Esta es una publicación invitada coescrita con Brandon Abear, Dinesh Sharma, John Bush y Ozcan IIikhan de GoDaddy.
Ve papi empodera a los emprendedores cotidianos brindándoles toda la ayuda y herramientas para tener éxito en línea. Con más de 20 millones de clientes en todo el mundo, GoDaddy es el lugar al que acuden las personas para poner nombre a sus ideas, crear un sitio web profesional, atraer clientes y gestionar su trabajo.
En GoDaddy, estamos orgullosos de ser una empresa basada en datos. Nuestra búsqueda incesante de información valiosa a partir de los datos impulsa nuestras decisiones comerciales y garantiza la satisfacción del cliente. Nuestro compromiso con la eficiencia es inquebrantable y hemos emprendido una interesante iniciativa para optimizar nuestros trabajos de procesamiento por lotes. En este viaje, hemos identificado un enfoque estructurado al que nos referimos como las siete capas de oportunidades de mejora. Esta metodología se ha convertido en nuestra guía en la búsqueda de la eficiencia.
En esta publicación, analizamos cómo mejoramos la eficiencia operativa con Amazon EMR sin servidor. Compartimos nuestros resultados y metodología de evaluación comparativa, y conocimientos sobre la rentabilidad de EMR Serverless frente a la capacidad fija. Amazon EMR en EC2 Clústeres transitorios en nuestros flujos de trabajo de datos orquestados utilizando Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA). Compartimos nuestra estrategia para la adopción de EMR Serverless en áreas donde sobresale. Nuestros hallazgos revelan beneficios significativos, que incluyen una reducción de costos de más del 60 %, cargas de trabajo Spark un 50 % más rápidas, una notable mejora cinco veces mayor en la velocidad de desarrollo y pruebas, y una reducción significativa de nuestra huella de carbono.
Antecedentes
A finales de 2020, la plataforma de datos de GoDaddy inició su viaje a la nube de AWS, migrando un clúster Hadoop de 800 nodos con 2.5 PB de datos desde su centro de datos a EMR en EC2. Este enfoque de elevación y cambio facilitó una comparación directa entre los entornos locales y de nube, lo que garantizó una transición sin problemas a los canales de AWS y minimizó los problemas de validación de datos y los retrasos en la migración.
A principios de 2022, migramos con éxito nuestras cargas de trabajo de big data a EMR en EC2. Utilizando las mejores prácticas aprendidas del programa AWS FinHack, ajustamos los trabajos que consumen muchos recursos, convertimos los trabajos de Pig y Hive a Spark y redujimos nuestro gasto en cargas de trabajo por lotes en un 22.75 % en 2022. Sin embargo, surgieron desafíos de escalabilidad debido a la multitud de trabajos. . Esto impulsó a GoDaddy a embarcarse en un viaje de optimización sistemática, estableciendo una base para un procesamiento de big data más sostenible y eficiente.
Siete capas de oportunidades de mejora
En nuestra búsqueda de eficiencia operativa, hemos identificado siete capas distintas de oportunidades de optimización dentro de nuestros trabajos de procesamiento por lotes, como se muestra en la siguiente figura. Estas capas van desde mejoras precisas a nivel de código hasta mejoras más completas de la plataforma. Este enfoque de múltiples niveles se ha convertido en nuestro plan estratégico en la búsqueda continua de un mejor desempeño y una mayor eficiencia.

Las capas son las siguientes:
- Optimización de código – Se centra en refinar la lógica del código y cómo se puede optimizar para obtener un mejor rendimiento. Esto implica mejoras de rendimiento mediante almacenamiento en caché selectivo, poda de proyecciones y particiones, optimizaciones de unión y otros ajustes específicos del trabajo. El uso de soluciones de codificación de IA también es una parte integral de este proceso.
- Actualizaciones de software - Actualización a las últimas versiones de software de código abierto (OSS) para aprovechar nuevas funciones y mejoras. Por ejemplo, la ejecución adaptable de consultas en Spark 3 aporta importantes mejoras de rendimiento y costos.
- Configuraciones personalizadas de Spark – Ajuste de configuraciones personalizadas de Spark para maximizar la utilización de recursos, la memoria y el paralelismo. Podemos lograr mejoras significativas ajustando el tamaño de las tareas, como por ejemplo a través de
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.coresyspark.executor.memory. Sin embargo, estas configuraciones personalizadas pueden resultar contraproducentes si no son compatibles con la versión específica de Spark. - Tiempo de aprovisionamiento de recursos – El tiempo que lleva lanzar recursos como grupos efímeros de EMR en Nube informática elástica de Amazon (Amazon EC2). Aunque algunos factores que influyen en este tiempo están fuera del control de un ingeniero, identificar y abordar los factores que se pueden optimizar puede ayudar a reducir el tiempo general de aprovisionamiento.
- Escalado detallado a nivel de tarea – Ajustar dinámicamente recursos como CPU, memoria, disco y ancho de banda de red según las necesidades de cada etapa dentro de una tarea. El objetivo aquí es evitar tamaños de conglomerados fijos que podrían resultar en un desperdicio de recursos.
- Escalado detallado en múltiples tareas en un flujo de trabajo – Dado que cada tarea tiene requisitos de recursos únicos, mantener un tamaño de recursos fijo puede resultar en un aprovisionamiento insuficiente o excesivo para ciertas tareas dentro del mismo flujo de trabajo. Tradicionalmente, el tamaño de la tarea más grande determina el tamaño del clúster para un flujo de trabajo multitarea. Sin embargo, ajustar dinámicamente los recursos en múltiples tareas y pasos dentro de un flujo de trabajo da como resultado una implementación más rentable.
- Mejoras a nivel de plataforma – Las mejoras en las capas anteriores solo pueden optimizar un trabajo o flujo de trabajo determinado. La mejora de la plataforma tiene como objetivo alcanzar la eficiencia a nivel de empresa. Podemos lograr esto a través de varios medios, como actualizar o mejorar la infraestructura central, introducir nuevos marcos, asignar recursos apropiados para cada perfil de trabajo, equilibrar el uso del servicio, optimizar el uso de Planes de Ahorro e Instancias Spot, o implementar otros cambios integrales para impulsar eficiencia en todas las tareas y flujos de trabajo.
Capas 1 a 3: reducciones de costos anteriores
Después de migrar de las instalaciones a la nube de AWS, centramos principalmente nuestros esfuerzos de optimización de costos en las primeras tres capas que se muestran en el diagrama. Al realizar la transición de nuestras canalizaciones Pig y Hive heredadas más costosas a Spark y optimizar las configuraciones de Spark para Amazon EMR, logramos importantes ahorros de costos.
