(f"CSV data has been loaded into the DynamoDB table: {table_name}")
Alternativamente, puede utilizar Banco de trabajo NoSQL u otras herramientas para cargar rápidamente los datos en su tabla de DynamoDB.
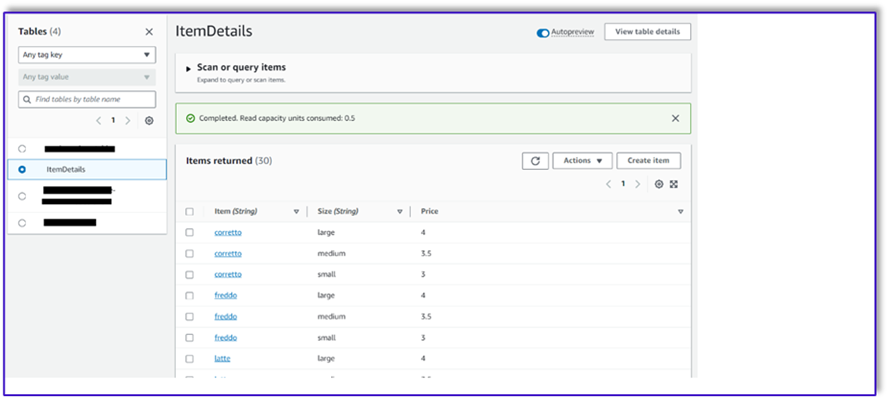
La siguiente es una captura de pantalla después de insertar los datos de muestra en la tabla.
Cree plantillas en un cuaderno de SageMaker utilizando la API de invocación de Amazon Bedrock
Para crear nuestra plantilla de aviso para este caso de uso, utilizamos Amazon Bedrock. Puede acceder a Amazon Bedrock desde Consola de administración de AWS y mediante invocaciones API. En nuestro caso, accedemos a Amazon Bedrock a través de API desde la comodidad de una computadora portátil de SageMaker Studio para crear no solo nuestra plantilla de solicitud, sino también nuestro código de invocación de API completo que luego podemos usar en nuestra función Lambda.
- En la consola de SageMaker, acceda a un dominio de SageMaker Studio existente o cree uno nuevo para acceder a Amazon Bedrock desde una computadora portátil de SageMaker.

- Después de crear el dominio y el usuario de SageMaker, elija el usuario y elija Más información y creativo. Esto abrirá un entorno JupyterLab.
- Cuando el entorno JupyterLab esté listo, abra un nuevo cuaderno y comience a importar las bibliotecas necesarias.
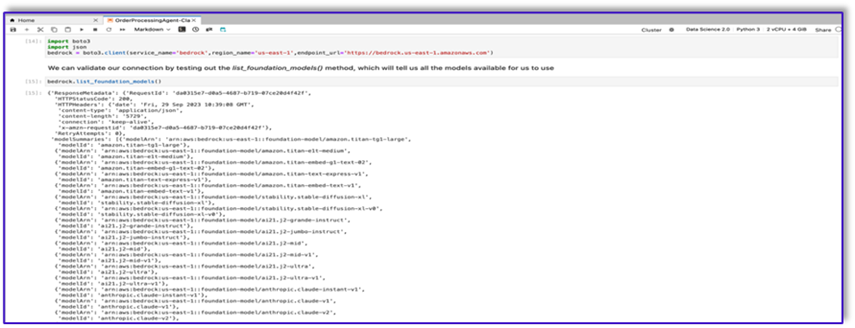
Hay muchos FM disponibles a través del SDK de Amazon Bedrock Python. En este caso, utilizamos Claude V2, un poderoso modelo fundamental desarrollado por Anthropic.
El agente de procesamiento de pedidos necesita algunas plantillas diferentes. Esto puede cambiar según el caso de uso, pero hemos diseñado un flujo de trabajo general que se puede aplicar a múltiples configuraciones. Para este caso de uso, la plantilla de Amazon Bedrock LLM logrará lo siguiente:
- Validar la intención del cliente
- Validar la solicitud
- Crear la estructura de datos del pedido.
- Pasar un resumen del pedido al cliente
- Para invocar el modelo, cree un objeto de tiempo de ejecución de base desde Boto3.

#Model api request parameters
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
import boto3
import json
bedrock = boto3.client(service_name='bedrock-runtime')
Comencemos trabajando en la plantilla de solicitud del validador de intenciones. Este es un proceso iterativo, pero gracias a la guía de ingeniería de avisos de Anthropic, puede crear rápidamente un aviso que pueda realizar la tarea.
- Cree la primera plantilla de solicitud junto con una función de utilidad que ayudará a preparar el cuerpo para las invocaciones de API.
El siguiente es el código para Prompt_template_intent_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to identify the intent that the human wants to accomplish and respond appropriately. The valid intents are: Greeting,Place Order, Complain, Speak to Someone. Always put your response to the Human within the Response tags. Also add an XML tag to your output identifying the human intent.nHere are some examples:n<example><Conversation> H: hi there.nnA: Hi, how can I help you today?nnH: Yes. I would like a medium mocha please</Conversation>nnA:<intent>Place Order</intent><Response>nGot it.</Response></example>n<example><Conversation> H: hellonnA: Hi, how can I help you today?nnH: my coffee does not taste well can you please re-make it?</Conversation>nnA:<intent>Complain</intent><Response>nOh, I am sorry to hear that. Let me get someone to help you.</Response></example>n<example><Conversation> H: hinnA: Hi, how can I help you today?nnH: I would like to speak to someone else please</Conversation>nnA:<intent>Speak to Someone</intent><Response>nSure, let me get someone to help you.</Response></example>n<example><Conversation> H: howdynnA: Hi, how can I help you today?nnH:can I get a large americano with sugar and 2 mochas with no whipped cream</Conversation>nnA:<intent>Place Order</intent><Response>nSure thing! Please give me a moment.</Response></example>n<example><Conversation> H: hinn</Conversation>nnA:<intent>Greeting</intent><Response>nHi there, how can I help you today?</Response></example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 1, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
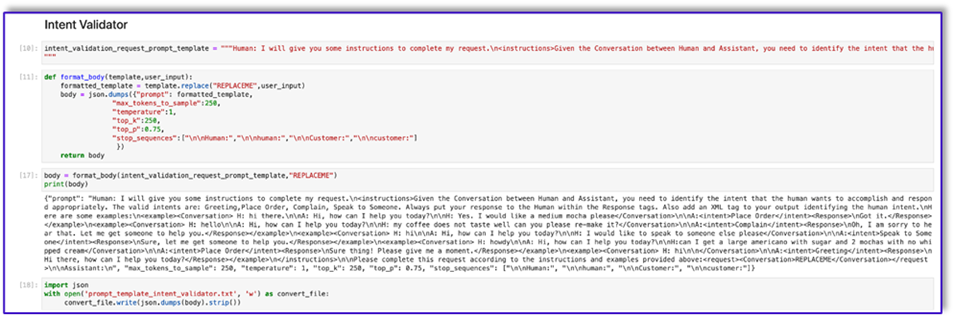

