
“Más vale prevenir que curar”, dice el viejo refrán, que nos recuerda que es más fácil evitar que algo suceda en primer lugar que reparar el daño una vez ocurrido.
En la era de la inteligencia artificial (IA), este proverbio subraya la importancia de evitar posibles errores, como el sobreajuste, mediante técnicas como la regularización.
En este artículo, descubriremos la regularización comenzando con sus principios fundamentales para su aplicación utilizando Sci-kit Learn (aprendizaje automático) y Tensorflow (aprendizaje profundo) y seremos testigos de su poder transformador con conjuntos de datos del mundo real al comparar estos resultados. ¡Empecemos!
La regularización es un concepto crítico en el aprendizaje automático y el aprendizaje profundo que tiene como objetivo evitar el sobreajuste de los modelos.
El sobreajuste ocurre cuando un modelo aprende demasiado bien los datos de entrenamiento. La situación muestra que su modelo es demasiado bueno para ser verdad.
Veamos cómo se ve el sobreajuste.
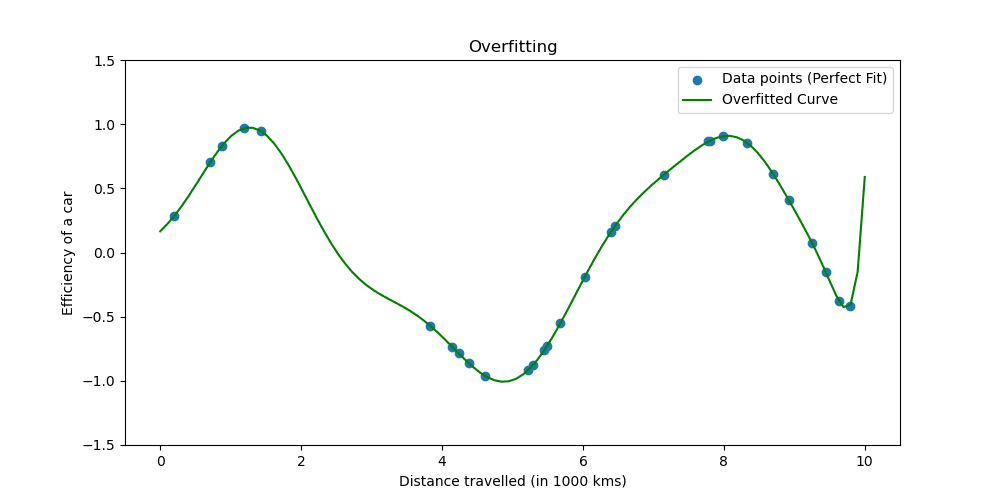
Las técnicas de regularización ajustan el proceso de aprendizaje para simplificar el modelo, asegurando que funcione bien con los datos de entrenamiento y se generalice bien a datos nuevos. Exploraremos dos formas bien conocidas de hacer esto.
En el aprendizaje automático, la regularización se aplica a menudo a modelos lineales, como la regresión lineal y logística. En este contexto, las formas de regularización más comunes son:
- Regularización L1 (regresión Lasso)
- Regularización L2 (regresión de crestas)
Regularización de lazo Alienta al modelo a utilizar solo las características más esenciales al permitir que algunos valores de coeficientes sean exactamente cero, lo que puede ser particularmente útil para la selección de características.


Por otra parte, Regularización de crestas desalienta los coeficientes significativos penalizando el cuadrado de sus valores.

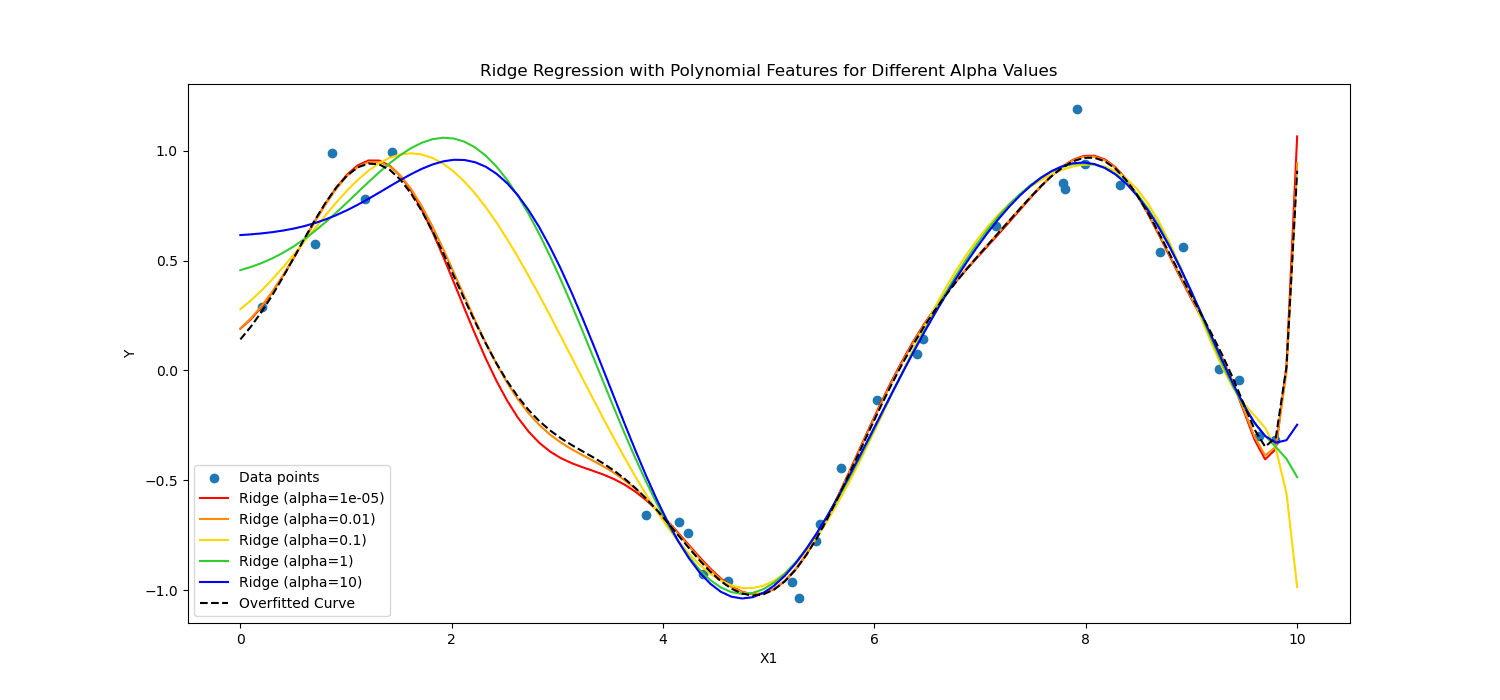
En resumen, calcularon de manera diferente.
Apliquemos esto a los datos del paciente cardíaco para ver su poder en el aprendizaje profundo y el aprendizaje automático.
