Cliente 360 (C360) proporciona una vista completa y unificada de las interacciones y el comportamiento de un cliente en todos los puntos de contacto y canales. Esta vista se utiliza para identificar patrones y tendencias en el comportamiento del cliente, que pueden informar decisiones basadas en datos para mejorar los resultados comerciales. Por ejemplo, puede utilizar C360 para segmentar y crear campañas de marketing que tengan más probabilidades de resonar en grupos específicos de clientes.
En 2022, AWS encargó un estudio realizado por el Centro Estadounidense de Productividad y Calidad (APQC) para cuantificar la Valor comercial del cliente 360. La siguiente figura muestra algunas de las métricas derivadas del estudio. Las organizaciones que utilizaron C360 lograron una reducción del 43.9 % en la duración del ciclo de ventas, un aumento del 22.8 % en el valor de vida del cliente, un tiempo de comercialización un 25.3 % más rápido y una mejora del 19.1 % en la calificación de puntuación neta del promotor (NPS).

Sin C360, las empresas se enfrentan a oportunidades perdidas, informes inexactos y experiencias de clientes inconexas, lo que genera una pérdida de clientes. Sin embargo, crear una solución C360 puede resultar complicado. A Encuesta de marketing de Gartner descubrió que solo el 14 % de las organizaciones han implementado con éxito una solución C360, debido a la falta de consenso sobre lo que significa una vista de 360 grados, los desafíos con la calidad de los datos y la falta de una estructura de gobierno multifuncional para los datos de los clientes.
En esta publicación, analizamos cómo puede utilizar servicios de AWS diseñados específicamente para crear una estrategia de datos de un extremo a otro para que C360 unifique y gobierne los datos de los clientes que abordan estos desafíos. Lo estructuramos en cinco pilares que impulsan C360: recopilación de datos, unificación, análisis, activación y gobierno de datos, junto con una arquitectura de solución que puede utilizar para su implementación.
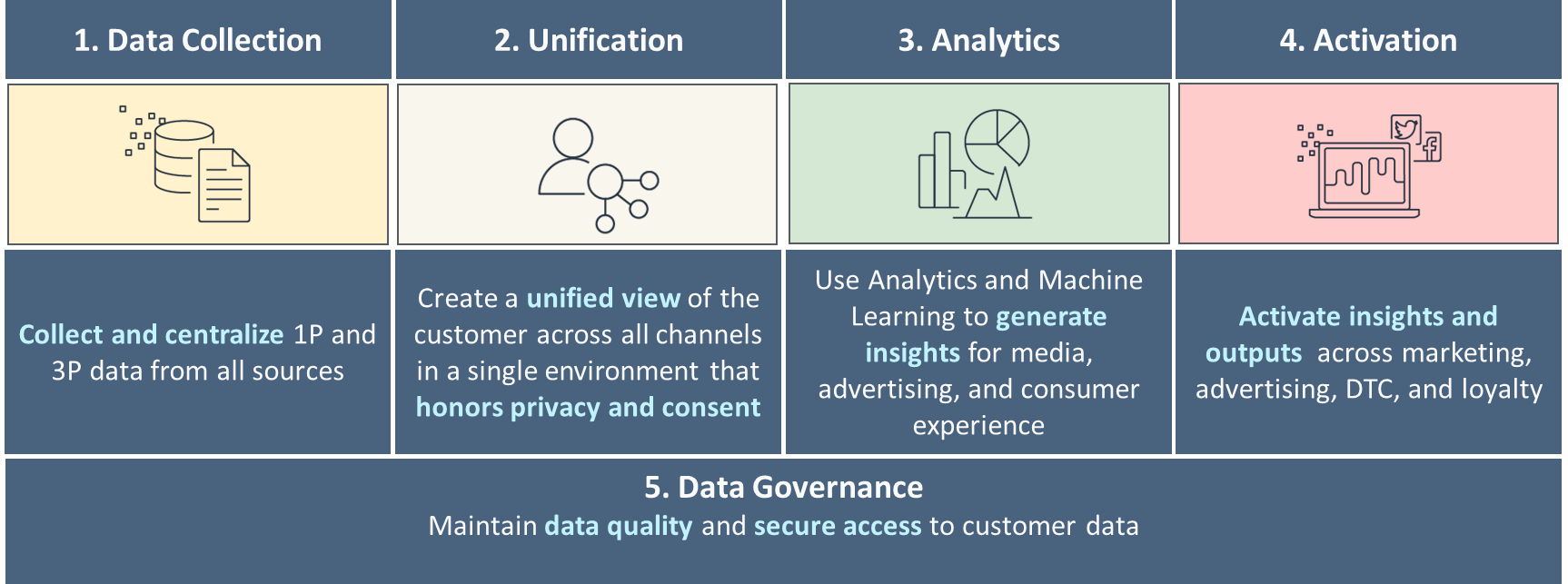
Los cinco pilares de un C360 maduro
Cuando se embarca en la creación de un C360, trabaja con múltiples casos de uso, tipos de datos de clientes y usuarios y aplicaciones que requieren diferentes herramientas. Crear un C360 con los conjuntos de datos correctos, agregar nuevos conjuntos de datos a lo largo del tiempo y al mismo tiempo mantener la calidad de los datos y mantenerlos seguros requiere una estrategia de datos de extremo a extremo para los datos de sus clientes. También debe proporcionar herramientas que faciliten a sus equipos la creación de productos que hagan madurar su C360.
