En el cambiante panorama de la fabricación, el poder transformador de la IA y el aprendizaje automático (ML) es evidente, impulsando una revolución digital que agiliza las operaciones y aumenta la productividad. Sin embargo, este progreso presenta desafíos únicos para las empresas que navegan por soluciones basadas en datos. Las instalaciones industriales se enfrentan a grandes volúmenes de datos no estructurados, procedentes de sensores, sistemas de telemetría y equipos dispersos en las líneas de producción. Los datos en tiempo real son fundamentales para aplicaciones como el mantenimiento predictivo y la detección de anomalías; sin embargo, el desarrollo de modelos de aprendizaje automático personalizados para cada caso de uso industrial con tales datos de series temporales exige un tiempo y recursos considerables por parte de los científicos de datos, lo que dificulta su adopción generalizada.
IA generativa utilizando grandes modelos de base (FM) previamente entrenados, como Claude puede generar rápidamente una variedad de contenido, desde texto conversacional hasta código de computadora basado en indicaciones de texto simples, conocido como indicaciones de disparo cero. Esto elimina la necesidad de que los científicos de datos desarrollen manualmente modelos de aprendizaje automático específicos para cada caso de uso y, por lo tanto, democratiza el acceso a la IA, lo que beneficia incluso a los pequeños fabricantes. Los trabajadores ganan productividad a través de conocimientos generados por IA, los ingenieros pueden detectar anomalías de manera proactiva, los gerentes de la cadena de suministro optimizan los inventarios y los líderes de la planta toman decisiones informadas y basadas en datos.
Sin embargo, los FM independientes enfrentan limitaciones en el manejo de datos industriales complejos con limitaciones de tamaño del contexto (normalmente menos de 200,000 fichas), lo que plantea desafíos. Para solucionar este problema, puede utilizar la capacidad del FM para generar código en respuesta a consultas en lenguaje natural (NLQ). A los agentes les gusta pandasAI entran en juego, ejecutando este código en datos de series de tiempo de alta resolución y manejando errores usando FM. PandasAI es una biblioteca de Python que agrega capacidades de IA generativa a pandas, la popular herramienta de manipulación y análisis de datos.
Sin embargo, los NLQ complejos, como el procesamiento de datos de series temporales, la agregación multinivel y las operaciones de tablas dinámicas o conjuntas, pueden producir una precisión inconsistente del script Python con un mensaje de disparo cero.
Para mejorar la precisión de la generación de código, proponemos construir dinámicamente indicaciones de disparos múltiples para NLQ. Las indicaciones de disparos múltiples proporcionan contexto adicional al FM al mostrarle varios ejemplos de resultados deseados para indicaciones similares, lo que aumenta la precisión y la coherencia. En esta publicación, se recuperan mensajes de múltiples disparos de una incrustación que contiene código Python ejecutado exitosamente en un tipo de datos similar (por ejemplo, datos de series temporales de alta resolución de dispositivos de Internet de las cosas). El mensaje de disparo múltiple construido dinámicamente proporciona el contexto más relevante para el FM y aumenta la capacidad del FM en cálculos matemáticos avanzados, procesamiento de datos de series temporales y comprensión de acrónimos de datos. Esta respuesta mejorada facilita que los trabajadores empresariales y los equipos operativos interactúen con los datos y obtengan conocimientos sin requerir grandes habilidades en ciencia de datos.
Más allá del análisis de datos de series temporales, los FM resultan valiosos en diversas aplicaciones industriales. Los equipos de mantenimiento evalúan el estado de los activos, capturan imágenes para Reconocimiento de amazonasresúmenes de funcionalidad basados en y análisis de causa raíz de anomalías mediante búsquedas inteligentes con Recuperación Generación Aumentada (TRAPO). Para simplificar estos flujos de trabajo, AWS ha introducido lecho rocoso del amazonas, lo que le permite crear y escalar aplicaciones de IA generativa con FM previamente entrenados de última generación como claudio v2. Con Bases de conocimiento para Amazon Bedrock, puede simplificar el proceso de desarrollo de RAG para proporcionar un análisis de causa raíz de anomalías más preciso para los trabajadores de la planta. Nuestra publicación muestra un asistente inteligente para casos de uso industrial impulsado por Amazon Bedrock, que aborda los desafíos de NLQ, genera resúmenes de piezas a partir de imágenes y mejora las respuestas de FM para el diagnóstico de equipos mediante el enfoque RAG.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.

El flujo de trabajo incluye tres casos de uso distintos:
Caso de uso 1: NLQ con datos de series temporales
El flujo de trabajo para NLQ con datos de series temporales consta de los siguientes pasos:
- Utilizamos un sistema de monitoreo de condición con capacidades de ML para la detección de anomalías, como Amazonas Monitron, para monitorear la salud de los equipos industriales. Amazon Monitron puede detectar posibles fallas en los equipos a partir de las mediciones de vibración y temperatura del equipo.
- Recopilamos datos de series temporales mediante el procesamiento Amazonas Monitron datos a través de Secuencias de datos de Amazon Kinesis y Manguera de datos de Amazon, convirtiéndolo a un formato CSV tabular y guardándolo en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
- El usuario final puede comenzar a chatear con sus datos de series temporales en Amazon S3 enviando una consulta en lenguaje natural a la aplicación Streamlit.
- La aplicación Streamlit reenvía las consultas de los usuarios al Modelo de incrustación de texto de Amazon Bedrock Titan para incrustar esta consulta y realiza una búsqueda de similitud dentro de un Servicio Amazon OpenSearch índice, que contiene NLQ anteriores y códigos de ejemplo.
