Por Dan Yu, Harry Foster y Tom Fitzpatrick
Bienvenido a la era de EDA 4.0, donde estamos presenciando una transformación revolucionaria en la automatización del diseño electrónico impulsada por el poder de la inteligencia artificial. La historia de EDA se puede delinear en distintos períodos marcados por importantes avances tecnológicos que han impulsado iteraciones de diseño más rápidas, mejorado la productividad y fomentado el desarrollo de sistemas electrónicos complejos.
En particular, el advenimiento de EDA 1.0 fue iniciado por la introducción de SPICE (programa de simulación con énfasis en circuitos integrados) en la Universidad de California, Berkeley, a principios de la década de 1970, que revolucionó el diseño de circuitos.
En la década de 1980 y principios de la de 1990, EDA 2.0 surgió como resultado del desarrollo de algoritmos eficientes de ubicación y ruta. Este período, también conocido como la era RTL, fue testigo de una transición del diseño a nivel de puerta a abstracciones de nivel superior, con el diseño RTL permitiendo descripciones de circuitos en el nivel de transferencia de registro, mejorando así el rendimiento de la simulación. Este período fue testigo de un hito significativo con la introducción de la síntesis lógica.
El auge de los diseños de sistema en chip (SoC) a fines de la década de 1990 y principios de la de 2000 marcó un momento crucial que condujo a EDA 3.0. Esta era fue testigo del surgimiento de una economía de desarrollo de propiedad intelectual junto con metodologías de reutilización de diseños. Las herramientas y los estándares de EDA se desarrollaron para respaldar el diseño, la verificación y la validación de SoC, lo que permite a los ingenieros gestionar la creciente complejidad de los diseños de clase SoC.
En muchos aspectos, EDA 4.0 se alinea con las tendencias más amplias de la Revolución Industrial 4.0, que está cambiando rápidamente la forma en que las empresas fabrican, mejoran y distribuyen sus productos, impulsada en parte por la digitalización del sector manufacturero. EDA 4.0 ha evolucionado para facilitar el diseño de dispositivos inteligentes y conectados, aprovechando el potencial de la computación en la nube y las capacidades de inteligencia artificial (IA) y aprendizaje automático (ML).


Las herramientas EDA ahora incorporan aprendizaje automático, creación de prototipos virtuales, un gemelo digital y metodologías de diseño a nivel de sistema para brindar verificación acelerada, flujos de trabajo de verificación automatizados y mayor precisión de verificación a los productos EDA. La era EDA 4.0 promete un rendimiento optimizado del producto, un tiempo de comercialización reducido y procesos de desarrollo y fabricación optimizados.
En este artículo, profundizamos en la implementación de vanguardia de soluciones de ML diseñadas específicamente para la verificación funcional. Exploramos los desafíos que enfrenta ML y presentamos técnicas y algoritmos novedosos que tienen relevancia en este dominio.
Temas de ML en verificación funcional
La Tabla 1 resume los temas y subtemas aplicables a la verificación funcional al incluir todos los temas de verificación funcional en la perspectiva general de la verificación del código de programación. El texto en cursiva indica subtemas que no se exploraron en otras publicaciones de encuestas generales.
Tabla 1: Temas de aplicaciones de ML en verificación funcional.

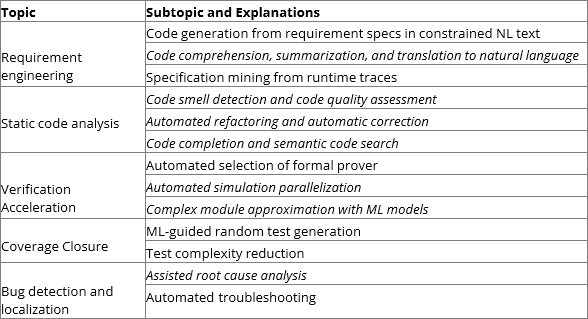
ingeniería de requisitos
La ingeniería de requisitos en la verificación funcional es el proceso de definir, documentar y mantener los requisitos de verificación, lo cual es fundamental para garantizar la excelente calidad del diseño de IC subyacente.