Recomendamos construir su estrategia de datos en torno a cinco pilares de C360, como se muestra en la siguiente figura. Esto comienza con la recopilación de datos básicos, unificando y vinculando datos de varios canales relacionados con clientes únicos, y avanza hacia análisis básicos a avanzados para la toma de decisiones y la participación personalizada a través de varios canales. A medida que madure en cada uno de estos pilares, avanzará hacia la respuesta a las señales de los clientes en tiempo real.
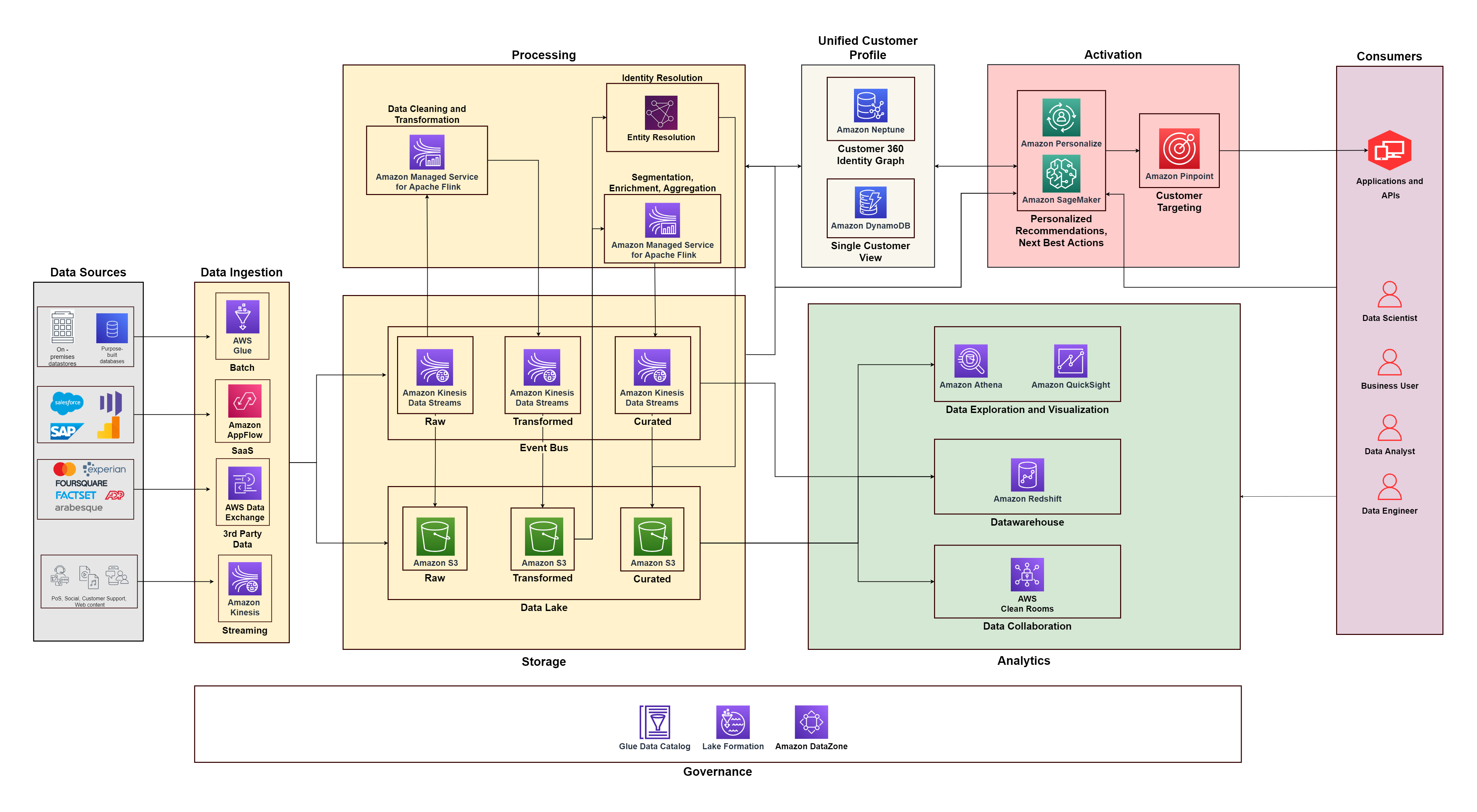
El siguiente diagrama ilustra la arquitectura funcional que combina los componentes básicos de una Plataforma de datos del cliente en AWS con componentes adicionales utilizados para diseñar una solución C360 de extremo a extremo. Esto está alineado con los cinco pilares que analizamos en esta publicación.