Por ejemplo, un trabajo antiguo de Pig tardó 10 horas en completarse y se ubicó entre los 10 trabajos de EMR más caros. Al revisar los registros de TEZ y las métricas del clúster, descubrimos que el clúster estaba muy sobreaprovisionado para el volumen de datos que se estaba procesando y permaneció infrautilizado durante la mayor parte del tiempo de ejecución. La transición de Pig a Spark fue más eficiente. Aunque no había herramientas automatizadas disponibles para la conversión, se realizaron optimizaciones manuales, que incluyen:
- Reducción de escrituras innecesarias en disco, ahorrando tiempo de serialización y deserialización (Capa 1)
- Se reemplazó la paralelización de tareas de Airflow con Spark, simplificando el Airflow DAG (Capa 1)
- Se eliminaron transformaciones de Spark redundantes (Capa 1)
- Actualizado de Spark 2 a 3, usando Adaptive Query Execution (Capa 2)
- Se solucionaron uniones sesgadas y tablas de dimensiones más pequeñas optimizadas (Capa 3)
Como resultado, el costo del trabajo disminuyó en un 95 % y el tiempo de finalización del trabajo se redujo a 1 hora. Sin embargo, este enfoque requería mucha mano de obra y no era escalable para numerosos trabajos.
Capas 4 a 6: encontrar y adoptar la solución informática adecuada
A finales de 2022, tras nuestros importantes logros en optimización en los niveles anteriores, nuestra atención se centró en mejorar las capas restantes.
Comprender el estado de nuestro procesamiento por lotes
Usamos Amazon MWAA para organizar nuestros flujos de trabajo de datos en la nube a escala. Flujo de aire Apache es una herramienta de código abierto que se utiliza para crear, programar y monitorear mediante programación secuencias de procesos y tareas denominadas flujos de trabajo. En esta publicación, los términos flujo de trabajo y trabajo se usan indistintamente y se refieren a los gráficos acíclicos dirigidos (DAG) que consisten en tareas orquestadas por Amazon MWAA. Para cada flujo de trabajo, tenemos tareas secuenciales o paralelas, e incluso una combinación de ambas en el DAG entre create_emr y terminate_emr tareas que se ejecutan en un clúster EMR transitorio con capacidad informática fija durante toda la ejecución del flujo de trabajo. Incluso después de optimizar una parte de nuestra carga de trabajo, todavía teníamos numerosos flujos de trabajo no optimizados que estaban infrautilizados debido al aprovisionamiento excesivo de recursos informáticos basados en la tarea con mayor uso de recursos del flujo de trabajo, como se muestra en la siguiente figura.
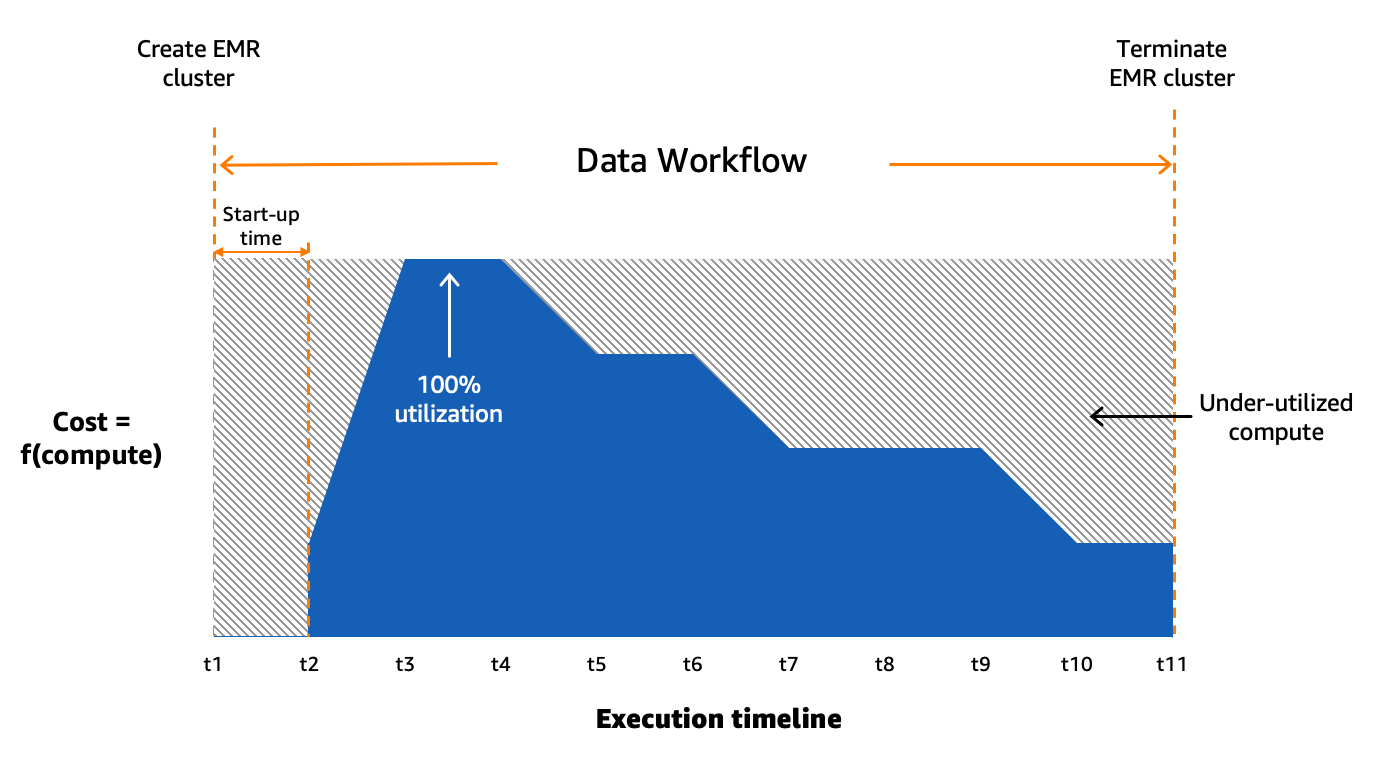
Esto destacó la impracticabilidad de la asignación estática de recursos y nos llevó a reconocer la necesidad de un sistema de asignación dinámica de recursos (DRA). Antes de proponer una solución, recopilamos una gran cantidad de datos para comprender a fondo nuestro procesamiento por lotes. El análisis del tiempo de paso del clúster, excluyendo el aprovisionamiento y el tiempo de inactividad, reveló información importante: una distribución sesgada hacia la derecha con más de la mitad de los flujos de trabajo que se completan en 20 minutos o menos y solo el 10 % tarda más de 60 minutos. Esta distribución guió nuestra elección de una solución informática de aprovisionamiento rápido, lo que redujo drásticamente los tiempos de ejecución del flujo de trabajo. El siguiente diagrama ilustra los tiempos de los pasos (excluidos el aprovisionamiento y el tiempo de inactividad) de EMR en clústeres transitorios de EC2 en una de nuestras cuentas de procesamiento por lotes.
