Esta publicación fue escrita en colaboración con Bhajandeep Singh y Ajay Vishwakarma de AWS AI/ML Practice de Wipro.
Muchas organizaciones han estado utilizando una combinación de soluciones de ciencia de datos locales y de código abierto para crear y gestionar modelos de aprendizaje automático (ML).
Los equipos de ciencia de datos y DevOps pueden enfrentar desafíos al administrar estos sistemas y conjuntos de herramientas aislados. La integración de múltiples conjuntos de herramientas para crear una solución compacta puede implicar la creación de conectores o flujos de trabajo personalizados. Administrar diferentes dependencias en función de la versión actual de cada pila y mantener esas dependencias con el lanzamiento de nuevas actualizaciones de cada pila complica la solución. Esto aumenta el costo de mantenimiento de la infraestructura y obstaculiza la productividad.
Ofertas de inteligencia artificial (IA) y aprendizaje automático (ML) de Servicios Web de Amazon (AWS), junto con servicios integrados de monitoreo y notificación, ayudan a las organizaciones a alcanzar el nivel requerido de automatización, escalabilidad y calidad de modelo a un costo óptimo. AWS también ayuda a los equipos de ciencia de datos y DevOps a colaborar y agilizar el proceso general del ciclo de vida del modelo.
El portafolio de servicios de aprendizaje automático de AWS incluye un sólido conjunto de servicios que puede utilizar para acelerar el desarrollo, la capacitación y la implementación de aplicaciones de aprendizaje automático. El conjunto de servicios se puede utilizar para respaldar el ciclo de vida completo del modelo, incluido el monitoreo y el reentrenamiento de los modelos de ML.
En esta publicación, analizamos el desarrollo de modelos y la implementación del marco MLOps para uno de los clientes de Wipro que utiliza Amazon SageMaker y otros servicios de AWS.
Wipro es un Socio de servicios de nivel Premier de AWS y Proveedor de Servicios Gestionados (MSP). Es Soluciones de IA/ML impulsar una mayor eficiencia operativa, productividad y experiencia del cliente para muchos de sus clientes empresariales.
Retos actuales
Primero, comprendamos algunos de los desafíos que enfrentaron los equipos de ciencia de datos y DevOps del cliente con su configuración actual. Luego podemos examinar cómo las ofertas integradas de IA/ML de SageMaker ayudaron a resolver esos desafíos.
- Colaboración: cada uno de los científicos de datos trabajó en sus propios cuadernos Jupyter locales para crear y entrenar modelos de aprendizaje automático. Carecían de un método eficaz para compartir y colaborar con otros científicos de datos.
- Escalabilidad: entrenar y reentrenar modelos de ML tomaba cada vez más tiempo a medida que los modelos se volvían más complejos mientras que la capacidad de infraestructura asignada permanecía estática.
- MLOps: el monitoreo del modelo y la gobernanza continua no estaban estrechamente integrados ni automatizados con los modelos de ML. Existen dependencias y complejidades con la integración de herramientas de terceros en el proceso de MLOps.
- Reutilizabilidad: sin marcos MLOps reutilizables, cada modelo debe desarrollarse y gobernarse por separado, lo que aumenta el esfuerzo general y retrasa la puesta en funcionamiento del modelo.
Este diagrama resume los desafíos y cómo la implementación de Wipro en SageMaker los abordó con servicios y ofertas integrados de SageMaker.
