iceberg apache es un formato de tabla abierta para grandes conjuntos de datos en Servicio de almacenamiento simple de Amazon (Amazon S3) y proporciona un rendimiento de consulta rápido en tablas grandes, confirmaciones atómicas, escrituras simultáneas y evolución de tablas compatible con SQL. Con EMR de Amazon 6.5+, puede usar Apache Spark en clústeres de EMR con el formato de tabla Iceberg.
Iceberg ayuda a los ingenieros de datos a gestionar desafíos complejos, como conjuntos de datos en constante evolución, manteniendo el rendimiento de las consultas. Iceberg le permite hacer lo siguiente:
- Mantenga la consistencia transaccional en tablas entre múltiples aplicaciones donde los archivos se pueden agregar, eliminar o modificar de forma atómica con aislamiento de lectura completo y múltiples escrituras simultáneas
- Implemente la evolución completa del esquema para realizar un seguimiento de los cambios en una tabla a lo largo del tiempo
- Emita consultas de viaje en el tiempo para consultar datos históricos y verificar cambios entre actualizaciones
- Organice tablas en diseños de partición flexibles con evolución de partición, lo que permite actualizaciones de esquemas de partición a medida que cambian las consultas y el volumen de datos sin depender de directorios físicos
- Retroceda las tablas a versiones anteriores para corregir problemas rápidamente y devolver las tablas a un buen estado conocido
- Realice una planificación y filtrado avanzados en consultas de alto rendimiento en grandes conjuntos de datos
En esta publicación, le mostramos cómo mejorar el rendimiento de las operaciones de archivos de metadatos de Iceberg usando Amazon FSx para Lustre y Amazon EMR.
Rendimiento de operaciones de archivos de metadatos en Iceberg
El catálogo, la capa de metadatos y la capa de datos de Iceberg se describen en el siguiente diagrama.
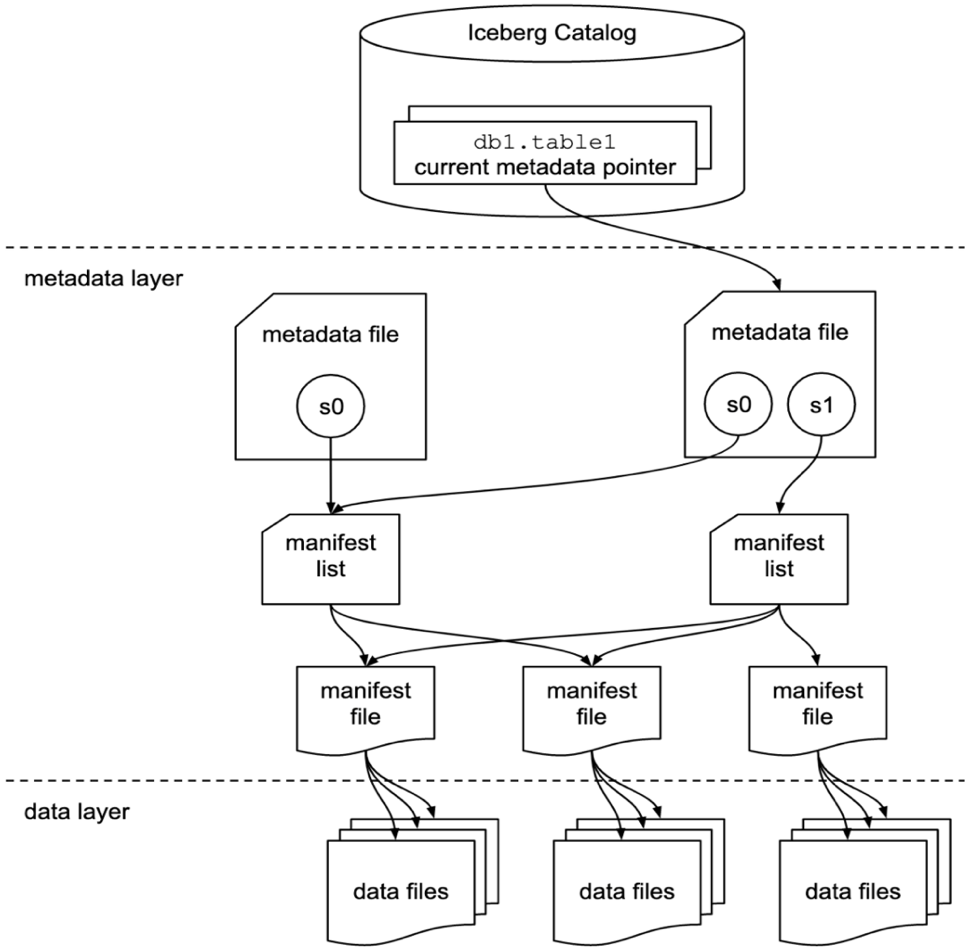
Iceberg mantiene metadatos en múltiples archivos pequeños (archivo de metadatos, lista de manifiestos y archivos de manifiestos) para podar datos, filtrar datos, leer la instantánea correcta, fusionar archivos delta y más de manera efectiva. Aunque Iceberg ha implementado planificación de escaneo rápido Para asegurarse de que las operaciones de archivos de metadatos no requieran una gran cantidad de tiempo, el tiempo necesario es ligeramente alto para el almacenamiento de objetos como Amazon S3 porque tiene una latencia de lectura/escritura más alta.
