Esta publicación está coescrita con Santosh Waddi y Nanda Kishore Thatikonda de BigBasket.
BigBasket es la tienda de comestibles y alimentos en línea más grande de la India. Operan en múltiples canales de comercio electrónico, como comercio rápido, entrega programada y suscripciones diarias. También podrás comprar en sus tiendas físicas y máquinas expendedoras. Ofrecen una gran variedad de más de 50,000 productos en 1,000 marcas y operan en más de 500 ciudades y pueblos. BigBasket atiende a más de 10 millones de clientes.
En esta publicación, analizamos cómo utilizó BigBasket Amazon SageMaker entrenar su modelo de visión por computadora para la identificación de productos de bienes de consumo de rápido movimiento (FMCG), lo que les ayudó a reducir el tiempo de capacitación en aproximadamente un 50 % y ahorrar costos en un 20 %.
Desafíos del cliente
Hoy en día, la mayoría de los supermercados y tiendas físicas de la India ofrecen pago manual en la caja. Esto tiene dos problemas:
- Requiere mano de obra adicional, etiquetas de peso y capacitación repetida para el equipo operativo de la tienda a medida que escalan.
- En la mayoría de las tiendas, el mostrador de caja es diferente de los mostradores de pesaje, lo que aumenta la fricción en el proceso de compra del cliente. Los clientes a menudo pierden la etiqueta de peso y tienen que volver a los mostradores de pesaje para recogerla nuevamente antes de continuar con el proceso de pago.
Proceso de autopago
BigBasket introdujo un sistema de pago impulsado por inteligencia artificial en sus tiendas físicas que utiliza cámaras para distinguir los artículos de forma única. La siguiente figura proporciona una descripción general del proceso de pago.
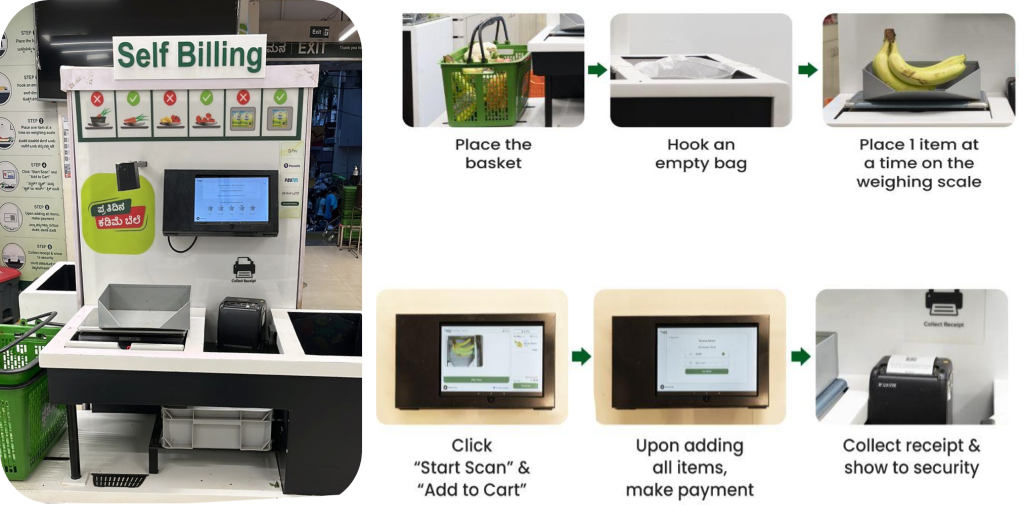
El equipo de BigBasket estaba ejecutando algoritmos de aprendizaje automático internos de código abierto para el reconocimiento de objetos por visión por computadora para impulsar el proceso de pago habilitado por IA en su Fresco tiendas (físicas). Nos enfrentábamos a los siguientes desafíos para operar su configuración existente:
- Con la introducción continua de nuevos productos, el modelo de visión por computadora necesitaba incorporar continuamente nueva información de productos. El sistema necesitaba manejar un gran catálogo de más de 12,000 600 unidades de mantenimiento de existencias (SKU), y se agregaban continuamente nuevas SKU a un ritmo de más de XNUMX por mes.
- Para seguir el ritmo de los nuevos productos, cada mes se producía un nuevo modelo utilizando los últimos datos de entrenamiento. Era costoso y requería mucho tiempo entrenar los modelos con frecuencia para adaptarlos a nuevos productos.