- Después de la búsqueda de similitudes, los principales ejemplos similares, incluidas las preguntas de NLQ, el esquema de datos y los códigos Python, se insertan en un mensaje personalizado.
- PandasAI envía este mensaje personalizado al modelo Amazon Bedrock Claude v2.
- La aplicación utiliza el agente PandasAI para interactuar con el modelo Amazon Bedrock Claude v2, generando código Python para el análisis de datos de Amazon Monitron y las respuestas NLQ.
- Después de que el modelo Amazon Bedrock Claude v2 devuelve el código Python, PandasAI ejecuta la consulta Python en los datos de Amazon Monitron cargados desde la aplicación, recopilando resultados de código y abordando los reintentos necesarios para ejecuciones fallidas.
- La aplicación Streamlit recopila la respuesta a través de PandasAI y proporciona el resultado a los usuarios. Si el resultado es satisfactorio, el usuario puede marcarlo como útil, guardando el código Python generado por NLQ y Claude en OpenSearch Service.
Caso de uso 2: generación resumida de piezas que funcionan mal
Nuestro caso de uso de generación de resumen consta de los siguientes pasos:
- Una vez que el usuario sabe qué activo industrial muestra un comportamiento anómalo, puede cargar imágenes de la pieza que funciona mal para identificar si hay algún problema físico con esta pieza de acuerdo con su especificación técnica y condición de operación.
- El usuario puede usar el API DetectText de reconocimiento de Amazon para extraer datos de texto de estas imágenes.
- Los datos de texto extraídos se incluyen en el mensaje del modelo Amazon Bedrock Claude v2, lo que permite que el modelo genere un resumen de 200 palabras de la parte que funciona mal. El usuario puede utilizar esta información para realizar una inspección más detallada de la pieza.
Caso de uso 3: diagnóstico de causa raíz
Nuestro caso de uso de diagnóstico de causa raíz consta de los siguientes pasos:
- El usuario obtiene datos empresariales en varios formatos de documentos (PDF, TXT, etc.) relacionados con activos que funcionan mal y los carga en un depósito S3.
- Se genera una base de conocimiento de estos archivos en Amazon Bedrock con un modelo de incrustaciones de texto Titan y un almacén de vectores predeterminado de OpenSearch Service.
- El usuario plantea preguntas relacionadas con el diagnóstico de la causa raíz del mal funcionamiento del equipo. Las respuestas se generan a través de la base de conocimientos de Amazon Bedrock con un enfoque RAG.
Requisitos previos
Para seguir esta publicación, debe cumplir con los siguientes requisitos previos:
Implementar la infraestructura de la solución
Para configurar los recursos de su solución, complete los siguientes pasos:
- Implementar el Formación en la nube de AWS plantilla opensearchsagemaker.yml, que crea una colección e índice del servicio OpenSearch, Amazon SageMaker instancia de notebook y depósito de S3. Puede nombrar esta pila de AWS CloudFormation como:
genai-sagemaker. - Abra la instancia del cuaderno de SageMaker en JupyterLab. Encontrarás lo siguiente Repositorio GitHub ya descargado en esta instancia: desbloquear-el-potencial-de-la-ia-generativa-en-operaciones-industriales.
- Ejecute el cuaderno desde el siguiente directorio en este repositorio: desbloqueando-el-potencial-de-la-ia-generativa-en-operaciones-industriales/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Este cuaderno cargará el índice del servicio OpenSearch utilizando el cuaderno de SageMaker para almacenar pares clave-valor del 23 ejemplos existentes de NLQ.
- Cargar documentos desde la carpeta de datos. activopartdoc en el repositorio de GitHub al depósito de S3 que figura en las salidas de la pila de CloudFormation.

A continuación, crea la base de conocimientos para los documentos en Amazon S3.
- En la consola de Amazon Bedrock, elija Base de conocimiento en el panel de navegación.
- Elige Crear base de conocimientos.
- Nombre de la base de conocimientos, ingresa un nombre.
- Rol de tiempo de ejecución, seleccione Crear y utilizar un nuevo rol de servicio.
- Nombre de fuente de datos, ingrese el nombre de su fuente de datos.
- URI de S3, ingrese la ruta S3 del depósito donde cargó los documentos de la causa raíz.
- Elige Siguiente.
 El modelo de incrustaciones Titan se selecciona automáticamente.
El modelo de incrustaciones Titan se selecciona automáticamente. - Seleccione Crea rápidamente una nueva tienda de vectores.
