
Imagen del autor
En un mundo donde los datos son el nuevo petróleo, comprender los matices de una carrera en ciencia de datos es más importante que nunca. Ya sea que sea un entusiasta de los datos o un veterano que explore oportunidades, el uso de SQL puede ofrecerle información sobre el mercado laboral de la ciencia de datos.
Espero que estés ansioso por saber cuál títulos de trabajo de ciencia de datos son los más atractivos o cuáles ofrecen los sueldos más altos. O tal vez te estés preguntando cómo se relacionan los niveles de experiencia. salarios promedio en ciencia de datos?
En este artículo, cubrimos todas esas preguntas (y más) a medida que profundizamos en el mercado laboral de la ciencia de datos. ¡Empecemos!
El conjunto de datos que utilizaremos en este artículo está diseñado para arrojar luz sobre los patrones salariales en el campo de la ciencia de datos de 2021 a 2023. Al destacar elementos como el historial laboral, los puestos de trabajo y las ubicaciones corporativas, ofrece información crucial sobre la dispersión salarial en el sector.
Este artículo encontrará una respuesta a las siguientes preguntas:
- ¿Cómo es el salario promedio en diferentes niveles de experiencia?
- ¿Cuáles son los títulos de trabajo más comunes en ciencia de datos?
- ¿Cómo varía la distribución salarial según el tamaño de la empresa?
- ¿Dónde se encuentran geográficamente principalmente los trabajos de ciencia de datos?
- ¿Qué puestos de trabajo ofrecen los mejores salarios en ciencia de datos?
Puede descargar estos datos desde el Kaggle.
1. ¿Cómo es el salario promedio en diferentes niveles de experiencia?
En esta consulta SQL, encontramos el salario promedio para diferentes niveles de experiencia. La cláusula GROUP BY agrupa los datos por nivel de experiencia y la función AVG calcula el salario medio de cada grupo.
Esto ayuda a comprender cómo la experiencia en el campo influye en el potencial de ingresos, lo cual es esencial para usted al planificar su trayectorias profesionales en ciencia de datos. Veamos el código.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
Ahora visualicemos este resultado usando Python.
Aquí está el código.
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the style for the graphs
sns.set(style="whitegrid") # Initialize the list for storing graphs
graphs = [] plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Average Salary by Experience Level')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Ahora comparemos los salarios de nivel inicial y experimentado y de nivel medio y superior.
Comencemos con el nivel básico y el experimentado. Aquí está el código.
# Filter the data for Entry_Level and Experienced levels
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])] # Filter the data for Mid-Level and Senior levels
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])] # Plotting the Entry_Level vs Experienced graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Entry_Level vs Experienced')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Aquí está el gráfico.
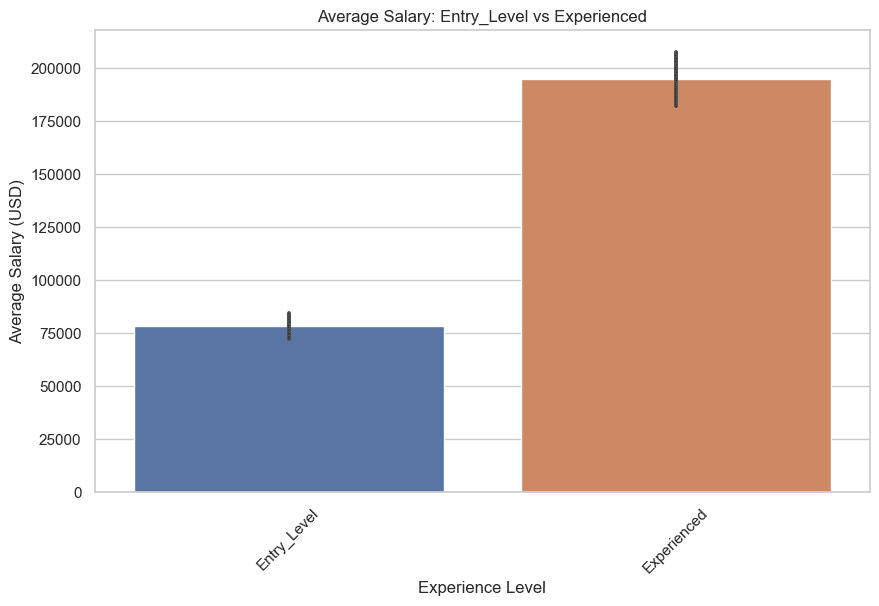
Ahora dibujemos, nivel medio y superior. Aquí está el código.