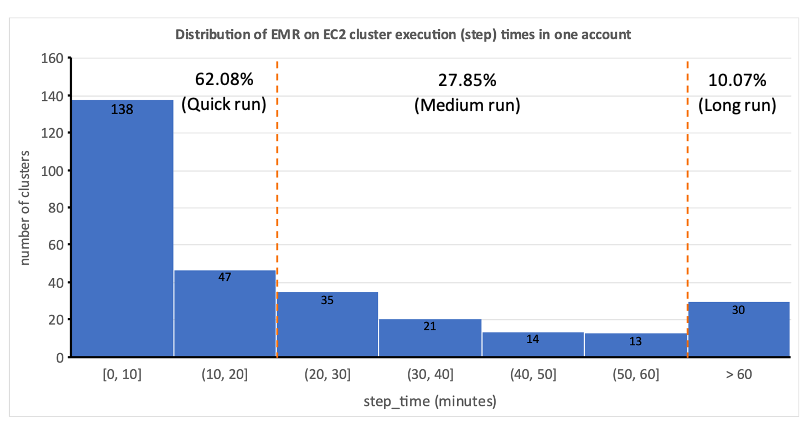
Además, según la distribución del tiempo de paso (excluyendo el aprovisionamiento y el tiempo de inactividad) de los flujos de trabajo, categorizamos nuestros flujos de trabajo en tres grupos:
- Carrera rapida – Dura 20 minutos o menos.
- plazo medio – Dura entre 20 y 60 minutos.
- Largo plazo – Más de 60 minutos, que a menudo abarcan varias horas o más
Otro factor que debíamos considerar era el uso extensivo de clústeres transitorios por razones tales como seguridad, aislamiento de trabajos y costos, y clústeres diseñados específicamente. Además, hubo una variación significativa en las necesidades de recursos entre las horas pico y los períodos de baja utilización.
En lugar de clústeres de tamaño fijo, podríamos utilizar el escalado administrado en EMR en EC2 para lograr algunos beneficios de costos. Sin embargo, migrar a EMR Serverless parece ser una dirección más estratégica para nuestra plataforma de datos. Además de los posibles beneficios de costos, EMR Serverless ofrece ventajas adicionales, como una actualización con un solo clic a las versiones más recientes de Amazon EMR, una experiencia operativa y de depuración simplificada y actualizaciones automáticas a las últimas generaciones tras la implementación. Estas características simplifican colectivamente el proceso de operar una plataforma a mayor escala.
Evaluación de EMR Serverless: un estudio de caso en GoDaddy
EMR Serverless es una opción sin servidor en Amazon EMR que elimina las complejidades de configurar, administrar y escalar clústeres cuando se ejecutan marcos de big data como Apache Spark y Apache Hive. Con EMR Serverless, las empresas pueden disfrutar de numerosos beneficios, incluida la rentabilidad, un aprovisionamiento más rápido, una experiencia de desarrollador simplificada y una mayor resistencia a las fallas de la zona de disponibilidad.
Reconociendo el potencial de EMR Serverless, realizamos un estudio comparativo en profundidad utilizando flujos de trabajo de producción reales. El estudio tuvo como objetivo evaluar el rendimiento y la eficiencia de EMR Serverless y al mismo tiempo crear un plan de adopción para una implementación a gran escala. Los hallazgos fueron muy alentadores y demostraron que EMR Serverless puede manejar eficazmente nuestras cargas de trabajo.
Metodología de evaluación comparativa
Dividimos nuestros flujos de trabajo de datos en tres categorías según el tiempo total del paso (excluyendo el aprovisionamiento y el tiempo de inactividad): ejecución rápida (0 a 20 minutos), ejecución media (20 a 60 minutos) y ejecución larga (más de 60 minutos). Analizamos el impacto del tipo de implementación de EMR (Amazon EC2 frente a EMR Serverless) en dos métricas clave: rentabilidad y aceleración total del tiempo de ejecución, que sirvieron como nuestro criterio de evaluación general. Aunque no medimos formalmente la facilidad de uso y la resiliencia, estos factores se consideraron durante todo el proceso de evaluación.
Los pasos de alto nivel para evaluar el medio ambiente son los siguientes:
- Prepare los datos y el entorno:
- Elija de tres a cinco trabajos de producción aleatorios de cada categoría de trabajo.
- Implementar los ajustes necesarios para evitar interferencias con la producción.
- Ejecutar pruebas:
- Ejecute scripts durante varios días o mediante múltiples iteraciones para recopilar puntos de datos precisos y consistentes.
- Realice pruebas utilizando EMR en EC2 y EMR Serverless.
- Validar datos y ejecutar pruebas:
- Valide conjuntos de datos de entrada y salida, particiones y recuentos de filas para garantizar un procesamiento de datos idéntico.
- Reúna métricas y analice resultados:
- Reúna métricas relevantes de las pruebas.
- Analizar los resultados para extraer ideas y conclusiones.
Resultados comparativos
Nuestros resultados de referencia mostraron mejoras significativas en las tres categorías de trabajo, tanto en términos de aceleración del tiempo de ejecución como de rentabilidad. Las mejoras fueron más pronunciadas en los trabajos rápidos, como resultado directo de tiempos de inicio más rápidos. Por ejemplo, un flujo de trabajo de datos de 20 minutos (incluido el aprovisionamiento y el apagado del clúster) que se ejecuta en un EMR en un clúster transitorio EC2 de capacidad informática fija finaliza en 10 minutos en EMR Serverless, lo que proporciona un tiempo de ejecución más corto con beneficios de costos. En general, el cambio a EMR Serverless generó mejoras sustanciales en el rendimiento y reducciones de costos a escala en todos los sectores laborales, como se ve en la siguiente figura.