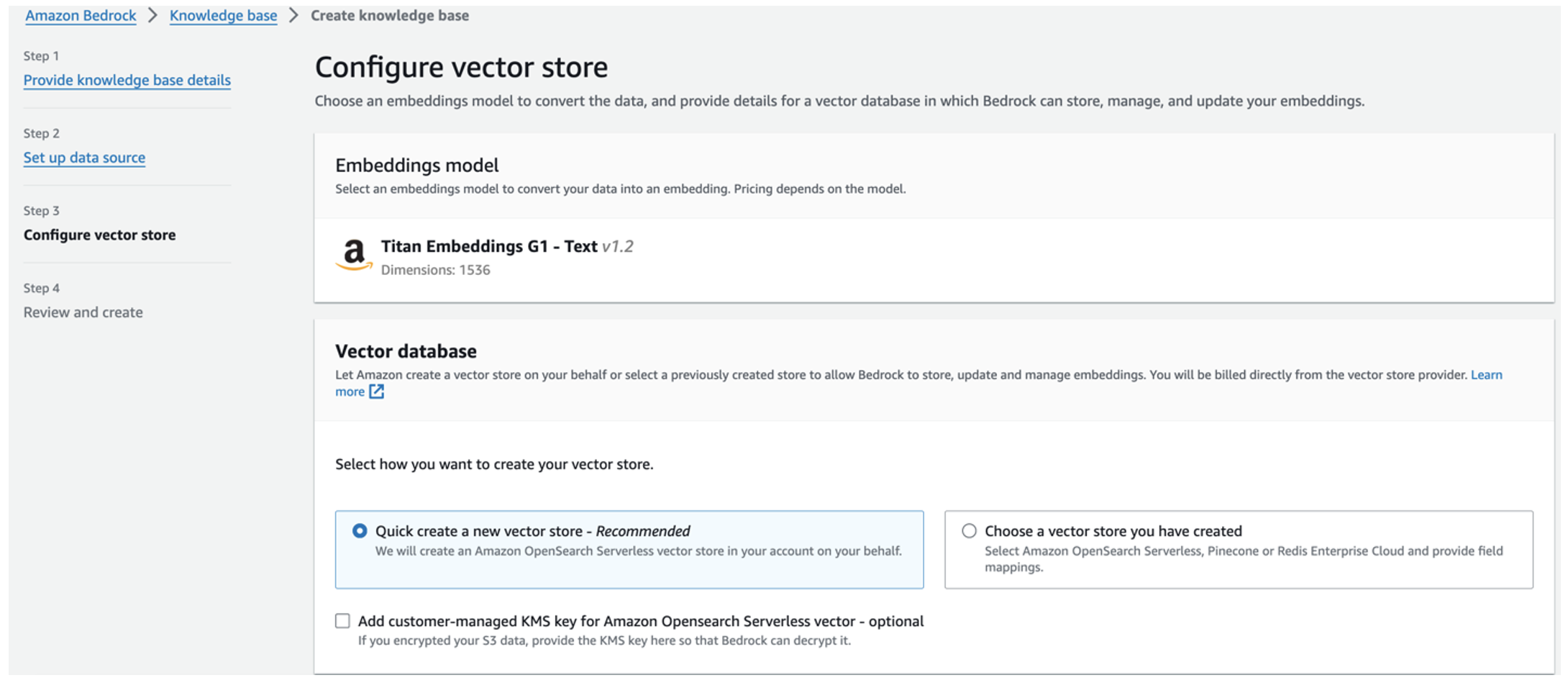
- Revise su configuración y cree la base de conocimientos eligiendo Crear base de conocimientos.
- Una vez creada correctamente la base de conocimientos, elija Sincronizar para sincronizar el depósito S3 con la base de conocimientos.

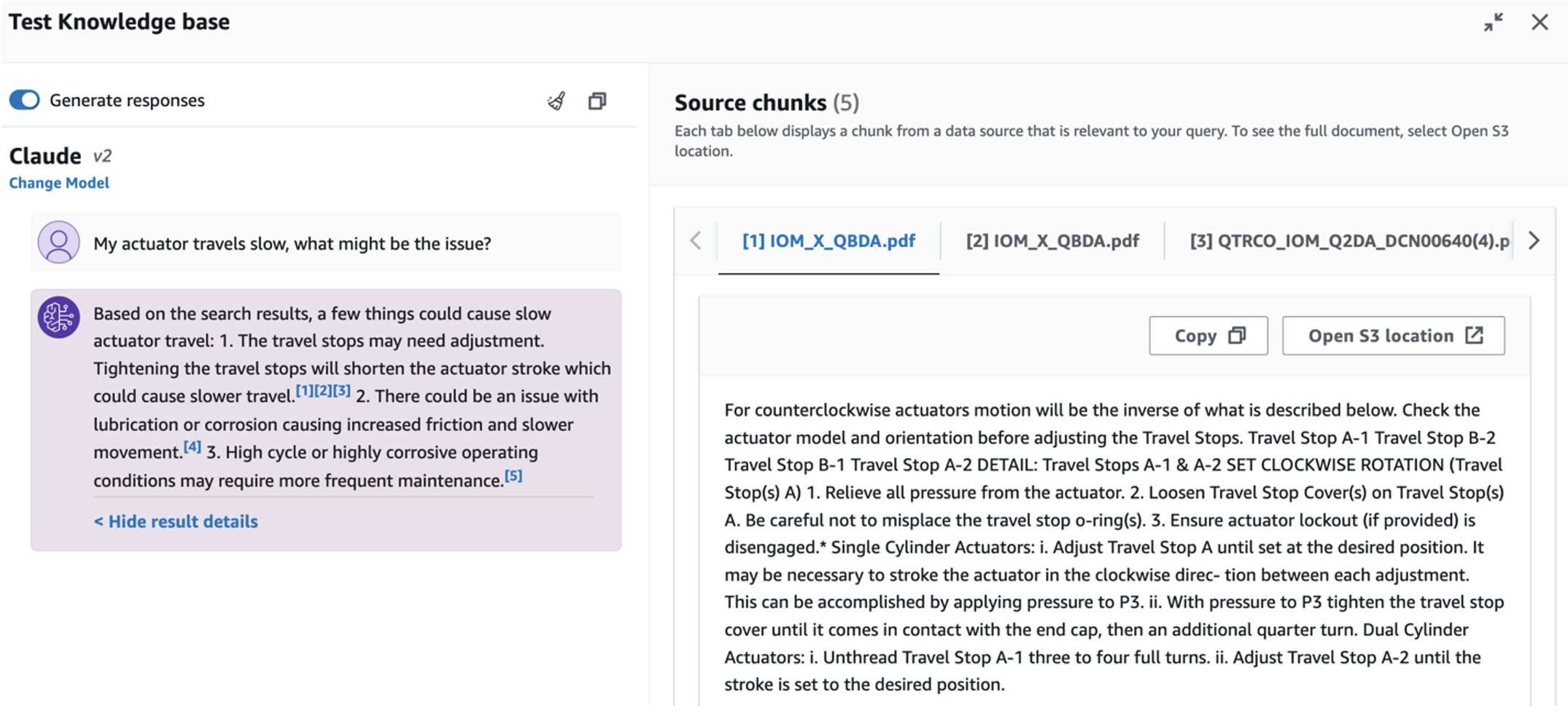
- Después de configurar la base de conocimientos, puede probar el enfoque RAG para el diagnóstico de la causa raíz haciendo preguntas como "Mi actuador viaja lento, ¿cuál podría ser el problema?"