La definición de requisitos implica traducir objetivos de verificación de lenguaje natural (NL) ambiguos en especificaciones de verificación con formalidad y precisión. La calidad de la traducción dicta directamente la corrección de la verificación. Tradicionalmente, este proceso es laborioso y consume ciclos de diseño sustanciales con varias iteraciones de pruebas manuales para garantizar la calidad.
Se han propuesto dos grupos de enfoques clásicos para automatizar la traducción. Un grupo de enfoques consiste en introducir lenguaje natural restringido (CNL) para formalizar la redacción de especificaciones, seguido de un motor de traducción basado en plantillas. Este enfoque requiere una inversión inicial significativa en el desarrollo de una sintaxis CNL potente y un sistema completo de compilador/plantilla para garantizar que sea lo suficientemente potente como para abordar la mayoría de los requisitos que se encuentran en la verificación funcional. Además, carga a los desarrolladores con el aprendizaje de un idioma adicional, lo que evita que la idea sea ampliamente aceptada.
El otro grupo aprovecha el proceso de lenguaje natural clásico (NLP) para analizar las especificaciones de NL y extraer elementos clave relevantes para formular especificaciones formales.
El avance de la traducción ML en el dominio NL ha hecho que la traducción automática totalmente automatizada sea comercialmente factible y, a veces, supera el rendimiento de los traductores humanos promedio. Ha encendido la esperanza de aprovechar los modelos NL entrenados a gran escala con hasta miles de millones de parámetros para traducir directamente las especificaciones NL en especificaciones de verificación en SystemVerilog Assertions (SVA), Property Specification Language (PSL) u otros idiomas. Se han observado varios intentos de realizar una traducción exitosa de un extremo a otro, pero ninguno está listo para la producción. El principal obstáculo para este enfoque es la escasez de conjuntos de datos de entrenamiento disponibles que combinen las especificaciones de NL con su traducción formal. Los conjuntos de datos más extensos son simplemente alrededor de 100 pares de oraciones.. El número palidece en comparación con sus pares de NL, que habitualmente vienen en millones o incluso miles de millones de pares de oraciones.
A diferencia de la definición de requisitos, el resumen analiza el código y lo traduce a un resumen de NL comprensible para los humanos. Ayuda a los desarrolladores a leer código con un mantenimiento menos ideal oa comprender la lógica compleja. Un resumen de código idealmente implementado puede insertar documentación en línea en bloques de código o generar documentación separada. Con su ayuda, la capacidad de mantenimiento y la documentación del código se pueden mejorar significativamente.
La aplicación de ML en el resumen de código se ha experimentado en lenguajes informáticos más populares, por ejemplo, Python y JavaScript. Varios grupos de enfoques han experimentado con diversos grados de éxito. Los enfoques basados en la recuperación de información (IR) se centran en aplicar PNL al código fuente y buscar un código similar con el resumen existente. Este grupo de enfoques depende en gran medida de la calidad del código existente con resúmenes. Su uso solo es posible dentro de una organización cercana donde muchos repositorios de código existentes están fácilmente disponibles. En su lugar, los enfoques basados en heurísticas intentan definir reglas específicas basadas en heurísticas identificadas en la definición de un módulo, por ejemplo, un módulo con muchos submódulos de líneas de comando básicas de lectura/escritura podría considerarse un módulo de memoria. Por lo tanto, se puede construir un resumen a partir de un patrón predefinido para el módulo de memoria.
En el momento de escribir este artículo, el resumen de código en la verificación del diseño de circuitos integrados aún no se ha informado en ninguna literatura. Es razonable ser optimista de que el éxito de otros lenguajes se puede realizar en el diseño y la verificación de circuitos integrados, lo que aún debe ser confirmado por la comunidad investigadora. En particular, el progreso reciente con los modelos de varios idiomas podría ayudar a transferir el conocimiento aprendido de otros lenguajes de programación al diseño de circuitos integrados. Sin embargo, además de los desafíos generales de ML en el resumen de código, el paralelismo temporal intrínseco en el diseño de IC y el código de verificación puede presentar desafíos poco comunes en otros lenguajes de programación.