# Plotting the Mid-Level vs Senior graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Mid-Level vs Senior')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
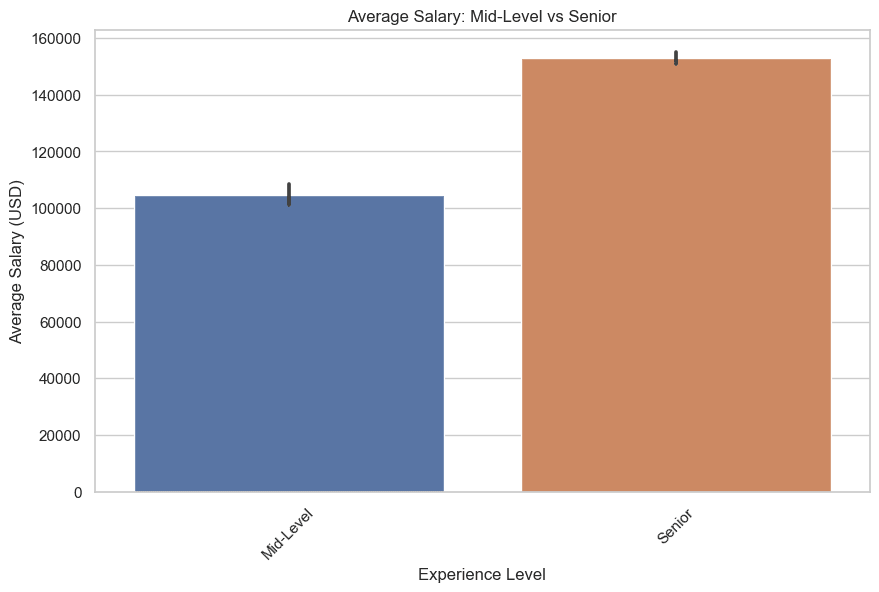
2. ¿Cuáles son los títulos laborales más comunes en ciencia de datos?
Aquí, extraemos los 10 puestos de trabajo más comunes en ciencia de datos. La función CONTAR cuenta el número de apariciones de cada puesto de trabajo y los resultados se ordenan en orden descendente para obtener los títulos más comunes en la parte superior.
Esta información le brinda una idea de la demanda del mercado laboral y lo guiará en la identificación de roles potenciales a los que puede dirigirse. Veamos el código.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