El siguiente paso es implementar la aplicación con los paquetes de biblioteca necesarios en su PC o en una instancia EC2 (Ubuntu Server 22.04 LTS).
- Configure sus credenciales de AWS con AWS CLI en su PC local. Para simplificar, puede utilizar la misma función de administrador que utilizó para implementar la pila de CloudFormation. Si está utilizando Amazon EC2, adjuntar un rol de IAM adecuado a la instancia.
- Clon Repositorio GitHub:
- Cambie el directorio a
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcY ejecutar elsetup.shscript en esta carpeta para instalar los paquetes necesarios, incluidos LangChain y PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Ejecute la aplicación Streamlit con el siguiente comando:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Proporcione el ARN de la colección de OpenSearch Service que creó en Amazon Bedrock en el paso anterior.
Chatea con tu asistente de salud de activos
Después de completar la implementación de un extremo a otro, puede acceder a la aplicación a través del host local en el puerto 8501, que abre una ventana del navegador con la interfaz web. Si implementó la aplicación en una instancia EC2, permitir el acceso al puerto 8501 a través de la regla de entrada del grupo de seguridad. Puede navegar a diferentes pestañas para diversos casos de uso.
Explorar el caso de uso 1
Para explorar el primer caso de uso, elija Información y gráfico de datos. Comience cargando los datos de su serie temporal. Si no tiene un archivo de datos de series temporales existente para usar, puede cargar el siguiente archivo CSV de muestra con datos anónimos del proyecto Amazon Monitron. Si ya tiene un proyecto de Amazon Monitron, consulte Genere información procesable para la gestión de mantenimiento predictivo con Amazon Monitron y Amazon Kinesis para transmitir sus datos de Amazon Monitron a Amazon S3 y utilizar sus datos con esta aplicación.
Cuando se complete la carga, ingrese una consulta para iniciar una conversación con sus datos. La barra lateral izquierda ofrece una variedad de preguntas de ejemplo para su conveniencia. Las siguientes capturas de pantalla ilustran la respuesta y el código Python generado por el FM al ingresar una pregunta como "¿Dígame el número único de sensores para cada sitio que se muestra como Advertencia o Alarma respectivamente?" (una pregunta difícil) o "Para los sensores que muestran una señal de temperatura como NO saludable, ¿puede calcular la duración en días para cada sensor que muestra una señal de vibración anormal?" (una pregunta a nivel de desafío). La aplicación responderá a su pregunta y también mostrará el script Python del análisis de datos que realizó para generar dichos resultados.


Si está satisfecho con la respuesta, puede marcarla como Útil, guardando el código Python generado por NLQ y Claude en un índice del servicio OpenSearch.

Explorar el caso de uso 2
Para explorar el segundo caso de uso, elija el Resumen de la imagen capturada pestaña en la aplicación Streamlit. Puede cargar una imagen de su activo industrial y la aplicación generará un resumen de 200 palabras de sus especificaciones técnicas y condiciones de funcionamiento basándose en la información de la imagen. La siguiente captura de pantalla muestra el resumen generado a partir de una imagen de una transmisión por motor por correa. Para probar esta función, si no tiene una imagen adecuada, puede utilizar lo siguiente imagen de ejemplo.