- BigBasket también quería reducir el tiempo del ciclo de formación para mejorar el tiempo de comercialización. Debido a los aumentos en los SKU, el tiempo que tardaba el modelo aumentaba linealmente, lo que afectaba su tiempo de comercialización porque la frecuencia de capacitación era muy alta y tomaba mucho tiempo.
- El aumento de datos para la capacitación de modelos y la gestión manual del ciclo de capacitación completo de un extremo a otro estaba agregando una sobrecarga significativa. BigBasket lo ejecutaba en una plataforma de terceros, lo que generaba costes importantes.
Resumen de la solución
Recomendamos que BigBasket rediseñara su solución existente de detección y clasificación de productos de bienes de consumo masivo utilizando SageMaker para abordar estos desafíos. Antes de pasar a la producción a gran escala, BigBasket probó un piloto en SageMaker para evaluar métricas de rendimiento, costo y conveniencia.
Su objetivo era ajustar un modelo de aprendizaje automático (ML) de visión por computadora existente para la detección de SKU. Utilizamos una arquitectura de red neuronal convolucional (CNN) con ResNet152 para la clasificación de imágenes. Se estimó un conjunto de datos considerable de alrededor de 300 imágenes por SKU para el entrenamiento del modelo, lo que dio como resultado más de 4 millones de imágenes de entrenamiento en total. Para ciertos SKU, aumentamos los datos para abarcar una gama más amplia de condiciones ambientales.
El siguiente diagrama ilustra la arquitectura de la solución.

El proceso completo se puede resumir en los siguientes pasos de alto nivel:
- Realice limpieza, anotación y aumento de datos.
- Almacenar datos en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
- Utilice SageMaker y Amazon FSx para Lustre para un aumento eficiente de los datos.
- Divida los datos en conjuntos de entrenamiento, validación y prueba. Usamos FSx para Lustre y Servicio de base de datos relacional de Amazon (Amazon RDS) para un rápido acceso a datos paralelos.
- Utilice una costumbre PyTorch Contenedor Docker que incluye otras bibliotecas de código abierto.
- Uso Paralelismo de datos distribuidos de SageMaker (SMDDP) para capacitación distribuida acelerada.
- Métricas de entrenamiento del modelo de registro.
- Copie el modelo final en un depósito S3.
BigBasket usado Cuadernos SageMaker para entrenar sus modelos de aprendizaje automático y pudieron trasladar fácilmente su PyTorch de código abierto existente y otras dependencias de código abierto a un contenedor PyTorch de SageMaker y ejecutar el proceso sin problemas. Este fue el primer beneficio visto por el equipo de BigBasket, porque apenas se necesitaron cambios en el código para hacerlo compatible para ejecutarse en un entorno SageMaker.
La red modelo consta de una arquitectura ResNet 152 seguida de capas completamente conectadas. Congelamos las capas de entidades de bajo nivel y conservamos los pesos adquiridos mediante el aprendizaje por transferencia del modelo ImageNet. Los parámetros totales del modelo fueron 66 millones, de los cuales 23 millones de parámetros se pueden entrenar. Este enfoque basado en el aprendizaje por transferencia les ayudó a utilizar menos imágenes en el momento del entrenamiento y también permitió una convergencia más rápida y redujo el tiempo total de entrenamiento.
Construyendo y entrenando el modelo dentro Estudio Amazon SageMaker proporcionó un entorno de desarrollo integrado (IDE) con todo lo necesario para preparar, construir, entrenar y ajustar modelos. Aumentar los datos de entrenamiento utilizando técnicas como recortar, rotar y voltear imágenes ayudó a mejorar los datos de entrenamiento del modelo y la precisión del modelo.
La capacitación del modelo se aceleró en un 50 % mediante el uso de la biblioteca SMDDP, que incluye algoritmos de comunicación optimizados diseñados específicamente para la infraestructura de AWS. Para mejorar el rendimiento de lectura/escritura de datos durante el entrenamiento del modelo y el aumento de datos, utilizamos FSx para Lustre para un rendimiento de alto rendimiento.
El tamaño inicial de sus datos de entrenamiento fue de más de 1.5 TB. Usamos dos Nube informática elástica de Amazon (Amazon EC2) p4d.24 instancias grandes con 8 GPU y 40 GB de memoria GPU. Para la capacitación distribuida de SageMaker, las instancias deben estar en la misma región y zona de disponibilidad de AWS. Además, los datos de entrenamiento almacenados en un depósito de S3 deben estar en la misma zona de disponibilidad. Esta arquitectura también permite a BigBasket cambiar a otros tipos de instancias o agregar más instancias a la arquitectura actual para atender cualquier crecimiento significativo de datos o lograr una mayor reducción en el tiempo de capacitación.