- Guarde esta plantilla en un archivo para cargarla en Amazon S3 y llamarla desde la función Lambda cuando sea necesario. Guarde las plantillas como cadenas serializadas JSON en un archivo de texto. La captura de pantalla anterior también muestra el ejemplo de código para lograr esto.
- Repita los mismos pasos con las otras plantillas.
Las siguientes son algunas capturas de pantalla de las otras plantillas y los resultados al llamar a Amazon Bedrock con algunas de ellas.
El siguiente es el código para Prompt_template_request_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the context do the following steps: 1. verify that the items in the input are valid. If customer provided an invalid item, recommend replacing it with a valid one. 2. verify that the customer has provided all the information marked as required. If the customer missed a required information, ask the customer for that information. 3. When the order is complete, provide a summary of the order and ask for confirmation always using this phrase: 'is this correct?' 4. If the customer confirms the order, Do not ask for confirmation again, just say the phrase inside the brackets [Great, Give me a moment while I try to process your order]</instructions>n<context>nThe VALID MENU ITEMS are: [latte, frappe, mocha, espresso, cappuccino, romano, americano].nThe VALID OPTIONS are: [splenda, stevia, raw sugar, honey, whipped cream, sugar, oat milk, soy milk, regular milk, skimmed milk, whole milk, 2 percent milk, almond milk].nThe required information is: size. Size can be: small, medium, large.nHere are some examples: <example>H: I would like a medium latte with 1 Splenda and a small romano with no sugar please.nnA: <Validation>:nThe Human is ordering a medium latte with one splenda. Latte is a valid menu item and splenda is a valid option. The Human is also ordering a small romano with no sugar. Romano is a valid menu item.</Validation>n<Response>nOk, I got: nt-Medium Latte with 1 Splenda and.nt-Small Romano with no Sugar.nIs this correct?</Response>nnH: yep.nnA:n<Response>nGreat, Give me a moment while I try to process your order</example>nn<example>H: I would like a cappuccino and a mocha please.nnA: <Validation>:nThe Human is ordering a cappuccino and a mocha. Both are valid menu items. The Human did not provide the size for the cappuccino. The human did not provide the size for the mocha. I will ask the Human for the required missing information.</Validation>n<Response>nSure thing, but can you please let me know the size for the Cappuccino and the size for the Mocha? We have Small, Medium, or Large.</Response></example>nn<example>H: I would like a small cappuccino and a large lemonade please.nnA: <Validation>:nThe Human is ordering a small cappuccino and a large lemonade. Cappuccino is a valid menu item. Lemonade is not a valid menu item. I will suggest the Human a replacement from our valid menu items.</Validation>n<Response>nSorry, we don't have Lemonades, would you like to order something else instead? Perhaps a Frappe or a Latte?</Response></example>nn<example>H: Can I get a medium frappuccino with sugar please?nnA: <Validation>:n The Human is ordering a Frappuccino. Frappuccino is not a valid menu item. I will suggest a replacement from the valid menu items in my context.</Validation>n<Response>nI am so sorry, but Frappuccino is not in our menu, do you want a frappe or a cappuccino instead? perhaps something else?</Response></example>nn<example>H: I want two large americanos and a small latte please.nnA: <Validation>:n The Human is ordering 2 Large Americanos, and a Small Latte. Americano is a valid menu item. Latte is a valid menu item.</Validation>n<Response>nOk, I got: nt-2 Large Americanos and.nt-Small Latte.nIs this correct?</Response>nnH: looks correct, yes.nnA:n<Response>nGreat, Give me a moment while I try to process your order.</Response></example>nn</Context>nnPlease complete this request according to the instructions and examples provided above:<request>REPLACEME</request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
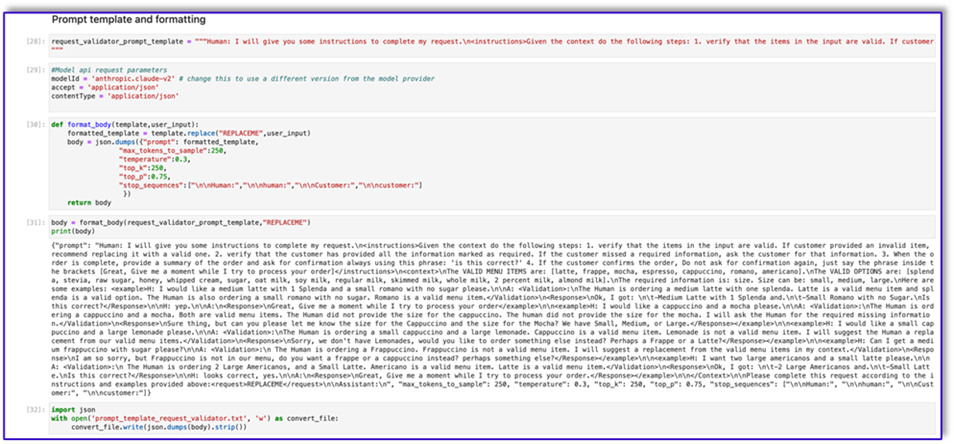
La siguiente es nuestra respuesta de Amazon Bedrock utilizando esta plantilla.