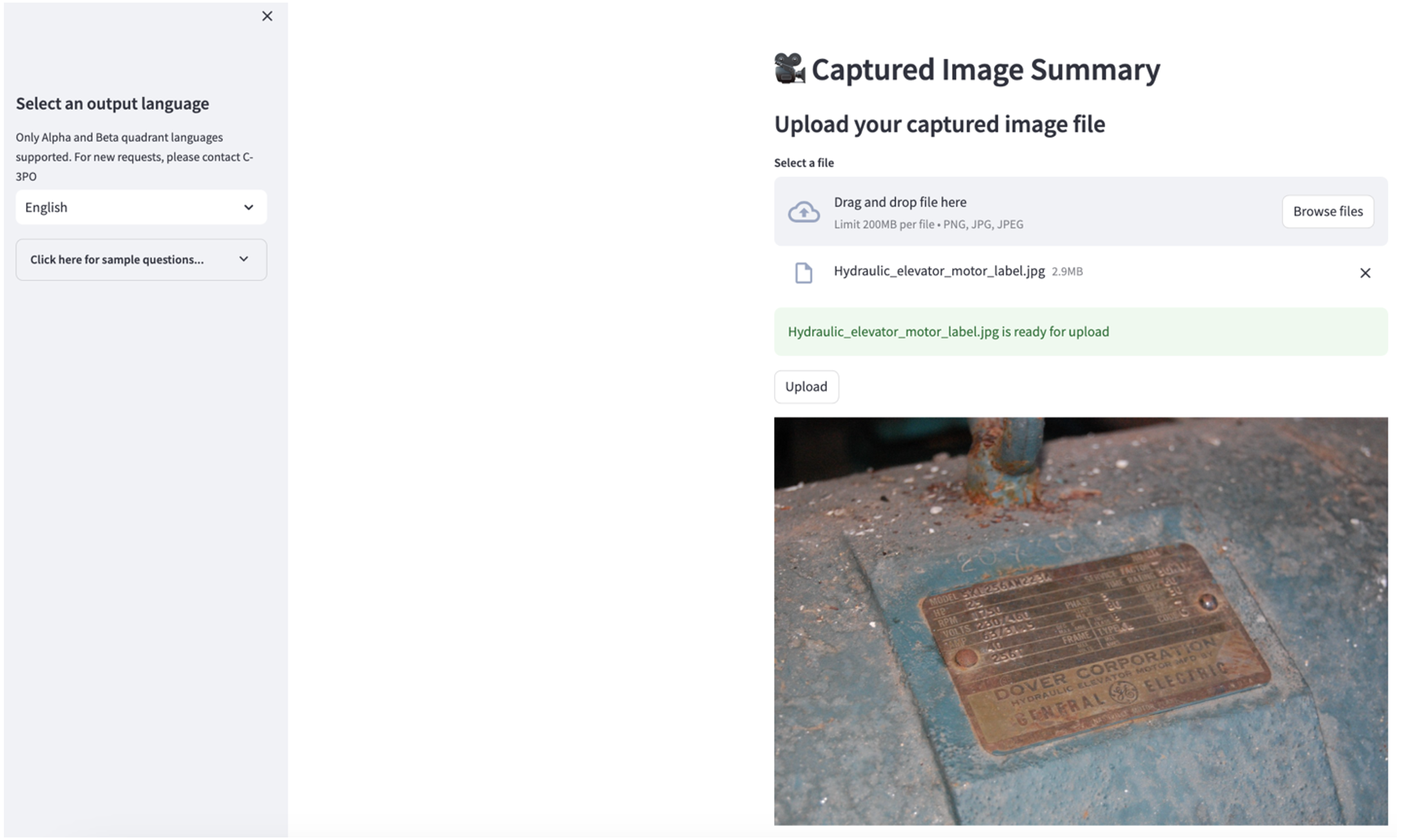
Etiqueta del motor del ascensor hidráulico”de Clarence Risher tiene licencia bajo CC BY-SA 2.0.

Explorar el caso de uso 3
Para explorar el tercer caso de uso, elija el Diagnóstico de causa raíz pestaña. Ingrese una consulta relacionada con su activo industrial averiado, como por ejemplo: "Mi actuador viaja lento, ¿cuál podría ser el problema?" Como se muestra en la siguiente captura de pantalla, la aplicación entrega una respuesta con el extracto del documento fuente utilizado para generar la respuesta.
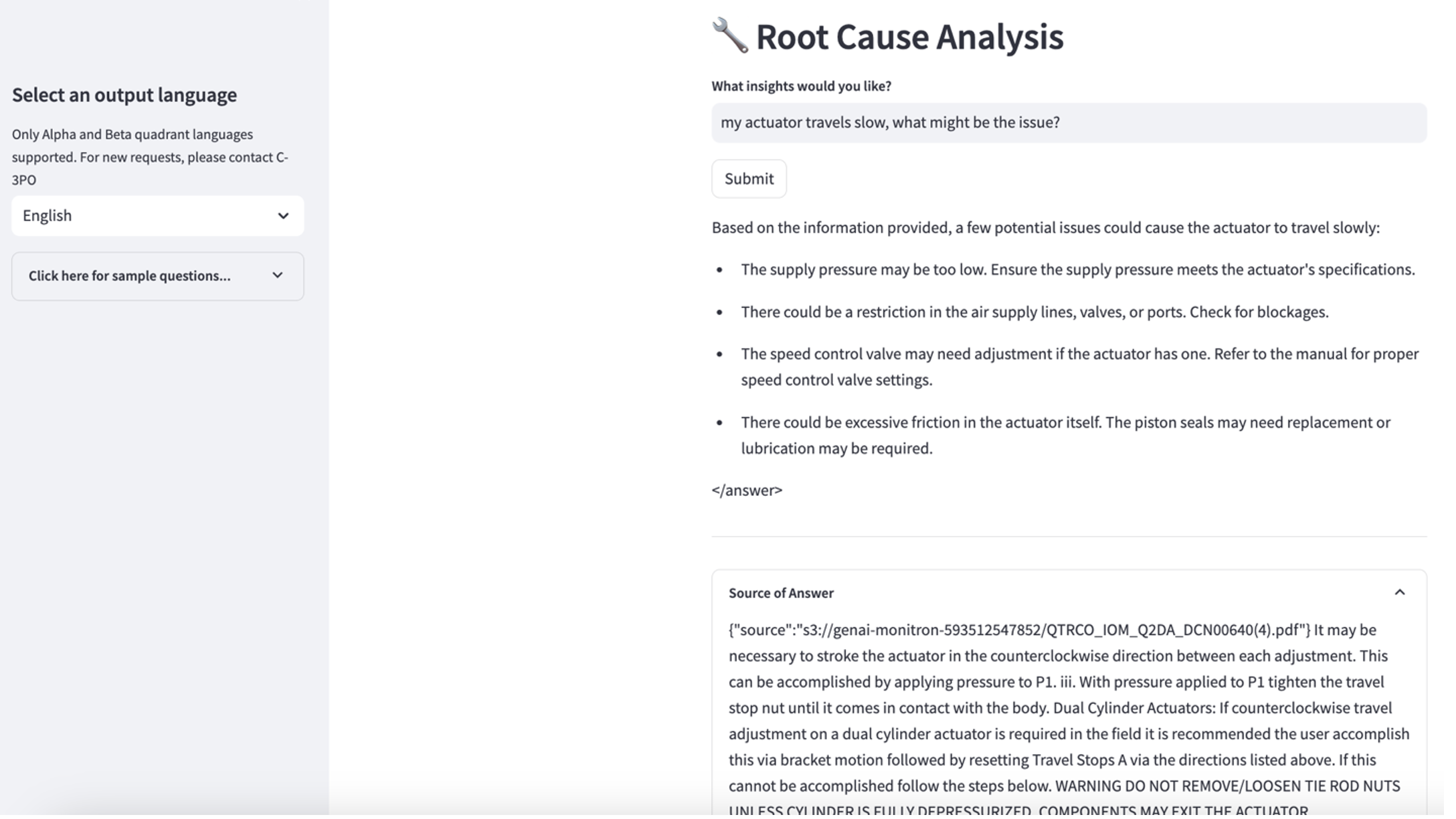
Caso de uso 1: detalles de diseño
En esta sección, analizamos los detalles de diseño del flujo de trabajo de la aplicación para el primer caso de uso.