Cómo la biblioteca SMDDP ayudó a reducir el tiempo, el costo y la complejidad de la capacitación
En el entrenamiento tradicional de datos distribuidos, el marco de entrenamiento asigna rangos a las GPU (trabajadores) y crea una réplica de su modelo en cada GPU. Durante cada iteración de entrenamiento, el lote de datos globales se divide en partes (fragmentos de lote) y se distribuye una parte a cada trabajador. Luego, cada trabajador procede con el paso hacia adelante y hacia atrás definido en su script de entrenamiento en cada GPU. Finalmente, los pesos y gradientes del modelo de las diferentes réplicas del modelo se sincronizan al final de la iteración a través de una operación de comunicación colectiva llamada AllReduce. Después de que cada trabajador y GPU tengan una réplica sincronizada del modelo, comienza la siguiente iteración.
La biblioteca SMDDP es una biblioteca de comunicación colectiva que mejora el rendimiento de este proceso de entrenamiento paralelo de datos distribuidos. La biblioteca SMDDP reduce la sobrecarga de comunicación de las operaciones de comunicación colectiva clave, como AllReduce. Su implementación de AllReduce está diseñada para la infraestructura de AWS y puede acelerar el entrenamiento al superponer la operación de AllReduce con el paso hacia atrás. Este enfoque logra una eficiencia de escalado casi lineal y una velocidad de entrenamiento más rápida al optimizar las operaciones del kernel entre CPU y GPU.
Tenga en cuenta los siguientes cálculos:
- El tamaño del lote global es (número de nodos en un clúster) * (número de GPU por nodo) * (por fragmento de lote)
- Un fragmento por lotes (lote pequeño) es un subconjunto del conjunto de datos asignado a cada GPU (trabajador) por iteración.
BigBasket utilizó la biblioteca SMDDP para reducir su tiempo total de capacitación. Con FSx para Lustre, reducimos el rendimiento de lectura/escritura de datos durante el entrenamiento del modelo y el aumento de datos. Con el paralelismo de datos, BigBasket pudo lograr una capacitación casi un 50 % más rápida y un 20 % más barata en comparación con otras alternativas, ofreciendo el mejor rendimiento en AWS. SageMaker cierra automáticamente el proceso de capacitación una vez finalizado. El proyecto se completó con éxito con un tiempo de capacitación un 50 % más rápido en AWS (4.5 días en AWS frente a 9 días en su plataforma heredada).
Al momento de escribir esta publicación, BigBasket ha estado ejecutando la solución completa en producción durante más de 6 meses y ampliando el sistema atendiendo a nuevas ciudades, y estamos agregando nuevas tiendas cada mes.
“Nuestra asociación con AWS para la migración a la capacitación distribuida utilizando su oferta SMDDP ha sido una gran victoria. No sólo redujo nuestros tiempos de formación en un 50%, sino que también fue un 20% más barato. En toda nuestra asociación, AWS ha puesto el listón en la obsesión del cliente y la entrega de resultados, trabajando con nosotros en todo momento para lograr los beneficios prometidos”.
– Keshav Kumar, jefe de ingeniería de BigBasket.
Conclusión
En esta publicación, analizamos cómo BigBasket utilizó SageMaker para entrenar su modelo de visión por computadora para la identificación de productos de bienes de consumo. La implementación de un sistema de autopago automatizado impulsado por IA ofrece una experiencia mejorada para el cliente minorista a través de la innovación, al tiempo que elimina los errores humanos en el proceso de pago. Acelerar la incorporación de nuevos productos mediante el uso de la capacitación distribuida de SageMaker reduce el tiempo y el costo de incorporación de SKU. La integración de FSx para Lustre permite un rápido acceso a datos paralelos para un reentrenamiento eficiente del modelo con cientos de nuevos SKU mensualmente. En general, esta solución de autopago basada en inteligencia artificial proporciona una experiencia de compra mejorada sin errores de pago en la interfaz. La automatización y la innovación han transformado sus operaciones de incorporación y pago minorista.
SageMaker proporciona capacidades de monitoreo, implementación y desarrollo de aprendizaje automático de un extremo a otro, como un entorno de computadora portátil SageMaker Studio para escribir código, adquisición de datos, etiquetado de datos, entrenamiento de modelos, ajuste de modelos, implementación, monitoreo y mucho más. Si su empresa enfrenta alguno de los desafíos descritos en esta publicación y desea ahorrar tiempo de comercialización y mejorar los costos, comuníquese con el equipo de cuentas de AWS en su región y comience a usar SageMaker.
