Introducción
Cuando escuchamos ciencia de datos, lo primero que nos viene a la mente es construir un modelo en cuadernos y entrenar los datos. Pero esta no es la situación en la ciencia de datos del mundo real. En el mundo real, los científicos de datos construyen modelos y los ponen en producción. El entorno de producción tiene una brecha entre el desarrollo, la implementación y la confiabilidad del modelo y para facilitar operaciones eficientes y escalables. Aquí es donde los científicos de datos utilizan MLOps (Operaciones de aprendizaje automático) para crear e implementar aplicaciones de aprendizaje automático en un entorno de producción. En este artículo, crearemos e implementaremos un proyecto de predicción de pérdida de clientes utilizando MLOps.

OBJETIVOS DE APRENDIZAJE
En este artículo, aprenderá:
- Resumen del proyecto
- Presentaremos los fundamentos de ZenML y MLOPS.
- Aprenda a implementar el modelo localmente para realizar predicciones.
- Ingrese al preprocesamiento e ingeniería de datos, capacitación y evaluación del modelo.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Descripción general del proyecto
En primer lugar, debemos entender cuál es nuestro proyecto. Para este proyecto, tenemos un conjunto de datos de una empresa de telecomunicaciones. Ahora, construir un modelo para predecir si es probable que el usuario continúe con el servicio de la empresa o no. Construiremos esta aplicación ML utilizando la ayuda de ZenmML y MLFujo. Este es el flujo de trabajo de nuestro proyecto.
El flujo de trabajo de nuestro proyecto
- Recolectar Datos
- Preprocesamiento de datos
- Modelo de entrenamiento
- Evaluar modelo
- Despliegue
¿Qué es MLOps?
MLOps es un ciclo de vida de aprendizaje automático de un extremo a otro, desde el desarrollo hasta la implementación y el mantenimiento continuo. MLOps es la práctica de optimizar y automatizar todo el ciclo de vida de los modelos de aprendizaje automático, garantizando al mismo tiempo escalabilidad, confiabilidad y eficiencia.
Expliquemoslo con un ejemplo sencillo.:
Imagina que estás construyendo un rascacielos en tu ciudad. La construcción del edificio está terminada. Pero carece de electricidad, agua, sistema de drenaje, etc. El rascacielos no será funcional ni práctico.
Lo mismo se aplica a los modelos de aprendizaje automático. Si estos modelos se diseñan sin tener en cuenta su implementación, escalabilidad y mantenimiento a largo plazo, pueden volverse ineficaces y poco prácticos. Esto plantea un obstáculo importante para los científicos de datos a la hora de construir modelos de aprendizaje automático para su uso en entornos de producción.
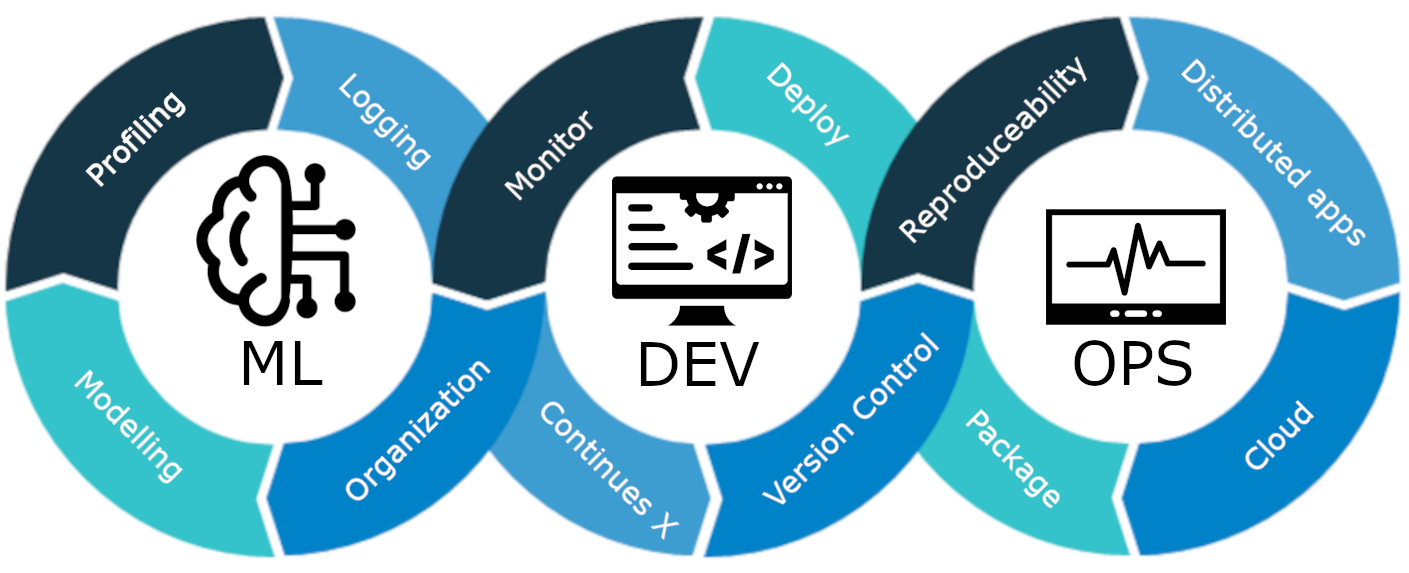
MLOps es un conjunto de mejores prácticas y estrategias que guían la producción, implementación y mantenimiento a largo plazo de modelos de aprendizaje automático. Garantiza que estos modelos no solo ofrezcan predicciones precisas, sino que también sigan siendo activos sólidos, escalables y valiosos para las empresas. Entonces, sin MLOps, será una pesadilla realizar todas estas tareas de manera eficiente, lo cual es un desafío. En este proyecto, explicaremos cómo funciona MLOps, las diferentes etapas y un proyecto de principio a fin sobre cómo construir un Cliente. predicción de abandono modelo.
Presentamos ZenML
ZenML es un marco MLOPS de código abierto que ayuda a crear canalizaciones portátiles y listas para producción. ZenML Framework nos ayudará a realizar este proyecto utilizando MLOPS.
⚠️ Si eres usuario de Windows, intenta instalar wsl en una PC. Zenml no es compatible con Windows.