Pilar 1: Recopilación de datos
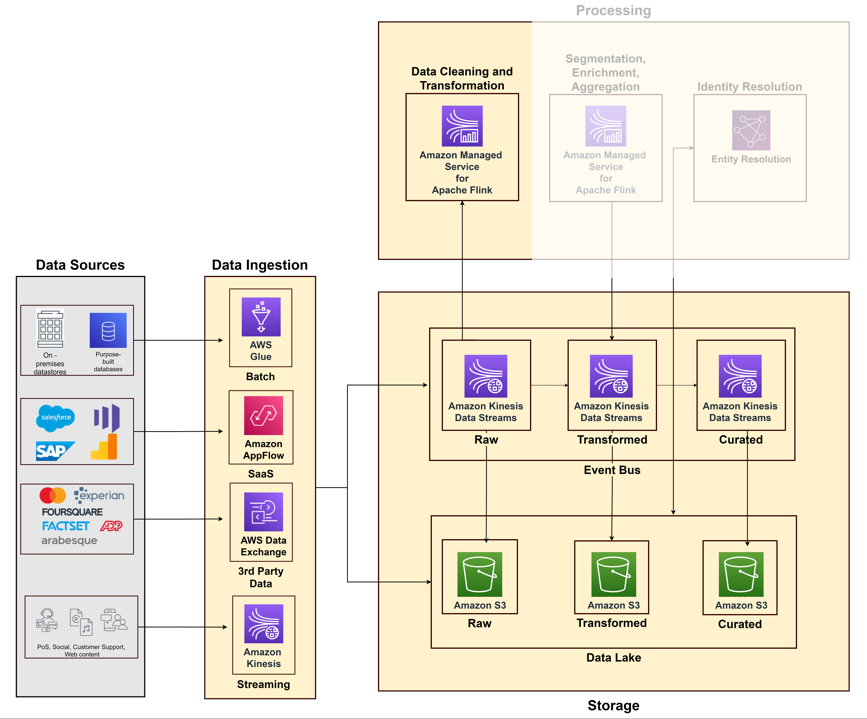
A medida que comienza a construir su plataforma de datos de clientes, debe recopilar datos de varios sistemas y puntos de contacto, como sus sistemas de ventas, atención al cliente, redes sociales y web, y mercados de datos. Piense en el pilar de recopilación de datos como una combinación de capacidades de ingesta, almacenamiento y procesamiento.
Ingestión de datos
Debe crear canales de ingesta basados en factores como tipos de fuentes de datos (almacenes de datos locales, archivos, aplicaciones SaaS, datos de terceros) y flujo de datos (flujos ilimitados o datos por lotes). AWS proporciona diferentes servicios para crear canales de ingesta de datos:
- Pegamento AWS es un servicio de integración de datos sin servidor que ingiere datos en lotes desde bases de datos locales y almacenes de datos en la nube. Se conecta a más de 70 fuentes de datos y le ayuda a crear canalizaciones de extracción, transformación y carga (ETL) sin tener que administrar la infraestructura de canalizaciones. Calidad de datos de AWS Glue comprueba y alerta sobre datos deficientes, lo que facilita la detección y solución de problemas antes de que perjudiquen su negocio.
- Flujo de aplicaciones de Amazon ingiere datos de aplicaciones de software como servicio (SaaS) como Google Analytics, Salesforce, SAP y Marketo, lo que le brinda la flexibilidad de ingerir datos de más de 50 aplicaciones SaaS.
- Intercambio de datos de AWS facilita la búsqueda, suscripción y uso de datos de terceros para análisis. Puede suscribirse a productos de datos que ayuden a enriquecer los perfiles de los clientes, por ejemplo, datos demográficos, datos publicitarios y datos de mercados financieros.
- Kinesis amazónica ingiere eventos de transmisión en tiempo real desde sistemas de puntos de venta, datos de secuencias de clics de aplicaciones móviles y sitios web, y datos de redes sociales. También podrías considerar usar Streaming administrado por Amazon para Apache Kafka (Amazon MSK) para transmisión de eventos en tiempo real.
El siguiente diagrama ilustra las diferentes canalizaciones para ingerir datos de varios sistemas de origen mediante los servicios de AWS.
Almacenamiento de datos
Los datos por lotes estructurados, semiestructurados o no estructurados se almacenan en un almacenamiento de objetos porque son rentables y duraderos. Servicio de almacenamiento simple de Amazon (Amazon S3) es un servicio de almacenamiento administrado con funciones de archivo que pueden almacenar petabytes de datos con once 9 de durabilidad. Los datos de transmisión con necesidades de baja latencia se almacenan en Secuencias de datos de Amazon Kinesis para consumo en tiempo real. Esto permite análisis y acciones inmediatas para varios consumidores intermedios, como se ve con el sistema central de Riot Games. Autobús de eventos antidisturbios.
Proceso de datos
Los datos sin procesar suelen estar llenos de duplicados y formatos irregulares. Debe procesar esto para que esté listo para el análisis. Si consume datos por lotes y datos en streaming, considere utilizar un marco que pueda manejar ambos. Un patrón como el arquitectura kappa ve todo como una secuencia, lo que simplifica los procesos de procesamiento. Considere usar Servicio administrado de Amazon para Apache Flink para manejar el trabajo de procesamiento. Con Managed Service para Apache Flink, puede limpiar y transformar los datos de transmisión y dirigirlos al destino adecuado según los requisitos de latencia. También puede implementar el procesamiento de datos por lotes utilizando EMR de Amazon en marcos de código abierto como Apache Spark con un rendimiento 3.5 veces mejor que la versión autogestionada. La decisión arquitectónica de utilizar un sistema de procesamiento por lotes o por streaming dependerá de varios factores; sin embargo, si desea habilitar análisis en tiempo real de los datos de sus clientes, le recomendamos utilizar un patrón de arquitectura Kappa.