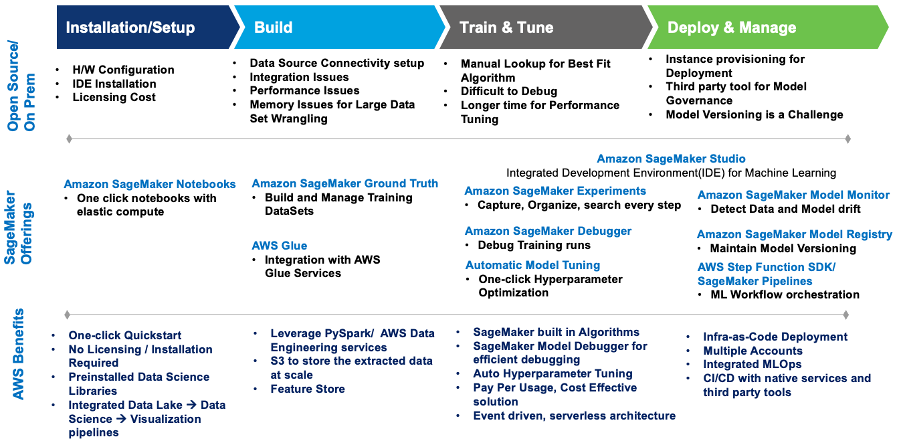
Figura 1: Ofertas de SageMaker para la migración de cargas de trabajo de ML
Wipro definió una arquitectura que aborda los desafíos de forma totalmente automatizada y con costes optimizados.
El siguiente es el caso de uso y el modelo utilizado para construir la solución:
- Caso de uso: Predicción de precios basada en el conjunto de datos de automóviles usados
- Tipo de problema: Regresión
- Modelos utilizados: XGBoost y Linear Learner (algoritmos integrados de SageMaker)
Arquitectura de soluciones
Los consultores de Wipro llevaron a cabo un taller de descubrimiento profundo con los equipos de ciencia de datos, DevOps e ingeniería de datos del cliente para comprender el entorno actual, así como sus requisitos y expectativas para una solución moderna en AWS. Al final del contrato de consultoría, el equipo había implementado la siguiente arquitectura que abordó de manera efectiva los requisitos principales del equipo del cliente, que incluyen:
Compartir código – Los cuadernos de SageMaker permiten a los científicos de datos experimentar y compartir código con otros miembros del equipo. Wipro aceleró aún más su viaje hacia el modelo de aprendizaje automático mediante la implementación de aceleradores y fragmentos de código de Wipro para acelerar la ingeniería de funciones, la capacitación de modelos, la implementación de modelos y la creación de canales.
Canalización de integración continua y entrega continua (CI/CD) – El uso del repositorio de GitHub del cliente permitió el control de versiones de código y scripts automatizados para iniciar la implementación de canalizaciones cada vez que se confirman nuevas versiones del código.
MLOps – La arquitectura implementa un canal de monitoreo de modelos de SageMaker para un control continuo de la calidad del modelo mediante la validación de los datos y la deriva del modelo según lo requiere el cronograma definido. Cada vez que se detecta una desviación, se lanza un evento para notificar a los respectivos equipos que tomen medidas o inicien el reentrenamiento del modelo.
Arquitectura impulsada por eventos – Los canales para la capacitación de modelos, la implementación de modelos y el monitoreo de modelos están bien integrados por uso. Puente de eventos de Amazon, un bus de eventos sin servidor. Cuando ocurren eventos definidos, EventBridge puede invocar una canalización para que se ejecute en respuesta. Esto proporciona un conjunto de tuberías poco acopladas que pueden ejecutarse según sea necesario en respuesta al entorno.
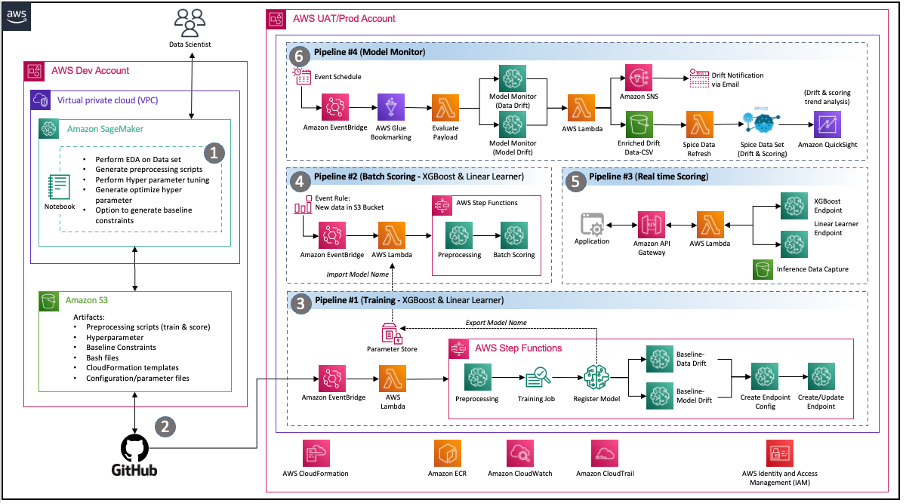
Figura 2: Arquitectura MLOps basada en eventos con SageMaker
Componentes de la solución
Esta sección describe los diversos componentes de la solución de la arquitectura.