Antes de pasar a los proyectos.
Conceptos fundamentales de MLOPS
- pasos: Los pasos son unidades individuales de tareas en una canalización o flujo de trabajo. Cada paso representa una acción u operación específica que debe realizarse para desarrollar un flujo de trabajo de aprendizaje automático. Por ejemplo, la limpieza de datos, el preprocesamiento de datos, los modelos de entrenamiento, etc., son ciertos pasos en el desarrollo de un modelo de aprendizaje automático.
- Pipelines: Conectan varios pasos para crear un proceso estructurado y automatizado para tareas de aprendizaje automático. para, por ejemplo, el proceso de procesamiento de datos, el proceso de evaluación de modelos y el proceso de capacitación de modelos.
Cómo Empezar
Cree un entorno virtual para el proyecto:
conda create -n churn_prediction python=3.9Luego instale estas bibliotecas:
pip install numpy pandas matplotlib scikit-learnDespués de instalar esto, instale ZenML:
pip install zenml["server"]Luego inicialice el repositorio ZenML.
zenml init
Obtendrá una bandera verde para continuar si su pantalla muestra esto. Después de inicializar, se creará una carpeta .zenml en su directorio.
Cree una carpeta para datos en el directorio. Obtenga los datos en este liga:
Cree carpetas según esta estructura.
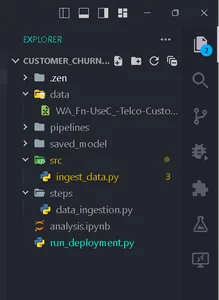
Recolectar Datos
En este paso, importaremos datos desde nuestro archivo csv. Estos datos se utilizarán para entrenar el modelo después de la limpieza y codificación.
Crear un archivo ingesta_data.py dentro de la carpeta pasos.
import pandas as pd
import numpy as np
import logging
from zenml import step class IngestData: """ Ingesting data to the workflow. """ def __init__(self, path:str) -> None: """ Args: data_path(str): path of the datafile """ self.path = path def get_data(self): df = pd.read_csv(self.path) logging.info("Reading csv file successfully completed.") return df @step(enable_cache = False)
def ingest_df(data_path:str) -> pd.DataFrame: """ ZenML step for ingesting data from a CSV file. """ try: #Creating an instance of IngestData class and ingest the data ingest_data = IngestData(data_path) df = ingest_data.get_data() logging.info("Ingesting data completed") return df except Exception as e: #Log an error message if data ingestion fails and raise the exception logging.error("Error while ingesting data") raise eAquí está el proyecto liga.
En este código, primero creamos la clase IngestData para encapsular la lógica de ingesta de datos. Luego creamos un ZenML paso, ingesta_df, que es una unidad individual del proceso de recopilación de datos.
Creando un archivo Training_pipeline.py dentro de la carpeta Pipeline.
escribir el código
from zenml import pipeline from steps.ingest_data import ingest_df #Define a ZenML pipeline called training_pipeline. @pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' df = ingest_df(data_path=data_path)Aquí, estamos creando un proceso de capacitación para entrenar un modelo de aprendizaje automático mediante una serie de pasos.
Luego crea un archivo llamado run_pipeline.py en el directorio base para ejecutar el industrial.
from pipelines.training_pipeline import train_pipeline if __name__ == '__main__': #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Este código se utiliza para ejecutar la canalización.
Ahora hemos terminado el proceso de ingesta de datos. Ejecutémoslo.
Ejecute el comando en su terminal:
python run_pipeline.py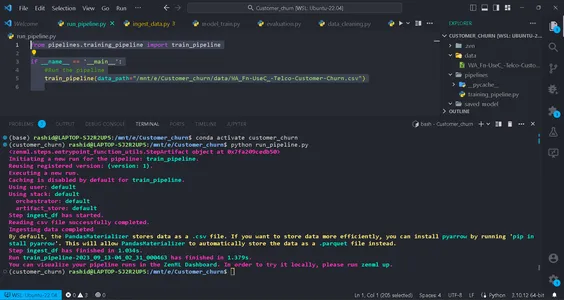
Luego, podrá ver los comandos que indican que Training_pipeline se ha completado con éxito.
Preprocesamiento de datos
En este paso, crearemos diferentes estrategias para limpiar datos. Las columnas no deseadas se eliminan y las columnas categóricas se codificarán utilizando la codificación de etiquetas. Finalmente, los datos se dividirán en datos de entrenamiento y de prueba.
Cree un archivo llamado clean_data.py en la carpeta src.
En este archivo, crearemos clases de estrategias para limpiar los datos.
import pandas as pd
import numpy as np
import logging
from sklearn.model_selection import train_test_split
from abc import abstractmethod, ABC
from typing import Union
from sklearn.preprocessing import LabelEncoder class DataStrategy(ABC): @abstractmethod def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame,pd.Series]: pass # Data Preprocessing strategy
class DataPreprocessing(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df['TotalCharges'] = df['TotalCharges'].replace(' ', 0).astype(float) df.drop('customerID', axis=1, inplace=True) df['Churn'] = df['Churn'].replace({'Yes': 1, 'No': 0}).astype(int) service = ['PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] for col in service: df[col] = df[col].replace({'No phone service': 'No', 'No internet service': 'No'}) logging.info("Length of df: ", len(df.columns)) return df except Exception as e: logging.error("Error in Preprocessing", e) raise e # Feature Encoding Strategy
class LabelEncoding(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df_cat = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] lencod = LabelEncoder() for col in df_cat: df[col] = lencod.fit_transform(df[col]) logging.info(df.head()) return df except Exception as e: logging.error(e) raise e # Data splitting Strategy
class DataDivideStrategy(DataStrategy): def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: X = df.drop('Churn', axis=1) y = df['Churn'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) return X_train, X_test, y_train, y_test except Exception as e: logging.error("Error in DataDividing", e) raise e
Este código implementa una canalización modular de preprocesamiento de datos para el aprendizaje automático. Incluye estrategias para el preprocesamiento de datos, codificación de características y pasos de codificación de datos para la limpieza de datos para el modelado predictivo.