Pilar 2: Unificación
Para vincular los diversos datos que llegan desde varios puntos de contacto a un cliente único, es necesario crear una solución de procesamiento de identidad que identifique inicios de sesión anónimos, almacene información útil del cliente, los vincule a datos externos para obtener mejores conocimientos y agrupe a los clientes en dominios de interés. Aunque la solución de procesamiento de identidad ayuda a crear un perfil de cliente unificado, recomendamos considerar esto como parte de sus capacidades de procesamiento de datos. El siguiente diagrama ilustra los componentes de dicha solución.
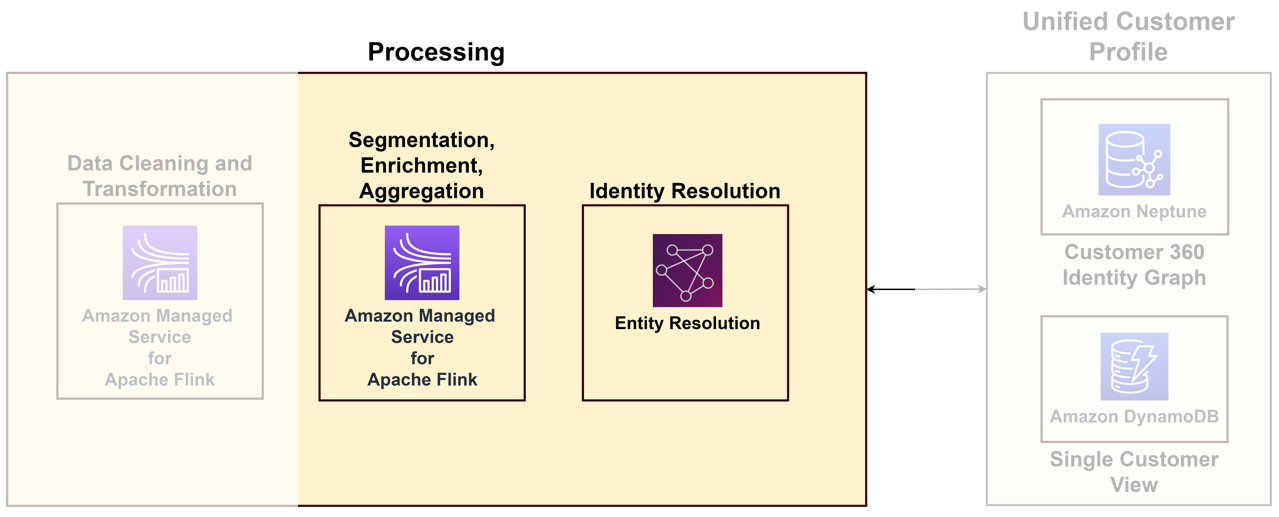
Los componentes clave son los siguientes:
- Resolución de identidad – La resolución de identidad es una solución de deduplicación, donde los registros se comparan para identificar a un cliente único y a clientes potenciales vinculando múltiples identificadores como cookies, identificadores de dispositivo, direcciones IP, ID de correo electrónico e ID de empresa interna a una persona conocida o un perfil anónimo mediante privacidad. métodos compatibles. Esto se puede lograr usando Resolución de entidad de AWS, que permite utilizar reglas y técnicas de aprendizaje automático (ML) para unir registros y resolver identidades. Alternativamente, puede construir gráficos de identidad usando Amazonas Neptuno para una vista única y unificada de sus clientes.
- Agregación de perfiles – Cuando haya identificado de forma única a un cliente, podrá crear aplicaciones en el servicio administrado para Apache Flink para consolidar todos sus metadatos, desde el nombre hasta el historial de interacciones. Luego, transforma estos datos en un formato conciso. En lugar de mostrar todos los detalles de la transacción, puede ofrecer un valor de gasto agregado y un enlace a su registro de Gestión de relaciones con el cliente (CRM). Para las interacciones de servicio al cliente, proporcione una puntuación CSAT promedio y un enlace al sistema del centro de llamadas para profundizar en su historial de comunicaciones.
- Enriquecimiento de perfil – Después de resolver un cliente con una identidad única, mejore su perfil utilizando varias fuentes de datos. El enriquecimiento normalmente implica agregar datos demográficos, de comportamiento y de geolocalización. Puedes usar productos de datos de terceros de AWS Marketplace entregados a través de AWS Data Exchange para obtener información sobre ingresos, patrones de consumo, puntuaciones de riesgo crediticio y muchas más dimensiones para perfeccionar aún más la experiencia del cliente.
- Segmentación de clientes – Después de identificar y enriquecer de forma única el perfil de un cliente, puede segmentarlo según datos demográficos como edad, gastos, ingresos y ubicación utilizando aplicaciones en Managed Service para Apache Flink. A medida que avances podrás ir incorporando Servicios de IA para técnicas de focalización más precisas.
Una vez que haya realizado el procesamiento y la segmentación de la identidad, necesita una capacidad de almacenamiento para almacenar el perfil único del cliente y proporcionar capacidades de búsqueda y consulta además para que los consumidores intermedios utilicen los datos enriquecidos del cliente.
El siguiente diagrama ilustra el pilar de unificación para un perfil de cliente unificado y una vista única del cliente para aplicaciones posteriores.