Cuadernos de experimentos
- Propósito: El equipo de ciencia de datos del cliente quería experimentar con varios conjuntos de datos y múltiples modelos para encontrar las características óptimas, utilizándolas como entradas adicionales para el proceso automatizado.
- Solución: Wipro creó cuadernos de experimentos de SageMaker con fragmentos de código para cada paso reutilizable, como lectura y escritura de datos, ingeniería de características de modelos, entrenamiento de modelos y ajuste de hiperparámetros. Las tareas de ingeniería de funciones también se pueden preparar en Data Wrangler, pero el cliente solicitó específicamente trabajos de procesamiento de SageMaker y Funciones de paso de AWS porque se sentían más cómodos usando esas tecnologías. Usamos el SDK de ciencia de datos de función de pasos de AWS para crear una función de pasos (para pruebas de flujo) directamente desde la instancia del cuaderno para permitir entradas bien definidas para las canalizaciones. Esto ha ayudado al equipo de científicos de datos a crear y probar canalizaciones a un ritmo mucho más rápido.
Pipeline de entrenamiento automatizado
- Propósito: Para habilitar un proceso automatizado de capacitación y reentrenamiento con parámetros configurables como tipo de instancia, hiperparámetros y un Servicio de almacenamiento simple de Amazon (Amazon S3) ubicación del cubo. La canalización también debería iniciarse mediante el evento de envío de datos al S3.
- Solución: Wipro implementó un canal de capacitación reutilizable utilizando el SDK de Step Functions, procesamiento de SageMaker, trabajos de capacitación, un contenedor de monitoreo de modelos de SageMaker para la generación de líneas de base, AWS Lambday servicios EventBridge. Al utilizar la arquitectura basada en eventos de AWS, la canalización se configura para iniciarse automáticamente en función de un nuevo evento de datos que se envía al depósito S3 asignado. Las notificaciones están configuradas para enviarse a las direcciones de correo electrónico definidas. En un nivel alto, el flujo de capacitación se parece al siguiente diagrama:
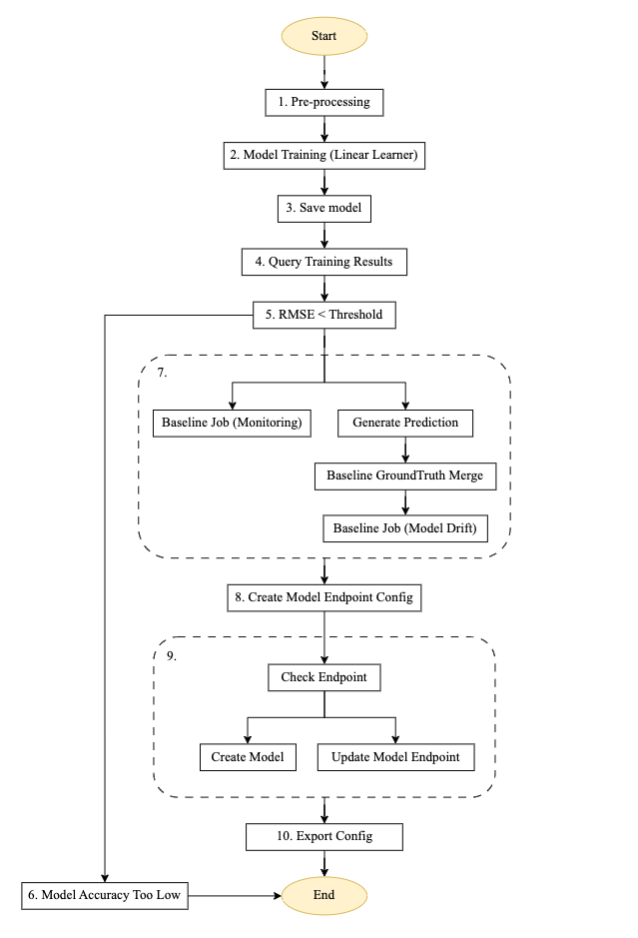
Figura 3 – Máquina paso a paso para canalización de entrenamiento.