En casos de uso, como una aplicación de transmisión de alto rendimiento que escribe datos en un lago de datos S3 casi en tiempo real, las instantáneas se producen en microlotes a una velocidad muy rápida, lo que da como resultado una gran cantidad de archivos de instantáneas y degrada el rendimiento del archivo de metadatos. operaciones.
Como se muestra en el siguiente diagrama de arquitectura, el clúster de EMR consume de Kafka y escribe en una tabla Iceberg, que usa Amazon S3 como almacenamiento y Pegamento AWS como el catálogo.

En esta publicación, profundizamos en cómo mejorar el rendimiento de las consultas mediante el almacenamiento en caché de archivos de metadatos en un sistema de archivos de baja latencia como FSx for Lustre.
Resumen de la solución
FSx for Lustre hace que sea fácil y rentable lanzar y ejecutar el alto rendimiento Sistema de archivos Lustre. Lo usa para cargas de trabajo donde la velocidad es importante, como escrituras de transmisión de alto rendimiento, aprendizaje automático, computación de alto rendimiento (HPC), procesamiento de video y modelado financiero. Tú también puedes vincular el sistema de archivos FSx for Lustre a un depósito S3, si es requerido. FSx for Lustre ofrece múltiples opciones de implementación, incluidas las siguientes:
- Sistemas de archivos temporales, que están diseñados para el almacenamiento temporal y el procesamiento a corto plazo de datos. Los datos no se replican y no persisten si falla un servidor de archivos. Utilice sistemas de archivos reutilizables cuando necesite un almacenamiento rentable para cargas de trabajo de procesamiento pesado a corto plazo.
- Sistemas de archivos persistentes, que están diseñados para cargas de trabajo y almacenamiento a largo plazo. Los servidores de archivos tienen una alta disponibilidad y los datos se replican automáticamente dentro del mismo Zona de disponibilidad en el que se encuentra el sistema de archivos. Los volúmenes de datos adjuntos a los servidores de archivos se replican independientemente de los servidores de archivos a los que están conectados.
El caso de uso con los archivos de metadatos de Iceberg está relacionado con el almacenamiento en caché, y las cargas de trabajo son de ejecución corta (unas pocas horas), por lo que el sistema de archivos temporales puede considerarse una opción de implementación viable. Un sistema de archivos Scratch-2 con 200 MB/s/TiB de rendimiento es suficiente para nuestras necesidades porque los archivos de metadatos de Iceberg son pequeños y no esperamos una gran cantidad de conexiones paralelas.
Puede usar FSx for Lustre como caché para los archivos de metadatos (en la parte superior de una ubicación de S3) para ofrecer un mejor rendimiento en términos de operaciones de archivos de metadatos. Para leer/escribir archivos, Iceberg proporciona la capacidad de cargar un FileIO personalizado de forma dinámica durante el tiempo de ejecución. Puedes pasar el FSxForLustreS3FileIO referencia usando una configuración de Spark, que se encarga de leer/escribir en los sistemas de archivos apropiados (FSx para Lustre para lecturas y Amazon S3 para escrituras). Al habilitar las propiedades del catálogo lustre.mount.path, lustre.file.system.pathy data.repository.path, Iceberg resuelve la ruta S3 a FSx para la ruta Lustre en tiempo de ejecución.