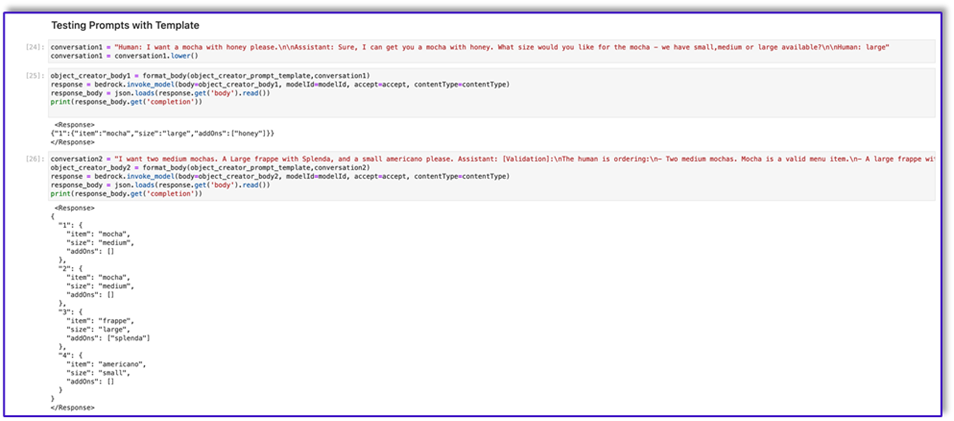
El siguiente es el código para prompt_template_object_creator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a json object in Response with the appropriate attributes.nHere are some examples:n<example><Conversation> H: I want a latte.nnA:nCan I have the size?nnH: Medium.nnA: So, a medium latte.nIs this Correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"frappe","size":"large","addOns":[]},"2":{"item":"americano","size":"small","addOns":["sugar"]},"3":{"item":"americano","size":"small","addOns":["sugar"]}}</Response>n</example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"americano","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large latte with oatmilk.nnA: Okay, let me confirm:nnLarge latte with oatmilknnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"large","addOns":["oatmilk"]}}</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"mocha","size":"small","addOns":["no whipped cream"]}}</Response>nn</example></instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"

El siguiente es el código para Prompt_template_order_summary.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a summary of the order with bullet points and include the order total.nHere are some examples:n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>10.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 large frappenn2 small americanos with sugar.nYour Order total is $10.50</Response></example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>3.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 medium americano.nYour Order total is $3.50</Response></example>n<example><Conversation> H: I want a large latte with oat milk.nnA: Okay, let me confirm:nnLarge latte with oat milknnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>6.75</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnLarge latte with oat milk.nYour Order total is $6.75</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>4.25</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnSmall mocha with no whipped cream.nYour Order total is $6.75</Response>nn</example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation>nn<OrderTotal>REPLACETOTAL</OrderTotal></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:", "[Conversation]"]}"


Como puede ver, hemos utilizado nuestras plantillas de mensajes para validar los elementos del menú, identificar la información requerida faltante, crear una estructura de datos y resumir el pedido. Los modelos fundamentales disponibles en Amazon Bedrock son muy potentes, por lo que podría realizar aún más tareas a través de estas plantillas.
Ha completado la ingeniería de las indicaciones y ha guardado las plantillas en archivos de texto. Ahora puede comenzar a crear el bot de Amazon Lex y las funciones Lambda asociadas.
Cree una capa Lambda con las plantillas de mensajes
Complete los siguientes pasos para crear su capa Lambda:
- En SageMaker Studio, cree una nueva carpeta con una subcarpeta llamada
python.
- Copie sus archivos de aviso al
python carpeta.

- Puede agregar la biblioteca ZIP a su instancia de notebook ejecutando el siguiente comando.
!conda install -y -c conda-forge zip
- Ahora, ejecute el siguiente comando para crear el archivo ZIP y cargarlo en la capa Lambda.
!zip -r prompt_templates_layer.zip prompt_templates_layer/.
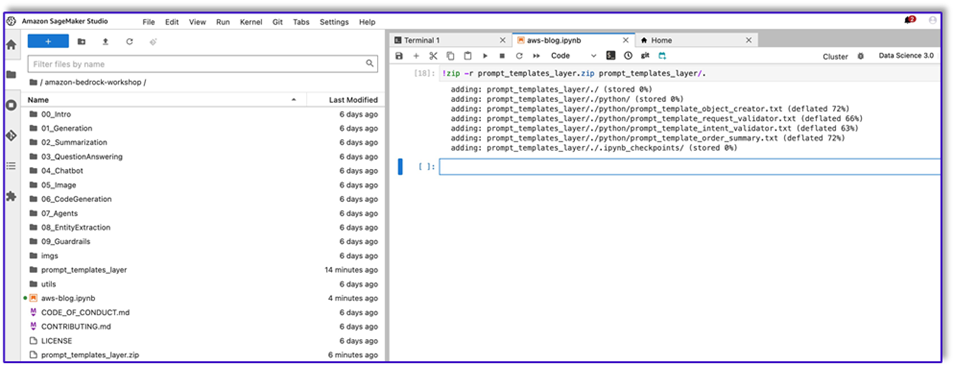
- Después de crear el archivo ZIP, puede descargarlo. Vaya a Lambda, cree una nueva capa cargando el archivo directamente o cargándolo primero en Amazon S3.
- Luego adjunte esta nueva capa a la función Lambda de orquestación.
Ahora sus archivos de plantilla de solicitud se almacenan localmente en su entorno de ejecución de Lambda. Esto acelerará el proceso durante la ejecución del bot.
Cree una capa Lambda con las bibliotecas necesarias
Complete los siguientes pasos para crear su capa Lambda con las bibliotecas requeridas:
- Abrir una Nube de AWS9 entorno de instancia, cree una carpeta con una subcarpeta llamada
python.
- Abra una terminal dentro del
python carpeta.
- Ejecute los siguientes comandos desde la terminal:
pip install “boto3>=1.28.57” -t .
pip install “awscli>=1.29.57" -t .
pip install “botocore>=1.31.57” -t .
- Ejecutar
cd .. y colócate dentro de tu nueva carpeta donde también tienes el python subcarpeta
- Ejecute el siguiente comando:
- Después de crear el archivo ZIP, puede descargarlo. Vaya a Lambda, cree una nueva capa cargando el archivo directamente o cargándolo primero en Amazon S3.
- Luego adjunte esta nueva capa a la función Lambda de orquestación.
Crear el bot en Amazon Lex v2
Para este caso de uso, creamos un bot de Amazon Lex que puede proporcionar una interfaz de entrada/salida para la arquitectura con el fin de llamar a Amazon Bedrock mediante voz o texto desde cualquier interfaz. Debido a que LLM manejará el tema de conversación de este agente de procesamiento de pedidos y Lambda organizará el flujo de trabajo, puede crear un bot con tres intenciones y sin espacios.
- En la consola de Amazon Lex, cree un nuevo bot con el método Crea un bot en blanco.
Ahora puede agregar una intención con cualquier expresión inicial adecuada para que los usuarios finales inicien la conversación con el bot. Usamos saludos simples y agregamos una respuesta inicial de bot para que los usuarios finales puedan enviar sus solicitudes. Al crear el bot, asegúrese de utilizar un enlace de código Lambda con intenciones; esto activará una función Lambda que organizará el flujo de trabajo entre el cliente, Amazon Lex y el LLM.
- Agregue su primera intención, que activa el flujo de trabajo y utiliza la plantilla de solicitud de validación de intenciones para llamar a Amazon Bedrock e identificar lo que el cliente está tratando de lograr. Agregue algunas expresiones simples para que los usuarios finales inicien una conversación.