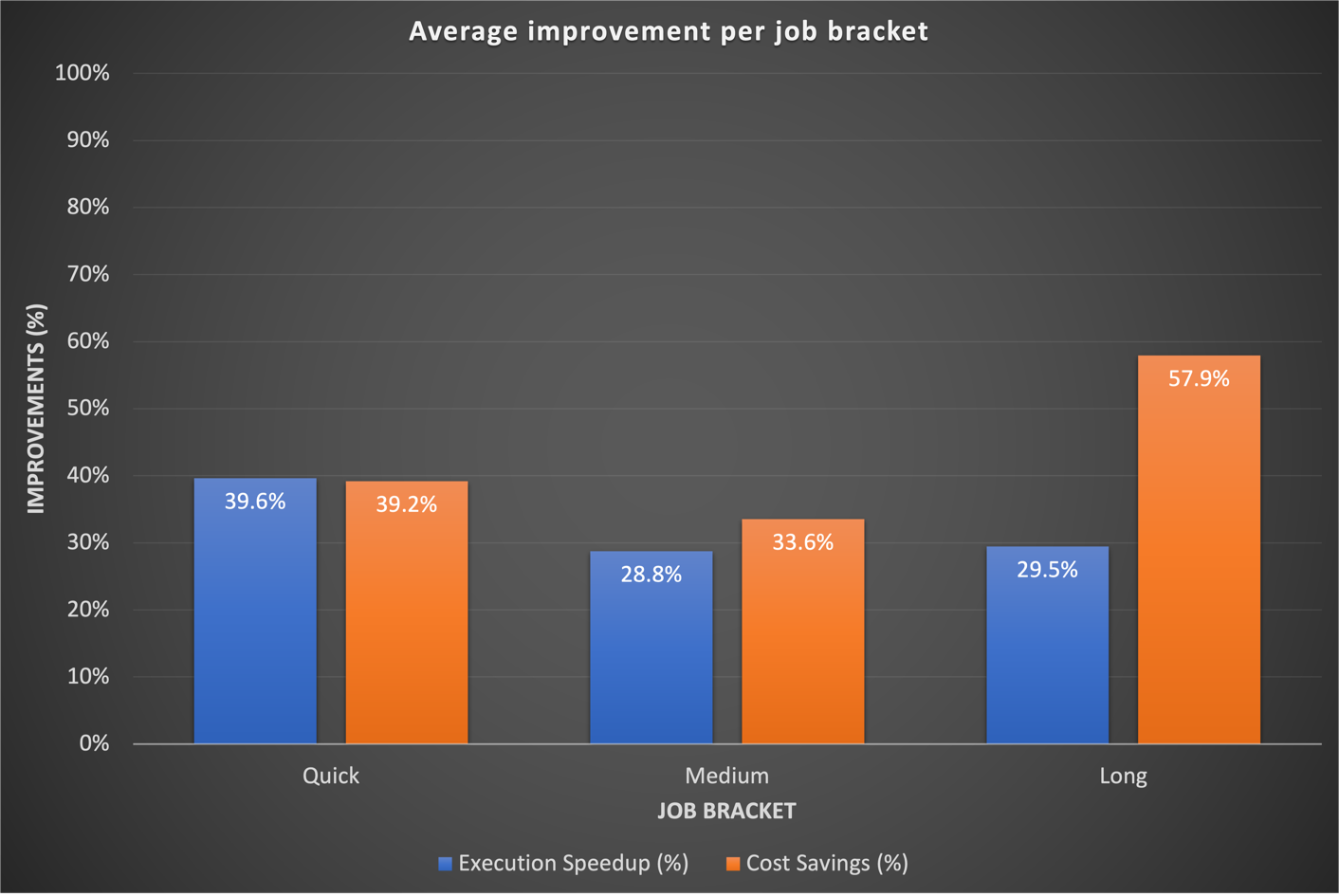
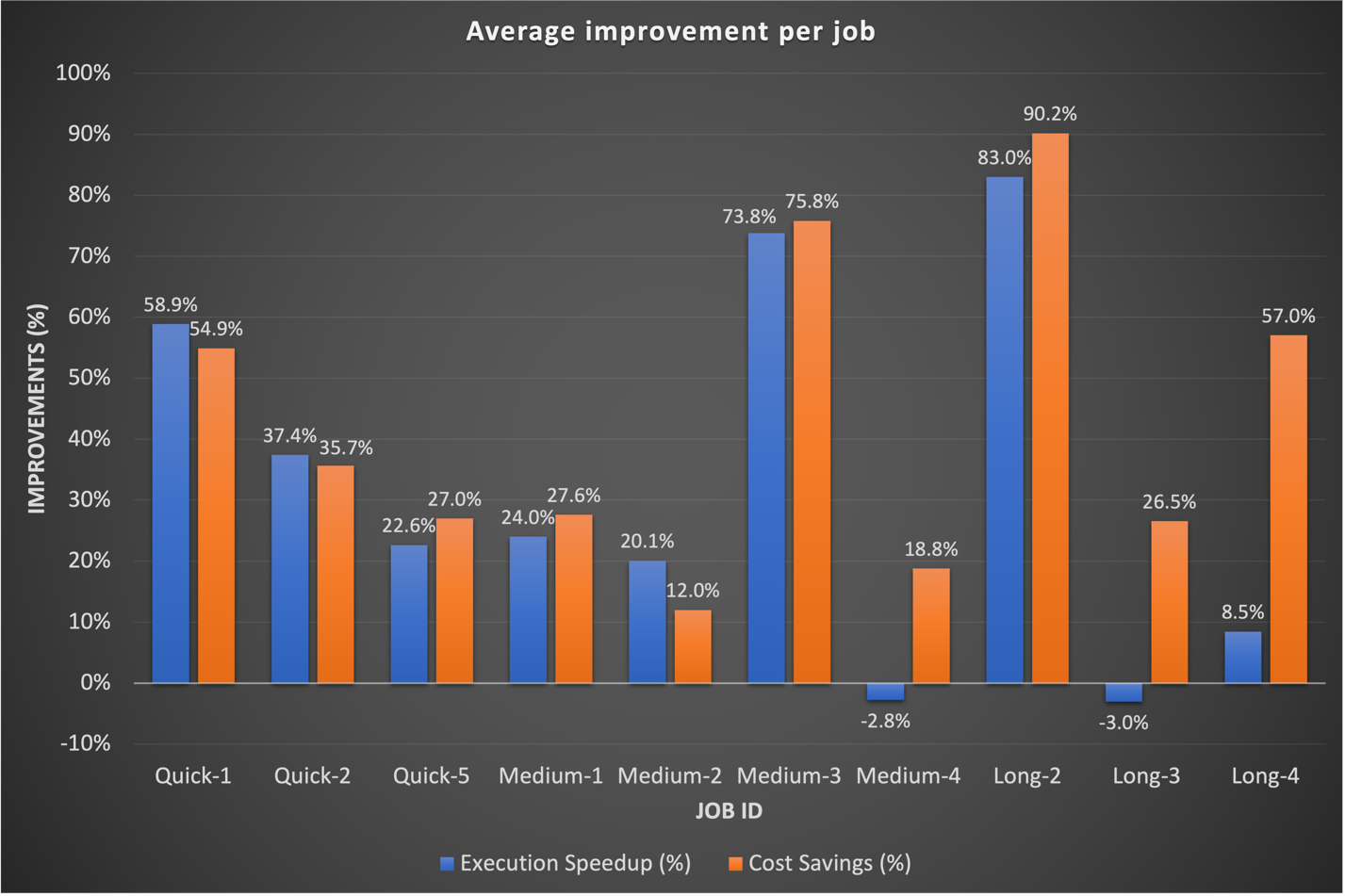
Históricamente, dedicamos más tiempo a ajustar nuestros flujos de trabajo a largo plazo. Curiosamente, descubrimos que las configuraciones personalizadas de Spark existentes para estos trabajos no siempre se traducían bien en EMR Serverless. En los casos en que los resultados fueron insignificantes, un enfoque común fue descartar configuraciones anteriores de Spark relacionadas con los núcleos ejecutores. Al permitir que EMR Serverless administre de forma autónoma estas configuraciones de Spark, a menudo observamos mejores resultados. El siguiente gráfico muestra el tiempo de ejecución promedio y la mejora de costos por trabajo al comparar EMR Serverless con EMR en EC2.