Bien, es hora de visualizar esta consulta usando Python.
Aquí está el código.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Most Common Job Titles in Data Science')
plt.xlabel('Job Count')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.show()
Veamos el gráfico.
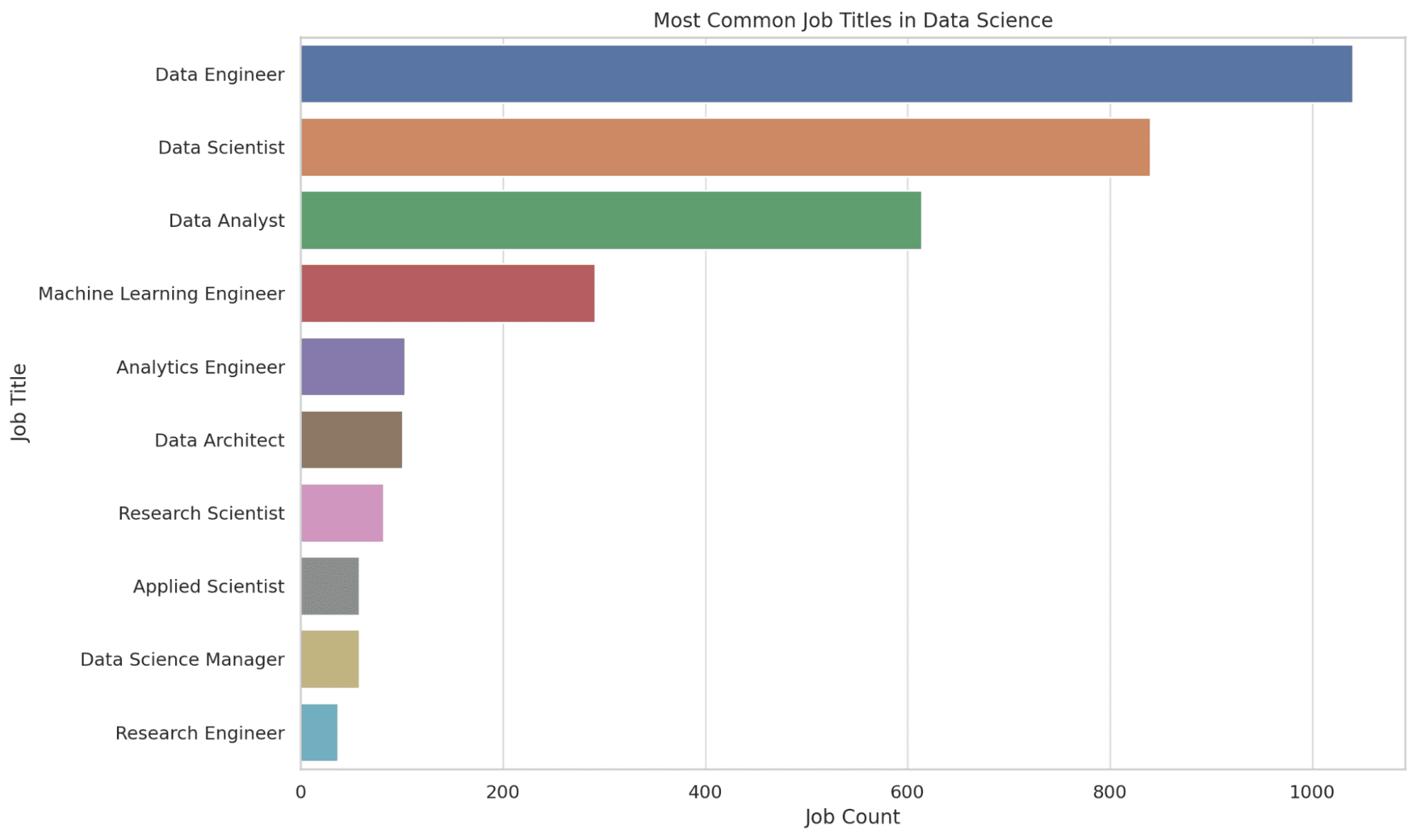
3. ¿Cómo varía la distribución salarial según el tamaño de la empresa?
En esta consulta, extraemos los salarios promedio, mínimo y máximo para cada grupo de tamaño de empresa. El uso de funciones agregadas como AVG, MIN y MAX ayuda a proporcionar una visión integral del panorama salarial en relación con el tamaño de una empresa.