No es necesario utilizar ningún espacio ni lectura inicial en ninguno de los intentos del bot. De hecho, no es necesario agregar expresiones de segunda o tercera intención. Esto se debe a que el LLM guiará a Lambda durante todo el proceso.
- Agregue un mensaje de confirmación. Puede personalizar este mensaje en la función Lambda más adelante.
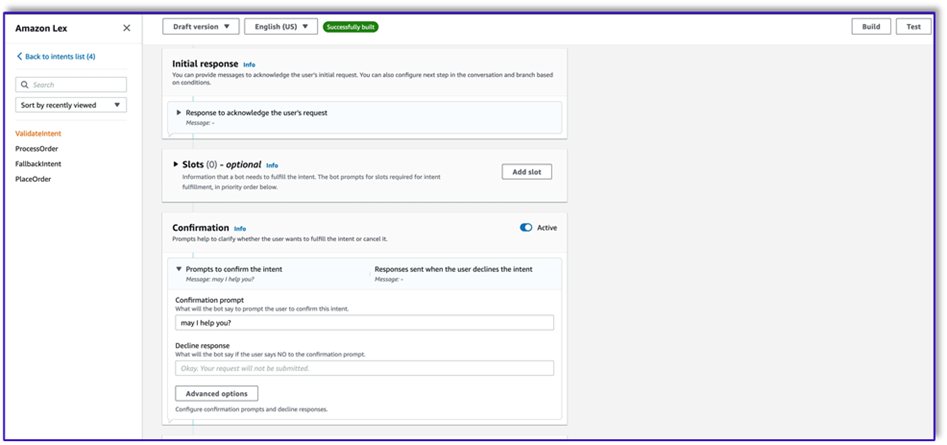
- under Ganchos de código, seleccione Use una función Lambda para inicialización y validación.
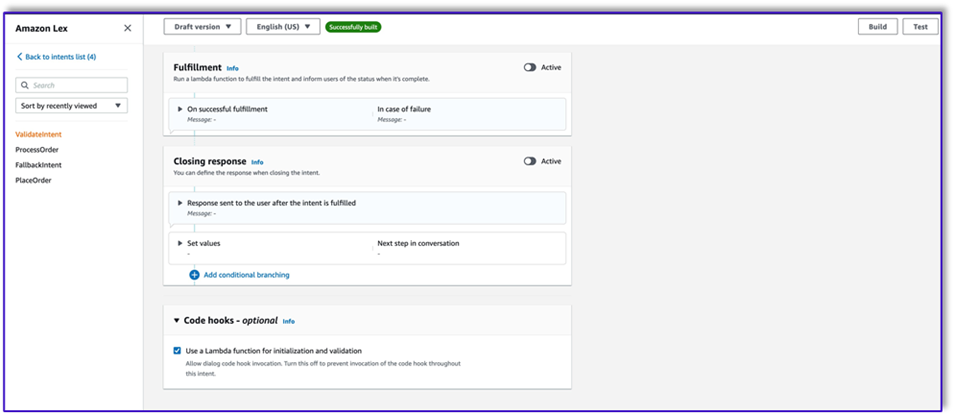
- Cree una segunda intención sin expresión ni respuesta inicial. Este es el
PlaceOrder intención.
Cuando el LLM identifica que el cliente está intentando realizar un pedido, la función Lambda activará esta intención y validará la solicitud del cliente en el menú, y se asegurará de que no falte ninguna información requerida. Recuerde que todo esto está en las plantillas de mensajes, por lo que puede adaptar este flujo de trabajo para cualquier caso de uso cambiando las plantillas de mensajes.
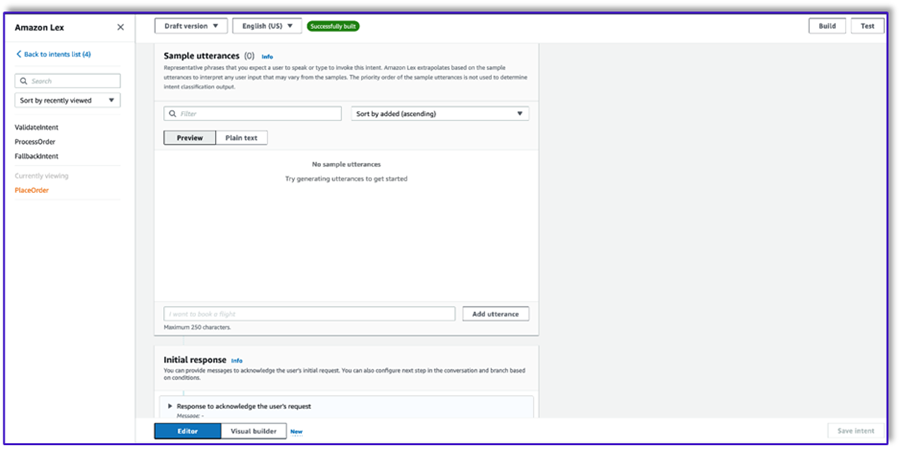
- No agregue ningún espacio, pero agregue un mensaje de confirmación y rechace la respuesta.
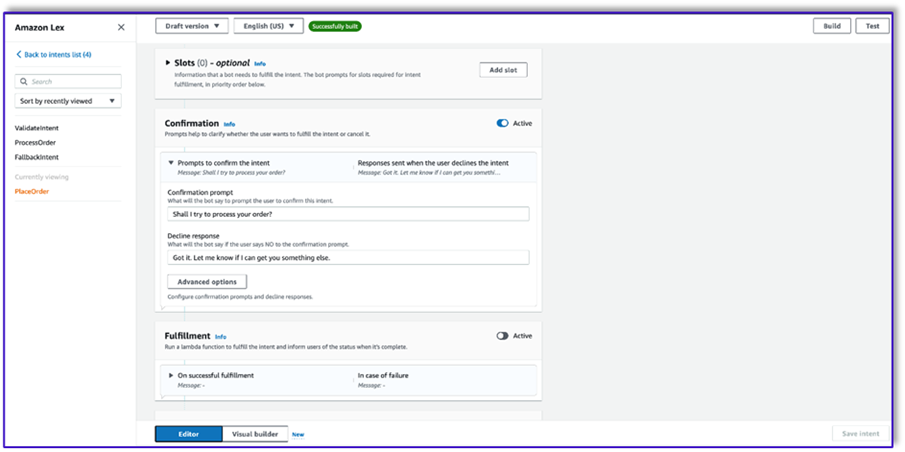
- Seleccione Use una función Lambda para inicialización y validación.