La siguiente tabla muestra una comparación de muestra de los resultados para el mismo flujo de trabajo que se ejecuta en diferentes opciones de implementación de Amazon EMR (EMR en EC2 y EMR Serverless).
| Métricos | EMR en EC2 (Promedio) |
EMR sin servidor (Promedio) |
EMR en EC2 frente a EMR sin servidor |
| Costo total de ejecución ($) | $ 5.82 | $ 2.60 | 55% |
| Tiempo total de ejecución (minutos) | 53.40 | 39.40 | 26% |
| Tiempo de aprovisionamiento (minutos) | 10.20 | 0.05 | . |
| Costo de aprovisionamiento ($) | US$ 1.19 | . | . |
| Pasos Tiempo (Minutos) | 38.20 | 39.16 | - 3% |
| Costo de los pasos ($) | US$ 4.30 | . | . |
| Tiempo de inactividad (minutos) | 4.80 | . | . |
| Etiqueta de lanzamiento de EMR | emr-6.9.0 | . | |
| Distribución de Hadoop | Amazon 3.3.3 | . | |
| Versión chispa | Spark 3.3.0 | . | |
| Versión de Hive/HCatalog | Colmena 3.1.3, HCatalog 3.1.3 | . | |
| Tipo de contratación | Spark | . | |
AWS Graviton2 en la evaluación del rendimiento de EMR Serverless
Después de ver resultados convincentes con EMR Serverless para nuestras cargas de trabajo, decidimos analizar más a fondo el rendimiento del Gravitón2 de AWS (arm64) dentro de EMR Serverless. AWS tenía comparado Spark cargas de trabajo en Graviton2 EMR Serverless utilizando la escala TPC-DS de 3 TB, lo que muestra una mejora general de precio-rendimiento del 27 %.
Para comprender mejor los beneficios de la integración, realizamos nuestro propio estudio utilizando las cargas de trabajo de producción de GoDaddy en un cronograma diario y observamos una impresionante mejora de precio-rendimiento del 23.8 % en una variedad de trabajos al usar Graviton2. Para más detalles sobre este estudio, ver La evaluación comparativa de GoDaddy da como resultado una relación precio-rendimiento hasta un 24 % mejor para sus cargas de trabajo Spark con AWS Graviton2 en Amazon EMR Serverless.
Estrategia de adopción de EMR Serverless
Implementamos estratégicamente una implementación gradual de EMR Serverless a través de anillos de implementación, lo que permitió una integración sistemática. Este enfoque gradual nos permite validar las mejoras y detener una mayor adopción de EMR Serverless, si es necesario. Sirvió como red de seguridad para detectar problemas a tiempo y como medio para perfeccionar nuestra infraestructura. El proceso mitigó el impacto del cambio a través de operaciones fluidas y al mismo tiempo desarrolló la experiencia del equipo de nuestros equipos de Ingeniería de Datos y DevOps. Además, fomentó circuitos de retroalimentación estrechos, lo que permitió realizar ajustes rápidos y garantizar una integración eficiente de EMR Serverless.
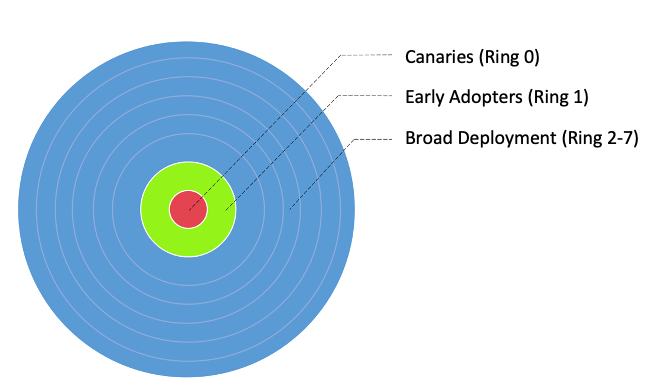
Dividimos nuestros flujos de trabajo en tres grupos de adopción principales, como se muestra en la siguiente imagen:
- Canarias – Este grupo ayuda a detectar y resolver cualquier problema potencial en las primeras etapas de la etapa de implementación.
- Los primeros en adoptar – Este es el segundo lote de flujos de trabajo que adoptan la nueva solución informática después de que el grupo canaries haya identificado y rectificado los problemas iniciales.
- Amplios anillos de despliegue – Este grupo, el grupo de anillos más grande, representa la implementación a gran escala de la solución. Estos se implementan después de pruebas e implementación exitosas en los dos grupos anteriores.
Además, dividimos estos flujos de trabajo en anillos de implementación granulares para adoptar EMR Serverless, como se muestra en la siguiente tabla.
| Anillo # | Nombre | Detalles |
| Anillo 0 | Canarios | Empleos de bajo riesgo de adopción que se espera que generen algunos beneficios de ahorro de costos. |
| Anillo 1 | Los primeros en adoptar | Trabajos Spark de ejecución rápida de bajo riesgo que esperan generar grandes ganancias. |
| Anillo 2 | Carrera rapida | Resto de la ejecución rápida (step_time <= 20 min) Trabajos Spark |
| Anillo 3 | Trabajos más grandes_EZ | Alto potencial de ganancia, fácil movimiento, trabajos Spark de mediano y largo plazo |
| Anillo 4 | Trabajos más grandes | Resto de empleos Spark a mediano y largo plazo con ganancias potenciales |
| Anillo 5 | Colmena | Trabajos de colmena con ahorros de costos potencialmente mayores |
| Anillo 6 | Desplazamiento al rojo_EZ | Migración sencilla: trabajos de Redshift que se adaptan a EMR Serverless |
| Anillo 7 | Pegamento_EZ | Migración sencilla Trabajos de pegamento que se adaptan a EMR Serverless |
Resumen de resultados de adopción de producción
Los alentadores resultados de la evaluación comparativa y la adopción canary generaron un interés considerable en una adopción más amplia de EMR Serverless en GoDaddy. Hasta la fecha, la implementación de EMR Serverless sigue en marcha. Hasta ahora, ha reducido los costos en un 62.5 % y ha acelerado la finalización del flujo de trabajo por lotes total en un 50.4 %.