La minería de especificaciones ha sido un tema de ingeniería de software a largo plazo. Como alternativa a la redacción manual de especificaciones, extrae especificaciones indirectamente de la ejecución del diseño bajo prueba (DUT). ML se puede aplicar a la extracción de patrones recurrentes a partir de rastros de simulación. Puede ayudar a automatizar el cierre de cobertura basado en simulación o la verificación formal. Se supone que los patrones comúnmente recurrentes podrían ser el comportamiento esperado del DUT. Alternativamente, un patrón de eventos que rara vez ocurre en las trazas puede considerarse como una anomalía; por lo tanto, se puede utilizar con fines de diagnóstico y depuración.
ML se ha aplicado en el descubrimiento de patrones y la detección de anomalías en muchos dominios donde están disponibles los datos temporales de un sistema complejo. Azeem et al. Proponga un enfoque general de ingeniería de software en el que se use ML para descubrir especificaciones formales a partir de la observación de rastros de protocolo y encontrar la posible implementación problemática del protocolo. Los experimentos exitosos han inspirado interesantes proyectos de investigación de seguimiento en la minería de especificaciones con ML.
Análisis de código estático
A medida que el costo de corregir un error crece exponencialmente a lo largo de las etapas de desarrollo de IC, el análisis de código estático ofrece una opción atractiva para mejorar la calidad y la capacidad de mantenimiento del código en una etapa anterior del desarrollo del diseño.
El olor del código se refiere a patrones de diseño subóptimos en el código fuente, que pueden ser correctos desde el punto de vista sintáctico y semántico, pero violan las mejores prácticas y pueden conducir a una capacidad de mantenimiento deficiente del código. Un ejemplo particular es la duplicación de código, donde la misma función se implementa varias veces en un proyecto o en todo el código base. Algunas copias pueden corregir un error en particular en un período relativamente corto, mientras que el mismo error pasa desapercibido en otras copias.
La detección de olores de código clásico se basa en reglas heurísticas definidas para identificar patrones en el código fuente. En lugar de desarrollar manualmente estas reglas y métricas en las herramientas de análisis de código estático, se puede entrenar un enfoque basado en ML en una gran cantidad de código fuente disponible para identificar los olores del código. La investigación ha demostrado que la detección de olores con ML puede conducir a la detección de olores de código universal y a una cantidad significativamente menor de esfuerzos de implementación de patrones. El puntaje de olor resultante se puede usar para evaluar la calidad del código y ayudar a los desarrolladores a mejorar la calidad del producto de manera consistente. Además, la refactorización de código basada en ML podría proporcionar sugerencias útiles para mejorar el olor del código o incluso promover algunos cambios candidatos.
La aplicación de ML en la verificación funcional aún no es visible, y la falta de disponibilidad de grandes conjuntos de datos de entrenamiento ha impedido que la investigación existente explote completamente el potencial de esta solución.
Los desarrolladores que trabajan en el diseño de circuitos integrados pueden ser más productivos cuando se les proporcionan las herramientas adecuadas. La finalización de código simple es una función estándar en el entorno de desarrollo integrado (IDE) moderno. Sin embargo, se propusieron técnicas más avanzadas que involucran aprendizaje profundo y están madurando rápidamente. Ahora es posible entrenar ANN con miles de millones de parámetros de muchos repositorios de código de fuente abierta a gran escala para brindar recomendaciones razonables de fragmentos de código de la intención de implementación de los desarrolladores o el contexto.