Como se muestra en el siguiente diagrama de arquitectura, el clúster de EMR consume de Kafka y escribe en una tabla Iceberg que usa Amazon S3 como almacenamiento y AWS Glue como catálogo. Las lecturas de metadatos se redirigen a FSx for Lustre, que se actualiza de forma asincrónica.

Precios y rendimiento
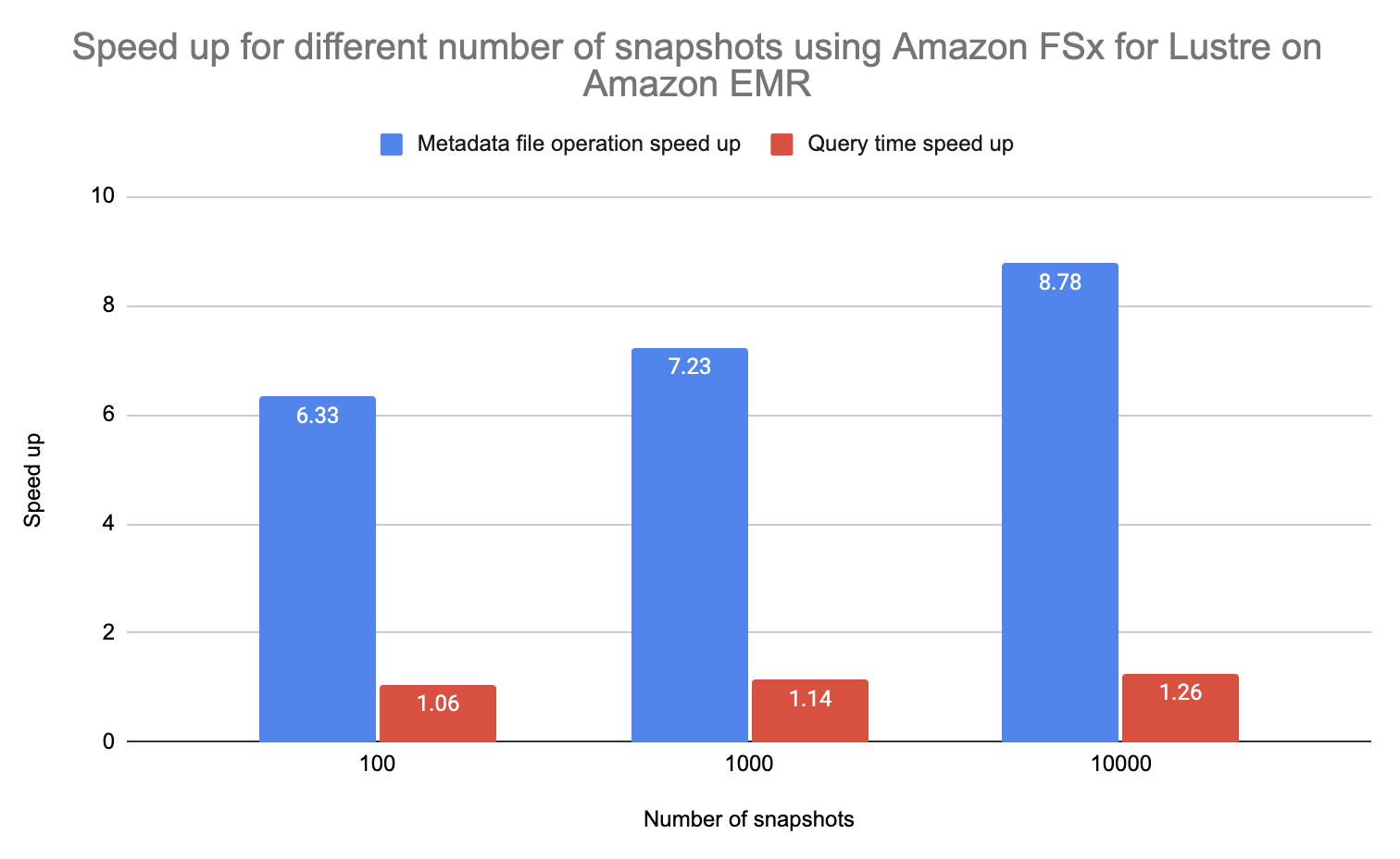
Tomamos un conjunto de datos de muestra en 100, 1,000 y 10,000 8.78 instantáneas, y pudimos observar una aceleración de hasta 1.26 veces en las operaciones de archivos de metadatos y una aceleración de hasta XNUMX veces en el tiempo de consulta. Tenga en cuenta que el beneficio se observó para las tablas con una mayor cantidad de instantáneas. Los componentes del entorno utilizados en este benchmark se enumeran en la siguiente tabla.