- Crea una tercera intención llamada
ProcessOrder sin ejemplos de expresiones ni espacios.
- Agregue una respuesta inicial, un mensaje de confirmación y una respuesta de rechazo.
Después de que el LLM haya validado la solicitud del cliente, la función Lambda activa la tercera y última intención para procesar el pedido. Aquí, Lambda usará la plantilla de creador de objetos para generar la estructura de datos JSON del pedido para consultar la tabla de DynamoDB y luego usará la plantilla de resumen del pedido para resumir todo el pedido junto con el total para que Amazon Lex pueda pasárselo al cliente.
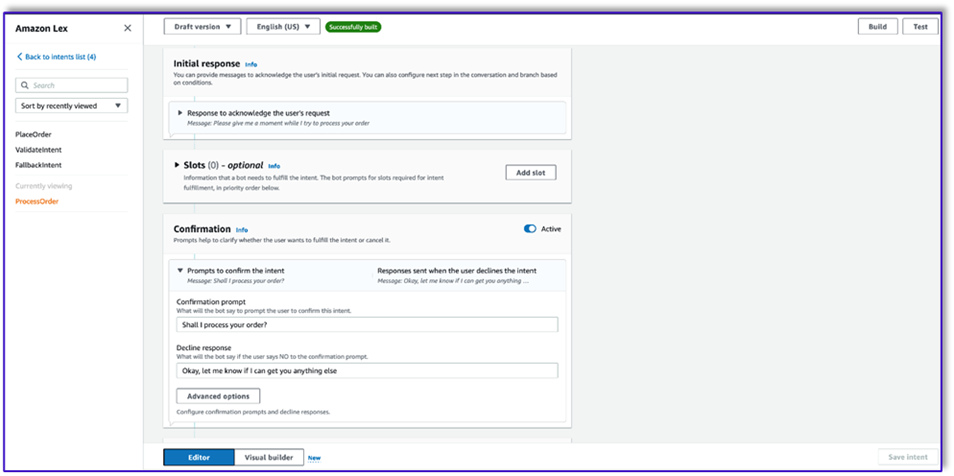
- Seleccione Use una función Lambda para inicialización y validación. Esto puede utilizar cualquier función Lambda para procesar el pedido después de que el cliente haya dado la confirmación final.

- Después de crear los tres intents, vaya al constructor visual para el
ValidateIntent, agregue un paso de intención de inicio y conecte la salida de la confirmación positiva a ese paso.
- Después de agregar la intención de acceso, edítela y elija la intención PlaceOrder como nombre de la intención.