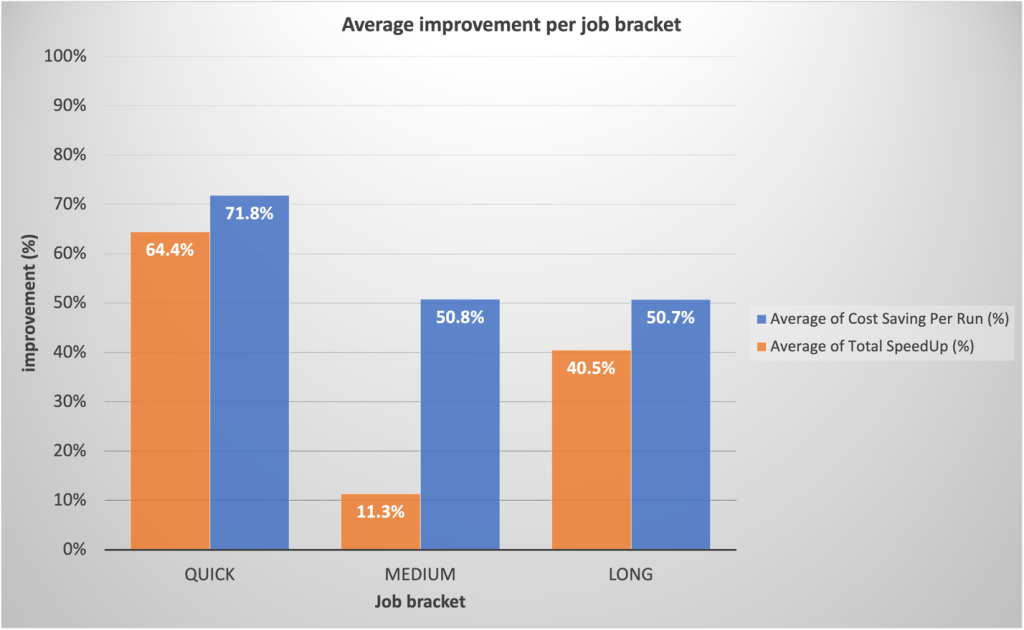
Según los puntos de referencia preliminares, nuestro equipo esperaba ganancias sustanciales para trabajos rápidos. Para nuestra sorpresa, los despliegues de producción reales superaron las proyecciones, con un promedio de 64.4% más rápido frente al 42% proyectado, y 71.8% más baratos frente al 40% previsto.
Sorprendentemente, los trabajos de larga duración también experimentaron mejoras significativas en el rendimiento debido al rápido aprovisionamiento de EMR Serverless y al escalamiento agresivo permitido por la asignación dinámica de recursos. Observamos una paralelización sustancial durante los segmentos de altos recursos, lo que resultó en un tiempo de ejecución total un 40.5 % más rápido en comparación con los enfoques tradicionales. El siguiente cuadro ilustra las mejoras promedio por categoría laboral.
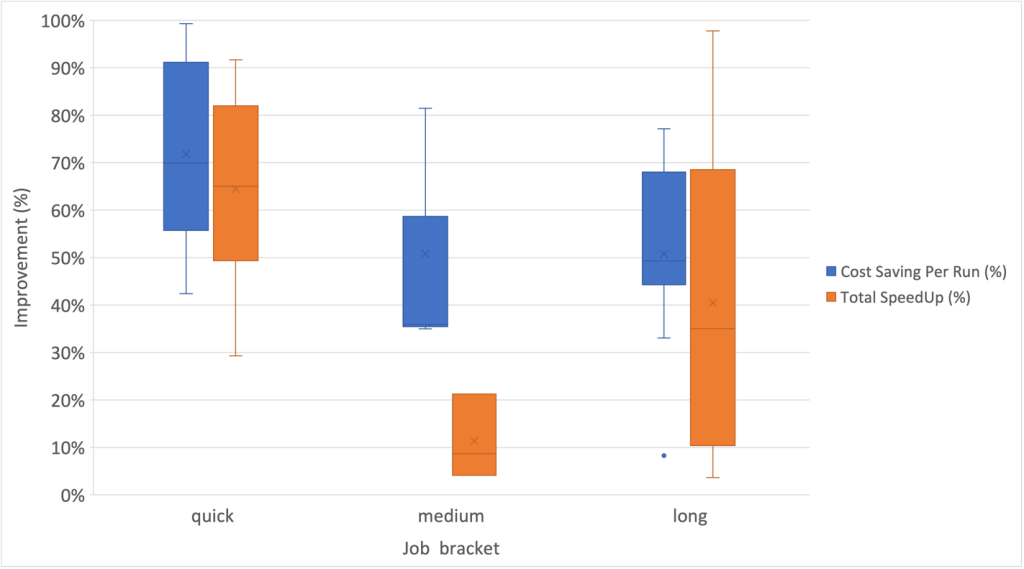
Además, observamos el mayor grado de dispersión en las mejoras de velocidad dentro de la categoría laboral a largo plazo, como se muestra en el siguiente diagrama de caja y bigotes.
Flujos de trabajo de muestra adoptados EMR Serverless
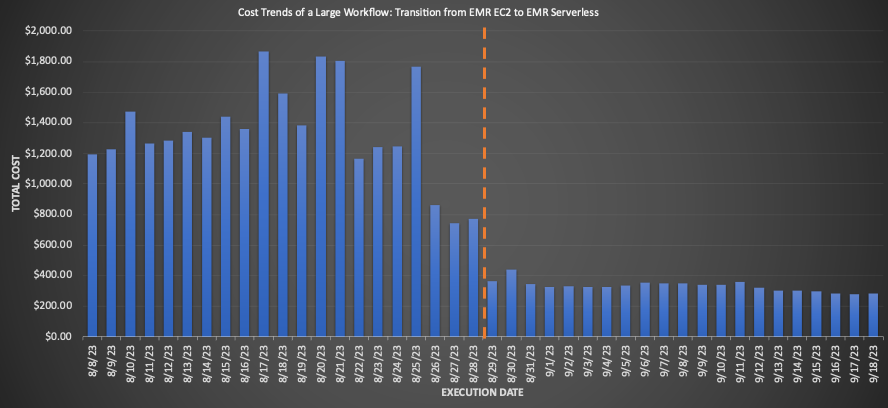
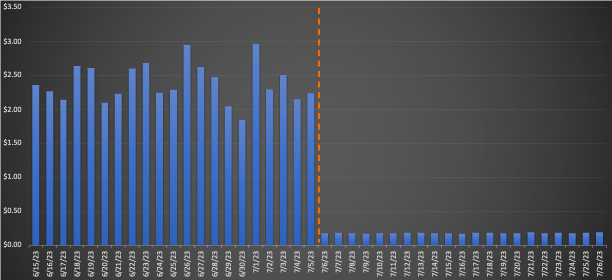
Para un gran flujo de trabajo migrado a EMR Serverless, la comparación de los promedios de 3 semanas antes y después de la migración reveló ahorros de costos impresionantes: una disminución del 75.30 % según los precios minoristas con una mejora del 10 % en el tiempo de ejecución total, lo que aumenta la eficiencia operativa. El siguiente gráfico ilustra la tendencia de los costos.
Aunque los trabajos de ejecución rápida lograron reducciones mínimas de costos por dólar, generaron los ahorros de costos porcentuales más significativos. Con miles de estos flujos de trabajo ejecutándose diariamente, los ahorros acumulados son sustanciales. El siguiente gráfico muestra la tendencia de costos para una pequeña carga de trabajo migrada de EMR en EC2 a EMR Serverless. La comparación de los promedios de 3 semanas antes y después de la migración reveló un notable ahorro de costos del 92.43 % en los precios minoristas bajo demanda, junto con una aceleración del 80.6 % en el tiempo de ejecución total.