Descripción del flujo para el proceso de capacitación automatizado
El diagrama anterior es un canal de capacitación automatizado creado con Step Functions, Lambda y SageMaker. Es una canalización reutilizable para configurar el entrenamiento automatizado de modelos, generar predicciones, crear una línea de base para el monitoreo de modelos y datos, y crear y actualizar un punto final basado en el valor umbral del modelo anterior.
- Preprocesamiento: Este paso toma datos de una ubicación de Amazon S3 como entrada y utiliza el contenedor SageMaker SKLearn para realizar las tareas necesarias de ingeniería de funciones y preprocesamiento de datos, como entrenar, probar y validar la división.
- Entrenamiento modelo: Con el SDK de SageMaker, este paso ejecuta el código de entrenamiento con la imagen del modelo respectivo y entrena conjuntos de datos a partir de scripts de preprocesamiento mientras genera los artefactos del modelo entrenado.
- Guardar modelo: Este paso crea un modelo a partir de los artefactos del modelo entrenado. El nombre del modelo se almacena como referencia en otra tubería usando el Almacén de parámetros de AWS Systems Manager.
- Resultados del entrenamiento de consultas: Este paso llama a la función Lambda para recuperar las métricas del trabajo de capacitación completado del paso de capacitación del modelo anterior.
- Umbral RMSE: Este paso verifica la métrica del modelo entrenado (RMSE) frente a un umbral definido para decidir si se debe proceder con la implementación del punto final o rechazar este modelo.
- Precisión del modelo demasiado baja: En este paso, la precisión del modelo se compara con el mejor modelo anterior. Si el modelo falla en la validación de la métrica, la notificación se envía mediante una función Lambda al tema de destino registrado en Servicio de notificación simple de Amazon (Amazon SNS). Si esta verificación falla, el flujo sale porque el nuevo modelo entrenado no alcanzó el umbral definido.
- Desviación de los datos laborales de referencia: Si el modelo entrenado pasa los pasos de validación, se generan estadísticas de referencia para esta versión del modelo entrenado para permitir el monitoreo y se ejecutan los pasos de la rama paralela para generar la línea de base para la verificación de calidad del modelo.
- Crear configuración de punto final del modelo: Este paso crea la configuración del punto final para el modelo evaluado en el paso anterior con un habilitar la captura de datos configuración.
- Verificar punto final: Este paso comprueba si el punto final existe o es necesario crearlo. Según el resultado, el siguiente paso es crear o actualizar el punto final.
- Configuración de exportación: Este paso exporta el nombre del modelo del parámetro, el nombre del punto final y la configuración del punto final al Gerente de sistemas de AWS Almacén de parámetros.
Las alertas y notificaciones están configuradas para enviarse al correo electrónico del tema SNS configurado en caso de falla o éxito del cambio de estado de la máquina de estado. La misma configuración de canalización se reutiliza para el modelo XGBoost.
Canal de puntuación por lotes automatizado
- Finalidad: Inicie la puntuación por lotes tan pronto como los datos del lote de entrada de puntuación estén disponibles en la ubicación respectiva de Amazon S3. La puntuación por lotes debe utilizar el último modelo registrado para realizar la puntuación.
- Solución: Wipro implementó un canal de puntuación reutilizable utilizando el SDK de Step Functions, trabajos de transformación por lotes de SageMaker, Lambda y EventBridge. La canalización se activa automáticamente en función de la disponibilidad de datos del nuevo lote de puntuación en la ubicación S3 respectiva.