ML también podría ayudar a los desarrolladores de IC a mantenerse productivos con la búsqueda de código semántico, que permite recuperar el código relevante mediante consultas de NL. Como el código suele estar lleno de varias abreviaturas y jerga técnica, las búsquedas semánticas pueden ser más eficaces para encontrar fragmentos de código relevantes sin escribir correctamente los nombres de las variables, funciones o módulos clave. Si bien es similar a la búsqueda semántica en muchos motores de búsqueda existentes, la búsqueda de código semántico puede ayudar a encontrar código abreviado y altamente técnico con conceptos vagos. La clasificación recíproca media del mejor modelo ya puede alcanzar puntuaciones utilizables del 70 %.
Aunque, en teoría, las mismas técnicas de ML aplicadas a otros lenguajes de programación se pueden aplicar al diseño de circuitos integrados, aún no se ha publicado ninguna investigación sobre la asistencia de codificación.
Aceleración de verificación
Encuestas recientes indican que la verificación funcional sigue siendo el paso que consume más tiempo en el diseño de circuitos integrados, y los errores funcionales y lógicos siguen siendo la causa más importante de un nuevo giro. Cualquier mejora en la velocidad de la verificación funcional tendrá un impacto significativo en la calidad y la productividad del diseño de circuitos integrados. ML se ha utilizado tanto en la verificación formal como en la basada en simulación para su aceleración.
La verificación formal utiliza algoritmos matemáticos formales para probar la corrección de un diseño. La orquestación de verificación formal moderna emplea algoritmos formales para diseñar diseños de diferentes tamaños, tipos y complejidades. La experiencia y la heurística pueden ayudar a los desarrolladores a seleccionar los algoritmos más apropiados de la biblioteca para un problema específico.
Como método estadístico, ML no puede abordar directamente los problemas de verificación formal. Sin embargo, se ha demostrado que es muy útil en la orquestación formal. Con su predicción de recursos informáticos y la probabilidad de resolver un problema, es posible programar solucionadores formales para utilizar mejor estos recursos para acortar el tiempo de verificación programando primero los solucionadores más prometedores con menor consumo de recursos informáticos. El clasificador basado en el árbol de decisiones de Ada-boost puede mejorar la proporción de instancias resueltas desde la orquestación de referencia del 95 % al 97 %, con una velocidad promedio de 1.85. Otro experimento fue capaz de predecir los requisitos de recursos de verificación formal con un error promedio del 32%. Aplica iterativamente la ingeniería de características para seleccionar cuidadosamente las características del DUT, las propiedades y las restricciones formales, que luego se utilizan para entrenar un modelo de regresión lineal múltiple para la predicción de los requisitos de recursos.
A diferencia de la verificación formal, la verificación basada en simulación generalmente no puede garantizar la corrección completa del diseño. En cambio, el diseño se somete a un banco de pruebas con ciertos estímulos de entrada aleatorios o de patrón fijo aplicados, mientras que las salidas se comparan con las salidas de referencia para verificar si se espera el comportamiento del diseño. Si bien la simulación es el pan y la mantequilla de la verificación funcional, la verificación basada en simulación también puede sufrir largos tiempos de verificación. No es raro que la verificación de un diseño complejo tarde semanas en completarse.
Una idea prometedora que se está discutiendo y experimentando es el uso de ML para modelar y predecir el comportamiento de un sistema complejo. El teorema de aproximación universal demuestra que un perceptrón multicapa (MLP), una RNA de avance con al menos una capa oculta, puede aproximar cualquier función continua con precisión arbitraria. Mientras que se ha demostrado que las redes neuronales recurrentes normalizadas (RNN), una forma especializada de ANN, se aproximan a cualquier sistema dinámico con memoria. El hardware acelerador de ML avanzado ha hecho posible que las ANN puedan modelar los comportamientos de algunos módulos de diseño de IC para acelerar sus simulaciones. Se puede lograr una aceleración significativa según la capacidad de los aceleradores de IA y la complejidad de los modelos de ML.