1. Preprocesamiento de datos: esta clase es responsable de eliminar columnas no deseadas y manejar los valores faltantes (valores NA) en el conjunto de datos.
2. Codificación de etiquetas: La clase LabelEncoding está diseñada para codificar variables categóricas en un formato numérico con el que los algoritmos de aprendizaje automático pueden funcionar de manera efectiva. Transforma categorías basadas en texto en valores numéricos.
3. Estrategia de división de datos: Esta clase separa el conjunto de datos en variables independientes (X) y variables dependientes (y). Luego, divide los datos en conjuntos de entrenamiento y prueba.
Los implementaremos paso a paso para preparar nuestros datos para tareas de aprendizaje automático.
Estas estrategias garantizan que los datos estén estructurados y formateados correctamente para la capacitación y evaluación del modelo.
Crear limpieza_datos.py existentes pasos carpeta.
import pandas as pd
import numpy as np
from src.clean_data import DataPreprocessing, DataDivideStrategy, LabelEncoding
import logging
from typing_extensions import Annotated
from typing import Tuple
from zenml import step # Define a ZenML step for cleaning and preprocessing data
@step(enable_cache=False)
def cleaning_data(df: pd.DataFrame) -> Tuple[ Annotated[pd.DataFrame, "X_train"], Annotated[pd.DataFrame, "X_test"], Annotated[pd.Series, "y_train"], Annotated[pd.Series, "y_test"],
]: try: # Instantiate the DataPreprocessing strategy data_preprocessing = DataPreprocessing() # Apply data preprocessing to the input DataFrame data = data_preprocessing.handle_data(df) # Instantiate the LabelEncoding strategy feature_encode = LabelEncoding() # Apply label encoding to the preprocessed data df_encoded = feature_encode.handle_data(data) # Log information about the DataFrame columns logging.info(df_encoded.columns) logging.info("Columns:", len(df_encoded)) # Instantiate the DataDivideStrategy strategy split_data = DataDivideStrategy() # Split the encoded data into training and testing sets X_train, X_test, y_train, y_test = split_data.handle_data(df_encoded) # Return the split data as a tuple return X_train, X_test, y_train, y_test except Exception as e: # Handle and log any errors that occur during data cleaning logging.error("Error in step cleaning data", e) raise eEn este paso, implementamos las estrategias que creamos en clean_data.py
implementemos esto paso in formación_pipeline.py
from zenml import pipeline #importing steps from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df)Eso es todo; Hemos completado nuestro paso de preprocesamiento de datos en el proceso de capacitación.
Entrenamiento de modelos
Ahora vamos a construir el modelo para este proyecto. Aquí, estamos prediciendo un problema de clasificación binaria. Nosotros podemos usar regresión logística. Nuestra atención no se centrará en la precisión del modelo. Se basará en la parte MLOps.
Para aquellos que no saben acerca de la regresión logística, pueden leer sobre ella aquí. Implementaremos los mismos pasos que hicimos en el paso de preprocesamiento de datos. Primero, crearemos un archivo. modelo_entrenamiento.py existentes src carpeta.
import pandas as pd
from sklearn.linear_model import LogisticRegression
from abc import ABC, abstractmethod
import logging #Abstract model
class Model(ABC): @abstractmethod def train(self,X_train:pd.DataFrame,y_train:pd.Series): """ Trains the model on given data """ pass class LogisticReg(Model): """ Implementing the Logistic Regression model. """ def train(self, X_train: pd.DataFrame, y_train: pd.Series): """ Training the model Args: X_train: pd.DataFrame, y_train: pd.Series """ logistic_reg = LogisticRegression() logistic_reg.fit(X_train,y_train) return logistic_regDefinimos una clase de modelo abstracta con un método de 'entrenamiento' que todos los modelos deben implementar. La clase LogisticReg es una implementación específica que utiliza regresión logística. El siguiente paso implica configurar un archivo llamado config.py en la carpeta de pasos. Cree un archivo llamado config.py en la carpeta de pasos.
Configurar los parámetros del modelo
from zenml.steps import BaseParameters """
This file is used for used for configuring
and specifying various parameters related to your machine learning models and training process """ class ModelName(BaseParameters): """ Model configurations """ model_name: str = "logistic regression"En el archivo llamado configuración.py, dentro de pasos carpeta, está configurando parámetros relacionados con su modelo de aprendizaje automático. Creas una clase ModelName que hereda de Parámetros base para especificar el nombre del modelo. Esto facilita el cambio del tipo de modelo.
import logging import pandas as pd
from src.training_model import LogisticReg
from zenml import step
from .config import ModelName #Define a step called train_model
@step(enable_cache=False)
def train_model(X_train:pd.DataFrame,y_train:pd.Series,config:ModelName): """ Trains the data based on the configured model """ try: model = None if config == "logistic regression": model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) return trained_model except Exception as e: logging.error("Error in step training model",e) raise eEn el archivo llamado model_train.py en la carpeta de pasos, defina un paso llamado train_model usando ZenML. El propósito de este paso es entrenar un modelo de aprendizaje automático basado en el nombre del modelo en Nombre del modelo.
En el programa
Verifique el nombre del modelo configurado. Si se trata de "regresión logística", creamos una instancia del modelo LogisticReg y lo entrenamos con los datos de entrenamiento proporcionados (X_train e y_train). Si el nombre del modelo no es compatible, genera un error. Cualquier error durante este proceso se registra y se genera el error.
Después de esto, vamos a implementar este paso en formación_pipeline.py
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train)Ahora hemos implementado el paso train_model en el proceso. Entonces, se completa el paso model_train.py.
Evaluación del modelo
En este paso, evaluaremos qué tan eficiente es nuestro modelo. Para eso, verificaremos la puntuación de precisión al predecir los datos de la prueba. Primero, vamos a crear las estrategias que usaremos en el proceso.