| Versión iceberg | Versión chispa | Versión de clúster | Dominar | en domicilio |
| 0.14.1-amzn-0 | 3.3.0-amzn-1 | AmazonEMR 6.9.0 | m5.8xlargo | 15 x m5.8xgrande |
El siguiente gráfico compara la aceleración para cada cantidad de instantáneas.
Puedes calcular el precio usando el Calculadora de precios de AWS. El costo mensual estimado de un sistema de archivos FSx for Lustre (tipo de implementación temporal) en la región EE. UU. Este (Norte de Virginia) con una capacidad de almacenamiento de 1.2 TB y un rendimiento de almacenamiento de 200 MBps/TiB por unidad es de $336.38.
El beneficio general es significativo considerando el bajo costo incurrido. La ganancia de rendimiento en términos de operaciones de archivos de metadatos puede ayudarlo a lograr una lectura de baja latencia para cargas de trabajo de transmisión de alto rendimiento.
Requisitos previos
Para este tutorial, necesita los siguientes requisitos previos:
Crear un sistema de archivos FSx for Lustre
En esta sección, repasamos los pasos para crear su sistema de archivos FSx for Lustre a través de la consola FSx for Lustre. Usar el Interfaz de línea de comandos de AWS (AWS CLI), consulte crear-sistema-de-archivos.
- En la consola de Amazon FSx, cree un nuevo sistema de archivos.
- Opciones del sistema de archivos, seleccione Amazon FSx para Lustre.
- Elige Siguiente.

- Nombre del sistema de archivos¸ introduzca un nombre opcional.
- Tipo de implementación y almacenamiento, seleccione Rasguño, SSD, porque está diseñado para cargas de trabajo y almacenamiento a corto plazo.
- Rendimiento por unidad de almacenamiento, seleccione 200 MB/s/TiB.Puede elegir la capacidad de almacenamiento según su caso de uso. Un sistema de archivos Scratch-2 con 200 MB/s/TiB de rendimiento es suficiente para nuestras necesidades porque los archivos de metadatos de Iceberg son pequeños y no esperamos una gran cantidad de conexiones paralelas.

- Ingrese una VPC, un grupo de seguridad y una subred adecuados. Asegúrese de que el grupo de seguridad tenga la reglas entrantes y salientes apropiadas habilitadas para acceder al sistema de archivos FSx for Lustre desde Amazon EMR.

- En Importación/exportación del repositorio de datos sección, seleccionar Importar datos desde y exportar datos a S3.
- Seleccione Actualizar mi lista de archivos y directorios a medida que se agregan, modifican o eliminan objetos de mi depósito de S3 para mantener actualizada la lista del sistema de archivos.
- Cubo de importación, ingrese al depósito S3 para almacenar los metadatos de Iceberg.

- Elige Siguiente y verifique el resumen del sistema de archivos, luego elija Crear sistema de archivos.