Generación de pruebas y cierre de cobertura
Además de los patrones de prueba definidos manualmente, las técnicas estándar empleadas en la verificación basada en simulación incluyen la generación aleatoria de pruebas y la automatización inteligente de bancos de pruebas basada en gráficos. Debido a la naturaleza de “cola larga” del cierre de la cobertura, incluso una pequeña mejora en la eficiencia puede resultar fácilmente en una reducción significativa del tiempo de simulación. Gran parte de la investigación sobre la aplicación de ML a la verificación funcional se ha centrado en esta área.
Amplios estudios de ML han demostrado que pueden funcionar mejor que la generación aleatoria de pruebas. La mayoría de las investigaciones emplean un "modelo de caja negra", asumiendo que un DUT es una caja negra cuyas entradas se pueden controlar y las salidas se pueden monitorear. Opcionalmente, se pueden observar algunos puntos de prueba. La investigación no busca comprender el comportamiento del DUT. En cambio, el enfoque se dedica a reducir las pruebas innecesarias. Emplean varias técnicas de ML para aprender de los datos históricos de entrada/salida/observación para ajustar los generadores de pruebas aleatorias o eliminar las pruebas que probablemente no sean útiles. En un desarrollo reciente, se utilizó un modelo basado en el aprendizaje por refuerzo (RL) para aprender de la salida de un DUT y predecir las pruebas más probables para un controlador de caché. Cuando la recompensa otorgada al modelo ML son las profundidades FIFO, los experimentos pueden aprender de los resultados históricos y alcanzar las profundidades FIFO objetivo completas en varias iteraciones, mientras que el enfoque basado en la generación de pruebas aleatorias todavía tiene dificultades para alcanzar más de 1. Una arquitectura de ML con una granularidad mucho más fina requiere que se entrene un modelo de ML para cada punto de cobertura. También se emplea un clasificador ternario para ayudar a decidir si una prueba debe simularse, descartarse o usarse para volver a entrenar un modelo. La máquina de vectores de soporte (SVM), el bosque aleatorio y la red neuronal profunda se experimentan en un diseño de CPU. Puede cerrar una cobertura del 100 % con 3 a 5 veces menos pruebas. Experimentos adicionales en diseños FSM y no FSM han demostrado reducciones del 69 % y 72 % en comparación con la generación de secuencias dirigidas. Sin embargo, la mayoría de estos resultados todavía sufren de la limitación de la naturaleza estadística de ML. Una revisión más completa de la generación de pruebas dirigidas por cobertura (CDG) basada en ML brinda una descripción general de varios modelos de ML y los resultados de sus experimentos. Los algoritmos genéticos de red bayesiana y los enfoques de programación genética, el modelo de Markov, la extracción de datos y la programación lógica inductiva son todos experimentos con diversos grados de éxito.
En todos los enfoques discutidos, un modelo de ML puede hacer una predicción basada en el aprendizaje de los datos históricos que ha recopilado, pero tiene la capacidad mínima para predecir el futuro, es decir, qué prueba podría ser una opción más prometedora para alcanzar un objetivo de prueba descubierto. Como este tipo de información aún no está disponible, lo mejor que pueden hacer es elegir las pruebas que son más irrelevantes para las pruebas históricas. Otro experimento prometedor exploró un enfoque diferente, en el que el dispositivo bajo prueba se considera como una caja blanca y el código se analiza y convierte en un gráfico de control/flujo de datos (CDFG). Se utiliza una búsqueda basada en gradientes en una red neuronal gráfica (GNN) entrenada para generar pruebas para un objetivo de prueba predefinido. Los experimentos en IBEX v1, v2 y TPU lograron una precisión del 74 %, 73 % y 90 % en la predicción de cobertura cuando se entrenaron con puntos de cobertura del 50 %. Varios experimentos adicionales también confirman que el método de búsqueda de gradientes empleado es insensible a la arquitectura GNN.
Se observa que debido a la falta de disponibilidad de datos de entrenamiento, la mayoría de estos enfoques de ML solo aprenden de cada diseño sin explotar ningún conocimiento previo de otros diseños similares.