Crea un archivo llamado evaluar_modelo.py en la carpeta src.
import logging
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from abc import ABC, abstractmethod
import numpy as np # Abstract class for model evaluation
class Evaluate(ABC): @abstractmethod def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Abstract method to evaluate a machine learning model's performance. Args: y_true (np.ndarray): True labels. y_pred (np.ndarray): Predicted labels. Returns: float: Evaluation result. """ pass #Class to calculate accuracy score
class Accuracy_score(Evaluate): """ Calculates and returns the accuracy score for a model's predictions. """ def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: try: accuracy_scr = accuracy_score(y_true=y_true, y_pred=y_pred) * 100 logging.info("Accuracy_score:", accuracy_scr) return accuracy_scr except Exception as e: logging.error("Error in evaluating the accuracy of the model",e) raise e
#Class to calculate Precision score
class Precision_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Generates and returns a precision score for a model's predictions. """ try: precision = precision_score(y_true=y_true,y_pred=y_pred) logging.info("Precision score: ",precision) return float(precision) except Exception as e: logging.error("Error in calculation of precision_score",e) raise e class F1_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray): """ Generates and returns an F1 score for a model's predictions. """ try: f1_scr = f1_score(y_pred=y_pred, y_true=y_true) logging.info("F1 score: ", f1_scr) return f1_scr except Exception as e: logging.error("Error in calculating F1 score", e) raise e Ahora que hemos creado las estrategias de evaluación, las usaremos para evaluar el modelo. Implementemos el código en paso evaluar_modelo.py en la carpeta de pasos. Aquí, la puntuación de recuerdo, la puntuación de precisión y la puntuación de precisión son las estrategias que utilizamos como métricas para evaluar el modelo.
Implementémoslos en pasos. Crea un archivo llamado evaluación.py en pasos:
import logging
import pandas as pd
import numpy as np
from zenml import step
from src.evaluate_model import ClassificationReport, ConfusionMatrix, Accuracy_score
from typing import Tuple
from typing_extensions import Annotated
from sklearn.base import ClassifierMixin @step(enable_cache=False)
def evaluate_model( model: ClassifierMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[ Annotated[np.ndarray,"confusion_matix"], Annotated[str,"classification_report"], Annotated[float,"accuracy_score"], Annotated[float,"precision_score"], Annotated[float,"recall_score"] ]: """ Evaluate a machine learning model's performance using common metrics. """ try: y_pred = model.predict(X_test) precision_score_class = Precision_Score() precision_score = precision_score_class.evaluate_model(y_pred=y_pred,y_true=y_test) mlflow.log_metric("Precision_score ",precision_score) accuracy_score_class = Accuracy_score() accuracy_score = accuracy_score_class.evaluate_model(y_true=y_test, y_pred=y_pred) logging.info("accuracy_score:",accuracy_score) return accuracy_score, precision_score except Exception as e: logging.error("Error in evaluating model",e) raise eAhora, implementemos este paso en el proceso. Actualice Training_pipeline.py:
Este código define una evaluar_modelo paso en un proceso de aprendizaje automático. Se necesita un modelo de clasificación entrenado (modelo), datos de prueba independientes (X_prueba) y etiquetas verdaderas para los datos de prueba (y_prueba) como entrada. Luego evalúa el rendimiento del modelo utilizando métricas de clasificación comunes y devuelve los resultados, como el puntuación_precisión y puntuación_precisión.
Ahora, implementemos este paso en el proceso. Actualizar el formación_pipeline.py:
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
from steps.evaluation import evaluate_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train) #Evaluation metrics of data accuracy_score, precision_score = evaluate_model(model=model,X_test=X_test, y_test=y_test)Eso es todo. Ahora hemos completado el proceso de capacitación. Correr
python run_pipeline.py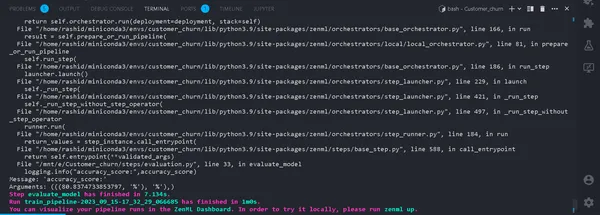
En la Terminal. Si se ejecuta exitosamente. Ahora que hemos completado la ejecución local de un canal de capacitación, se verá así:
¿Qué es un rastreador de experimentos?
Un rastreador de experimentos es una herramienta de aprendizaje automático que se utiliza para registrar, monitorear y gestionar varios experimentos en el proceso de desarrollo del aprendizaje automático.
Los científicos de datos experimentan con diferentes modelos para obtener los mejores resultados. Por lo tanto, necesitan seguir rastreando los datos y utilizando diferentes modelos. Les resultará muy difícil si lo registran manualmente utilizando una hoja de Excel.
flujo ml
MLflow es una herramienta valiosa para rastrear y gestionar de manera eficiente experimentos en aprendizaje automático. Automatiza el seguimiento de experimentos, el seguimiento de iteraciones de modelos y los datos asociados. Esto agiliza el proceso de desarrollo del modelo y proporciona una interfaz fácil de usar para visualizar los resultados.
La integración de MLflow con ZenML mejora la solidez y la gestión de los experimentos dentro del marco de operaciones de aprendizaje automático.
Para configurar MLflow con ZenML, siga estos pasos:
- Instale la integración de MLflow:
- Utilice el siguiente comando para instalar la integración de MLflow:
zenml integration install mlflow -y2. Registre el rastreador de experimentos de MLflow:
Registre un rastreador de experimentos en MLflow usando este comando:
zenml experiment-tracker register mlflow_tracker --flavor=mlflow3. Registrar una pila:
En ZenML, una pila es una colección de componentes que definen tareas dentro de su flujo de trabajo de ML. Ayuda a organizar y gestionar los pasos del proceso de aprendizaje automático de manera eficiente. Registre una pila con:
Puede encontrar más detalles en el documentación.
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --setEsto asocia su pila con configuraciones específicas para el almacenamiento de artefactos, orquestadores, objetivos de implementación y seguimiento de experimentos.
4. Ver detalles de la pila:
Puede ver los componentes de su Stack usando:
zenml stack describeEsto muestra los componentes asociados con la pila "mlflow_tracker".
Ahora, implementemos un rastreador de experimentos en el modelo de entrenamiento y evaluemos el modelo:
Puede ver el nombre de los componentes como mlflow_tracker.