Creación de avisos personalizados
La consulta en lenguaje natural del usuario tiene diferentes niveles de dificultad: fácil, difícil y desafiante.
Las preguntas sencillas pueden incluir las siguientes solicitudes:
- Seleccionar valores únicos
- Contar números totales
- Valores de clasificación
Para estas preguntas, PandasAI puede interactuar directamente con FM para generar scripts de Python para su procesamiento.
Las preguntas difíciles requieren operaciones de agregación básicas o análisis de series de tiempo, como las siguientes:
- Seleccione el valor primero y agrupe los resultados jerárquicamente
- Realizar estadísticas después de la selección de registros inicial
- Recuento de marcas de tiempo (por ejemplo, mínimo y máximo)
Para preguntas difíciles, una plantilla con instrucciones detalladas paso a paso ayuda a los FM a brindar respuestas precisas.
Las preguntas de nivel desafiante necesitan cálculos matemáticos avanzados y procesamiento de series de tiempo, como los siguientes:
- Calcular la duración de la anomalía para cada sensor.
- Calcular los sensores de anomalías para el sitio mensualmente.
- Compare las lecturas del sensor en funcionamiento normal y condiciones anormales
Para estas preguntas, puede utilizar disparos múltiples en un mensaje personalizado para mejorar la precisión de la respuesta. Estas tomas múltiples muestran ejemplos de procesamiento avanzado de series de tiempo y cálculos matemáticos, y proporcionarán contexto para que el FM realice inferencias relevantes en análisis similares. Insertar dinámicamente los ejemplos más relevantes de un banco de preguntas del NLQ en el mensaje puede ser un desafío. Una solución es construir incrustaciones a partir de ejemplos de preguntas de NLQ existentes y guardarlas en un almacén de vectores como OpenSearch Service. Cuando se envía una pregunta a la aplicación Streamlit, la pregunta será vectorizada por BedrockIncrustaciones. Las N incorporaciones más relevantes para esa pregunta se recuperan usando opensearch_vector_search.similarity_search y se inserta en la plantilla de mensaje como un mensaje de múltiples disparos.
El siguiente diagrama ilustra este flujo de trabajo.
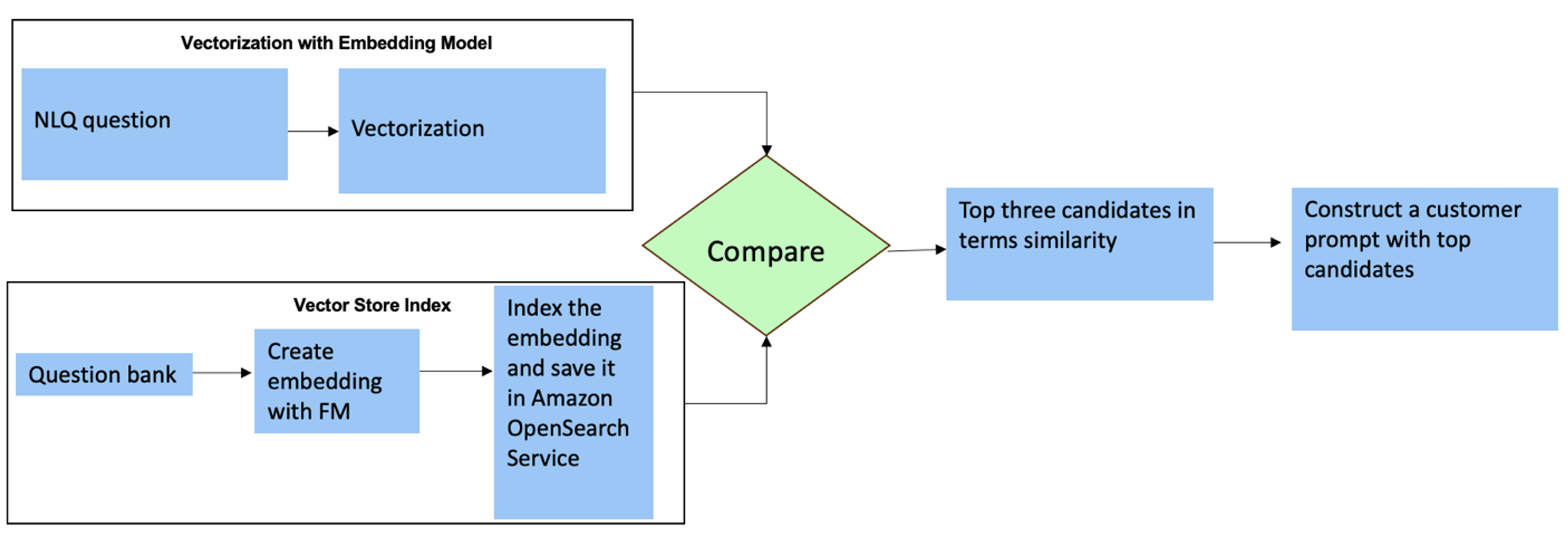
La capa de incrustación se construye utilizando tres herramientas clave:
- Modelo de incrustaciones – Usamos Amazon Titan Embeddings disponibles a través de Amazon Bedrock (amazon.titan-embed-text-v1) para generar representaciones numéricas de documentos textuales.