Análisis de errores
El análisis de errores tiene como objetivo identificar errores potenciales, localizar los bloques de código que los contienen y brindar sugerencias de solución. Encuestas recientes encontraron que la verificación de un IC lleva aproximadamente la misma cantidad de tiempo que en el diseño y que los errores funcionales contribuyen a aproximadamente el 50% de los respins para un diseño ASIC. Por lo tanto, es de vital importancia que estos errores se puedan identificar y corregir en la etapa inicial de verificación funcional. ML se ha empleado para ayudar a los desarrolladores a detectar errores en los diseños y encontrar errores más rápido.
Se deben resolver tres problemas progresivos para acelerar la búsqueda de errores en la verificación funcional, a saber, la agrupación de errores por sus causas principales, la clasificación de las causas principales y la sugerencia de soluciones. La mayor parte de la investigación se centra en los dos primeros, y aún no se dispone de resultados de investigación sobre el tercero.
Los archivos de registro de simulación semiestructurados se pueden utilizar para el análisis de errores. Extrae 616 características diferentes de metadatos y líneas de mensajes de archivos de registro de diseños no revelados. El experimento de agrupamiento logró información mutua ajustada (AMI) de 0.543 con K-means y agrupamiento aglomerativo y 0.593 con DBSCAN incluso después de la reducción de la dimensionalidad de características, lejos del agrupamiento ideal cuando AMI alcanza 1.0. También se probaron varios algoritmos de clasificación para determinar su precisión en la resolución del problema 2. Todos los algoritmos, incluido el bosque aleatorio, la clasificación de vectores de soporte (SVC), el árbol de decisión, la regresión logística, los vecinos K y el bayesiano ingenuo, se comparan en su poder para predecir las causas fundamentales. La mejor puntuación se logró mediante bosque aleatorio con una precisión de predicción del 90.7 % y puntuaciones F0.913 de 1. Otro enfoque propone utilizar un conjunto de datos etiquetados del compromiso de código para entrenar un modelo de aumento de gradiente, donde se probaron más de 100 características sobre autores, revisiones, códigos y proyectos hasta que se seleccionaron 36 para el algoritmo. Los experimentos muestran que es posible predecir qué confirmaciones tienen más probabilidades de contener código con errores y potencialmente reducir significativamente el tiempo de búsqueda manual de errores.
Sin embargo, debido a la relativa simplicidad de las técnicas de ML adoptadas, no pueden entrenar modelos de ML que puedan considerar una semántica rica en código o aprender de las correcciones de errores históricas. Por lo tanto, no pueden explicar por qué y cómo ocurren los errores ni sugerir revisar el código para eliminar los errores de forma automática o semiautomática.
Técnicas y modelos de ML emergentes aplicables a la verificación funcional
En los últimos años se han presenciado avances significativos en técnicas, modelos y algoritmos de ML. Nuestra investigación encontró que muy pocas de estas técnicas emergentes son adoptadas por la investigación de verificación funcional y, con optimismo, creemos que será posible un gran éxito una vez que se utilicen para abordar problemas desafiantes en la verificación funcional.
Los modelos de NL a gran escala basados en transformadores con miles de millones de parámetros entrenados en las enormes cantidades de corpus de texto lograron un rendimiento de nivel casi humano o superior al humano en diversas tareas de NL, por ejemplo, respuesta a preguntas, traducción automática, clasificación de texto, resumen abstracto y otros. La aplicación de estos resultados de investigación en el análisis de código también ha demostrado el gran potencial y versatilidad de estos modelos. Se ha demostrado que estos modelos realmente pueden ingerir un gran corpus de datos de entrenamiento, estructurar el conocimiento aprendido y proporcionar una fácil accesibilidad. Esta capacidad es fundamental en el análisis de código estático, la ingeniería de requisitos y la asistencia de codificación para varios lenguajes de programación populares. Dados suficientes datos de entrenamiento, es razonable creer que estas técnicas pueden entrenar modelos ML para varias tareas de verificación funcional.