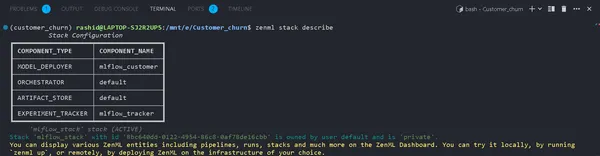
Configuración del rastreador de experimentos ZenML
Primero, comience a actualizar el tren_modelo.py:
import logging
import mlflow
import pandas as pd
from src.training_model import LogisticReg
from sklearn.base import ClassifierMixin
from zenml import step
from .config import ModelName
#import from zenml.client import Client # Obtain the active stack's experiment tracker
experiment_tracker = Client().active_stack.experiment_tracker #Define a step called train_model
@step(experiment_tracker = experiment_tracker.name,enable_cache=False)
def train_model( X_train:pd.DataFrame, y_train:pd.Series, config:ModelName ) -> ClassifierMixin: """ Trains the data based on the configured model Args: X_train: pd.DataFrame = Independent training data, y_train: pd.Series = Dependent training data. """ try: model = None if config.model_name == "logistic regression": #Automatically logging scores, model etc.. mlflow.sklearn.autolog() model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) logging.info("Training model completed.") return trained_model except Exception as e: logging.error("Error in step training model",e) raise eEn este código, configuramos el rastreador de experimentos usando mlflow.sklearn.autolog(), que registra automáticamente todos los detalles sobre el modelo, lo que facilita el seguimiento y el análisis de los experimentos.
En evaluación.py
from zenml.client import Client experiment_tracker = Client().active_stack.experiment_tracker @step(experiment_tracker=experiment_tracker.name, enable_cache = False)Ejecución de la tubería
Actualice su run_pipeline.py guión de la siguiente manera:
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == '__main__': #printimg the experiment tracking uri print(Client().active_stack.experiment_tracker.get_tracking_uri()) #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Cópialo y pégalo en este comando.
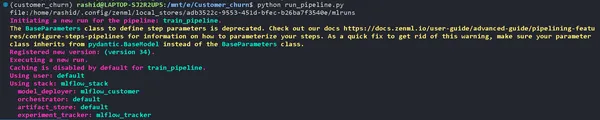
mlflow ui --backend-store-uri "--uri on the top of "file:/home/ "Explore sus experimentos
Haga clic en el enlace generado por el comando anterior para abrir la interfaz de usuario de MLflow. Aquí encontrará un tesoro escondido de ideas:
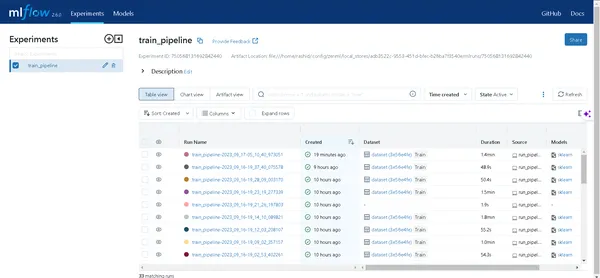
- Pipelines: acceda fácilmente a todas las canalizaciones que ha ejecutado.
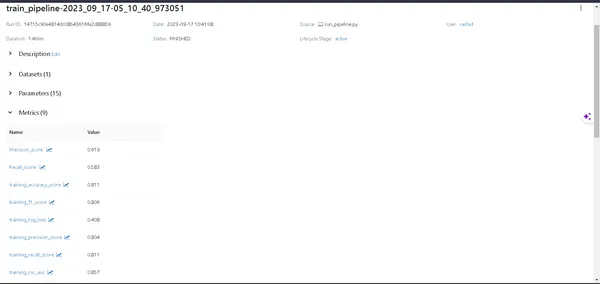
- Detalles del modelo: Haga clic en una tubería para descubrir todos los detalles sobre su modelo.
- Métrica: Sumérgete en la sección de métricas para visualizar el rendimiento de tu modelo.
¡Ahora puede conquistar el seguimiento de sus experimentos de aprendizaje automático con ZenML y MLflow!
Despliegue
En la siguiente sección, implementaremos este modelo. Necesitas conocer estos conceptos:
a). Canal de implementación continua
Este canal automatizará el proceso de implementación del modelo. Una vez que un modelo pasa los criterios de evaluación, se implementa automáticamente en un entorno de producción. Por ejemplo, comienza con el preprocesamiento de datos, la limpieza de datos, el entrenamiento de los datos, la evaluación del modelo, etc.
b). Canal de implementación de inferencia
El canal de implementación de inferencia se centra en la implementación de modelos de aprendizaje automático para inferencia en tiempo real o por lotes. Inference Deployment Pipeline se especializa en implementar modelos para hacer predicciones en un entorno de producción. Por ejemplo, configura un punto final API donde los usuarios pueden enviar mensajes de texto. Garantiza la disponibilidad y escalabilidad del modelo y monitorea su rendimiento en tiempo real. Estos canales son importantes para mantener la eficiencia y eficacia de los sistemas de aprendizaje automático. Ahora vamos a implementar la tubería continua.
Crea un archivo llamado implementación_pipeline.py en la carpeta de tuberías.
import numpy as np
import json
import logging
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from src.clean_data import FeatureEncoding
from .utils import get_data_for_test
from steps.data_cleaning import cleaning_data
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df # Define Docker settings with MLflow integration
docker_settings = DockerSettings(required_integrations = {MLFLOW}) #Define class for deployment pipeline configuration
class DeploymentTriggerConfig(BaseParameters): min_accuracy:float = 0.92 @step def deployment_trigger( accuracy: float, config: DeploymentTriggerConfig,
): """ It trigger the deployment only if accuracy is greater than min accuracy. Args: accuracy: accuracy of the model. config: Minimum accuracy thereshold. """ try: return accuracy >= config.min_accuracy except Exception as e: logging.error("Error in deployment trigger",e) raise e # Define a continuous pipeline
@pipeline(enable_cache=False,settings={"docker":docker_settings})
def continuous_deployment_pipeline( data_path:str, min_accuracy:float = 0.92, workers: int = 1, timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT
): df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df) model = train_model(X_train=X_train, y_train=y_train) accuracy_score, precision_score = evaluate_model(model=model, X_test=X_test, y_test=y_test) deployment_decision = deployment_trigger(accuracy=accuracy_score) mlflow_model_deployer_step( model=model, deploy_decision = deployment_decision, workers = workers, timeout = timeout )Proyecto ZenML Framework para aprendizaje automático
Este código define una implementación continua para un proyecto de aprendizaje automático utilizando ZenML Framework.