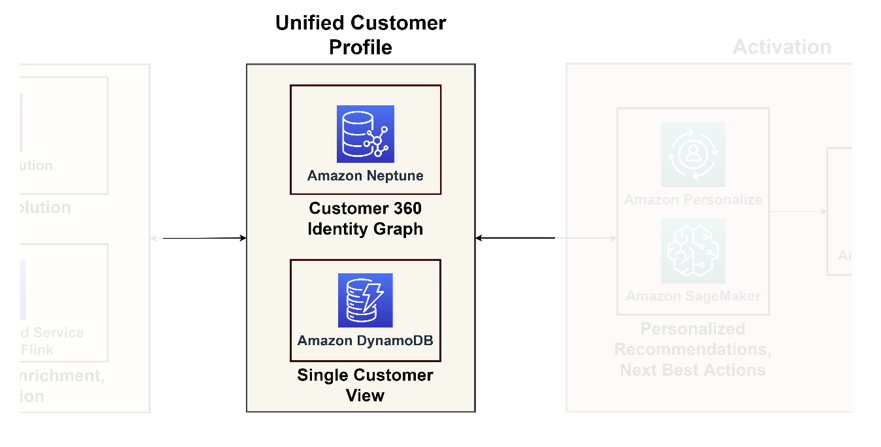
Perfil de cliente unificado
Las bases de datos de gráficos se destacan en el modelado de interacciones y relaciones con los clientes, ofreciendo una visión integral del recorrido del cliente. Si trabaja con miles de millones de perfiles e interacciones, puede considerar utilizar Neptune, un servicio de base de datos de gráficos administrado en AWS. Organizaciones como Zed y Activision han utilizado Neptune con éxito para almacenar y consultar miles de millones de identificadores únicos por mes y millones de consultas por segundo con un tiempo de respuesta de milisegundos.
Vista de cliente único
Aunque las bases de datos de gráficos proporcionan información detallada, pueden resultar complejas para aplicaciones habituales. Es prudente consolidar estos datos en una única vista del cliente, que sirva como referencia principal para aplicaciones posteriores, que van desde plataformas de comercio electrónico hasta sistemas CRM. Esta visión consolidada actúa como enlace entre la plataforma de datos y las aplicaciones centradas en el cliente. Para tales fines, recomendamos utilizar Amazon DynamoDB por su adaptabilidad, escalabilidad y rendimiento, dando como resultado una base de datos de clientes actualizada y eficiente. Esta base de datos aceptará muchas consultas de escritura de los sistemas de activación que aprenden nueva información sobre los clientes y les brindan información.
Pilar 3: Análisis
El pilar de análisis define capacidades que le ayudan a generar información sobre los datos de sus clientes. Su estrategia de análisis se aplica a las necesidades organizacionales más amplias, no solo a C360. Puede utilizar las mismas capacidades para generar informes financieros, medir el rendimiento operativo o incluso monetizar los activos de datos. Cree estrategias en función de cómo sus equipos exploran datos, ejecutan análisis, analizan datos para requisitos posteriores y visualizan datos en diferentes niveles. Planifique cómo puede permitir que sus equipos utilicen ML para pasar del análisis descriptivo al prescriptivo.
El Arquitectura de datos moderna de AWS muestra una manera de construir una plataforma de datos escalable, segura y diseñada específicamente en la nube. Aprenda de esto para crear capacidades de consulta en su lago de datos y en el almacén de datos.
El siguiente diagrama desglosa la capacidad de análisis en exploración de datos, visualización, almacenamiento de datos y colaboración de datos. Averigüemos qué papel juega cada uno de estos componentes en el contexto de C360.

Exploración de datos
La exploración de datos ayuda a descubrir inconsistencias, valores atípicos o errores. Al detectarlos desde el principio, sus equipos pueden tener una integración de datos más limpia para C360, lo que a su vez conduce a análisis y predicciones más precisos. Considere las personas que exploran los datos, sus habilidades técnicas y el tiempo para obtener información. Por ejemplo, los analistas de datos que saben escribir SQL pueden consultar directamente los datos que residen en Amazon S3 utilizando Atenea amazónica. Los usuarios interesados en la exploración visual pueden hacerlo utilizando Elaboración de datos de AWS Glue. Los científicos o ingenieros de datos pueden utilizar Estudio de Amazon EMR or Estudio Amazon SageMaker para explorar datos desde el cuaderno y, para disfrutar de una experiencia con poco código, puede utilizar Wrangler de datos de Amazon SageMaker. Debido a que estos servicios consultan directamente los depósitos de S3, puede explorar los datos a medida que llegan al lago de datos, lo que reduce el tiempo de obtención de información.
Visualización
Convertir conjuntos de datos complejos en imágenes intuitivas revela patrones ocultos en los datos y es crucial para los casos de uso de C360. Con esta capacidad, puede diseñar informes para diferentes niveles que satisfagan diversas necesidades: informes ejecutivos que ofrecen resúmenes estratégicos, informes de gestión que destacan métricas operativas e informes detallados que profundizan en los detalles. Esta claridad visual ayuda a su organización a tomar decisiones informadas en todos los niveles, centralizando la perspectiva del cliente.