Cuando se crea el sistema de archivos, puede ver el nombre DNS y el nombre de montaje.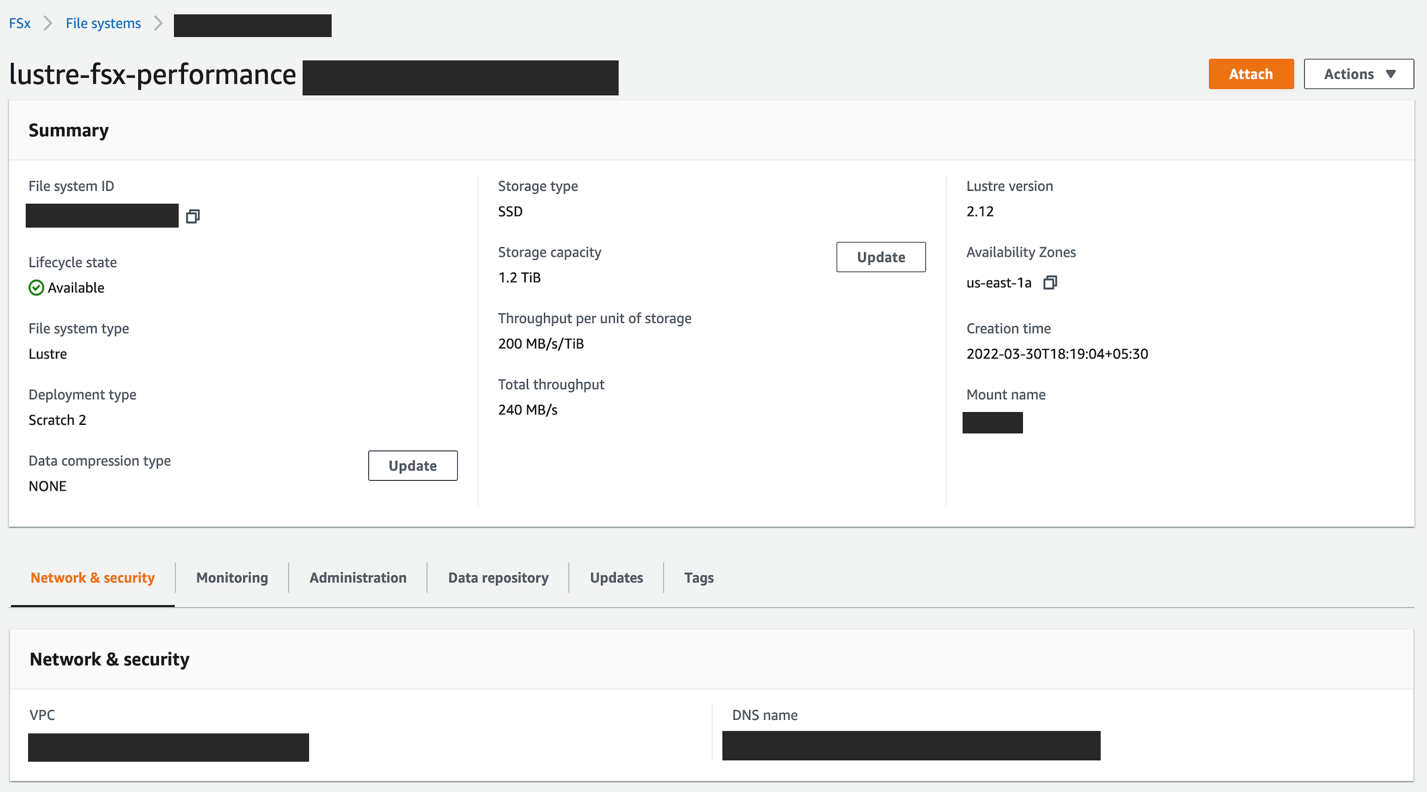
Cree un clúster EMR con FSx for Lustre montado
Esta sección muestra cómo crear una tabla Iceberg usando Spark, aunque también podemos usar otros motores. Para crear su clúster EMR con FSx for Lustre montado, complete los siguientes pasos:
- En la consola de Amazon EMR, cree un clúster de EMR (6.9.0 o superior) con Iceberg instalado. Para obtener instrucciones, consulte Usar un clúster con Iceberg instalado.
Para utilizar la CLI de AWS, consulte crear-cluster.
- Mantenga la red (VPC) y la subred EC2 igual que las que usó al crear el sistema de archivos FSx for Lustre.

- Cree un script de arranque y cárguelo en un depósito de S3 al que pueda acceder EMR. Consulte el siguiente script de arranque para montar FSx for Lustre en un clúster de EMR (el sistema de archivos se monta en el
/mnt/fsxruta del clúster). El nombre DNS del sistema de archivos y el nombre de montaje se pueden encontrar en los detalles del resumen del sistema de archivos. - Agregue el script de acción de arranque al clúster de EMR.

- Especifique su par de claves EC2.
- Elige Crear clúster.