- De manera similar, para ir al constructor visual para el
PlaceOrder intención y conectar la salida de la confirmación positiva a la ProcessOrder intención de ir. No se requiere edición para el ProcessOrder intención.
- Ahora necesita crear la función Lambda que organiza Amazon Lex y llama a la tabla de DynamoDB, como se detalla en la siguiente sección.
Cree una función Lambda para orquestar el bot de Amazon Lex
Ahora puede crear la función Lambda que organiza el flujo de trabajo y el bot de Amazon Lex. Complete los siguientes pasos:
- Cree una función Lambda con la política de ejecución estándar y deje que Lambda cree un rol por usted.
- En la ventana de código de su función, agregue algunas funciones de utilidad que le ayudarán: formatee las indicaciones agregando el contexto lex a la plantilla, llame a la API de Amazon Bedrock LLM, extraiga el texto deseado de las respuestas y más. Vea el siguiente código:
import json
import re
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
bedrock = boto3.client(service_name='bedrock-runtime')
def CreatingCustomPromptFromLambdaLayer(object_key,replace_items):
folder_path = '/opt/order_processing_agent_prompt_templates/python/'
try:
file_path = folder_path + object_key
with open(file_path, "r") as file1:
raw_template = file1.read()
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
value = json.dumps(json.dumps(value).replace('"','')).replace('"','')
raw_template = raw_template.replace(key,value)
modified_prompt = raw_template
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def CreatingCustomPrompt(object_key,replace_items):
logger.debug('replace_items is: {}'.format(replace_items))
#retrieve user request from intent_request
#we first propmt the model with current order
bucket_name = 'your-bucket-name'
#object_key = 'prompt_template_order_processing.txt'
try:
s3 = boto3.client('s3')
# Retrieve the existing template from S3
response = s3.get_object(Bucket=bucket_name, Key=object_key)
raw_template = response['Body'].read().decode('utf-8')
raw_template = json.loads(raw_template)
logger.debug('raw template is {}'.format(raw_template))
#template_json = json.loads(raw_template)
#logger.debug('template_json is {}'.format(template_json))
#template = json.dumps(template_json)
#logger.debug('template is {}'.format(template))
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
raw_template = raw_template.replace(key,value)
logger.debug("Replacing: {} nwith: {}".format(key,value))
modified_prompt = json.dumps(raw_template)
logger.debug("Modified template: {}".format(modified_prompt))
logger.debug("Modified template type is: {}".format(print(type(modified_prompt))))
#modified_template_json = json.loads(modified_prompt)
#logger.debug("Modified template json: {}".format(modified_template_json))
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def validate_intent(intent_request):
logger.debug('starting validate_intent: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_intent_validator.txt'
#replace_items = {"REPLACEME":full_context}
#replace_items = {"REPLACEME":dialog_context}
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
intent_validation_completion = prompt_bedrock(validation_prompt)
intent_validation_completion = re.sub(r'["]','',intent_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(intent_validation_completion)
validation_intent = extract_intent(intent_validation_completion)
#business logic depending on intents
if validation_intent == 'Place Order':
return validate_request(intent_request)
elif validation_intent in ['Complain','Speak to Someone']:
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close',validation_response)
if validation_intent == 'Greeting':
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'InProgress','ConfirmIntent',validation_response)
def validate_request(intent_request):
logger.debug('starting validate_request: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_request_validator.txt'
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
request_validation_completion = prompt_bedrock(validation_prompt)
request_validation_completion = re.sub(r'["]','',request_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(request_validation_completion)
##adding session attributes to keep current context
full_context = full_context + 'nn' + request_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',validation_response)
def process_order(intent_request):
logger.debug('starting process_order: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
# Preparing object creator prompt by adding context to prompt template
object_key = 'prompt_template_object_creator.txt'
replace_items = {"REPLACEME":dialog_context}
#object_creator_prompt = CreatingCustomPrompt(object_key,replace_items)
object_creator_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for object creation
object_creation_completion = prompt_bedrock(object_creator_prompt)
#extracting response from response completion
object_creation_response = extract_response(object_creation_completion)
inputParams = json.loads(object_creation_response)
inputParams = json.dumps(json.dumps(inputParams))
logger.debug('inputParams is: {}'.format(inputParams))
client = boto3.client('lambda')
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1:<AccountNumber>:function:aws-blog-order-validator',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
validationResult = responseFromChild['statusCode']
if validationResult == 205:
order_validation_error = responseFromChild['validator_response']
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',order_validation_error)
#invokes Order Processing lambda to query DynamoDB table and returns order total
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1: <AccountNumber>:function:aws-blog-order-processing',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
orderTotal = responseFromChild['body']
###Prompting the model to summarize the order along with order total
object_key = 'prompt_template_order_summary.txt'
replace_items = {"REPLACEME":dialog_context,"REPLACETOTAL":orderTotal}
#order_summary_prompt = CreatingCustomPrompt(object_key,replace_items)
order_summary_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
order_summary_completion = prompt_bedrock(order_summary_prompt)
#extracting response from response completion
order_summary_response = extract_response(order_summary_completion)
order_summary_response = order_summary_response + '. Shall I finalize processing your order?'
##adding session attributes to keep current context
full_context = full_context + 'nn' + order_summary_completion
dialog_context = dialog_context + 'nnAssistant: ' + order_summary_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'ProcessOrder','InProgress','ConfirmIntent',order_summary_response)
""" --- Main handler and Workflow functions --- """
def lambda_handler(event, context):
"""
Route the incoming request based on intent.
The JSON body of the request is provided in the event slot.
"""
logger.debug('event is: {}'.format(event))
return dispatch(event)
def dispatch(intent_request):
"""
Called when the user specifies an intent for this bot. If intent is not valid then returns error name
"""
logger.debug('intent_request is: {}'.format(intent_request))
intent_name = intent_request['sessionState']['intent']['name']
confirmation_state = intent_request['sessionState']['intent']['confirmationState']
# Dispatch to your bot's intent handlers
if intent_name == 'ValidateIntent' and confirmation_state == 'None':
return validate_intent(intent_request)
if intent_name == 'PlaceOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Confirmed':
return process_order(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'PlaceOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
elif intent_name == 'ProcessOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'ProcessOrder' and confirmation_state == 'Confirmed':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Perfect! Your order has been processed. Please proceed to payment.')
elif intent_name == 'ProcessOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'ProcessOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
raise Exception('Intent with name ' + intent_name + ' not supported')
def prompt_bedrock(formatted_template):
logger.debug('prompt bedrock input is:'.format(formatted_template))
body = json.loads(formatted_template)
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_completion = response_body.get('completion')
logger.debug('response is: {}'.format(response_completion))
#print_ww(response_body.get('completion'))
#print(response_body.get('results')[0].get('outputText'))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_response(response_completion):
if '<Response>' in response_completion:
customer_response = response_completion.replace('<Response>','||').replace('</Response>','').split('||')[1]
logger.debug('modified response is: {}'.format(response_completion))
return customer_response
else:
logger.debug('modified response is: {}'.format(response_completion))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_intent(response_completion):
if '<intent>' in response_completion:
customer_intent = response_completion.replace('<intent>','||').replace('</intent>','||').split('||')[1]
return customer_intent
else:
return customer_intent
def close(session_attributes, intent, fulfillment_state, action_type, message):
#This function prepares the response in the appropiate format for Lex V2
response = {
"sessionState": {
"sessionAttributes":session_attributes,
"dialogAction": {
"type": action_type
},
"intent": {
"name":intent,
"state":fulfillment_state
},
},
"messages":
[{
"contentType":"PlainText",
"content":message,
}]
,
}
return response
- Adjunte la capa Lambda que creó anteriormente a esta función.
- Además, adjunte la capa a las plantillas de mensajes que creó.
- En la función de ejecución de Lambda, adjunte la política para acceder a Amazon Bedrock, que se creó anteriormente.

La función de ejecución de Lambda debe tener los siguientes permisos.

Adjunte la función Orchestration Lambda al bot de Amazon Lex
- Después de crear la función en la sección anterior, regrese a la consola de Amazon Lex y navegue hasta su bot.
- under Idiomas en el panel de navegación, elija Inglés.
- Fuente, elige tu robot de procesamiento de pedidos.
- Versión o alias de la función Lambda, escoger $ ÚLTIMO.
- Elige Guardar.