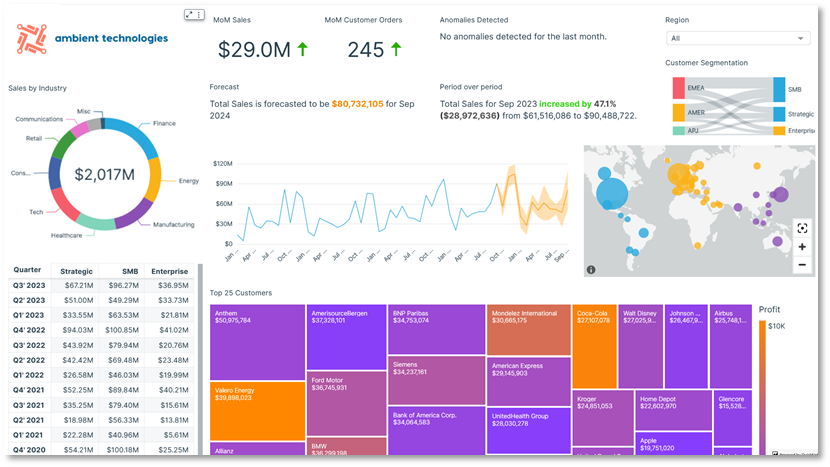
El siguiente diagrama muestra un panel de muestra de C360 integrado en Amazon QuickSight. QuickSight ofrece capacidades de visualización escalables y sin servidor. Puede beneficiarse de sus integraciones de aprendizaje automático para obtener información automatizada como previsión y detección de anomalías o consultas en lenguaje natural con Amazon Q en QuickSight, conectividad directa de datos de diversas fuentes, y precios de pago por sesión. Con QuickSight, puede Incrustar paneles en sitios web y aplicaciones externos., y la SPICE El motor permite una visualización de datos rápida e interactiva a escala. La siguiente captura de pantalla muestra un panel de ejemplo de C360 creado en QuickSight.
Almacén de datos
Los almacenes de datos son eficientes para consolidar datos estructurados de diversas fuentes y atender consultas analíticas de una gran cantidad de usuarios simultáneos. Los almacenes de datos pueden proporcionar una vista unificada y coherente de una gran cantidad de datos de clientes para casos de uso C360. Desplazamiento al rojo de Amazon aborda esta necesidad manejando hábilmente grandes volúmenes de datos y diversas cargas de trabajo. Proporciona una sólida coherencia entre los conjuntos de datos, lo que permite a las organizaciones obtener información confiable y completa sobre sus clientes, lo cual es esencial para una toma de decisiones informada. Amazon Redshift ofrece información en tiempo real y capacidades de análisis predictivo para analizar datos desde terabytes hasta petabytes. Con Aprendizaje automático de Amazon Redshift, puede incorporar ML encima de los datos almacenados en el almacén de datos con una mínima sobrecarga de desarrollo. Amazon Redshift sin servidor simplifica la creación de aplicaciones y facilita que las empresas incorporen capacidades de análisis de datos enriquecidas.
Colaboración de datos
Puedes de forma segura colaborar y analizar conjuntos de datos colectivos de sus socios sin compartir ni copiar los datos subyacentes de cada uno utilizando Salas limpias de AWS. Puede reunir datos dispares de todos los canales de participación y conjuntos de datos de socios para formar una vista de 360 grados de sus clientes. AWS Clean Rooms puede mejorar C360 al permitir casos de uso como optimización de marketing multicanal, segmentación avanzada de clientes y personalización que cumpla con las normas de privacidad. Al fusionar conjuntos de datos de forma segura, ofrece conocimientos más completos y una privacidad de datos sólida, satisfaciendo las necesidades comerciales y los estándares regulatorios.
Pilar 4: Activación
El valor de los datos disminuye a medida que envejecen, lo que genera mayores costos de oportunidad con el tiempo. En una encuesta realizado por Intersystems, el 75% de las organizaciones encuestadas cree que los datos inoportunos inhibieron las oportunidades comerciales. En otra encuesta, el 58% de las organizaciones (de 560 encuestados del consejo asesor de HBR y lectores) afirmaron haber visto un aumento en la retención y lealtad de los clientes utilizando análisis de clientes en tiempo real.
Puede alcanzar la madurez en C360 cuando desarrolle la capacidad de actuar sobre todos los conocimientos adquiridos de los pilares anteriores que analizamos en tiempo real. Por ejemplo, en este nivel de madurez, puede actuar sobre la opinión del cliente basándose en el contexto que derivó automáticamente con un perfil de cliente enriquecido y canales integrados. Para ello es necesario implementar una toma de decisiones prescriptiva sobre cómo abordar el sentimiento del cliente. Para hacer esto a escala, debe utilizar servicios de IA/ML para la toma de decisiones. El siguiente diagrama ilustra la arquitectura para activar conocimientos utilizando ML para análisis prescriptivos y servicios de IA para focalización y segmentación.