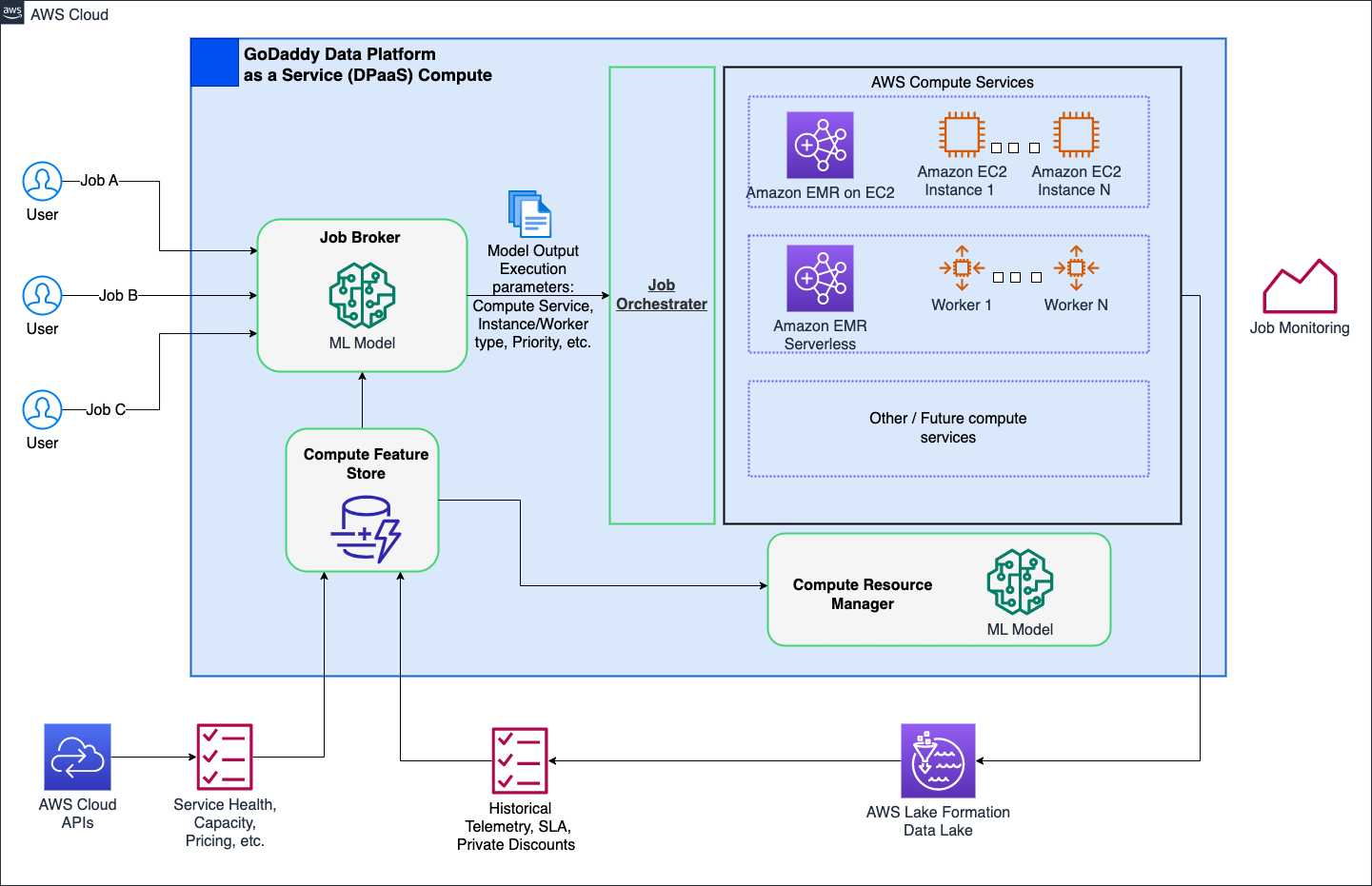
Capa 7: mejoras en toda la plataforma
Nuestro objetivo es revolucionar las operaciones informáticas en GoDaddy, proporcionando soluciones simplificadas pero potentes para todos los usuarios con nuestra plataforma informática inteligente. Con las soluciones informáticas de AWS como EMR Serverless y EMR en EC2, proporcionó ejecuciones optimizadas de cargas de trabajo de procesamiento de datos y aprendizaje automático (ML). Un intermediario de trabajos basado en ML determina de forma inteligente cuándo y cómo ejecutar trabajos en función de varios parámetros, al tiempo que permite a los usuarios avanzados personalizarlos. Además, un administrador de recursos informáticos basado en ML aprovisiona recursos en función de la carga y los datos históricos, proporcionando un aprovisionamiento rápido y eficiente a un costo óptimo. La computación inteligente brinda a los usuarios una optimización lista para usar, atendiendo a diversas personas sin comprometer a los usuarios avanzados.
El siguiente diagrama muestra una ilustración de alto nivel de la arquitectura informática inteligente.
Ideas y mejores prácticas recomendadas
La siguiente sección analiza los conocimientos que hemos recopilado y las mejores prácticas recomendadas que hemos desarrollado durante nuestras etapas de adopción preliminar y más amplia.
Preparación de infraestructura
Aunque EMR Serverless es un método de implementación dentro de EMR, requiere cierta preparación de la infraestructura para optimizar su potencial. Considere los siguientes requisitos y orientación práctica sobre la implementación:
- Utilice subredes grandes en varias zonas de disponibilidad: Al ejecutar cargas de trabajo EMR Serverless dentro de su VPC, asegúrese de que las subredes abarquen múltiples zonas de disponibilidad y no estén limitadas por direcciones IP. Referirse a Configurar el acceso a VPC y Mejores prácticas para la planificación de subredes para obtener más detalles.
- Modificar la cuota máxima de vCPU simultánea – Para requisitos informáticos extensos, se recomienda aumentar su vCPU máximas simultáneas por cuenta cuota de servicio.
- Compatibilidad de la versión Amazon MWAA – Al adoptar EMR Serverless, el ecosistema descentralizado Amazon MWAA de GoDaddy para la orquestación de canalizaciones de datos creó problemas de compatibilidad entre versiones dispares de proveedores de AWS. Actualizar directamente Amazon MWAA fue más eficiente que actualizar numerosos DAG. Facilitamos la adopción actualizando nosotros mismos las instancias de Amazon MWAA, documentando problemas y compartiendo hallazgos y estimaciones de esfuerzo para una planificación de actualización precisa.
- Operador de EMR de GoDaddy – Para agilizar la migración de numerosos DAG Airflow de EMR en EC2 a EMR Serverless, desarrollamos operadores personalizados adaptando las interfaces existentes. Esto permitió transiciones fluidas y al mismo tiempo mantuvo las opciones de ajuste familiares. Los ingenieros de datos podrían migrar fácilmente las canalizaciones con simples importaciones de búsqueda y reemplazo y utilizar inmediatamente EMR Serverless.