1. Importar bibliotecas necesarias: Importando las bibliotecas necesarias para el despliegue del modelo.
2. Configuración de la ventana acoplable: Al configurar los ajustes de Docker para usar con MLflow, Docker ayuda a empaquetar y ejecutar estos modelos de manera consistente.
3. Configuración de activación de implementación: Es la clase donde se configura el umbral mínimo de precisión para que se implemente un modelo.
4. despliegue_trigger: Este paso volverá si la precisión del modelo excede la precisión mínima.
5. tubería_deployment_continua: Esta canalización consta de varios pasos: ingesta de datos, limpieza de datos, entrenamiento del modelo y evaluación del modelo. Y el modelo sólo se implementará si alcanza el umbral mínimo de precisión.
A continuación, implementaremos el canal de inferencia en implementación_pipeline.py.
import logging
import pandas as pd
from zenml.steps import BaseParameters, Output
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import MLFlowModelDeployer
from zenml.integrations.mlflow.services import MLFlowDeploymentService class MLFlowDeploymentLoaderStepParameters(BaseParameters): pipeline_name: str step_name: str running: bool = True @step(enable_cache=False)
def dynamic_importer() -> str: data = get_data_for_test() return data @step(enable_cache=False)
def prediction_service_loader( pipeline_name: str, pipeline_step_name: str, running: bool = True, model_name: str = "model",
) -> MLFlowDeploymentService: model_deployer = MLFlowModelDeployer.get_active_model_deployer() existing_services = model_deployer.find_model_server( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, model_name=model_name, running=running, ) if not existing_services: raise RuntimeError( f"No MLflow prediction service deployed by the " f"{pipeline_step_name} step in the {pipeline_name} " f"pipeline for the '{model_name}' model is currently " f"running." ) return existing_services[0] @step
def predictor(service: MLFlowDeploymentService, data: str) -> np.ndarray: service.start(timeout=10) data = json.loads(data) prediction = service.predict(data) return prediction @pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str): batch_data = dynamic_importer() model_deployment_service = prediction_service_loader( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, running=False, ) prediction = predictor(service=model_deployment_service, data=batch_data) return prediction
Este código configura una canalización para realizar predicciones utilizando un modelo de aprendizaje automático implementado a través de MLflow. Importa datos, carga el modelo implementado y lo utiliza para hacer predicciones.
Necesitamos crear la función. obtener_datos_para_prueba() in utils.py en la carpeta de tuberías. Para que podamos administrar nuestro código de manera más eficiente.
import logging import pandas as pd from src.clean_data import DataPreprocessing, LabelEncoding # Function to get data for testing purposes
def get_data_for_test(): try: df = pd.read_csv('./data/WA_Fn-UseC_-Telco-Customer-Churn.csv') df = df.sample(n=100) data_preprocessing = DataPreprocessing() data = data_preprocessing.handle_data(df) # Instantiate the FeatureEncoding strategy label_encode = LabelEncoding() df_encoded = label_encode.handle_data(data) df_encoded.drop(['Churn'],axis=1,inplace=True) logging.info(df_encoded.columns) result = df_encoded.to_json(orient="split") return result except Exception as e: logging.error("e") raise eAhora, implementemos la canalización que creamos para implementar el modelo y predecir en el modelo implementado.
Crea el run_deployment.py archivo en el directorio del proyecto:
import click # For handling command-line arguments
import logging from typing import cast
from rich import print # For console output formatting # Import pipelines for deployment and inference
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline, inference_pipeline
)
# Import MLflow utilities and components
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService # Define constants for different configurations: DEPLOY, PREDICT, DEPLOY_AND_PREDICT
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict" # Define a main function that uses Click to handle command-line arguments
@click.command()
@click.option( "--config", "-c", type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]), default=DEPLOY_AND_PREDICT, help="Optionally you can choose to only run the deployment " "pipeline to train and deploy a model (`deploy`), or to " "only run a prediction against the deployed model " "(`predict`). By default both will be run " "(`deploy_and_predict`).",
)
@click.option( "--min-accuracy", default=0.92, help="Minimum accuracy required to deploy the model",
)
def run_main(config:str, min_accuracy:float ): # Get the active MLFlow model deployer component mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer() # Determine if the user wants to deploy a model (deploy), make predictions (predict), or both (deploy_and_predict) deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT predict = config == PREDICT or config == DEPLOY_AND_PREDICT # If deploying a model is requested: if deploy: continuous_deployment_pipeline( data_path='/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv', min_accuracy=min_accuracy, workers=3, timeout=60 ) # If making predictions is requested: if predict: # Initialize an inference pipeline run inference_pipeline( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", ) # Print instructions for viewing experiment runs in the MLflow UI print( "You can run:n " f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}" "[/italic green]n ...to inspect your experiment runs within the MLflow" " UI.nYou can find your runs tracked within the " "`mlflow_example_pipeline` experiment. There you'll also be able to " "compare two or more runs.nn" ) # Fetch existing services with the same pipeline name, step name, and model name existing_services = mlflow_model_deployer_component.find_model_server( pipeline_name = "continuous_deployment_pipeline", pipeline_step_name = "mlflow_model_deployer_step", ) # Check the status of the prediction server: if existing_services: service = cast(MLFlowDeploymentService, existing_services[0]) if service.is_running: print( f"The MLflow prediciton server is running locally as a daemon" f"process service and accepts inference requests at: n" f" {service.prediction_url}n" f"To stop the service, run" f"[italic green] zenml model-deployer models delete" f"{str(service.uuid)}'[/italic green]." ) elif service.is_failed: print( f"The MLflow prediciton server is in a failed state: n" f" Last state: '{service.status.state.value}'n" f" Last error: '{service.status.last_error}'" ) else: print( "No MLflow prediction server is currently running. The deployment" "pipeline must run first to train a model and deploy it. Execute" "the same command with the '--deploy' argument to deploy a model." ) # Entry point: If this script is executed directly, run the main function
if __name__ == "__main__": run_main()Este código es un script de línea de comandos para administrar e implementar el modelo de aprendizaje automático utilizando MLFlow y ZenMl.