Crear funciones Lambda de asistencia
Complete los siguientes pasos para crear funciones Lambda adicionales:
- Cree una función Lambda para consultar la tabla de DynamoDB que creó anteriormente:
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# Initialize the DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('your-table-name')
def calculate_grand_total(input_data):
# Initialize the total price
total_price = 0
try:
# Loop through each item in the input JSON
for item_id, item_data in input_data.items():
item_name = item_data['item'].lower() # Convert item name to lowercase
item_size = item_data['size'].lower() # Convert item size to lowercase
# Query the DynamoDB table for the item based on Item and Size
response = table.get_item(
Key={'Item': item_name,
'Size': item_size}
)
# Check if the item was found in the table
if 'Item' in response:
item = response['Item']
price = float(item['Price'])
total_price += price # Add the item's price to the total
return total_price
except Exception as e:
raise Exception('An error occurred: {}'.format(str(e)))
def lambda_handler(event, context):
try:
# Parse the input JSON from the Lambda event
input_json = json.loads(event)
# Calculate the grand total
grand_total = calculate_grand_total(input_json)
# Return the grand total in the response
return {'statusCode': 200,'body': json.dumps(grand_total)}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps('An error occurred: {}'.format(str(e)))
- Navegue hasta la Configuración pestaña en la función Lambda y elija Permisos.
- Adjunte una declaración de política basada en recursos que permita a la función Lambda de procesamiento de pedidos invocar esta función.
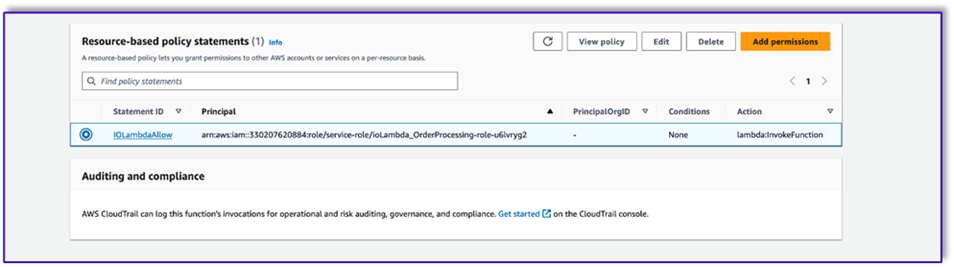
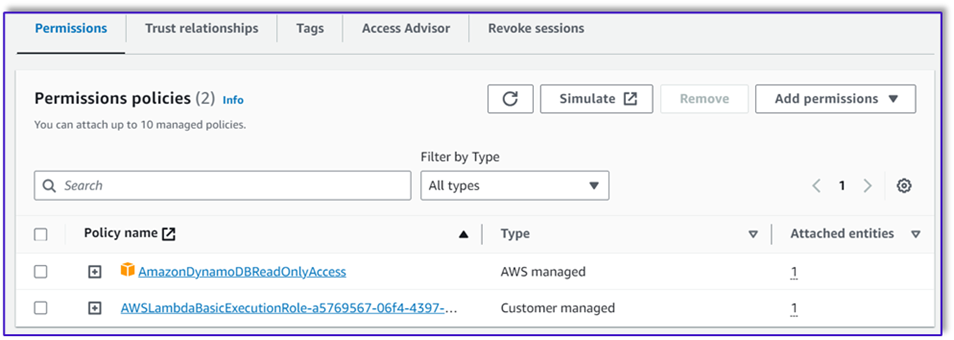
- Navegue hasta la función de ejecución de IAM para esta función Lambda y agregue una política para acceder a la tabla de DynamoDB.
- Cree otra función Lambda para validar si el cliente pasó todos los atributos requeridos. En el siguiente ejemplo, validamos si el atributo de tamaño se captura para un pedido:
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def lambda_handler(event, context):
# Define customer orders from the input event
customer_orders = json.loads(event)
# Initialize a list to collect error messages
order_errors = {}
missing_size = []
error_messages = []
# Iterate through each order in customer_orders
for order_id, order in customer_orders.items():
if "size" not in order or order["size"] == "":
missing_size.append(order['item'])
order_errors['size'] = missing_size
if order_errors:
items_missing_size = order_errors['size']
error_message = f"could you please provide the size for the following items: {', '.join(items_missing_size)}?"
error_messages.append(error_message)
# Prepare the response message
if error_messages:
response_message = "n".join(error_messages)
return {
'statusCode': 205,
'validator_response': response_message
}
else:
response_message = "Order is validated successfully"
return {
'statusCode': 200,
'validator_response': response_message
}
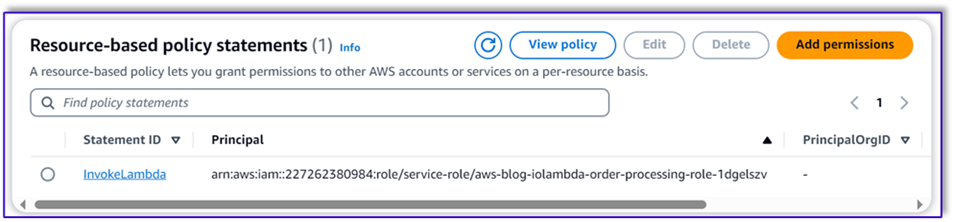
- Navegue hasta la Configuración pestaña en la función Lambda y elija Permisos.
- Adjunte una declaración de política basada en recursos que permita a la función Lambda de procesamiento de pedidos invocar esta función.
Prueba la solución
Ahora podemos probar la solución con pedidos de ejemplo que los clientes realizan a través de Amazon Lex.
En nuestro primer ejemplo, el cliente pidió un frappuccino, que no está en el menú. El modelo se valida con la ayuda de la plantilla del validador de pedidos y sugiere algunas recomendaciones basadas en el menú. Después de que el cliente confirma su pedido, se le notifica el total y el resumen del pedido. El pedido se procesará en base a la confirmación final del cliente.
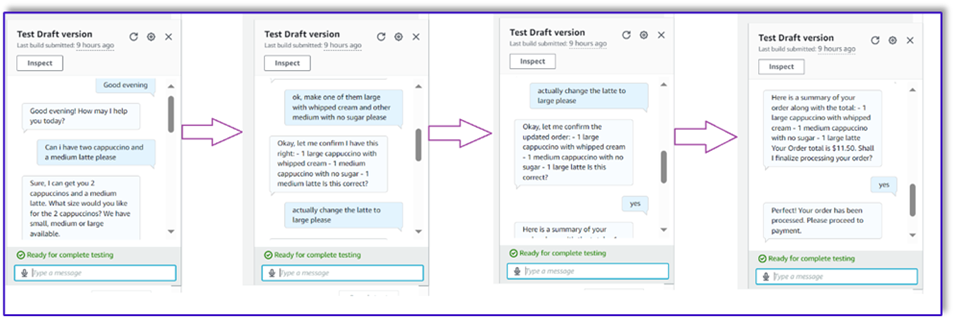
En nuestro siguiente ejemplo, el cliente pide un capuchino grande y luego modifica el tamaño de grande a mediano. El modelo captura todos los cambios necesarios y solicita al cliente que confirme el pedido. El modelo presenta el total del pedido y el resumen del pedido, y procesa el pedido en función de la confirmación final del cliente.