Mitigación de comportamiento inesperado
Los siguientes son comportamientos inesperados que encontramos y lo que hicimos para mitigarlos:
- Escalado agresivo de Spark DRA – Para algunos trabajos (8.33 % de los puntos de referencia iniciales, 13.6 % de la producción), los costos aumentaron después de migrar a EMR Serverless. Esto se debió a que Spark DRA asignó excesivamente nuevos trabajadores por poco tiempo, priorizando el desempeño sobre el costo. Para contrarrestar esto, establecemos umbrales máximos de ejecutor ajustando
spark.dynamicAllocation.maxExecutor, limitando efectivamente la agresión de escalado de EMR Serverless. Al migrar desde EMR en EC2, sugerimos observar el recuento máximo de núcleos en la interfaz de usuario del historial de Spark para replicar límites de procesamiento similares en EMR Serverless, como--conf spark.executor.coresy--conf spark.dynamicAllocation.maxExecutors. - Administrar espacio en disco para trabajos a gran escala – Al realizar la transición de trabajos que procesan grandes volúmenes de datos con cambios sustanciales y requisitos de disco importantes a EMR Serverless, recomendamos configurar
spark.emr-serverless.executor.diskhaciendo referencia a las métricas de trabajo de Spark existentes. Además, configuraciones comospark.executor.corescombinado conspark.emr-serverless.executor.diskyspark.dynamicAllocation.maxExecutorspermitir el control sobre el tamaño del trabajador subyacente y el almacenamiento adjunto total cuando sea ventajoso. Por ejemplo, un trabajo con mucha reproducción aleatoria con un uso de disco relativamente bajo puede beneficiarse del uso de un trabajador más grande para aumentar la probabilidad de recuperaciones aleatorias locales.
Conclusión
Como se analiza en esta publicación, nuestras experiencias con la adopción de EMR Serverless en arm64 han sido abrumadoramente positivas. Los impresionantes resultados que hemos logrado, incluida una reducción del 60 % en el costo, ejecuciones un 50 % más rápidas de cargas de trabajo Spark por lotes y una asombrosa mejora cinco veces mayor en la velocidad de desarrollo y prueba, dicen mucho sobre el potencial de esta tecnología. Además, nuestros resultados actuales sugieren que al adoptar ampliamente Graviton2 en EMR Serverless, podríamos reducir potencialmente la huella de carbono hasta en un 60% para nuestro procesamiento por lotes.
Sin embargo, es fundamental comprender que estos resultados no son un escenario único para todos. Las mejoras que puede esperar están sujetas a factores que incluyen, entre otros, la naturaleza específica de sus flujos de trabajo, configuraciones de clúster, niveles de utilización de recursos y fluctuaciones en la capacidad computacional. Por lo tanto, recomendamos firmemente una estrategia de implementación basada en anillos basada en datos al considerar la integración de EMR Serverless, que puede ayudar a optimizar sus beneficios al máximo.
Un agradecimiento especial a Mukul Sharma y boris berlín por sus contribuciones al benchmarking. Muchas gracias a Travis Muhlestein (CDO), Abhijit Kundu (vicepresidente de ingeniería), Vicente Yung (Director sénior de ingeniería), y Wai Kin Lau (Director sénior de ingeniería de datos) por su continuo apoyo.
Acerca de los autores
 Brandon Abear es ingeniero de datos principal en la organización de datos y análisis (DnA) de GoDaddy. Disfruta de todo lo relacionado con big data. En su tiempo libre le gusta viajar, ver películas y jugar juegos de ritmo.
Brandon Abear es ingeniero de datos principal en la organización de datos y análisis (DnA) de GoDaddy. Disfruta de todo lo relacionado con big data. En su tiempo libre le gusta viajar, ver películas y jugar juegos de ritmo.
 Dinesh Sharma es ingeniero de datos principal en la organización de datos y análisis (DnA) de GoDaddy. Le apasiona la experiencia del usuario y la productividad de los desarrolladores, siempre buscando formas de optimizar los procesos de ingeniería y ahorrar costos. En su tiempo libre le encanta leer y es un ávido fanático del manga.
Dinesh Sharma es ingeniero de datos principal en la organización de datos y análisis (DnA) de GoDaddy. Le apasiona la experiencia del usuario y la productividad de los desarrolladores, siempre buscando formas de optimizar los procesos de ingeniería y ahorrar costos. En su tiempo libre le encanta leer y es un ávido fanático del manga.
 juan arbusto es ingeniero de software principal en la organización de datos y análisis (DnA) de GoDaddy. Le apasiona facilitar a las organizaciones la gestión de datos y su uso para impulsar sus negocios. En su tiempo libre, le encanta hacer senderismo, acampar y andar en bicicleta eléctrica.
juan arbusto es ingeniero de software principal en la organización de datos y análisis (DnA) de GoDaddy. Le apasiona facilitar a las organizaciones la gestión de datos y su uso para impulsar sus negocios. En su tiempo libre, le encanta hacer senderismo, acampar y andar en bicicleta eléctrica.
 Ozcan Ilikhan es el director de ingeniería de la plataforma de datos y aprendizaje automático de GoDaddy. Tiene más de dos décadas de experiencia en liderazgo multidisciplinario, que abarca desde nuevas empresas hasta empresas globales. Le apasiona aprovechar los datos y la inteligencia artificial para crear soluciones que deleiten a los clientes, les permitan lograr más e impulsen la eficiencia operativa. Fuera de su vida profesional, le gusta leer, hacer senderismo, hacer jardinería, ser voluntario y embarcarse en proyectos de bricolaje.
Ozcan Ilikhan es el director de ingeniería de la plataforma de datos y aprendizaje automático de GoDaddy. Tiene más de dos décadas de experiencia en liderazgo multidisciplinario, que abarca desde nuevas empresas hasta empresas globales. Le apasiona aprovechar los datos y la inteligencia artificial para crear soluciones que deleiten a los clientes, les permitan lograr más e impulsen la eficiencia operativa. Fuera de su vida profesional, le gusta leer, hacer senderismo, hacer jardinería, ser voluntario y embarcarse en proyectos de bricolaje.
 Harsh Vardhan es un arquitecto de soluciones de AWS, especializado en big data y análisis. Tiene más de 8 años de experiencia trabajando en el campo de big data y ciencia de datos. Le apasiona ayudar a los clientes a adoptar las mejores prácticas y descubrir conocimientos a partir de sus datos.
Harsh Vardhan es un arquitecto de soluciones de AWS, especializado en big data y análisis. Tiene más de 8 años de experiencia trabajando en el campo de big data y ciencia de datos. Le apasiona ayudar a los clientes a adoptar las mejores prácticas y descubrir conocimientos a partir de sus datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