Acerca de los autores
 Santosh Waddi es ingeniero principal en BigBasket y aporta más de una década de experiencia en la resolución de desafíos de IA. Con una sólida experiencia en visión por computadora, ciencia de datos y aprendizaje profundo, tiene un posgrado del IIT Bombay. Santosh es autor de notables publicaciones de IEEE y, como autor experimentado de blogs de tecnología, también ha realizado importantes contribuciones al desarrollo de soluciones de visión por computadora durante su mandato en Samsung.
Santosh Waddi es ingeniero principal en BigBasket y aporta más de una década de experiencia en la resolución de desafíos de IA. Con una sólida experiencia en visión por computadora, ciencia de datos y aprendizaje profundo, tiene un posgrado del IIT Bombay. Santosh es autor de notables publicaciones de IEEE y, como autor experimentado de blogs de tecnología, también ha realizado importantes contribuciones al desarrollo de soluciones de visión por computadora durante su mandato en Samsung.
 Nanda Kishore Thatikonda es un Gerente de Ingeniería que lidera la Ingeniería y Análisis de Datos en BigBasket. Nanda ha creado múltiples aplicaciones para la detección de anomalías y tiene una patente presentada en un espacio similar. Ha trabajado en la creación de aplicaciones de nivel empresarial, la creación de plataformas de datos en múltiples organizaciones y plataformas de informes para agilizar las decisiones respaldadas por datos. Nanda tiene más de 18 años de experiencia trabajando en Java/J2EE, tecnologías Spring y marcos de big data utilizando Hadoop y Apache Spark.
Nanda Kishore Thatikonda es un Gerente de Ingeniería que lidera la Ingeniería y Análisis de Datos en BigBasket. Nanda ha creado múltiples aplicaciones para la detección de anomalías y tiene una patente presentada en un espacio similar. Ha trabajado en la creación de aplicaciones de nivel empresarial, la creación de plataformas de datos en múltiples organizaciones y plataformas de informes para agilizar las decisiones respaldadas por datos. Nanda tiene más de 18 años de experiencia trabajando en Java/J2EE, tecnologías Spring y marcos de big data utilizando Hadoop y Apache Spark.
 Odio Sudhanshu es un especialista principal en IA y aprendizaje automático en AWS y trabaja con clientes para asesorarlos sobre sus MLOps y su recorrido por la IA generativa. En su puesto anterior, conceptualizó, creó y dirigió equipos para construir una plataforma de gamificación e inteligencia artificial basada en código abierto y desde cero, y la comercializó con éxito con más de 100 clientes. Sudhanshu tiene en su haber un par de patentes; ha escrito 2 libros, varios artículos y blogs; y ha expuesto su punto de vista en diversos foros. Ha sido un líder intelectual y orador, y ha estado en la industria durante casi 25 años. Ha trabajado con clientes de Fortune 1000 en todo el mundo y, más recientemente, está trabajando con clientes nativos digitales en India.
Odio Sudhanshu es un especialista principal en IA y aprendizaje automático en AWS y trabaja con clientes para asesorarlos sobre sus MLOps y su recorrido por la IA generativa. En su puesto anterior, conceptualizó, creó y dirigió equipos para construir una plataforma de gamificación e inteligencia artificial basada en código abierto y desde cero, y la comercializó con éxito con más de 100 clientes. Sudhanshu tiene en su haber un par de patentes; ha escrito 2 libros, varios artículos y blogs; y ha expuesto su punto de vista en diversos foros. Ha sido un líder intelectual y orador, y ha estado en la industria durante casi 25 años. Ha trabajado con clientes de Fortune 1000 en todo el mundo y, más recientemente, está trabajando con clientes nativos digitales en India.
 ayush kumar es arquitecto de soluciones en AWS. Trabaja con una amplia variedad de clientes de AWS, ayudándolos a adoptar las últimas aplicaciones modernas e innovar más rápido con tecnologías nativas de la nube. Lo encontrarás experimentando en la cocina en su tiempo libre.
ayush kumar es arquitecto de soluciones en AWS. Trabaja con una amplia variedad de clientes de AWS, ayudándolos a adoptar las últimas aplicaciones modernas e innovar más rápido con tecnologías nativas de la nube. Lo encontrarás experimentando en la cocina en su tiempo libre.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