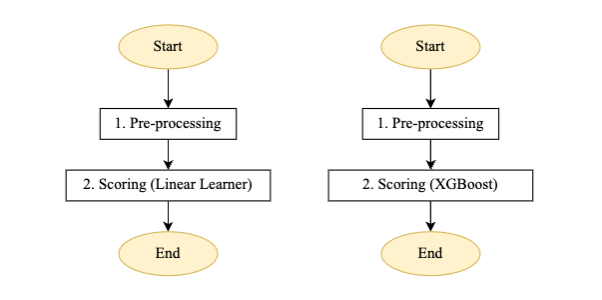
Figura 4: Máquina paso a paso de canalización de puntuación para alumno lineal y modelo XGBoost
Descripción del flujo para el proceso de puntuación por lotes automatizado:
- Preprocesamiento: La entrada para este paso es un archivo de datos de la ubicación S3 respectiva y realiza el procesamiento previo requerido antes de llamar al trabajo de transformación por lotes de SageMaker.
- Puntuación: Este paso ejecuta el trabajo de transformación por lotes para generar inferencias, llama a la última versión del modelo registrado y almacena el resultado de la puntuación en un depósito de S3. Wipro ha utilizado el filtro de entrada y la funcionalidad de unión de la API de transformación por lotes de SageMaker. Ayudó a enriquecer los datos de puntuación para una mejor toma de decisiones.
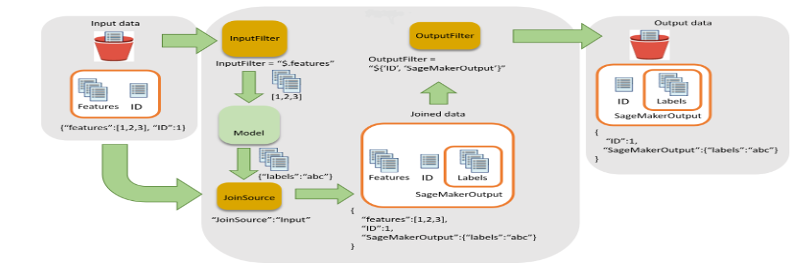
Figura 5: Filtro de entrada y flujo de unión para transformación por lotes
- En este paso, la canalización de la máquina de estado se inicia mediante un nuevo archivo de datos en el depósito de S3.
La notificación está configurada para enviarse al correo electrónico del tema SNS configurado en caso de falla o éxito del cambio de estado de la máquina de estado.
Canal de inferencia en tiempo real
- Finalidad: Para habilitar inferencias en tiempo real desde los puntos finales de ambos modelos (Linear Learner y XGBoost) y obtener el valor máximo predicho (o mediante el uso de cualquier otra lógica personalizada que pueda escribirse como una función Lambda) para devolverlo a la aplicación.
- Solución: El equipo de Wipro ha implementado una arquitectura reutilizable utilizando Puerta de enlace API de Amazon, Lambda y SageMaker como se muestra en la Figura 6:

Figura 6 – Canal de inferencia en tiempo real
Descripción del flujo para el canal de inferencia en tiempo real que se muestra en la Figura 6:
- La carga útil se envía desde la aplicación a Amazon API Gateway, que la enruta a la función Lambda respectiva.
- Una función Lambda (con una capa personalizada de SageMaker integrada) realiza el preprocesamiento requerido, el formato de carga útil JSON o CSV e invoca los puntos finales respectivos.
- La respuesta se devuelve a Lambda y se envía a la aplicación a través de API Gateway.
El cliente utilizó este canal para modelos de pequeña y mediana escala, que incluían el uso de varios tipos de algoritmos de código abierto. Uno de los beneficios clave de SageMaker es que se pueden incorporar varios tipos de algoritmos a SageMaker e implementarlos mediante la técnica de traer su propio contenedor (BYOC). BYOC implica contener el algoritmo y registrar la imagen en Registro de contenedores elásticos de Amazon (Amazon ECR)y luego usar la misma imagen para crear un contenedor para realizar entrenamiento e inferencia.