Ahora, aplicaremos la regularización para analizar los datos de pacientes cardíacos y ver el poder de la regularización. Puede acceder al conjunto de datos desde esta página.
Para aplicar el aprendizaje automático, usaremos Scikit-learn; Para aplicar el aprendizaje profundo, usaremos TensorFlow. ¡Empecemos!
Regularización en Machine Learning
Scikit-learn es uno de los más populares Bibliotecas de Python para aprendizaje automático que proporciona herramientas de modelado y análisis de datos simples y eficientes.
Incluye implementaciones de varias técnicas de regularización, particularmente para modelos lineales.
Aquí, exploraremos cómo aplicar la regularización L1 (Lazo) y L2 (Ridge).
En el siguiente código, entrenaremos la regresión logística utilizando técnicas de regularización Ridge (L2) y Lasso (L1). Al final veremos el informe detallado. Veamos el código.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Aquí está la salida.
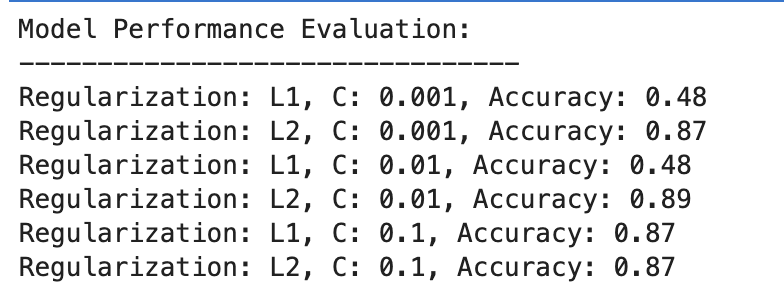
Evaluemos el resultado.
Regularización L1
- Con C=0.001, la precisión es notablemente baja (48%). Esto demuestra que el modelo no se ajusta lo suficiente. Muestra demasiada regularización.
- A medida que C aumenta a 0.01, la precisión permanece sin cambios para L1, lo que sugiere que el modelo todavía sufre de un ajuste insuficiente o que la regularización es demasiado fuerte.
- Con C = 0.1, la precisión mejora significativamente hasta el 87 %, lo que demuestra que reducir la fuerza de la regularización permite que el modelo aprenda mejor de los datos.
Regularización L2
En general, la regularización L2 funciona consistentemente bien, con una precisión del 87% para C=0.001 y ligeramente superior al 89% para C=0.01, y luego se estabiliza en el 87% para C=0.1.
Esto sugiere que la regularización L2 es generalmente más indulgente y efectiva para este conjunto de datos en modelos de regresión logística, potencialmente debido a su naturaleza.
Regularización en aprendizaje profundo
Se utilizan varias técnicas de regularización en el aprendizaje profundo, incluida la regularización, el abandono y la parada anticipada L1 (Lasso) y L2 (Ridge).