Estos datos son esenciales ya que le ayudan a comprender las ganancias potenciales que puede esperar dependiendo del tamaño de la empresa a la que desea unirse. Veamos el código.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
Ahora visualicemos esta consulta usando Python.
Aquí está el código.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'Medium', 'Large'])
plt.title('Salary Distribution by Company Size')
plt.xlabel('Company Size')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Aquí está la salida.
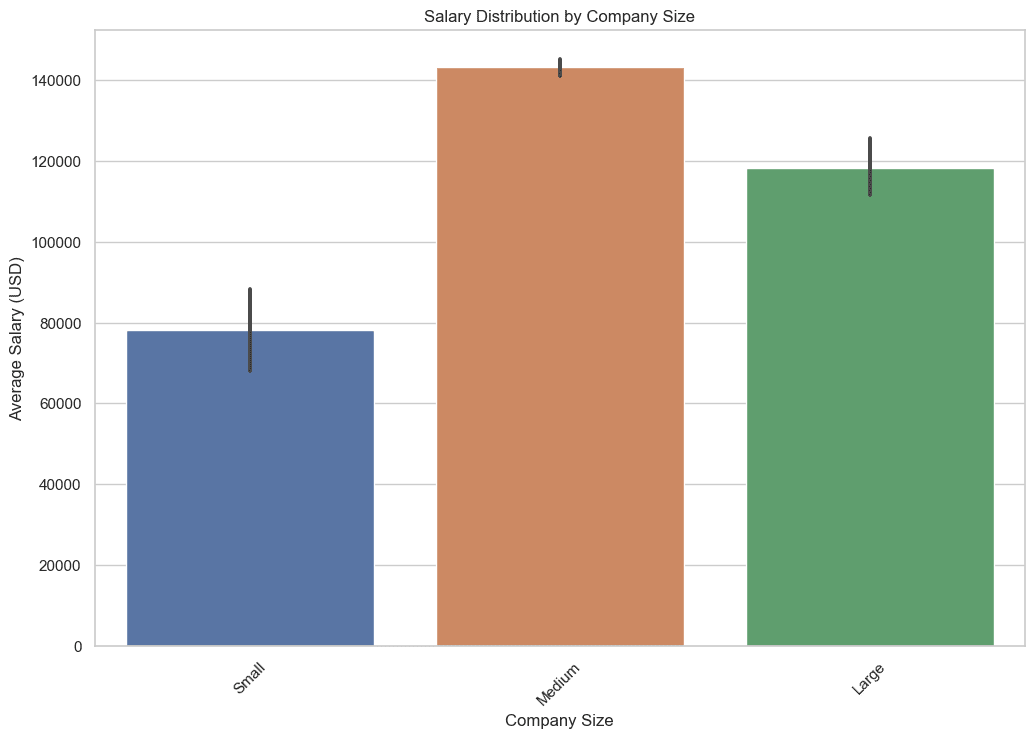
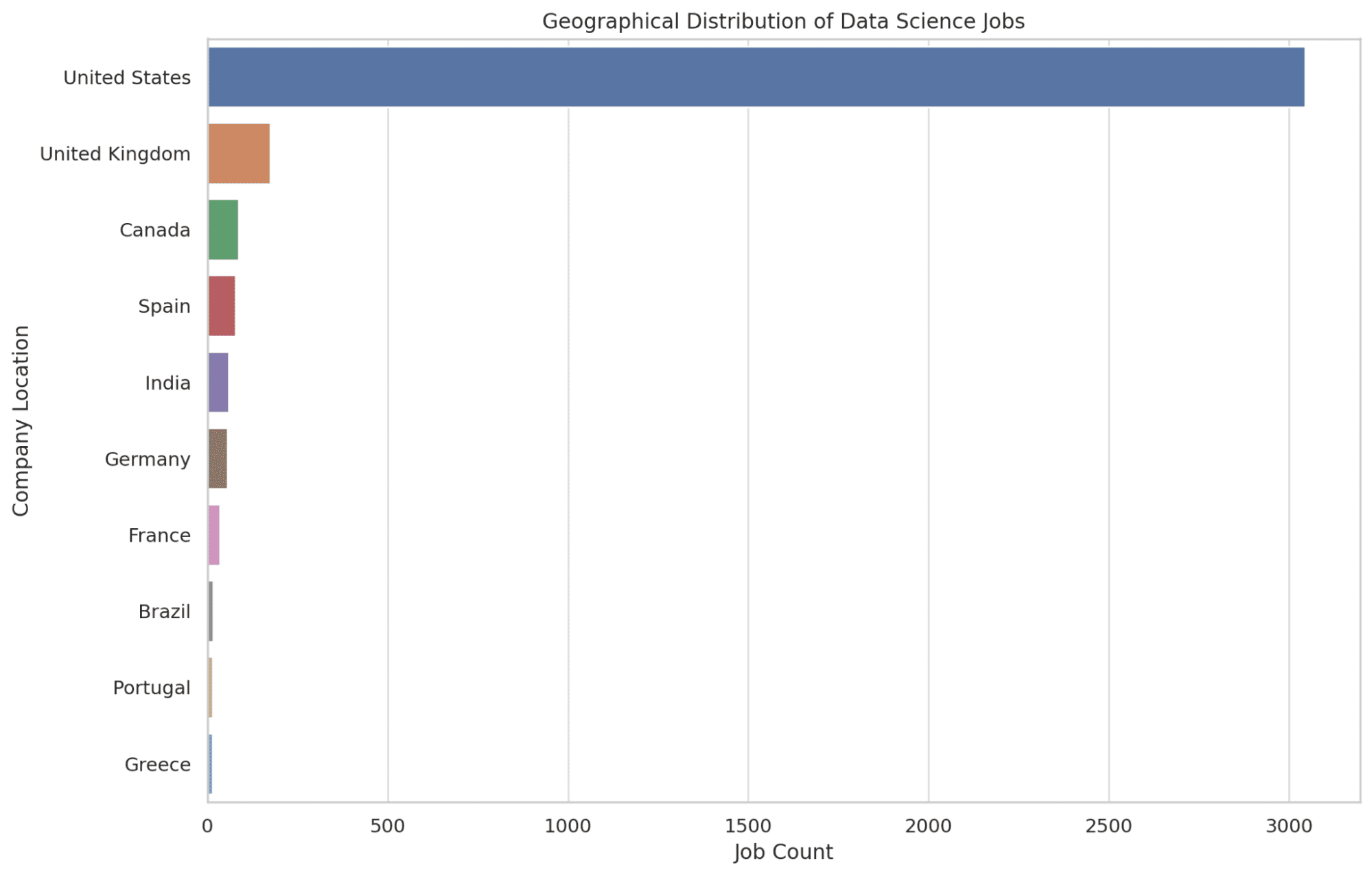
4. ¿Dónde se encuentran geográficamente principalmente los trabajos de ciencia de datos?