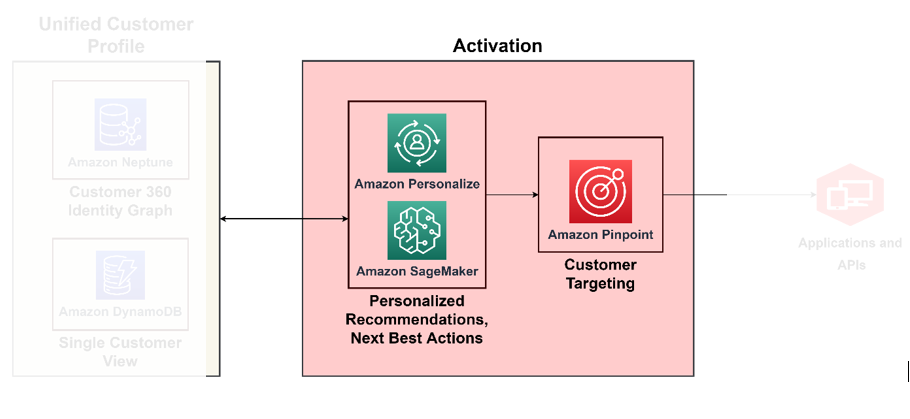
Utilice ML para el motor de toma de decisiones
Con ML, puede mejorar la experiencia general del cliente: puede crear modelos predictivos de comportamiento del cliente, diseñar ofertas hiperpersonalizadas y dirigirse al cliente adecuado con el incentivo adecuado. Puedes construirlos usando Amazon SageMaker, que presenta un conjunto de servicios administrados asignados al ciclo de vida de la ciencia de datos, que incluyen gestión de datos, entrenamiento de modelos, alojamiento de modelos, inferencia de modelos, detección de deriva de modelos y almacenamiento de características. SageMaker le permite Construya y ponga en funcionamiento sus modelos de aprendizaje automático., incorporándolos nuevamente a sus aplicaciones para producir la información adecuada para la persona adecuada en el momento adecuado.
Amazon Personalize admite recomendaciones contextuales, a través de las cuales puede mejorar la relevancia de las recomendaciones generándolas dentro de un contexto, por ejemplo, tipo de dispositivo, ubicación u hora del día. Su equipo puede comenzar sin ninguna experiencia previa en aprendizaje automático utilizando API para crear capacidades de personalización sofisticadas con unos pocos clics. Para más información, ver Personalice sus recomendaciones promocionando artículos específicos utilizando reglas comerciales con Amazon Personalize.
Activar canales de marketing, publicidad, directo al consumidor y fidelización.
Ahora que sabe quiénes son sus clientes y a quién dirigirse, puede crear soluciones para ejecutar campañas de segmentación a escala. Con Punto de Amazon, puede personalizar y segmentar las comunicaciones para atraer clientes a través de múltiples canales. Por ejemplo, puede utilizar Amazon Pinpoint para crear experiencias atractivas para los clientes a través de varios canales de comunicación como correo electrónico, SMS, notificaciones automáticas y notificaciones dentro de la aplicación.
Pilar 5: Gobernanza de datos
Establecer la gobernanza adecuada que equilibre el control y el acceso brinda a los usuarios confianza en los datos. Imagine ofrecer promociones de productos que un cliente no necesita o bombardear con notificaciones a los clientes equivocados. La mala calidad de los datos puede provocar este tipo de situaciones y, en última instancia, provocar la pérdida de clientes. Es necesario crear procesos que validen la calidad de los datos y tomen acciones correctivas. Calidad de datos de AWS Glue puede ayudarle a crear soluciones que validen la calidad de los datos en reposo y en tránsito, según reglas predefinidas.
Para configurar una estructura de gobierno multifuncional para los datos de los clientes, necesita una capacidad para gobernar y compartir datos en toda su organización. Con Zona de datos de Amazon, los administradores y administradores de datos pueden gestionar y controlar el acceso a los datos, y los consumidores, como ingenieros de datos, científicos de datos, gerentes de productos, analistas y otros usuarios comerciales, pueden descubrir, utilizar y colaborar con esos datos para generar conocimientos. Agiliza el acceso a los datos, permitiéndole encontrar y utilizar datos de clientes, promueve la colaboración en equipo con activos de datos compartidos y proporciona análisis personalizados a través de una aplicación web o API en un portal. Formación del lago AWS se asegura de que se acceda a los datos de forma segura, garantizando que las personas adecuadas vean los datos correctos por los motivos correctos, lo cual es crucial para una gobernanza interfuncional efectiva en cualquier organización. Los metadatos comerciales son almacenados y administrados por Amazon DataZone, que se basa en metadatos técnicos e información de esquema, que se registra en el Catálogo de datos de AWS Glue. Estos metadatos técnicos también los utilizan otros servicios de gobernanza, como Lake Formation y Amazon DataZone, y servicios de análisis, como Amazon Redshift, Athena y AWS Glue.

Llevar todo junto
Utilizando el siguiente diagrama como referencia, puede crear proyectos y equipos para crear y operar diferentes capacidades. Por ejemplo, puede hacer que un equipo de integración de datos se centre en el pilar de recopilación de datos; luego puede alinear roles funcionales, como arquitectos de datos e ingenieros de datos. Puede desarrollar sus prácticas de análisis y ciencia de datos para centrarse en los pilares de análisis y activación, respectivamente. Luego, puede crear un equipo especializado para procesar la identidad del cliente y crear una vista unificada del cliente. Puede establecer un equipo de gobierno de datos con administradores de datos de diferentes funciones, administradores de seguridad y formuladores de políticas de gobierno de datos para diseñar y automatizar políticas.