Ahora, implementemos el modelo.
Ejecute este comando en su terminal.
python run_deployment.py --config deploy
Ahora hemos implementado nuestro modelo. Su canalización se ejecutará correctamente y podrá verlos en el panel de zenml.
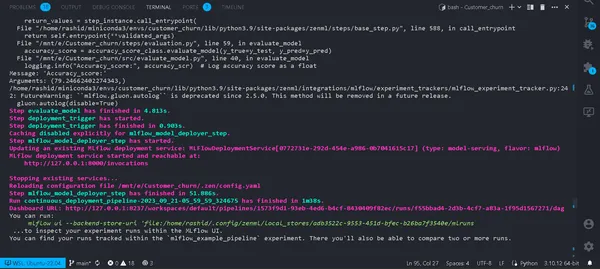
python run_deployment.py --config predictIniciando el proceso de predicción
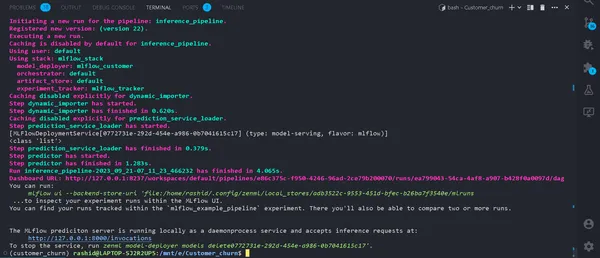
Ahora, nuestro servidor de predicción MLFlow se está ejecutando.
Necesitamos una aplicación web para ingresar los datos y ver los resultados. Quizás te preguntes por qué tenemos que crear una aplicación web desde cero.
No precisamente. Usaremos Streamlit, que es un marco de interfaz de código abierto que ayuda a crear una aplicación web de interfaz de usuario rápida y sencilla para nuestro modelo de aprendizaje automático.
Instalar la biblioteca
pip install streamlitCree un archivo llamado streamlit_app.py en el directorio de su proyecto.
import json
import logging
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
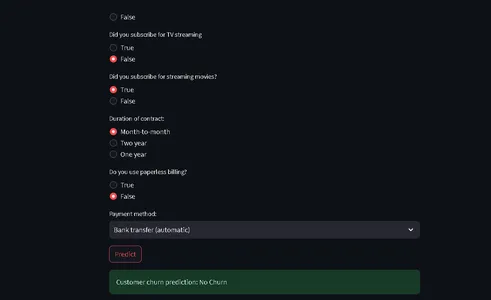
from run_deployment import main def main(): st.title("End to End Customer Satisfaction Pipeline with ZenML") st.markdown( """ #### Problem Statement The objective here is to predict the customer satisfaction score for a given order based on features like order status, price, payment, etc. I will be using [ZenML](https://zenml.io/) to build a production-ready pipeline to predict the customer satisfaction score for the next order or purchase. """ ) st.markdown( """ Above is a figure of the whole pipeline, we first ingest the data, clean it, train the model, and evaluate the model, and if data source changes or any hyperparameter values changes, deployment will be triggered, and (re) trains the model and if the model meets minimum accuracy requirement, the model will be deployed. """ ) st.markdown( """ #### Description of Features This app is designed to predict the customer satisfaction score for a given customer. You can input the features of the product listed below and get the customer satisfaction score. | Models | Description | | ------------- | - | | SeniorCitizen | Indicates whether the customer is a senior citizen. | | tenure | Number of months the customer has been with the company. | | MonthlyCharges | Monthly charges incurred by the customer. | | TotalCharges | Total charges incurred by the customer. | | gender | Gender of the customer (Male: 1, Female: 0). | | Partner | Whether the customer has a partner (Yes: 1, No: 0). | | Dependents | Whether the customer has dependents (Yes: 1, No: 0). | | PhoneService | Whether the customer has dependents (Yes: 1, No: 0). | | MultipleLines | Whether the customer has multiple lines (Yes: 1, No: 0). | | InternetService | Type of internet service (No: 1, Other: 0). | | OnlineSecurity | Whether the customer has online security service (Yes: 1, No: 0). | | OnlineBackup | Whether the customer has online backup service (Yes: 1, No: 0). | | DeviceProtection | Whether the customer has device protection service (Yes: 1, No: 0). | | TechSupport | Whether the customer has tech support service (Yes: 1, No: 0). | | StreamingTV | Whether the customer has streaming TV service (Yes: 1, No: 0). | | StreamingMovies | Whether the customer has streaming movies service (Yes: 1, No: 0). | | Contract | Type of contract (One year: 1, Other: 0). | | PaperlessBilling | Whether the customer has paperless billing (Yes: 1, No: 0). | | PaymentMethod | Payment method (Credit card: 1, Other: 0). | | Churn | Whether the customer has churned (Yes: 1, No: 0). | """ ) payment_options = { 2: "Electronic check", 3: "Mailed check", 1: "Bank transfer (automatic)", 0: "Credit card (automatic)" } contract = { 0: "Month-to-month", 2: "Two year", 1: "One year" } def format_func(PaymentMethod): return payment_options[PaymentMethod] def format_func_contract(Contract): return contract[Contract] display = ("male", "female") options = list(range(len(display))) # Define the data columns with their respective values SeniorCitizen = st.selectbox("Are you senior citizen?", options=[True, False],) tenure = st.number_input("Tenure") MonthlyCharges = st.number_input("Monthly Charges: ") TotalCharges = st.number_input("Total Charges: ") gender = st.radio("gender:", options, format_func=lambda x: display[x]) Partner = st.radio("Do you have a partner? ", options=[True, False]) Dependents = st.radio("Dependents: ", options=[True, False]) PhoneService = st.radio("Do you have phone service? : ", options=[True, False]) MultipleLines = st.radio("Do you Multiplines? ", options=[True, False]) InternetService = st.radio("Did you subscribe for Internet service? ", options=[True, False]) OnlineSecurity = st.radio("Did you subscribe for OnlineSecurity? ", options=[True, False]) OnlineBackup = st.radio("Did you subscribe for Online Backup service? ", options=[True, False]) DeviceProtection = st.radio("Did you subscribe for device protection only?", options=[True, False]) TechSupport =st.radio("Did you subscribe for tech support? ", options=[True, False]) StreamingTV = st.radio("Did you subscribe for TV streaming", options=[True, False]) StreamingMovies = st.radio("Did you subscribe for streaming movies? ", options=[True, False]) Contract = st.radio("Duration of contract: ", options=list(contract.keys()), format_func=format_func_contract) PaperlessBilling = st.radio("Do you use paperless billing? ", options=[True, False]) PaymentMethod = st.selectbox("Payment method:", options=list(payment_options.keys()), format_func=format_func) # You can use PaymentMethod to get the selected payment