- Cuando el clúster de EMR se esté ejecutando, SSH en el clúster e inicie el
spark-sqlusando el siguiente código:
Tenga en cuenta lo siguiente:
-
- En un nivel de sesión de Spark, las propiedades del catálogo
io-impl,lustre.mount.path,lustre.file.system.pathydata.repository.pathhan sido establecidas. io-implestablece una implementación de FileIO personalizada que resuelve la ubicación FSx for Lustre (desde la ubicación S3) durante las lecturas.lustre.mount.pathes la ruta de montaje local en el clúster de EMR,lustre.file.system.pathes la ruta del sistema de archivos FSx for Lustre, ydata.repository.pathes la ruta del repositorio de datos de S3, que está vinculada a la ruta del sistema de archivos FSx for Lustre. Después de proporcionar todas estas propiedades, eldata.repository.pathse resuelve a la concatenación delustre.mount.pathylustre.file.system.pathdurante las lecturas. Tenga en cuenta que FSx para Lustre es eventualmente consistente después de una actualización en Amazon S3. Entonces, en caso de que FSx for Lustre se ponga al día con las actualizaciones de S3, elFileIOrecurrirá a las rutas S3 adecuadas.- If
write.metadata.pathestá configurado, asegúrese de que la ruta no contenga barras inclinadas ydata.repository.pathes equivalente awrite.metadata.path.
- En un nivel de sesión de Spark, las propiedades del catálogo
- Cree la base de datos y la tabla Iceberg utilizando las siguientes consultas:
Tenga en cuenta que para migrar una tabla existente para usar FSx for Lustre, debe crear el sistema de archivos FSx for Lustre, montarlo mientras inicia el clúster de EMR e iniciar la sesión de Spark como se destacó en el paso anterior. La lista de Amazon S3 de la tabla existente se actualiza eventualmente en el sistema de archivos FSx for Lustre.
- Inserte los datos en la tabla usando un
INSERT INTOconsulta y luego consulta lo mismo: - Ahora puede ver los archivos de metadatos en el montaje FSx local, que también está vinculado al depósito S3
s3://<bucket>/warehouse/sample_table/metadata/: - Puede ver los archivos de metadatos en Amazon S3:
- También puede ver los archivos de datos en Amazon S3:
Limpiar
Cuando haya terminado de explorar la solución, complete los siguientes pasos para limpiar los recursos:
- Suelta la mesa Iceberg.
- Elimina el clúster de EMR.
- Elimine el sistema de archivos FSx for Lustre.
- Si hay archivos huérfanos presentes, vacíe el depósito S3.
- Elimine el par de claves EC2.
- Eliminar la VPC.
Conclusión
En esta publicación, demostramos cómo crear un sistema de archivos FSx for Lustre y un clúster EMR con el sistema de archivos montado. Observamos la ganancia de rendimiento en términos de operaciones de archivos de metadatos Iceberg y luego limpiamos para no incurrir en cargos adicionales.
El uso de FSx for Lustre con Iceberg en Amazon EMR le permite obtener un rendimiento significativo en términos de operaciones de archivos de metadatos. Observamos una aceleración de 6.33 a 8.78 veces en las operaciones de archivos de metadatos y de 1.06 a 1.26 veces en el tiempo de consulta para las tablas Iceberg con 100, 1,000 y 10,000 XNUMX instantáneas. Tenga en cuenta que este enfoque reduce el tiempo de las operaciones de archivos de metadatos y no el de las operaciones de datos. La ganancia de rendimiento general dependería de la cantidad de archivos de metadatos, el tamaño de cada archivo de metadatos, la cantidad de datos que se procesan, etc.
Sobre la autora
 Rajarshi Sarkar es ingeniero de desarrollo de software en Amazon EMR. Trabaja en funciones de vanguardia de Amazon EMR y también participa en proyectos de código abierto como Apache Iceberg y Trino. En su tiempo libre le gusta viajar, ver películas y salir con amigos.
Rajarshi Sarkar es ingeniero de desarrollo de software en Amazon EMR. Trabaja en funciones de vanguardia de Amazon EMR y también participa en proyectos de código abierto como Apache Iceberg y Trino. En su tiempo libre le gusta viajar, ver películas y salir con amigos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/improve-the-performance-of-apache-icebergs-metadata-file-operations-using-amazon-fsx-for-lustre-on-amazon-emr/