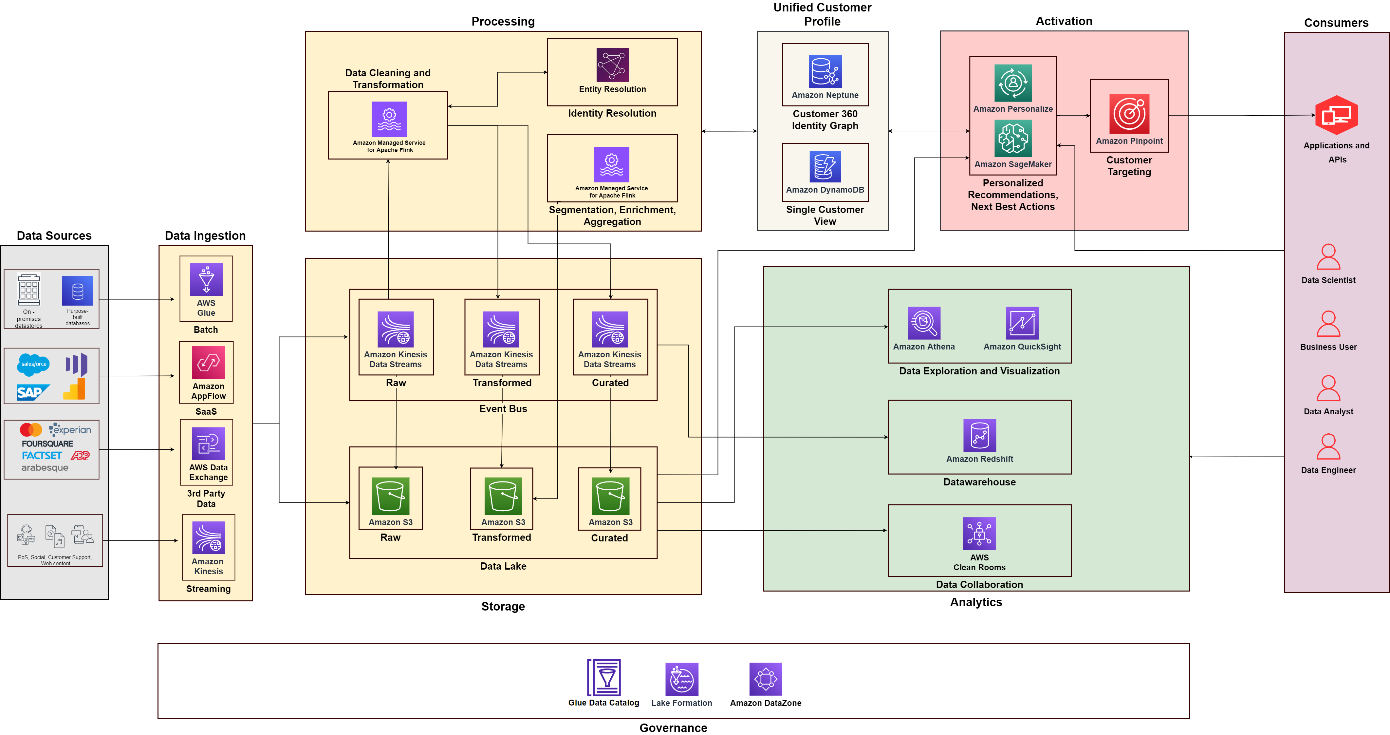
Conclusión
Desarrollar una capacidad C360 sólida es fundamental para que su organización obtenga información sobre su base de clientes. Las bases de datos, los análisis y los servicios de IA/ML de AWS pueden ayudar a optimizar este proceso, proporcionando escalabilidad y eficiencia. Siguiendo los cinco pilares que guían su pensamiento, puede crear una estrategia de datos de un extremo a otro que defina la visión C360 en toda la organización, garantice que los datos sean precisos y establezca una gobernanza multifuncional para los datos de los clientes. Puede categorizar y priorizar los productos y funciones que debe desarrollar dentro de cada pilar, seleccionar la herramienta adecuada para el trabajo y desarrollar las habilidades que necesita en sus equipos.
Visite Historias de clientes de AWS para datos para conocer cómo AWS está transformando los recorridos de los clientes, desde las empresas más grandes del mundo hasta las nuevas empresas en crecimiento.
Acerca de los autores
 Ismail Makhlouf es arquitecto senior de soluciones especializado en análisis de datos en AWS. Ismail se centra en diseñar soluciones para organizaciones en todo su conjunto de análisis de datos de extremo a extremo, incluida la transmisión por lotes y en tiempo real, big data, almacenamiento de datos y cargas de trabajo de lagos de datos. Trabaja principalmente con organizaciones de venta minorista, comercio electrónico, tecnología financiera, tecnología de la salud y viajes para lograr sus objetivos comerciales con plataformas de datos bien diseñadas.
Ismail Makhlouf es arquitecto senior de soluciones especializado en análisis de datos en AWS. Ismail se centra en diseñar soluciones para organizaciones en todo su conjunto de análisis de datos de extremo a extremo, incluida la transmisión por lotes y en tiempo real, big data, almacenamiento de datos y cargas de trabajo de lagos de datos. Trabaja principalmente con organizaciones de venta minorista, comercio electrónico, tecnología financiera, tecnología de la salud y viajes para lograr sus objetivos comerciales con plataformas de datos bien diseñadas.
 Sandipan Bhaumik (sandi) es arquitecto senior de soluciones especialista en análisis en AWS. Ayuda a los clientes a modernizar sus plataformas de datos en la nube para realizar análisis de forma segura a escala, reducir los gastos operativos y optimizar el uso para lograr rentabilidad y sostenibilidad.
Sandipan Bhaumik (sandi) es arquitecto senior de soluciones especialista en análisis en AWS. Ayuda a los clientes a modernizar sus plataformas de datos en la nube para realizar análisis de forma segura a escala, reducir los gastos operativos y optimizar el uso para lograr rentabilidad y sostenibilidad.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