method's numeric value if st.button("Predict"): service = prediction_service_loader( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", running=False, ) if service is None: st.write( "No service could be found. The pipeline will be run first to create a service." ) run_main() try: data_point = { 'SeniorCitizen': int(SeniorCitizen), 'tenure': tenure, 'MonthlyCharges': MonthlyCharges, 'TotalCharges': TotalCharges, 'gender': int(gender), 'Partner': int(Partner), 'Dependents': int(Dependents), 'PhoneService': int(PhoneService), 'MultipleLines': int(MultipleLines), 'InternetService': int(InternetService), 'OnlineSecurity': int(OnlineSecurity), 'OnlineBackup': int(OnlineBackup), 'DeviceProtection': int(DeviceProtection), 'TechSupport': int(TechSupport), 'StreamingTV': int(StreamingTV), 'StreamingMovies': int(StreamingMovies), 'Contract': int(Contract), 'PaperlessBilling': int(PaperlessBilling), 'PaymentMethod': int(PaymentMethod) } # Convert the data point to a Series and then to a DataFrame data_point_series = pd.Series(data_point) data_point_df = pd.DataFrame(data_point_series).T # Convert the DataFrame to a JSON list json_list = json.loads(data_point_df.to_json(orient="records")) data = np.array(json_list) for i in range(len(data)): logging.info(data[i]) pred = service.predict(data) logging.info(pred) st.success(f"Customer churn prediction: {'Churn' if pred == 1 else 'No Churn'}") except Exception as e: logging.error(e) raise e if __name__ == "__main__": main()Este código define que StreamLit proporcionará una interfaz para predecir la pérdida de clientes en una empresa de telecomunicaciones en función de los datos de los clientes y los detalles demográficos.
Los usuarios pueden ingresar su información a través de una interfaz fácil de usar y el código utiliza un modelo de aprendizaje automático entrenado (implementado con ZenML y MLflow) para hacer predicciones.
Luego, el resultado previsto se muestra al usuario.
Ahora ejecuta este comando:
⚠️ asegúrese de que su modelo de predicción esté funcionando
streamlit run streamlit_app.pyClic en el enlace.
Eso es todo; Hemos completado nuestro proyecto.

Eso es todo; Hemos concluido con éxito nuestro proyecto de aprendizaje automático de un extremo a otro, cómo los profesionales abordan todo el proceso.
Conclusión
En esta exploración integral de las operaciones de aprendizaje automático (MLOps) a través del desarrollo y la implementación de un modelo de predicción de abandono de clientes, hemos sido testigos del poder transformador de MLOps para optimizar el ciclo de vida del aprendizaje automático. Desde la recopilación y el preprocesamiento de datos hasta la capacitación, evaluación e implementación de modelos, nuestro proyecto muestra el papel esencial de MLOps para cerrar la brecha entre el desarrollo y la producción. A medida que las organizaciones dependen cada vez más de la toma de decisiones basada en datos, las prácticas eficientes y escalables demostradas aquí resaltan la importancia crítica de MLOps para garantizar el éxito de las aplicaciones de aprendizaje automático.
Puntos clave
- MLOps (Operaciones de aprendizaje automático) es fundamental para optimizar el ciclo de vida del aprendizaje automático de un extremo a otro, garantizando operaciones eficientes, confiables y escalables.
- ZenML y MLflow son marcos poderosos que facilitan el desarrollo, seguimiento e implementación de modelos de aprendizaje automático en aplicaciones del mundo real.
- El preprocesamiento adecuado de datos, incluida la limpieza, codificación y división, es fundamental para crear modelos sólidos de aprendizaje automático.
- Las métricas de evaluación como la exactitud, la precisión, la recuperación y la puntuación F1 brindan una comprensión integral del rendimiento del modelo.
- Las herramientas de seguimiento de experimentos como MLflow mejoran la colaboración y la gestión de la experimentación en proyectos de ciencia de datos.
- Los canales de implementación continua y de inferencia son fundamentales para mantener la eficiencia y la disponibilidad del modelo en entornos de producción.
Preguntas frecuentes
MLOPS significa que Machine Learning Operations es un ciclo de vida de aprendizaje automático de un extremo a otro, desde el desarrollo hasta la recopilación de datos. Es un conjunto de prácticas para diseñar y automatizar todo el ciclo de aprendizaje automático. Abarca todas las etapas, desde el desarrollo y la capacitación de modelos de aprendizaje automático hasta su implementación, monitoreo y mantenimiento continuo. MLOps es crucial porque garantiza la escalabilidad, confiabilidad y eficiencia de las aplicaciones de aprendizaje automático. Ayuda a los científicos de datos a crear aplicaciones sólidas de aprendizaje automático que ofrecen predicciones precisas.
MLOps y DevOps tienen objetivos similares de optimizar y automatizar procesos dentro de sus respectivos dominios. DevOps se centra principalmente en el desarrollo de software, el proceso de entrega de software. Su objetivo es acelerar el desarrollo de software, mejorar la calidad del código y mejorar la confiabilidad de la implementación. MLOps satisface las necesidades especializadas de los proyectos de aprendizaje automático, lo que la convierte en una práctica crucial para aprovechar la inteligencia artificial y la ciencia de datos.
Este es un error común al que se enfrentará en el proyecto. Solo corre
'zenml abajo'
luego
'desconexión zenml'
ejecute nuevamente la tubería. Se resolverá.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/10/a-mlops-enhanced-customer-churn-prediction-project/