- Tienda de vectores – Para nuestra tienda de vectores, utilizamos el servicio OpenSearch a través del marco LangChain, lo que agiliza el almacenamiento de incrustaciones generadas a partir de ejemplos de NLQ en este cuaderno.
- Home – El índice del servicio OpenSearch desempeña un papel fundamental al comparar las incrustaciones de entrada con las incrustaciones de documentos y facilitar la recuperación de documentos relevantes. Debido a que los códigos de ejemplo de Python se guardaron como un archivo JSON, se indexaron en OpenSearch Service como vectores a través de un OpenSearchVevtorSearch.fromtexts Llamada API.
Colección continua de ejemplos auditados por humanos a través de Streamlit
Al comienzo del desarrollo de la aplicación, comenzamos con solo 23 ejemplos guardados en el índice del servicio OpenSearch como incrustaciones. A medida que la aplicación se activa en el campo, los usuarios comienzan a ingresar sus NLQ a través de la aplicación. Sin embargo, debido a los ejemplos limitados disponibles en la plantilla, es posible que algunos NLQ no encuentren mensajes similares. Para enriquecer continuamente estas incorporaciones y ofrecer indicaciones de usuario más relevantes, puede utilizar la aplicación Streamlit para recopilar ejemplos auditados por humanos.
Dentro de la aplicación, la siguiente función sirve para este propósito. Cuando los usuarios finales encuentran útil el resultado y seleccionan Útil, la aplicación sigue estos pasos:
- Utilice el método de devolución de llamada de PandasAI para recopilar el script de Python.
- Vuelva a formatear el script de Python, la pregunta de entrada y los metadatos CSV en una cadena.
- Compruebe si este ejemplo de NLQ ya existe en el índice actual del servicio OpenSearch utilizando opensearch_vector_search.similarity_search_with_score.
- Si no hay un ejemplo similar, este NLQ se agrega al índice del servicio OpenSearch usando opensearch_vector_search.add_texts.
En el caso de que un usuario seleccione No es útil, no se toma ninguna medida. Este proceso iterativo garantiza que el sistema mejore continuamente incorporando ejemplos aportados por los usuarios.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Al incorporar la auditoría humana, la cantidad de ejemplos en OpenSearch Service disponibles para su rápida integración crece a medida que la aplicación gana uso. Este conjunto de datos de incorporación ampliado da como resultado una precisión de búsqueda mejorada con el tiempo. Específicamente, para los NLQ desafiantes, la precisión de la respuesta del FM alcanza aproximadamente el 90 % cuando se insertan dinámicamente ejemplos similares para crear indicaciones personalizadas para cada pregunta del NLQ. Esto representa un notable aumento del 28 % en comparación con escenarios sin indicaciones de disparos múltiples.
Caso de uso 2: detalles de diseño
En la aplicación Streamlit Resumen de la imagen capturada pestaña, puede cargar directamente un archivo de imagen. Esto inicia la API de Amazon Rekognition (detectar_texto API), extrayendo texto de la etiqueta de la imagen que detalla las especificaciones de la máquina. Posteriormente, los datos de texto extraídos se envían al modelo de Amazon Bedrock Claude como contexto de un mensaje, lo que da como resultado un resumen de 200 palabras.
Desde la perspectiva de la experiencia del usuario, habilitar la funcionalidad de transmisión para una tarea de resumen de texto es primordial, ya que permite a los usuarios leer el resumen generado por FM en fragmentos más pequeños en lugar de esperar el resultado completo. Amazon Bedrock facilita la transmisión a través de su API (bedrock_runtime.invoke_model_with_response_stream).
Caso de uso 3: detalles de diseño
En este escenario, hemos desarrollado una aplicación de chatbot centrada en el análisis de la causa raíz, empleando el enfoque RAG. Este chatbot se basa en múltiples documentos relacionados con equipos de rodamientos para facilitar el análisis de la causa raíz. Este chatbot de análisis de causa raíz basado en RAG utiliza bases de conocimiento para generar representaciones de texto vectorial o incrustaciones. Knowledge Bases for Amazon Bedrock es una capacidad totalmente administrada que le ayuda a implementar todo el flujo de trabajo de RAG, desde la ingesta hasta la recuperación y el aumento rápido, sin tener que crear integraciones personalizadas con fuentes de datos ni administrar flujos de datos y detalles de implementación de RAG.
Cuando esté satisfecho con la respuesta de la base de conocimientos de Amazon Bedrock, puede integrar la respuesta de la causa raíz de la base de conocimientos a la aplicación Streamlit.
Limpiar
Para ahorrar costos, elimine los recursos que creó en esta publicación:
- Eliminar la base de conocimientos de Amazon Bedrock.
- Elimine el índice del servicio OpenSearch.
- Elimine la pila de CloudFormation de genai-sagemaker.