Hasta hace poco, era difícil aplicar ML a datos gráficos debido a la complejidad de su estructura. Los avances de la red neuronal gráfica (GNN) han prometido una nueva oportunidad para la verificación funcional. Uno de estos enfoques convierte un diseño en un gráfico de flujo de código/datos, que luego se usa para entrenar un GNN para ayudar a predecir el cierre de cobertura de una prueba. Este tipo de enfoque de caja blanca promete una visión que antes no estaba disponible sobre el control y el flujo de datos en un diseño, lo que puede generar pruebas dirigidas para llenar los posibles agujeros de cobertura. Los gráficos pueden representar una rica información relacional, estructural y semántica encontrada en la verificación. La rica información del entrenamiento de un modelo ML en gráficos puede permitir muchas tareas de verificación funcional nuevas posibles, por ejemplo, búsqueda de errores y cierre de cobertura.
Conclusión
EDA 4.0 está transformando la automatización del diseño electrónico a través del poder de la inteligencia artificial y ofrece varias tecnologías clave que ayudarán a los ingenieros a realizar los cambios revolucionarios de la Industria 4.0. En este artículo proporcionamos un estudio exhaustivo de las contribuciones potenciales del aprendizaje automático para abordar varios aspectos de la verificación funcional. El artículo destaca las aplicaciones típicas de ML en la verificación funcional y resume los logros más avanzados en este campo.
Sin embargo, a pesar de la aplicación de diversas técnicas de ML, la investigación actual se basa principalmente en métodos básicos de ML y está limitada por la disponibilidad de datos de entrenamiento. Esta situación recuerda las primeras etapas de las aplicaciones de ML en otros dominios avanzados, lo que indica que las aplicaciones de ML en la verificación funcional aún se encuentran en su fase inicial. Queda un importante potencial sin explotar para aprovechar técnicas y modelos avanzados para explotar completamente las capacidades de ML. Además, la utilización de información semántica, relacional y estructural en las aplicaciones de ML de hoy en día aún no se realiza por completo.
Para una exploración más detallada de este tema, lo invitamos a consultar nuestro informe técnico titulado Una encuesta de aplicaciones de aprendizaje automático en la verificación funcional. En este informe técnico, profundizamos en el tema, ofrecemos información desde una perspectiva industrial y discutimos el desafío apremiante que plantea la disponibilidad limitada de datos. El documento completo también incluye referencias exhaustivas a las fascinantes investigaciones y escritos que informan gran parte de este artículo.
Harry Foster es Jefe Científico de Verificación de Siemens Digital Industries Software; y es cofundador y editor ejecutivo de Verification Academy. Foster se desempeñó como presidente general de la Conferencia de automatización de diseño de 2021 y actualmente se desempeña como presidente anterior. Posee múltiples patentes en verificación y es coautor de seis libros sobre verificación. Foster recibió el premio Accellera Technical Excellence Award por sus contribuciones al desarrollo de estándares de la industria y fue el creador original del estándar Accellera Open Verification Library (OVL). Además, Foster recibió el Premio al Servicio Distinguido de ACM de 2022 y el Premio al Servicio Destacado de IEEE CEDA de 2022.
Tom Fitzpatrick es arquitecto de verificación estratégica en Siemens Digital Industries Software (Siemens EDA), donde trabaja en el desarrollo de metodologías, lenguajes y estándares de verificación avanzados. Ha contribuido significativamente a varios estándares de la industria que han mejorado drásticamente el panorama de la verificación funcional durante los últimos 25 años, incluidos Verilog 1364, SystemVerilog 1800 y UVM 1800.2. Es miembro fundador y actual vicepresidente del grupo de trabajo Accellera Portable Stimulus y actualmente se desempeña como presidente de los grupos de trabajo IEEE 1800 y Accellera UVM-AMS. Fitzpatrick es miembro desde hace mucho tiempo del Comité Directivo de DVCon US y es el Presidente General de DVConUS 2024. También es miembro del Comité Ejecutivo de la Conferencia de Automatización de Diseño. Fitzpatrick tiene una maestría y una licenciatura en ingeniería eléctrica y ciencias de la computación del MIT.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