El escalado es uno de los mayores problemas en el ciclo del aprendizaje automático. SageMaker viene con las herramientas necesarias para escalar un modelo durante la inferencia. En la arquitectura anterior, los usuarios deben habilitar el escalado automático de SageMaker, que eventualmente maneja la carga de trabajo. Para habilitar el escalado automático, los usuarios deben proporcionar una política de escalado automático que solicite el rendimiento por instancia y las instancias máximas y mínimas. Dentro de la política vigente, SageMaker maneja automáticamente la carga de trabajo para puntos finales en tiempo real y cambia entre instancias cuando es necesario.
Canalización de monitorización de modelo personalizado
- Finalidad: El equipo del cliente quería tener un monitoreo automatizado del modelo para capturar tanto la desviación de los datos como la desviación del modelo. El equipo de Wipro utilizó el monitoreo del modelo SageMaker para permitir tanto la deriva de datos como la deriva del modelo con una canalización reutilizable para inferencias en tiempo real y transformación por lotes. Tenga en cuenta que durante el desarrollo de esta solución, el monitoreo del modelo SageMaker no proporcionó provisiones para detectar datos o deriva del modelo para la transformación por lotes. Hemos implementado personalizaciones para utilizar el contenedor de monitor de modelo para la carga útil de transformaciones por lotes.
- Solución: El equipo de Wipro implementó un canal de monitoreo de modelos reutilizable para cargas útiles de inferencia por lotes y en tiempo real utilizando Pegamento AWS para capturar la carga útil incremental e invocar el trabajo de monitoreo del modelo de acuerdo con el cronograma definido.

Figura 7 – Modelo de máquina paso a paso con monitor
Descripción del flujo para la canalización del monitor de modelo personalizado:
La canalización se ejecuta según el cronograma definido configurado a través de EventBridge.
- Consolidación CSV – Utiliza la función de marcador de AWS Glue para detectar la presencia de carga útil incremental en el depósito S3 definido de captura y respuesta de datos en tiempo real y respuesta de datos por lotes. Luego agrega esos datos para su posterior procesamiento.
- Evaluar carga útil – Si hay datos incrementales o carga útil presentes para la ejecución actual, invoca la rama de monitoreo. De lo contrario, se omite sin procesar y sale del trabajo.
- Postprocesamiento – La rama de monitoreo está diseñada para tener dos subramas paralelas: una para la deriva de datos y otra para la deriva del modelo.
- Monitoreo (derivación de datos) – La rama de deriva de datos se ejecuta siempre que hay una carga útil presente. Utiliza las últimas restricciones de línea base del modelo entrenado y archivos de estadísticas generados a través del proceso de capacitación para las características de datos y ejecuta el trabajo de monitoreo del modelo.
- Monitoreo (deriva del modelo) – La rama de deriva del modelo se ejecuta solo cuando se suministran datos reales sobre el terreno, junto con la carga útil de inferencia. Utiliza restricciones de línea base del modelo entrenado y archivos de estadísticas generados a través del proceso de capacitación para las características de calidad del modelo y ejecuta el trabajo de monitoreo del modelo.
- Evaluar la deriva – El resultado de la deriva tanto de los datos como del modelo es un archivo de violación de restricciones que se evalúa mediante la función Lambda de evaluación de la deriva, que envía notificaciones a los respectivos temas de Amazon SNS con detalles de la deriva. Los datos de deriva se enriquecen aún más con la adición de atributos para fines de generación de informes. Los correos electrónicos de notificación de deriva serán similares a los ejemplos de la Figura 8.

Figura 8 – Mensaje de notificación de variación de datos y modelos

Figura 9 – Mensaje de notificación de variación de datos y modelos
Información valiosa con la visualización de Amazon QuickSight:
- Finalidad: El cliente quería obtener información sobre los datos y la deriva del modelo, relacionar los datos de la deriva con los respectivos trabajos de monitoreo del modelo y descubrir las tendencias de los datos de inferencia para comprender la naturaleza de las tendencias de los datos de interferencia.
- Solución: El equipo de Wipro enriqueció los datos de la deriva conectando los datos de entrada con el resultado de la deriva, lo que permite clasificar desde la deriva hasta el monitoreo y los datos de puntuación respectivos. Las visualizaciones y los paneles se crearon utilizando Amazon QuickSight Atenea amazónica como fuente de datos (utilizando los datos de deriva y puntuación CSV de Amazon S3).