En este, para repetir lo que hicimos antes en el ejemplo de aprendizaje automático, aplicaremos la regularización L1 y L2. Esta vez definamos una lista de valores de regularización L1 y L2.
Luego, para todos estos valores, entrenaremos y evaluaremos nuestro modelo de aprendizaje profundo y, al final, evaluaremos los resultados.
Veamos el código.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Aquí está la salida.
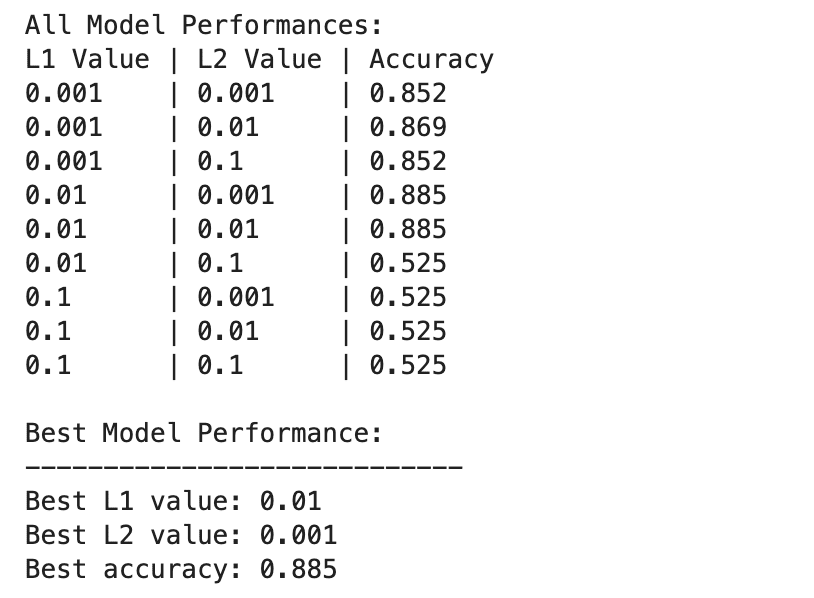
El rendimiento del modelo de aprendizaje profundo varía más ampliamente entre diferentes combinaciones de valores de regularización L1 y L2.
El mejor rendimiento se observa en L1=0.01 y L2=0.001, con una precisión del 88.5%, lo que indica una regularización equilibrada que evita el sobreajuste y al mismo tiempo permite que el modelo capture los patrones subyacentes en los datos.
Los valores de regularización más altos, especialmente en L1=0.1 o L2=0.1, reducen drásticamente la precisión del modelo al 52.5%, lo que sugiere que demasiada regularización limita severamente la capacidad de aprendizaje del modelo.
Aprendizaje automático y aprendizaje profundo en la regularización
Comparemos los resultados entre Machine Learning y Deep Learning.
Efectividad de la Regularización: Tanto en contextos de aprendizaje automático como de aprendizaje profundo, la regularización adecuada ayuda a mitigar el sobreajuste, pero una regularización excesiva conduce a un ajuste insuficiente. La fuerza de regularización óptima varía, y los modelos de aprendizaje profundo potencialmente requieren un equilibrio más matizado debido a su mayor complejidad.
Actuación: El modelo de aprendizaje automático de mejor rendimiento (L2 con C=0.01, 89 % de precisión) y el modelo de aprendizaje profundo de mejor rendimiento (L1=0.01, L2=0.001, 88.5 % de precisión) logran precisiones comparables, lo que demuestra que ambos enfoques pueden ser eficaces. regularizado para lograr un alto rendimiento en este conjunto de datos.
Estrategia de Regularización: La regularización L2 parece ser más efectiva y menos sensible a la elección de C en los modelos de regresión logística, mientras que una combinación de regularización L1 y L2 proporciona el mejor resultado en el aprendizaje profundo, ofreciendo un equilibrio entre la selección de características y la penalización de peso.
La elección y la fuerza de la regularización deben ajustarse cuidadosamente para equilibrar la complejidad del aprendizaje con el riesgo de sobreadaptación o desadaptación.
A lo largo de esta exploración, hemos desmitificado la regularización, mostrando su papel en la prevención del sobreajuste y garantizando que nuestros modelos se generalicen bien a datos invisibles.
La aplicación de técnicas de regularización lo acercará a la competencia en aprendizaje automático y aprendizaje profundo, solidificando su conjunto de herramientas de científico de datos.
Vaya a los proyectos de datos e intente regularizar sus datos en diferentes escenarios, como Predicción de la duración de la entrega. Utilizamos modelos de aprendizaje automático y aprendizaje profundo en este proyecto de datos. Sin embargo, al final también mencionamos que podría haber margen de mejora. Entonces, ¿por qué no intentas la regularización allí y ves si te ayuda?
Nate Rosidi es científico de datos y en estrategia de producto. También es profesor adjunto de enseñanza de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Gorjeo: StrataScratch or Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