Aquí, identificamos las 10 ubicaciones principales que ofrecen la mayor cantidad de oportunidades laborales en ciencia de datos. Usamos la función CONTAR para determinar la cantidad de ofertas de trabajo en cada ubicación, organizándolas en orden descendente para destacar las áreas con más oportunidades.
Tener esta información brinda a los lectores conocimiento de las áreas geográficas que son centros para las funciones de ciencia de datos, lo que ayuda en posibles decisiones de reubicación. Veamos el código.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
Ahora creemos gráficos del código anterior, con Python.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Geographical Distribution of Data Science Jobs')
plt.xlabel('Job Count')
plt.ylabel('Company Location')
graphs.append(plt.gcf())
plt.show()
Veamos el gráfico a continuación.
5. ¿Qué puestos de trabajo ofrecen los mejores salarios en ciencia de datos?
Aquí, identificamos los 10 puestos de trabajo mejor pagados en el sector de la ciencia de datos. Al utilizar el AVG, calculamos el salario promedio para cada puesto de trabajo, clasificándolos en orden descendente según el salario promedio para resaltar los puestos más lucrativos.
Puede aspirar a lo que puede aspirar en su trayectoria profesional observando estos datos. Procedamos a comprender cómo los lectores pueden crear una visualización de Python para estos datos.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
Aquí está la salida.
(Aquí no podemos usar fotos, porque agregamos 4 fotos arriba y dejamos una como miniatura. ¿Tenemos la oportunidad de usar una tabla como la siguiente para demostrar el resultado?)
| Rango | Ocupación | Salario Promedio (USD) |
| 1 | Líder tecnológico de ciencia de datos | 375,000.00 |
| 2 | Arquitecto de datos en la nube | 250,000.00 |
| 3 | Cliente potencial de datos | 212,500.00 |
| 4 | Líder de análisis de datos | 211,254.50 |
| 5 | Científico de datos principal | 198,171.13 |
| 6 | Director de ciencia de datos | 195,140.73 |
| 7 | Ingeniero Principal de Datos | 192,500.00 |
| 8 | Ingeniero de software de aprendizaje automático | 192,420.00 |
| 9 | Gerente de Ciencia de Datos | 191,278.78 |
| 10 | Científico Aplicado | 190,264.48 |
Esta vez, intentemos crear un gráfico usted mismo.
Tips: Puede utilizar el siguiente mensaje en ChatGPT para generar un código Pythonic de este gráfico:
<SQL Query here> Create a Python graph to visualize the top 10 highest-paying job titles in Data Science, similar to the insights gathered from the given SQL query above.A medida que concluimos nuestro viaje a través de los diversos terrenos del mundo profesional de la ciencia de datos, esperamos que SQL demuestre ser una guía confiable que lo ayude a descubrir joyas de conocimientos que respalden sus decisiones profesionales.
Espero que ahora se sienta más preparado, no sólo para trazar su trayectoria profesional, sino también para utilizar SQL para transformar datos sin procesar en narrativas poderosas. Así que, ¡brindemos por dar un paso hacia un futuro lleno de oportunidades, con los datos como brújula y SQL como fuerza guía!
¡Gracias por leer!
Nate Rosidi es científico de datos y en estrategia de producto. También es profesor adjunto de enseñanza de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Gorjeo: StrataScratch or Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/using-sql-to-understand-data-science-career-trends?utm_source=rss&utm_medium=rss&utm_campaign=using-sql-to-understand-data-science-career-trends