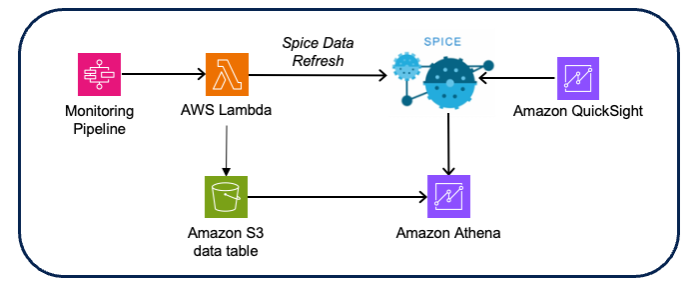
Figura 10 – Arquitectura de visualización de monitoreo del modelo
Consideraciones de diseño:
- Utilice el conjunto de datos QuickSight Spice para obtener un mejor rendimiento en memoria.
- Utilice las API del conjunto de datos de actualización QuickSight para automatizar la actualización de datos de especias.
- Implemente seguridad basada en grupos para el control de acceso al panel y al análisis.
- En todas las cuentas, automatice la implementación mediante la exportación e importación de conjuntos de datos, fuentes de datos y llamadas API de análisis proporcionadas por QuickSight.
Panel de seguimiento del modelo:
Para permitir un resultado efectivo y conocimientos significativos de los trabajos de monitoreo del modelo, se crearon paneles personalizados para los datos de monitoreo del modelo. Los puntos de datos de entrada se combinan en paralelo con datos de solicitud de inferencia, datos de trabajos y resultados de monitoreo para crear una visualización de las tendencias reveladas por el monitoreo del modelo.
Esto realmente ha ayudado al equipo del cliente a visualizar los aspectos de varias características de datos junto con el resultado previsto de cada lote de solicitudes de inferencia.
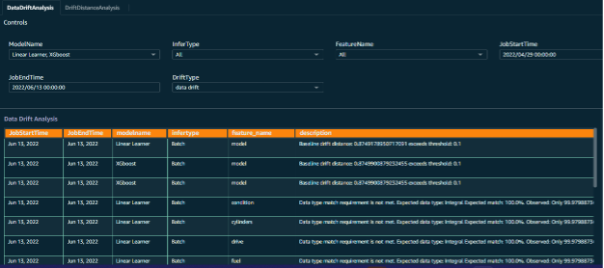
Figura 11: Panel de control del modelo con indicaciones de selección

Figura 12 – Análisis de deriva del monitor del modelo
Conclusión
La implementación explicada en esta publicación permitió a Wipro migrar eficazmente sus modelos locales a AWS y crear un marco de desarrollo de modelos automatizado y escalable.
El uso de componentes de marco reutilizables permite al equipo de ciencia de datos empaquetar de manera efectiva su trabajo como componentes JSON implementables de AWS Step Functions. Al mismo tiempo, los equipos de DevOps utilizaron y mejoraron el proceso automatizado de CI/CD para facilitar la promoción y el reentrenamiento fluidos de modelos en entornos superiores.
El componente de monitoreo del modelo ha permitido el monitoreo continuo del desempeño del modelo y los usuarios reciben alertas y notificaciones cada vez que se detectan datos o desviaciones del modelo.
El equipo del cliente está utilizando este marco MLOps para migrar o desarrollar más modelos y aumentar su adopción de SageMaker.
Al aprovechar el conjunto integral de servicios de SageMaker junto con nuestra arquitectura meticulosamente diseñada, los clientes pueden incorporar sin problemas múltiples modelos, reduciendo significativamente el tiempo de implementación y mitigando las complejidades asociadas con el uso compartido de código. Además, nuestra arquitectura simplifica el mantenimiento de versiones del código, lo que garantiza un proceso de desarrollo optimizado.
Esta arquitectura maneja todo el ciclo de aprendizaje automático, que abarca el entrenamiento automatizado de modelos, la inferencia en tiempo real y por lotes, el monitoreo proactivo de modelos y el análisis de deriva. Esta solución integral permite a los clientes lograr un rendimiento óptimo del modelo mientras mantiene capacidades rigurosas de monitoreo y análisis para garantizar precisión y confiabilidad continuas.