Para nuestro ejemplo final, el cliente realizó un pedido de varios artículos y falta la talla de un par de artículos. El modelo y la función Lambda verificarán si todos los atributos requeridos están presentes para procesar el pedido y luego le pedirán al cliente que proporcione la información faltante. Después de que el cliente proporciona la información que falta (en este caso, el tamaño del café), se le muestra el total y el resumen del pedido. El pedido se procesará en base a la confirmación final del cliente.
Limitaciones del LLM
Los resultados de nuestro LLM son estocásticos por naturaleza, lo que significa que los resultados de nuestro LLM pueden variar en formato, o incluso en forma de contenido falso (alucinaciones). Por lo tanto, los desarrolladores deben confiar en una buena lógica de manejo de errores en todo su código para poder manejar estos escenarios y evitar una experiencia degradada para el usuario final.
Limpiar
Si ya no necesita esta solución, puede eliminar los siguientes recursos:
- Funciones lambda
- Caja Amazon Lex
- Tabla DynamoDB
- Cucharón S3
Además, cierre la instancia de SageMaker Studio si la aplicación ya no es necesaria.
Evaluación de costos
Para obtener información sobre los precios de los principales servicios utilizados por esta solución, consulte lo siguiente:
Tenga en cuenta que puede utilizar Claude v2 sin necesidad de aprovisionamiento, por lo que los costos generales siguen siendo mínimos. Para reducir aún más los costos, puede configurar la tabla de DynamoDB con la configuración bajo demanda.
Conclusión
Esta publicación demostró cómo crear un agente de procesamiento de pedidos de IA con capacidad de voz utilizando Amazon Lex, Amazon Bedrock y otros servicios de AWS. Mostramos cómo la ingeniería rápida con un potente modelo de IA generativa como Claude puede permitir una comprensión sólida del lenguaje natural y flujos de conversación para el procesamiento de pedidos sin la necesidad de datos de capacitación extensos.
La arquitectura de la solución utiliza componentes sin servidor como Lambda, Amazon S3 y DynamoDB para permitir una implementación flexible y escalable. Almacenar las plantillas de mensajes en Amazon S3 le permite personalizar la solución para diferentes casos de uso.
Los próximos pasos podrían incluir ampliar las capacidades del agente para manejar una gama más amplia de solicitudes de clientes y casos extremos. Las plantillas de avisos proporcionan una manera de mejorar de forma iterativa las habilidades del agente. Las personalizaciones adicionales podrían implicar la integración de los datos del pedido con sistemas backend como inventario, CRM o POS. Por último, el agente podría estar disponible en varios puntos de contacto con el cliente, como aplicaciones móviles, autoservicio, quioscos y más, utilizando las capacidades multicanal de Amazon Lex.
Para obtener más información, consulte los siguientes recursos relacionados:
- Implementación y gestión de bots multicanal:
- Ingeniería rápida para Claude y otros modelos:
- Patrones arquitectónicos sin servidor para asistentes de IA escalables:
Acerca de los autores
 Moumita Dutta es arquitecto de soluciones asociado en Amazon Web Services. En su función, colabora estrechamente con socios para desarrollar activos escalables y reutilizables que agilicen las implementaciones en la nube y mejoren la eficiencia operativa. Es miembro de la comunidad AI/ML y experta en AI generativa en AWS. En su tiempo libre le gusta la jardinería y el ciclismo.
Moumita Dutta es arquitecto de soluciones asociado en Amazon Web Services. En su función, colabora estrechamente con socios para desarrollar activos escalables y reutilizables que agilicen las implementaciones en la nube y mejoren la eficiencia operativa. Es miembro de la comunidad AI/ML y experta en AI generativa en AWS. En su tiempo libre le gusta la jardinería y el ciclismo.
 Fernando Lammoglia es arquitecto de soluciones de socios en Amazon Web Services y trabaja en estrecha colaboración con socios de AWS para encabezar el desarrollo y la adopción de soluciones de inteligencia artificial de vanguardia en todas las unidades de negocios. Un líder estratégico con experiencia en arquitectura de nube, IA generativa, aprendizaje automático y análisis de datos. Se especializa en ejecutar estrategias de comercialización y ofrecer soluciones de IA impactantes alineadas con los objetivos organizacionales. En su tiempo libre le encanta pasar tiempo con su familia y viajar a otros países.
Fernando Lammoglia es arquitecto de soluciones de socios en Amazon Web Services y trabaja en estrecha colaboración con socios de AWS para encabezar el desarrollo y la adopción de soluciones de inteligencia artificial de vanguardia en todas las unidades de negocios. Un líder estratégico con experiencia en arquitectura de nube, IA generativa, aprendizaje automático y análisis de datos. Se especializa en ejecutar estrategias de comercialización y ofrecer soluciones de IA impactantes alineadas con los objetivos organizacionales. En su tiempo libre le encanta pasar tiempo con su familia y viajar a otros países.
 Mitul Patel es arquitecto senior de soluciones en Amazon Web Services. En su función como habilitador de tecnología en la nube, trabaja con los clientes para comprender sus objetivos y desafíos, y brinda orientación prescriptiva para lograr su objetivo con las ofertas de AWS. Es miembro de la comunidad AI/ML y embajador de AI generativa en AWS. En su tiempo libre le gusta hacer senderismo y jugar fútbol.
Mitul Patel es arquitecto senior de soluciones en Amazon Web Services. En su función como habilitador de tecnología en la nube, trabaja con los clientes para comprender sus objetivos y desafíos, y brinda orientación prescriptiva para lograr su objetivo con las ofertas de AWS. Es miembro de la comunidad AI/ML y embajador de AI generativa en AWS. En su tiempo libre le gusta hacer senderismo y jugar fútbol.