- Detenga la instancia EC2 si utilizó una instancia EC2 para ejecutar la aplicación Streamlit.
Conclusión
Las aplicaciones de IA generativa ya han transformado varios procesos empresariales, mejorando la productividad y las habilidades de los trabajadores. Sin embargo, las limitaciones de los FM en el manejo del análisis de datos de series temporales han dificultado su plena utilización por parte de los clientes industriales. Esta limitación ha impedido la aplicación de la IA generativa al tipo de datos predominante que se procesa diariamente.
En esta publicación, presentamos una solución de aplicación de IA generativa diseñada para aliviar este desafío para los usuarios industriales. Esta aplicación utiliza un agente de código abierto, PandasAI, para fortalecer la capacidad de análisis de series temporales de un FM. En lugar de enviar datos de series temporales directamente a los FM, la aplicación emplea PandasAI para generar código Python para el análisis de datos de series temporales no estructurados. Para mejorar la precisión de la generación de código Python, se implementó un flujo de trabajo de generación de mensajes personalizado con auditoría humana.
Al contar con información sobre el estado de sus activos, los trabajadores industriales pueden aprovechar plenamente el potencial de la IA generativa en diversos casos de uso, incluido el diagnóstico de la causa raíz y la planificación del reemplazo de piezas. Con Knowledge Bases para Amazon Bedrock, la solución RAG es sencilla de crear y administrar para los desarrolladores.
La trayectoria de las operaciones y la gestión de datos empresariales avanza sin lugar a dudas hacia una integración más profunda con la IA generativa para obtener información integral sobre el estado operativo. Este cambio, encabezado por Amazon Bedrock, se ve significativamente amplificado por la creciente solidez y potencial de los LLM como Amazon Bedrock Claude 3 para elevar aún más las soluciones. Para obtener más información, visite consultar el Documentación de Amazon Bedrocky ponte manos a la obra con Taller de lecho de roca amazónica.
Sobre los autores
 julia hu es arquitecto sénior de soluciones de IA/ML en Amazon Web Services. Está especializada en IA generativa, ciencia de datos aplicada y arquitectura IoT. Actualmente forma parte del equipo de Amazon Q y miembro activo/mentor en la comunidad de campo técnico de aprendizaje automático. Trabaja con clientes, desde empresas emergentes hasta empresas, para desarrollar algunas soluciones de IA generativa. Le apasiona especialmente aprovechar los modelos de lenguajes grandes para análisis de datos avanzados y explorar aplicaciones prácticas que aborden los desafíos del mundo real.
julia hu es arquitecto sénior de soluciones de IA/ML en Amazon Web Services. Está especializada en IA generativa, ciencia de datos aplicada y arquitectura IoT. Actualmente forma parte del equipo de Amazon Q y miembro activo/mentor en la comunidad de campo técnico de aprendizaje automático. Trabaja con clientes, desde empresas emergentes hasta empresas, para desarrollar algunas soluciones de IA generativa. Le apasiona especialmente aprovechar los modelos de lenguajes grandes para análisis de datos avanzados y explorar aplicaciones prácticas que aborden los desafíos del mundo real.
 Sudeesh Sasidharan es Arquitecto de Soluciones Senior en AWS, dentro del equipo de Energía. A Sudeesh le encanta experimentar con nuevas tecnologías y crear soluciones innovadoras que resuelvan desafíos comerciales complejos. Cuando no está diseñando soluciones o jugando con las últimas tecnologías, puedes encontrarlo en la cancha de tenis trabajando su revés.
Sudeesh Sasidharan es Arquitecto de Soluciones Senior en AWS, dentro del equipo de Energía. A Sudeesh le encanta experimentar con nuevas tecnologías y crear soluciones innovadoras que resuelvan desafíos comerciales complejos. Cuando no está diseñando soluciones o jugando con las últimas tecnologías, puedes encontrarlo en la cancha de tenis trabajando su revés.
 Neil Desai es un ejecutivo de tecnología con más de 20 años de experiencia en inteligencia artificial (IA), ciencia de datos, ingeniería de software y arquitectura empresarial. En AWS, dirige un equipo de arquitectos de soluciones especializados en servicios de IA a nivel mundial que ayudan a los clientes a crear soluciones innovadoras impulsadas por IA generativa, compartir las mejores prácticas con los clientes e impulsar la hoja de ruta del producto. En sus puestos anteriores en Vestas, Honeywell y Quest Diagnostics, Neil ocupó puestos de liderazgo en el desarrollo y lanzamiento de productos y servicios innovadores que han ayudado a las empresas a mejorar sus operaciones, reducir costos y aumentar los ingresos. Le apasiona utilizar la tecnología para resolver problemas del mundo real y es un pensador estratégico con un historial comprobado de éxito.
Neil Desai es un ejecutivo de tecnología con más de 20 años de experiencia en inteligencia artificial (IA), ciencia de datos, ingeniería de software y arquitectura empresarial. En AWS, dirige un equipo de arquitectos de soluciones especializados en servicios de IA a nivel mundial que ayudan a los clientes a crear soluciones innovadoras impulsadas por IA generativa, compartir las mejores prácticas con los clientes e impulsar la hoja de ruta del producto. En sus puestos anteriores en Vestas, Honeywell y Quest Diagnostics, Neil ocupó puestos de liderazgo en el desarrollo y lanzamiento de productos y servicios innovadores que han ayudado a las empresas a mejorar sus operaciones, reducir costos y aumentar los ingresos. Le apasiona utilizar la tecnología para resolver problemas del mundo real y es un pensador estratégico con un historial comprobado de éxito.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