Para crear esta arquitectura, comience creando recursos esenciales como Nube privada virtual de Amazon (Amazon VPC), cuadernos SageMaker y funciones Lambda. Asegúrese de configurar apropiadamente Administración de acceso e identidad de AWS (IAM) políticas para estos recursos.
A continuación, concéntrese en crear los componentes de la arquitectura, como scripts de entrenamiento y preprocesamiento, dentro de SageMaker Studio o Jupyter Notebook. Este paso implica desarrollar el código y las configuraciones necesarios para habilitar las funcionalidades deseadas.
Una vez definidos los componentes de la arquitectura, puede continuar con la creación de funciones Lambda para generar inferencias o realizar pasos de posprocesamiento de los datos.
Al final, utilice Step Functions para conectar los componentes y establecer un flujo de trabajo fluido que coordine la ejecución de cada paso.
Acerca de los autores
 Esteban Randolph es arquitecto de soluciones socio senior en Amazon Web Services (AWS). Capacita y apoya a los socios de Global Systems Integrator (GSI) en la última tecnología de AWS mientras desarrollan soluciones industriales para resolver desafíos comerciales. A Stephen le apasiona especialmente la seguridad y la IA generativa, y ayuda a clientes y socios a diseñar soluciones seguras, eficientes e innovadoras en AWS.
Esteban Randolph es arquitecto de soluciones socio senior en Amazon Web Services (AWS). Capacita y apoya a los socios de Global Systems Integrator (GSI) en la última tecnología de AWS mientras desarrollan soluciones industriales para resolver desafíos comerciales. A Stephen le apasiona especialmente la seguridad y la IA generativa, y ayuda a clientes y socios a diseñar soluciones seguras, eficientes e innovadoras en AWS.
 Bhajandeep Singh Se ha desempeñado como director del Centro de Excelencia de IA/ML de AWS en Wipro Technologies, liderando la interacción con los clientes para ofrecer análisis de datos y soluciones de IA. Posee la certificación de especialidad de IA/ML de AWS y es autor de blogs técnicos sobre servicios y soluciones de IA/ML. Con experiencia liderando soluciones de IA/ML de AWS en todas las industrias, Bhajandeep ha permitido a los clientes maximizar el valor de los servicios de IA/ML de AWS a través de su experiencia y liderazgo.
Bhajandeep Singh Se ha desempeñado como director del Centro de Excelencia de IA/ML de AWS en Wipro Technologies, liderando la interacción con los clientes para ofrecer análisis de datos y soluciones de IA. Posee la certificación de especialidad de IA/ML de AWS y es autor de blogs técnicos sobre servicios y soluciones de IA/ML. Con experiencia liderando soluciones de IA/ML de AWS en todas las industrias, Bhajandeep ha permitido a los clientes maximizar el valor de los servicios de IA/ML de AWS a través de su experiencia y liderazgo.
 Ajay Vishwakarma es ingeniero de aprendizaje automático para el ala AWS de la práctica de soluciones de inteligencia artificial de Wipro. Tiene buena experiencia en la creación de soluciones BYOM para algoritmos personalizados en SageMaker, implementación de canales ETL de extremo a extremo, creación de chatbots utilizando Lex, intercambio de recursos QuickSight entre cuentas y creación de plantillas de CloudFormation para implementaciones. Le gusta explorar AWS tomando cada problema de los clientes como un desafío para explorar más y brindarles soluciones.
Ajay Vishwakarma es ingeniero de aprendizaje automático para el ala AWS de la práctica de soluciones de inteligencia artificial de Wipro. Tiene buena experiencia en la creación de soluciones BYOM para algoritmos personalizados en SageMaker, implementación de canales ETL de extremo a extremo, creación de chatbots utilizando Lex, intercambio de recursos QuickSight entre cuentas y creación de plantillas de CloudFormation para implementaciones. Le gusta explorar AWS tomando cada problema de los clientes como un desafío para explorar más y brindarles soluciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

